Lihang
1.0.0
Se ha publicado la segunda edición de este libro. Todas las actualizaciones de contenido posteriores a mayo de 2019 se refieren a la primera impresión de la segunda edición.
Para conocer el contenido de la primera edición, consulte Lanzamiento de la primera edición.
[TOC]
Para facilitar el aprendizaje, se recopilan algunas descripciones de herramientas.
Si necesita hacer referencia a este repositorio:
Formato: SmirkCao, Lihang, (2018), GitHub repository, https://github.com/SmirkCao/Lihang
o
@misc{SmirkCao,
author = {SmirkCao},
title = {Lihang},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/SmirkCao/Lihang}},
commit = {c5624a9bd757a5cc88e78b85b89e9221deb08270}
}
Esta parte del contenido no corresponde al prefacio de "Métodos de aprendizaje estadístico". El prefacio del libro también está bien escrito y se cita de la siguiente manera:
- En términos de selección de contenido, nos centramos en presentar los métodos más importantes y comúnmente utilizados, especialmente los métodos relacionados con problemas de clasificación y etiquetado .
- Intente utilizar un marco unificado para discutir todos los métodos para que todo el libro no pierda su sistematicidad.
- Aplicable a estudiantes universitarios y estudiantes de posgrado con especialización en recuperación de información y procesamiento del lenguaje natural.
Otra cosa a tener en cuenta es la trayectoria laboral del autor.
El autor ha participado en investigaciones sobre diversos procesamientos inteligentes de datos de texto utilizando métodos de aprendizaje estadístico, incluido el procesamiento del lenguaje natural, la recuperación de información y la extracción de datos de texto.
Si usa mi modelo para implementar la búsqueda de similitudes, el libro que es similar al libro del Sr. Li es "Dispositivos optoelectrónicos semiconductores". Es una lástima que no lo leí repetidamente cuando era joven.
Espero que en el proceso de lectura repetida, todo el libro se vuelva cada vez más grueso. Todos los documentos y códigos de esta serie, a menos que se indique lo contrario, la descripción "en el libro" se refiere a "Métodos de aprendizaje estadístico" del profesor Li Hang. Los contenidos de otras referencias se vincularán si se citan.
Algunas referencias se enumeran en Refs, algunas de las cuales son muy útiles para comprender el contenido del libro. Las descripciones y explicaciones de estos archivos se agregarán en Refs/README.md correspondiente a la sección de referencia. También se han agregado a este documento algunas notas sobre otras referencias.
Para facilitar la descarga de referencias, se agregó ref_downloader.sh durante review02, que se puede utilizar para descargar las referencias enumeradas en el libro. El proceso de actualización se completa gradualmente a medida que avanza review02.
Además, este libro del profesor Li Hang, Es realmente delgado (la segunda versión ya no es delgada) , pero casi cada oración resalta muchos puntos y vale la pena leerla una y otra vez.
Hay una tabla de símbolos después de la tabla de contenido del libro, que explica las definiciones de los símbolos, por lo que si hay símbolos que no comprende, puede buscarlos en la tabla; hay un índice al final del libro; y puedes utilizar el índice para encontrar el significado del símbolo correspondiente que aparece en el libro. En este Repo, se mantiene un glosario_index.md para agregar algunas explicaciones a los símbolos correspondientes y marcar directamente los números de página correspondientes a los símbolos. El progreso se actualizará con la revisión.
Después de cada algoritmo o ejemplo, habrá un ◼️, indicando que el algoritmo o ejemplo termina aquí. Esto se llama símbolo de fin de prueba. Lo sabrás si lees más literatura.
Al leer, a menudo tenemos preguntas sobre la base de los logaritmos. Algunas de las más importantes se destacan en el libro. Algunas que no se enfatizan se pueden entender a través del contexto. Además, como existe una fórmula para cambiar la base, no importa mucho cuál sea la base. La diferencia radica en un coeficiente constante. Sin embargo, elegir diferentes bases tendrá significados físicos y consideraciones de resolución de problemas. Para analizar este tema, puede consultar la discusión sobre entropía en PRML 1.6 para comprenderlo.
Además, en cuanto a la cuestión de los coeficientes constantes en la fórmula, si se utiliza una solución iterativa y, en ocasiones, se simplifica la fórmula hasta cierto punto, se puede mejorar la velocidad de convergencia. Los detalles pueden entenderse gradualmente en la práctica.
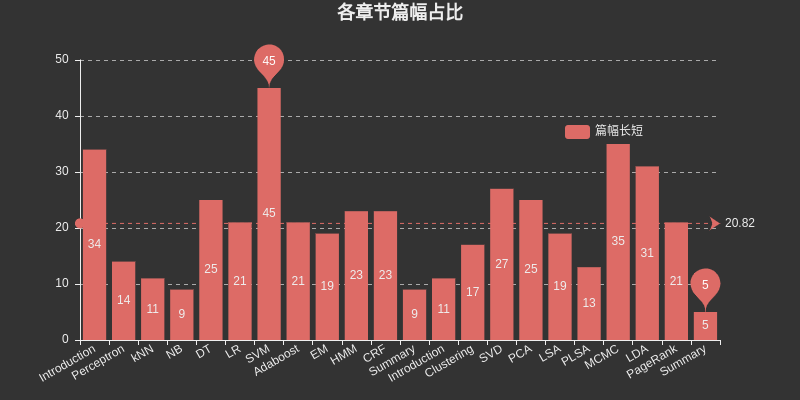
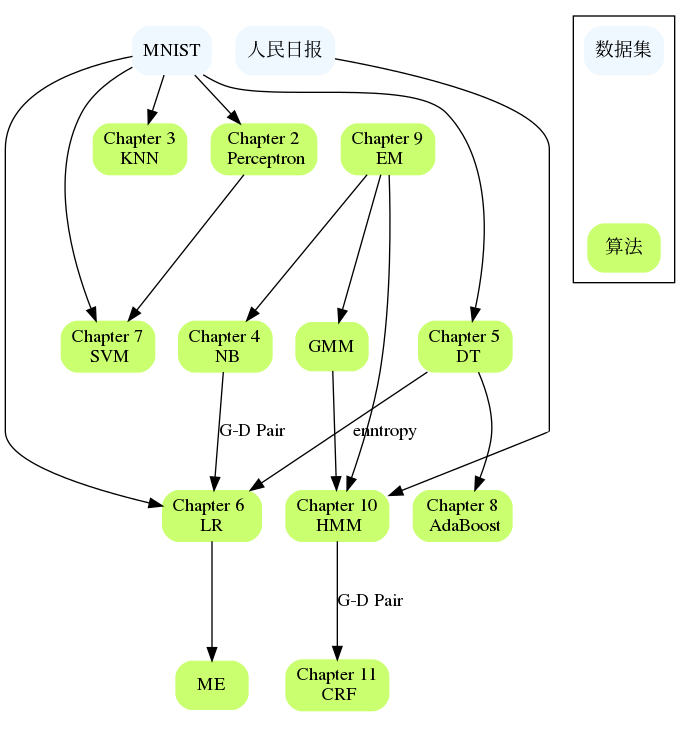
Inserte un cuadro aquí para enumerar el espacio ocupado por cada capítulo. Entre ellos, SVM ocupa el mayor espacio entre el aprendizaje supervisado, MCMC ocupa el mayor espacio entre el aprendizaje no supervisado y DT, HMM, CRF, SVD, PCA, LDA y. El PageRank también ocupa el espacio más grande.
Los capítulos están relacionados entre sí, como NB y LR, DT y AdaBoost, Perceptron y SVM, HMM y CRF, etc. Si encuentra dificultades en un capítulo grande, puede revisar el contenido de los capítulos anteriores o consultar las referencias. Generalmente se proporcionan referencias de capítulos específicos que describen el problema con más detalle y pueden explicar dónde se encuentra atascado.
Introducción
Tres elementos de los métodos de aprendizaje estadístico:
Modelo
Estrategia
algoritmo
La segunda edición ha reorganizado la estructura del directorio de este capítulo para hacerlo más claro.
perceptrón
kNN
NÓTESE BIEN.
DT
LR
Con respecto al estudio de la entropía máxima, se recomienda leer la literatura de referencia [1] en este capítulo, Berger, 1996, que es útil para comprender los ejemplos del libro y comprender el principio de la entropía máxima.
Entonces, ¿por qué se colocan LR y Maxent en un mismo capítulo?
Todos pertenecen al modelo lineal logarítmico.
Ambos se pueden utilizar para clasificación binaria y clasificación múltiple.
Los métodos de aprendizaje de los dos modelos generalmente utilizan estimación de máxima verosimilitud o estimación de máxima verosimilitud regularizada. Puede formalizarse como un problema de optimización sin restricciones y los métodos de solución incluyen IIS, GD, BFGS, etc.
Se describe a continuación en Regresión logística,
La regresión logística, a pesar de su nombre, es un modelo lineal para clasificación en lugar de regresión. La regresión logística también se conoce en la literatura como regresión logit, clasificación de máxima entropía (MaxEnt) o clasificador log-lineal. Los posibles resultados de un solo ensayo se modelan utilizando una función logística.
También existe tal descripción.
La regresión logística es un caso especial de máxima entropía con dos etiquetas +1 y −1.
La derivación en este capítulo utiliza la propiedad de $yin mathcal{Y}={0,1}$
A veces decimos que la regresión logística se llama Maxent en PNL
SVM
Impulsando
Vamos a desglosarlo aquí, porque HMM y CRF generalmente conducen a la introducción de modelos gráficos probabilísticos más adelante. En "Aprendizaje automático, Zhou Zhihua", se utiliza un capítulo separado sobre modelos gráficos probabilísticos para incluir HMM, MRF, CRF y otros contenidos. Además, hay muchos puntos relacionados desde HMM hasta el propio CRF.
En el primer capítulo del libro se explican tres aplicaciones del aprendizaje supervisado: clasificación, etiquetado y regresión. Hay suplementos en el Capítulo 12. Este libro considera principalmente los métodos de aprendizaje de los dos primeros. En consecuencia, la segmentación también es apropiada aquí. El modelo de clasificación se presenta anteriormente y la regresión se menciona en una pequeña parte. El problema del etiquetado se presenta principalmente más adelante.
EM
El algoritmo EM es un algoritmo iterativo utilizado para la estimación de máxima verosimilitud de los parámetros del modelo probabilístico que contienen variables ocultas, o estimación de máxima probabilidad posterior. (La estimación de máxima verosimilitud y la estimación de máxima probabilidad posterior aquí son estrategias de aprendizaje )
Si todas las variables del modelo de probabilidad son variables observadas, entonces, dados los datos, los parámetros del modelo se pueden estimar directamente utilizando el método de estimación de máxima verosimilitud o el método de estimación bayesiano.
Tenga en cuenta que si no comprende esta descripción en el libro, consulte la parte de estimación de parámetros del método Naive Bayes en CH04.
Esta parte del código implementa BMM y GMM, vale la pena echarle un vistazo.
Con respecto a EM, no se ha escrito mucho sobre este capítulo. EM es uno de los diez algoritmos principales y Hinton está estrechamente relacionado con el segundo artículo de Capsule Network "Matrix Capsules with EM Routing" en ICLR.
En CH22, el algoritmo EM se clasifica como un método básico de aprendizaje automático y no implica modelos específicos de aprendizaje automático. Puede usarse para aprendizaje no supervisado, aprendizaje supervisado y aprendizaje semisupervisado.
MMM
CRF
Resumen
Este capítulo sólo tiene unas pocas páginas. Puedes considerar la siguiente rutina de lectura:
Léelo con el Capítulo 1.
Si encuentra preguntas poco claras en estudios anteriores, lea este capítulo nuevamente.
Lea este capítulo detenidamente y amplíelo a otros diez capítulos.
Tenga en cuenta que en la Figura 12.2 de este capítulo se menciona que la función de pérdida logística $y$ aquí debe definirse en $cal{Y}={+1,-1}$ cuando se introdujo $y$. está definido en $cal{Y}={0,1}$, preste atención aquí.
El libro del profesor Li realmente te hace ganar algo nuevo cada vez que lo lees.
La segunda edición agrega ocho métodos de aprendizaje no supervisados: agrupamiento, descomposición de valores singulares, análisis de componentes principales, análisis semántico latente, análisis semántico latente probabilístico, método Monte Carlo de cadena de Markov, asignación de Dirichlet latente y PageRank.
Introducción
Agrupación
Cada capítulo de este libro no es completamente independiente. Esta parte espera organizar las conexiones entre los capítulos y los conjuntos de datos aplicables. Hasta qué punto se implementa el algoritmo y en qué conjuntos de datos puede ejecutarse también son un aspecto.