
Este repositorio contiene preguntas y ejercicios sobre diversos temas técnicos, a veces relacionados con DevOps y SRE.
Actualmente hay 2624 ejercicios y preguntas.
️ Puede utilizarlos para prepararse para una entrevista, pero la mayoría de las preguntas y ejercicios no representan una entrevista real. Lea la página de preguntas frecuentes para obtener más detalles.
? Si está interesado en seguir una carrera como ingeniero DevOps, sería útil aprender algunos de los conceptos mencionados aquí, pero debe saber que no se trata de aprender todos los temas y tecnologías mencionados en este repositorio.
Puede agregar más ejercicios enviando solicitudes de extracción :) Lea sobre las pautas de contribución aquí

DevOps | 
git | 
Red | 
Hardware | 
Kubernetes |

Desarrollo de software | 
Pitón | 
Ir | 
perla | 
expresión regular |

Nube | 
AWS | 
Azur | 
Plataforma en la nube de Google | 
pila abierta |

Sistema operativo | 
linux | 
Virtualización | 
DNS | 
Secuencias de comandos de shell |

Bases de datos | 
SQL | 
mongo | 
Pruebas | 
Grandes datos |

CI/CD | 
Certificados | 
Contenedores | 
Cambio abierto | 
Almacenamiento |

Terraformar | 
Marioneta | 
Repartido | 
Preguntas que puedes hacer | 
ansible |

Observabilidad | 
Prometeo | 
Círculo CI | 
| 
Grafana |

argo | 
Habilidades blandas | 
Seguridad | 
Diseño del sistema |

Ingeniería del Caos | 
Varios | 
Elástico | 
kafka | 
NodeJs |
Red
En general, ¿qué necesitas para comunicarte?
- Un lenguaje común (para que ambos extremos lo entiendan)
- Una forma de dirigirse a quién desea comunicarse
- Una conexión (para que el contenido de la comunicación pueda llegar a los destinatarios)
¿Qué es TCP/IP?
Un conjunto de protocolos que definen cómo dos o más dispositivos pueden comunicarse entre sí.
Para obtener más información sobre TCP/IP, lea aquí
¿Qué es Ethernet?
Ethernet simplemente se refiere al tipo más común de red de área local (LAN) que se utiliza en la actualidad. Una LAN, a diferencia de una WAN (red de área amplia), que abarca un área geográfica más grande, es una red conectada de computadoras en un área pequeña, como su oficina, campus universitario o incluso su hogar.
¿Qué es una dirección MAC? ¿Para qué se utiliza?
Una dirección MAC es un número o código de identificación único que se utiliza para identificar dispositivos individuales en la red.
Los paquetes que se envían por Ethernet siempre provienen de una dirección MAC y se envían a una dirección MAC. Si un adaptador de red recibe un paquete, compara la dirección MAC de destino del paquete con la dirección MAC del propio adaptador.
¿Cuándo se utiliza esta dirección MAC?: ff:ff:ff:ff:ff:ff
Cuando un dispositivo envía un paquete a la dirección MAC de transmisión (FF:FF:FF:FF:FF:FF), se entrega a todas las estaciones de la red local. Las transmisiones Ethernet se utilizan para resolver direcciones IP en direcciones MAC (mediante ARP) en la capa de enlace de datos.
¿Qué es una dirección IP?
Una dirección de Protocolo de Internet (dirección IP) es una etiqueta numérica asignada a cada dispositivo conectado a una red informática que utiliza el Protocolo de Internet para la comunicación. Una dirección IP cumple dos funciones principales: identificación de interfaz de red o host y direccionamiento de ubicación.
Explica la máscara de subred y da un ejemplo.
Una máscara de subred es un número de 32 bits que enmascara una dirección IP y divide las direcciones IP en direcciones de red y direcciones de host. La máscara de subred se crea estableciendo los bits de red en "1" y configurando los bits del host en "0". Dentro de una red determinada, del total de direcciones de host utilizables, dos siempre están reservadas para propósitos específicos y no se pueden asignar a ningún host. Estas son la primera dirección, que está reservada como dirección de red (también conocida como ID de red), y la última dirección utilizada para la transmisión de red.
Ejemplo
¿Qué es una dirección IP privada? ¿En qué escenarios/diseños de sistemas se debería utilizar?
Las direcciones IP privadas se asignan a los hosts de la misma red para comunicarse entre sí. Como sugiere el nombre "privado", los dispositivos que tienen direcciones IP privadas asignadas no pueden ser accedidos por dispositivos desde ninguna red externa. Por ejemplo, si vivo en un albergue y quiero que mis compañeros de albergue se unan al servidor de juegos que he alojado, les pediré que se unan a través de la dirección IP privada de mi servidor, ya que la red es local del albergue. ¿Qué es una dirección IP pública? ¿En qué escenarios/diseños de sistemas se debería utilizar?
Una dirección IP pública es una dirección IP pública. En el caso de que esté alojando un servidor de juegos al que desea que se unan sus amigos, les dará a sus amigos su dirección IP pública para permitir que sus computadoras identifiquen y ubiquen su red y servidor para que se realice la conexión. Un momento en el que no necesitarías usar una dirección IP pública es en el caso de que estuvieras jugando con amigos que estuvieran conectados a la misma red que tú, en ese caso, usarías una dirección IP privada. Para que alguien pueda conectarse a su servidor ubicado internamente, deberá configurar un reenvío de puerto para indicarle a su enrutador que permita el tráfico del dominio público a su red y viceversa. Explique el modelo OSI. ¿Qué capas hay? ¿De qué es responsable cada capa?
- Aplicación: extremo del usuario (HTTP está aquí)
- Presentación: establece el contexto entre entidades de la capa de aplicación (el cifrado está aquí)
- Sesión: establece, administra y finaliza las conexiones
- Transporte: transfiere secuencias de datos de longitud variable desde un host de origen a un host de destino (TCP & UDP están aquí)
- Red: transfiere datagramas de una red a otra (IP está aquí)
- Enlace de datos: proporciona un enlace entre dos nodos conectados directamente (MAC está aquí)
- Físico: las especificaciones eléctricas y físicas de la conexión de datos (los bits están aquí). aquí)
Puedes leer más sobre el modelo OSI en penguintutor.com
Para cada uno de los siguientes se determina a qué capa OSI pertenece:- Corrección de errores
- Enrutamiento de paquetes
- Cables y señales eléctricas.
- dirección MAC
- dirección IP
- Terminar conexiones
- apretón de manos de 3 vías
Corrección de errores - Enlace de datos Enrutamiento de paquetes - Red Cables y señales eléctricas - Dirección MAC física - Dirección IP del enlace de datos - Red Terminar conexiones - Sesión Apretón de manos de 3 vías: Transporte ¿Qué esquemas de entrega conoce?
Unicast: comunicación uno a uno donde hay un remitente y un receptor.
Difusión: Envío de un mensaje a todos los miembros de la red. La dirección ff:ff:ff:ff:ff:ff se utiliza para transmisión. Dos protocolos comunes que utilizan transmisión son ARP y DHCP.
Multidifusión: Envío de un mensaje a un grupo de suscriptores. Puede ser uno a muchos o muchos a muchos.
¿Qué es CSMA/CD? ¿Se utiliza en redes ethernet modernas?
CSMA/CD significa Acceso múltiple con detección de portadora/Detección de colisiones. Su objetivo principal es gestionar el acceso a un medio/bus compartido donde sólo un host puede transmitir en un momento determinado.
Algoritmo CSMA/CD:
Antes de enviar una trama, comprueba si otro host ya está transmitiendo una trama.- Si nadie está transmitiendo, comienza a transmitir la trama.
- Si dos hosts transmiten al mismo tiempo, tenemos una colisión.
- Ambos hosts dejan de enviar la trama y envían a todos una 'señal de interferencia' notificando a todos que se produjo una colisión.
- Están esperando un tiempo aleatorio antes de enviarlo nuevamente.
- Una vez que cada host esperó un tiempo aleatorio, intenta enviar la trama nuevamente y el ciclo comienza nuevamente.
Describa los siguientes dispositivos de red y la diferencia entre ellos:
Un enrutador, un conmutador y un concentrador son dispositivos de red que se utilizan para conectar dispositivos en una red de área local (LAN). Sin embargo, cada dispositivo funciona de manera diferente y tiene sus casos de uso específicos. A continuación te dejamos una breve descripción de cada dispositivo y las diferencias entre ellos:
Enrutador: un dispositivo de red que conecta varios segmentos de red entre sí. Opera en la capa de red (Capa 3) del modelo OSI y utiliza protocolos de enrutamiento para dirigir datos entre redes. Los enrutadores utilizan direcciones IP para identificar dispositivos y enrutar paquetes de datos al destino correcto.- Switch: un dispositivo de red que conecta múltiples dispositivos en una LAN. Opera en la capa de enlace de datos (Capa 2) del modelo OSI y utiliza direcciones MAC para identificar dispositivos y dirigir paquetes de datos al destino correcto. Los conmutadores permiten que los dispositivos de la misma red se comuniquen entre sí de manera más eficiente y pueden evitar las colisiones de datos que pueden ocurrir cuando varios dispositivos envían datos simultáneamente.
- Hub: un dispositivo de red que conecta múltiples dispositivos a través de un solo cable y se utiliza para conectar múltiples dispositivos sin segmentar una red. Sin embargo, a diferencia de un conmutador, opera en la capa física (Capa 1) del modelo OSI y simplemente transmite paquetes de datos a todos los dispositivos conectados a él, independientemente de si el dispositivo es el destinatario previsto o no. Esto significa que pueden producirse colisiones de datos y, como resultado, la eficiencia de la red puede verse afectada. Los concentradores generalmente no se utilizan en configuraciones de red modernas, ya que los conmutadores son más eficientes y brindan un mejor rendimiento de la red.
¿Qué es un "dominio de colisión"?
Un dominio de colisión es un segmento de red en el que los dispositivos pueden potencialmente interferir entre sí al intentar transmitir datos al mismo tiempo. Cuando dos dispositivos transmiten datos al mismo tiempo, puede provocar una colisión y provocar la pérdida o corrupción de datos. En un dominio de colisión, todos los dispositivos comparten el mismo ancho de banda y cualquier dispositivo puede interferir potencialmente con la transmisión de datos de otros dispositivos. ¿Qué es un "dominio de transmisión"?
Un dominio de difusión es un segmento de red en el que todos los dispositivos pueden comunicarse entre sí mediante el envío de mensajes de difusión. Un mensaje de difusión es un mensaje que se envía a todos los dispositivos de una red en lugar de a un dispositivo específico. En un dominio de difusión, todos los dispositivos pueden recibir y procesar mensajes de difusión, independientemente de si el mensaje estaba destinado a ellos o no. tres computadoras conectadas a un switch. ¿Cuántos dominios de colisión hay? ¿Cuántos dominios de difusión?
Tres dominios de colisión y un dominio de difusión
¿Cómo funciona un enrutador?
Un enrutador es un dispositivo físico o virtual que pasa información entre dos o más redes informáticas de conmutación de paquetes. Un enrutador inspecciona la dirección de Protocolo de Internet (dirección IP) de destino de un paquete de datos determinado, calcula la mejor manera de llegar a su destino y luego lo reenvía en consecuencia.
¿Qué es NAT?
La traducción de direcciones de red (NAT) es un proceso en el que una o más direcciones IP locales se traducen en una o más direcciones IP globales y viceversa para proporcionar acceso a Internet a los hosts locales.
¿Qué es un apoderado? ¿Cómo funciona? ¿Para qué lo necesitamos?
Un servidor proxy actúa como puerta de enlace entre usted e Internet. Es un servidor intermediario que separa a los usuarios finales de los sitios web que navegan.
Si está utilizando un servidor proxy, el tráfico de Internet fluye a través del servidor proxy en su camino hacia la dirección que solicitó. Luego, la solicitud regresa a través de ese mismo servidor proxy (hay excepciones a esta regla) y luego el servidor proxy le reenvía los datos recibidos del sitio web.
Los servidores proxy brindan distintos niveles de funcionalidad, seguridad y privacidad según su caso de uso, necesidades o política de la empresa.
¿Qué es TCP? ¿Cómo funciona? ¿Qué es el protocolo de enlace de tres vías?
El protocolo de enlace de tres vías TCP o protocolo de enlace de tres vías es un proceso que se utiliza en una red TCP/IP para establecer una conexión entre el servidor y el cliente.
Un protocolo de enlace de tres vías se utiliza principalmente para crear una conexión de socket TCP. Funciona cuando:
Un nodo cliente envía un paquete de datos SYN a través de una red IP a un servidor en la misma red o en una externa. El objetivo de este paquete es preguntar/inferir si el servidor está abierto para nuevas conexiones.- El servidor de destino debe tener puertos abiertos que puedan aceptar e iniciar nuevas conexiones. Cuando el servidor recibe el paquete SYN del nodo cliente, responde y devuelve un recibo de confirmación: el paquete ACK o paquete SYN/ACK.
- El nodo cliente recibe el SYN/ACK del servidor y responde con un paquete ACK.
¿Qué es el retraso de ida y vuelta o el tiempo de ida y vuelta?
De wikipedia: "el tiempo que tarda en enviarse una señal más el tiempo que tarda en recibirse el acuse de recibo de esa señal"
Pregunta adicional: ¿cuál es el RTT de LAN?
¿Cómo funciona un protocolo de enlace SSL?
El protocolo de enlace SSL es un proceso que establece una conexión segura entre un cliente y un servidor. El cliente envía un mensaje Client Hello al servidor, que incluye la versión del cliente del protocolo SSL/TLS, una lista de los algoritmos criptográficos admitidos por el cliente y un valor aleatorio.- El servidor responde con un mensaje de saludo del servidor, que incluye la versión del servidor del protocolo SSL/TLS, un valor aleatorio y un ID de sesión.
- El servidor envía un mensaje de Certificado, que contiene el certificado del servidor.
- El servidor envía un mensaje Server Hello Done, que indica que el servidor ha terminado de enviar mensajes para la fase Server Hello.
- El cliente envía un mensaje de Intercambio de claves de cliente, que contiene la clave pública del cliente.
- El cliente envía un mensaje Cambiar especificación de cifrado, que notifica al servidor que el cliente está a punto de enviar un mensaje cifrado con la nueva especificación de cifrado.
- El cliente envía un mensaje de protocolo de enlace cifrado, que contiene el secreto maestro previo cifrado con la clave pública del servidor.
- El servidor envía un mensaje Cambiar especificación de cifrado, que notifica al cliente que el servidor está a punto de enviar un mensaje cifrado con la nueva especificación de cifrado.
- El servidor envía un mensaje de protocolo de enlace cifrado, que contiene el secreto maestro previo cifrado con la clave pública del cliente.
- El cliente y el servidor ahora pueden intercambiar datos de la aplicación.
¿Cuál es la diferencia entre TCP y UDP?
TCP establece una conexión entre el cliente y el servidor para garantizar el orden de los paquetes, por otro lado, UDP no establece una conexión entre el cliente y el servidor y no maneja pedidos de paquetes. Esto hace que UDP sea más liviano que TCP y un candidato perfecto para servicios como streaming.
Penguintutor.com proporciona una buena explicación.
¿Qué protocolos TCP/IP conoce?
Explicar la "puerta de enlace predeterminada"
Una puerta de enlace predeterminada sirve como punto de acceso o enrutador IP que una computadora en red utiliza para enviar información a una computadora en otra red o a Internet.
¿Qué es ARP? ¿Cómo funciona?
ARP significa Protocolo de resolución de direcciones. Cuando intenta hacer ping a una dirección IP en su red local, digamos 192.168.1.1, su sistema tiene que convertir la dirección IP 192.168.1.1 en una dirección MAC. Esto implica utilizar ARP para resolver la dirección, de ahí su nombre.
Los sistemas mantienen una tabla de búsqueda ARP donde almacenan información sobre qué direcciones IP están asociadas con qué direcciones MAC. Al intentar enviar un paquete a una dirección IP, el sistema primero consultará esta tabla para ver si ya conoce la dirección MAC. Si hay un valor almacenado en caché, no se utiliza ARP.
¿Qué es TTL? ¿Qué ayuda a prevenir?
TTL (Tiempo de vida) es un valor en un paquete IP (Protocolo de Internet) que determina cuántos saltos o enrutadores puede viajar un paquete antes de ser descartado. Cada vez que un enrutador reenvía un paquete, el valor TTL disminuye en uno. Cuando el valor TTL llega a cero, el paquete se descarta y se envía un mensaje ICMP (Protocolo de mensajes de control de Internet) al remitente indicando que el paquete ha caducado.- TTL se utiliza para evitar que los paquetes circulen indefinidamente en la red, lo que puede provocar congestión y degradar el rendimiento de la red.
- También ayuda a evitar que los paquetes queden atrapados en bucles de enrutamiento, donde los paquetes viajan continuamente entre el mismo conjunto de enrutadores sin llegar nunca a su destino.
- Además, TTL se puede utilizar para ayudar a detectar y prevenir ataques de suplantación de IP, en los que un atacante intenta hacerse pasar por otro dispositivo en la red utilizando una dirección IP falsa o falsa. Al limitar la cantidad de saltos que puede viajar un paquete, TTL puede ayudar a evitar que los paquetes se enruten a destinos que no son legítimos.
¿Qué es DHCP? ¿Cómo funciona?
Significa Protocolo de configuración dinámica de host y asigna direcciones IP, máscaras de subred y puertas de enlace a los hosts. Así es como funciona:
- Un host al ingresar a una red transmite un mensaje en busca de un servidor DHCP (DHCP DISCOVER)
- El servidor DHCP devuelve un mensaje de oferta como un paquete que contiene el tiempo de concesión, la máscara de subred, las direcciones IP, etc. (OFERTA DHCP)
- Dependiendo de qué oferta se acepte, el cliente envía una respuesta transmitida para informar a todos los servidores DHCP (DHCP SOLICITUD)
- El servidor envía un acuse de recibo (DHCP ACK)
Leer más aquí
¿Puedes tener dos servidores DHCP en la misma red? ¿Cómo funciona?
Es posible tener dos servidores DHCP en la misma red, sin embargo, no es recomendable y es importante configurarlos cuidadosamente para evitar conflictos y problemas de configuración.
Cuando se configuran dos servidores DHCP en la misma red, existe el riesgo de que ambos servidores asignen direcciones IP y otras configuraciones de red al mismo dispositivo, lo que puede causar conflictos y problemas de conectividad. Además, si los servidores DHCP están configurados con diferentes configuraciones u opciones de red, los dispositivos en la red pueden recibir configuraciones de configuración conflictivas o inconsistentes.- Sin embargo, en algunos casos, puede ser necesario tener dos servidores DHCP en la misma red, como en redes grandes donde es posible que un servidor DHCP no pueda manejar todas las solicitudes. En tales casos, los servidores DHCP se pueden configurar para servir diferentes rangos de direcciones IP o diferentes subredes, de modo que no interfieran entre sí.
¿Qué es el túnel SSL? ¿Cómo funciona?
- El túnel SSL (Secure Sockets Layer) es una técnica que se utiliza para establecer una conexión segura y cifrada entre dos puntos finales a través de una red insegura, como Internet. El túnel SSL se crea encapsulando el tráfico dentro de una conexión SSL, lo que proporciona confidencialidad, integridad y autenticación.
Así es como funciona el túnel SSL:
Un cliente inicia una conexión SSL a un servidor, lo que implica un proceso de protocolo de enlace para establecer la sesión SSL.- Una vez establecida la sesión SSL, el cliente y el servidor negocian los parámetros de cifrado, como el algoritmo de cifrado y la longitud de la clave, y luego intercambian certificados digitales para autenticarse mutuamente.
- Luego, el cliente envía tráfico a través del túnel SSL al servidor, que descifra el tráfico y lo reenvía a su destino.
- El servidor envía tráfico a través del túnel SSL al cliente, que descifra el tráfico y lo reenvía a la aplicación.
¿Qué es un enchufe? ¿Dónde puede ver la lista de sockets en su sistema?
Un socket es un punto final de software que permite la comunicación bidireccional entre procesos a través de una red. Los sockets proporcionan una interfaz estandarizada para la comunicación de red, permitiendo que las aplicaciones envíen y reciban datos a través de una red. Para ver la lista de sockets abiertos en un sistema Linux: netstat -an- Este comando muestra una lista de todos los sockets abiertos, junto con su protocolo, dirección local, dirección extranjera y estado.
¿Qué es IPv6? ¿Por qué deberíamos plantearnos su uso si tenemos IPv4?
- IPv6 (Protocolo de Internet versión 6) es la última versión del Protocolo de Internet (IP), que se utiliza para identificar y comunicarse con dispositivos en una red. Las direcciones IPv6 son direcciones de 128 bits y se expresan en notación hexadecimal, como 2001:0db8:85a3:0000:0000:8a2e:0370:7334.
Hay varias razones por las que deberíamos considerar el uso de IPv6 sobre IPv4:
Espacio de direcciones: IPv4 tiene un espacio de direcciones limitado, que se ha agotado en muchas partes del mundo. IPv6 proporciona un espacio de direcciones mucho mayor, lo que permite billones de direcciones IP únicas.- Seguridad: IPv6 incluye soporte integrado para IPsec, que proporciona cifrado y autenticación de extremo a extremo para el tráfico de red.
- Rendimiento: IPv6 incluye funciones que pueden ayudar a mejorar el rendimiento de la red, como el enrutamiento de multidifusión, que permite enviar un solo paquete a múltiples destinos simultáneamente.
- Configuración de red simplificada: IPv6 incluye funciones que pueden simplificar la configuración de red, como la configuración automática sin estado, que permite a los dispositivos configurar automáticamente sus propias direcciones IPv6 sin la necesidad de un servidor DHCP.
- Mejor soporte de movilidad: IPv6 incluye funciones que pueden mejorar el soporte de movilidad, como Mobile IPv6, que permite a los dispositivos mantener sus direcciones IPv6 mientras se mueven entre diferentes redes.
¿Qué es VLAN?
- Una VLAN (red de área local virtual) es una red lógica que agrupa un conjunto de dispositivos en una red física, independientemente de su ubicación física. Las VLAN se crean configurando conmutadores de red para asignar una ID de VLAN específica a las tramas enviadas por dispositivos conectados a un puerto o grupo de puertos específico en el conmutador.
¿Qué es la MTU?
MTU significa Unidad de transmisión máxima. Es el tamaño de la PDU (Unidad de datos de protocolo) más grande que se puede enviar en una sola transacción.
¿Qué sucede si envía un paquete que es más grande que la MTU?
Con el protocolo IPv4, el enrutador puede fragmentar la PDU y luego enviar todas las PDU fragmentadas a través de la transacción.
Con el protocolo IPv6, genera un error en la computadora del usuario.
¿Verdadero o falso? Ping utiliza UDP porque no le importa la conexión confiable
FALSO. En realidad, Ping utiliza ICMP (Protocolo de mensajes de control de Internet), que es un protocolo de red que se utiliza para enviar mensajes de diagnóstico y mensajes de control relacionados con la comunicación de red.
¿Qué es SDN?
SDN significa Redes definidas por software. Es un enfoque para la gestión de redes que enfatiza la centralización del control de la red, permitiendo a los administradores gestionar el comportamiento de la red a través de una abstracción de software.- En una red tradicional, los dispositivos de red como enrutadores, conmutadores y firewalls se configuran y administran individualmente, utilizando software especializado o interfaces de línea de comandos. Por el contrario, SDN separa el plano de control de la red del plano de datos, lo que permite a los administradores gestionar el comportamiento de la red a través de un controlador de software centralizado.
¿Qué es ICMP? ¿Para qué se utiliza?
- ICMP significa Protocolo de mensajes de control de Internet. Es un protocolo utilizado con fines de diagnóstico y control en redes IP. Es parte del conjunto de Protocolos de Internet y opera en la capa de red.
Los mensajes ICMP se utilizan para diversos fines, entre ellos:
Informe de errores: los mensajes ICMP se utilizan para informar errores que ocurren en la red, como un paquete que no se pudo entregar a su destino.- Ping: ICMP se utiliza para enviar mensajes de ping, que se utilizan para probar si se puede acceder a un host o red y para medir el tiempo de ida y vuelta de los paquetes.
- Descubrimiento de MTU de ruta: ICMP se utiliza para descubrir la Unidad de transmisión máxima (MTU) de una ruta, que es el tamaño de paquete más grande que se puede transmitir sin fragmentación.
- Traceroute: la utilidad traceroute utiliza ICMP para rastrear la ruta que toman los paquetes a través de la red.
- Descubrimiento de enrutadores: ICMP se utiliza para descubrir los enrutadores en una red.
¿Qué es NAT? ¿Cómo funciona?
NAT significa traducción de direcciones de red. Es una forma de asignar varias direcciones privadas locales a una pública antes de transferir la información. Las organizaciones que desean que varios dispositivos empleen una única dirección IP utilizan NAT, al igual que la mayoría de los enrutadores domésticos. Por ejemplo, la IP privada de su computadora podría ser 192.168.1.100, pero su enrutador asigna el tráfico a su IP pública (por ejemplo, 1.1.1.1). Cualquier dispositivo en Internet verá el tráfico proveniente de su IP pública (1.1.1.1) en lugar de su IP privada (192.168.1.100).
¿Qué número de puerto se utiliza en cada uno de los siguientes protocolos?:- SSH
- SMTP
- HTTP
- DNS
- HTTPS
- ftp
- SFTP
SSH - 22- SMTP - 25
- HTTP-80
- DNS - 53
- HTTPS-443
- ftp-21
- SFTP - 22
¿Qué factores afectan el rendimiento de la red?
Varios factores pueden afectar el rendimiento de la red, entre ellos:
Ancho de banda: el ancho de banda disponible de una conexión de red puede afectar significativamente su rendimiento. Las redes con ancho de banda limitado pueden experimentar velocidades de transferencia de datos lentas, alta latencia y poca capacidad de respuesta.- Latencia: La latencia se refiere al retraso que ocurre cuando los datos se transmiten de un punto de una red a otro. Una latencia alta puede provocar un rendimiento lento de la red, especialmente para aplicaciones en tiempo real como videoconferencias y juegos en línea.
- Congestión de la red: cuando demasiados dispositivos utilizan una red al mismo tiempo, puede producirse una congestión de la red, lo que provoca velocidades de transferencia de datos lentas y un rendimiento deficiente de la red.
- Pérdida de paquetes: la pérdida de paquetes ocurre cuando se pierden paquetes de datos durante la transmisión. Esto puede resultar en velocidades de red más lentas y un menor rendimiento general de la red.
- Topología de la red: el diseño físico de una red, incluida la ubicación de conmutadores, enrutadores y otros dispositivos de red, puede afectar el rendimiento de la red.
- Protocolo de red: los diferentes protocolos de red tienen diferentes características de rendimiento, lo que puede afectar el rendimiento de la red. Por ejemplo, TCP es un protocolo confiable que puede garantizar la entrega de datos, pero también puede resultar en un rendimiento más lento debido a la sobrecarga requerida para la verificación y retransmisión de errores.
- Seguridad de la red: las medidas de seguridad, como los firewalls y el cifrado, pueden afectar el rendimiento de la red, especialmente si requieren una potencia de procesamiento significativa o introducen latencia adicional.
- Distancia: la distancia física entre dispositivos en una red puede afectar el rendimiento de la red, especialmente para las redes inalámbricas donde la intensidad de la señal y la interferencia pueden afectar la conectividad y las tasas de transferencia de datos.
¿Qué es APIPA?
APIPA es un conjunto de direcciones IP que se asignan a los dispositivos cuando no se puede acceder al servidor DHCP principal.
¿Qué rango de IP utiliza APIPA?
APIPA utiliza el rango de IP: 169.254.0.1 - 169.254.255.254.
Plano de control y plano de datos
¿A qué se refiere "plano de control"?
El plano de control es una parte de la red que decide cómo enrutar y reenviar paquetes a una ubicación diferente.
¿A qué se refiere "plano de datos"?
El plano de datos es una parte de la red que realmente reenvía los datos/paquetes.
¿A qué se refiere "plano de gestión"?
Se refiere a funciones de seguimiento y gestión.
¿A qué plano (datos, control,...) pertenece la creación de tablas de enrutamiento?
Plano de mando.
Explique el protocolo de árbol de expansión (STP).
¿Qué es la agregación de enlaces? ¿Por qué se usa?
¿Qué es el enrutamiento asimétrico? ¿Cómo afrontarlo?
¿Con qué protocolos de superposición (túnel) está familiarizado?
¿Qué es GRE? ¿Cómo funciona?
¿Qué es VXLAN? ¿Cómo funciona?
¿Qué es SNAT?
Explique OSPF.
OSPF (Abrir primero la ruta más corta) es un protocolo de enrutamiento que se puede implementar en varios tipos de enrutadores. En general, OSPF es compatible con la mayoría de los enrutadores modernos, incluidos los de proveedores como Cisco, Juniper y Huawei. El protocolo está diseñado para funcionar con redes basadas en IP, incluidas IPv4 e IPv6. Además, utiliza un diseño de red jerárquico, donde los enrutadores se agrupan en áreas, y cada área tiene su propio mapa de topología y tabla de enrutamiento. Este diseño ayuda a reducir la cantidad de información de enrutamiento que debe intercambiarse entre enrutadores y mejorar la escalabilidad de la red.
Los 4 tipos de enrutadores OSPF son:
- Enrutador interno
- Enrutadores de frontera de área
- Enrutadores de límites de sistemas autónomos
- Enrutadores troncales
Obtenga más información sobre los tipos de enrutadores OSPF: https://www.educba.com/ospf-router-types/
¿Qué es la latencia?
La latencia es el tiempo que tarda la información en llegar a su destino desde la fuente.
¿Qué es el ancho de banda?
El ancho de banda es la capacidad de un canal de comunicación para medir cuántos datos puede manejar durante un período de tiempo específico. Más ancho de banda implicaría más manejo de tráfico y, por tanto, más transferencia de datos.
¿Qué es el rendimiento?
El rendimiento se refiere a la medición de la cantidad real de datos transferidos durante un cierto período de tiempo a través de cualquier canal de transmisión.
Al realizar una consulta de búsqueda, ¿qué es más importante, la latencia o el rendimiento? ¿Y cómo garantizar que gestionamos la infraestructura global?
Estado latente. Para tener una buena latencia, se debe enviar una consulta de búsqueda al centro de datos más cercano.
Al subir un vídeo, ¿qué es más importante, la latencia o el rendimiento? ¿Y cómo asegurar eso?
Rendimiento. Para tener un buen rendimiento, el flujo de carga debe dirigirse a un enlace infrautilizado.
¿Qué otras consideraciones (excepto la latencia y el rendimiento) existen al reenviar solicitudes?
- Mantener los cachés actualizados (lo que significa que la solicitud podría no reenviarse al centro de datos más cercano)
Explicar la columna vertebral y la hoja
"Spine & Leaf" es una topología de red comúnmente utilizada en entornos de centros de datos para conectar múltiples conmutadores y administrar el tráfico de red de manera eficiente. También se la conoce como arquitectura "espina-hoja" o topología "hoja-espina". Este diseño proporciona un gran ancho de banda, baja latencia y escalabilidad, lo que lo hace ideal para centros de datos modernos que manejan grandes volúmenes de datos y tráfico. Dentro de una red Spine & Leaf existen dos tipos principales de conmutadores:
- Interruptores de columna: Los interruptores de columna son interruptores de alto rendimiento dispuestos en una capa de columna. Estos conmutadores actúan como el núcleo de la red y normalmente están interconectados con cada conmutador hoja. Cada conmutador central está conectado a todos los conmutadores de hoja del centro de datos.
- Conmutadores Leaf: Los conmutadores Leaf están conectados a dispositivos finales como servidores, matrices de almacenamiento y otros equipos de red. Cada interruptor de hoja está conectado a cada interruptor de columna en el centro de datos. Esto crea una conectividad de malla completa y sin bloqueo entre los interruptores de hoja y de columna, lo que garantiza que cualquier interruptor de hoja pueda comunicarse con cualquier otro interruptor de hoja con el máximo rendimiento.
La arquitectura Spine & Leaf se ha vuelto cada vez más popular en los centros de datos debido a su capacidad para manejar las demandas de las aplicaciones modernas de computación en la nube, virtualización y big data, proporcionando una infraestructura de red escalable, confiable y de alto rendimiento.
¿Qué es la congestión de la red? ¿Qué puede causarlo?
La congestión de la red ocurre cuando hay demasiados datos para transmitir en una red y no tiene suficiente capacidad para manejar la demanda.
Esto puede provocar una mayor latencia y pérdida de paquetes. Las causas pueden ser múltiples, como un uso elevado de la red, transferencias de archivos de gran tamaño, malware, problemas de hardware o problemas de diseño de la red.
Para evitar la congestión de la red, es importante monitorear el uso de su red e implementar estrategias para limitar o administrar la demanda.
¿Qué me puede decir sobre el formato de paquete UDP? ¿Qué pasa con el formato del paquete TCP? ¿En qué se diferencia?
¿Qué es el algoritmo de retroceso exponencial? ¿Dónde se usa?
Usando el código Hamming, ¿cuál sería la palabra clave para la siguiente palabra de datos 100111010001101?
00110011110100011101
Dar ejemplos de protocolos que se encuentran en la capa de aplicación.
Protocolo de transferencia de hipertexto (HTTP): utilizado para las páginas web en Internet- Protocolo simple de transferencia de correo (SMTP): transmisión de correo electrónico
- Red de telecomunicaciones - (TELNET): emulación de terminal para permitir que un cliente acceda a un servidor telnet
- Protocolo de transferencia de archivos (FTP): facilita la transferencia de archivos entre dos máquinas cualesquiera
- Sistema de nombres de dominio (DNS): traducción de nombres de dominio
- Protocolo de configuración dinámica de host (DHCP): asigna direcciones IP, máscaras de subred y puertas de enlace a los hosts
- Protocolo simple de administración de red (SNMP): recopila datos sobre dispositivos en la red
Dar ejemplos de protocolos que se encuentran en la capa de red.
Protocolo de Internet (IP): ayuda a enrutar paquetes de una máquina a otra- Protocolo de mensajes de control de Internet (ICMP): permite saber lo que sucede, como mensajes de error e información de depuración.
¿Qué es HSTS?
HTTP Strict Transport Security es una directiva de servidor web que informa a los agentes de usuario y a los navegadores web cómo manejar su conexión a través de un encabezado de respuesta enviado desde el principio y de regreso al navegador. Esto fuerza las conexiones a través del cifrado HTTPS, sin tener en cuenta la llamada de cualquier script para cargar cualquier recurso en ese dominio a través de HTTP. Lea más [aquí](https://www.globalsign.com/en/blog/what-is-hsts-and-how-do-i-use-it#:~:text=HTTP%20Strict%20Transport%20Security %20(HSTS,y%20back%20to%20el%20navegador.)
Red - Varios
¿Qué es Internet? ¿Es lo mismo que la World Wide Web?
Internet se refiere a una red de redes que transfieren enormes cantidades de datos en todo el mundo.
La World Wide Web es una aplicación que se ejecuta en millones de servidores, encima de Internet, a la que se accede a través de lo que se conoce como navegador web.
¿Qué es el ISP?
ISP (Proveedor de servicios de Internet) es el proveedor de la empresa de Internet local.
Sistema operativo
Ejercicios del sistema operativo
| Nombre | Tema | Objetivo e instrucciones | Solución | Comentarios |
|---|
| Horquilla 101 | Tenedor | Enlace | Enlace | |
| Horquilla 102 | Tenedor | Enlace | Enlace | |
Sistema operativo: autoevaluación
¿Qué es un sistema operativo?
Del libro "Sistemas operativos: tres piezas sencillas":
"Responsable de facilitar los programas de ejecutar (incluso permitirle ejecutar muchos a muchos al mismo tiempo), permitiendo que los programas compartan la memoria, permitiendo que los programas interactúen con dispositivos y otras cosas divertidas como esa".
Sistema operativo - Proceso
¿Puedes explicar qué es un proceso?
Un proceso es un programa en ejecución. Un programa es una o más instrucciones y el programa (o proceso) es ejecutado por el sistema operativo.
Si tuviera que diseñar una API para procesos en un sistema operativo, ¿cómo sería esta API?
Apoyaría lo siguiente:
Crear: permitir crear nuevos procesos- Eliminar: deje eliminar/destruir procesos
- Estado: permita verificar el estado del proceso, ya sea en ejecución, detenido, espera, etc.
- Detener: dejar detener un proceso de ejecución
¿Cómo se crea un proceso?
El sistema del sistema operativo está leyendo el código del programa y cualquier datos relevantes adicionales- El código del programa se carga en la memoria o más específicamente, en el espacio de direcciones del proceso.
- La memoria se asigna para la pila del programa (también conocido como pila de tiempo de ejecución). La pila también inicializada por el sistema operativo con datos como argv, argc y parámetros a main ()
- La memoria se asigna para el montón de programa que se requiere para datos asignados dinámicamente como las estructuras de datos vinculadas y tablas hash
- Se realizan tareas de inicialización de E/S, como en sistemas basados en UNIX/Linux, donde cada proceso tiene 3 descriptores de archivos (entrada, salida y error)
- OS está ejecutando el programa, comenzando desde Main ()
¿Verdadero o falso? La carga del programa en la memoria se realiza con entusiasmo (todo a la vez)
FALSO. Era cierto en el pasado, pero los sistemas operativos actuales realizan una carga perezosa, lo que significa que solo las piezas relevantes requeridas para que el proceso se ejecute se cargue primero.
¿Cuáles son los diferentes estados de un proceso?
Ejecutando: está ejecutando instrucciones- Listo: está listo para funcionar, pero por diferentes razones está en espera
- Bloqueado: está esperando que se complete alguna operación, por ejemplo, solicitud de disco de E/S
¿Cuáles son algunas razones para que un proceso se bloquee?
Operaciones de E/S (por ejemplo, lectura de un disco)- Esperando un paquete de una red
¿Qué es la comunicación entre procesos (IPC)?
La comunicación entre procesos (IPC) se refiere a los mecanismos proporcionados por un sistema operativo que permite a los procesos administrar datos compartidos.
¿Qué es el "tiempo compartiendo"?
Incluso cuando se usa un sistema con una CPU física, es posible permitir que varios usuarios trabajen en ella y ejecuten programas. Esto es posible con el tiempo compartido, donde los recursos informáticos se comparten de una manera que parece para el usuario, el sistema tiene múltiples CPU, pero de hecho es simplemente una CPU compartida aplicando multiprogramación y multitarea.
¿Qué es el "espacio compartido"?
Algo lo contrario del tiempo compartido. Mientras que en el tiempo compartir un recurso es utilizado por un tiempo por una entidad y luego el mismo recurso puede ser utilizado por otro recurso, en el espacio compartir el espacio es compartido por múltiples entidades, pero de una manera en la que no se transfiere entre ellos.
Es utilizado por una entidad, hasta que esta entidad decida deshacerse de ella. Tomemos, por ejemplo, almacenamiento. En el almacenamiento, un archivo es suyo, hasta que decida eliminarlo.
¿Qué componente determina qué proceso se ejecuta en un momento dado?
Planificador de la CPU
Sistema operativo - Memoria
¿Qué es la "memoria virtual" y a qué sirve?
La memoria virtual combina la RAM de su computadora con espacio temporal en su disco duro. Cuando RAM se ejecuta bajo, la memoria virtual ayuda a mover datos de RAM a un espacio llamado archivo de paginación. Mover datos al archivo de paginación puede liberar la RAM, para que su computadora pueda completar su trabajo. En general, cuanta más RAM tenga su computadora, más rápido se ejecutan los programas. https://www.minitool.com/lib/virtual-memory.html
¿Qué es la paginación de la demanda?
La paginación de demanda es una técnica de gestión de memoria donde las páginas se cargan en la memoria física solo cuando el proceso accede por un proceso. Optimiza el uso de la memoria cargando páginas a pedido, reduciendo la latencia de inicio y la sobrecarga del espacio. Sin embargo, introduce cierta latencia al acceder a las páginas por primera vez. En general, es un enfoque rentable para gestionar los recursos de memoria en los sistemas operativos.
¿Qué es Copy-On-Write?
Copy-on-write (COW) es un concepto de gestión de recursos, con el objetivo de reducir la copia innecesaria de la información. Es un concepto, que se implementa, por ejemplo, dentro del Syscall de Posix Fork, que crea un proceso duplicado del proceso de llamada. La idea:
Si los recursos se comparten entre 2 o más entidades (por ejemplo, segmentos de memoria compartida entre 2 procesos), los recursos no necesitan ser copiados para cada entidad, sino que cada entidad tiene un permiso de acceso de operación de lectura en el recurso compartido. (Los segmentos compartidos están marcados como de solo lectura) (piense en cada entidad que tenga un puntero a la ubicación del recurso compartido, que puede ser desactivado para leer su valor)- Si una entidad realice una operación de escritura en un recurso compartido, surgiría un problema, ya que el recurso también se cambiaría permanentemente para todas las demás entidades que lo compartan. (Piense en un proceso que modifique algunas variables en la pila, o asigne algunos datos dinámicamente en el montón, estos cambios en el recurso compartido también se aplicarían para todos los demás procesos, este es definitivamente un comportamiento indeseable)
- Como una solución solamente, si una operación de escritura está a punto de realizarse en un recurso compartido, este recurso se copia primero y luego se aplican los cambios.
¿Qué es un núcleo y qué hace?
El kernel es parte del sistema operativo y es responsable de tareas como:
Asignación de memoria- Procesos de programación
- Control de la CPU
¿Verdadero o falso? Algunas piezas del código en el núcleo se cargan en áreas protegidas de la memoria para que las aplicaciones no puedan sobrescribirlas.
Verdadero
¿Qué es Posix?
POSIX (interfaz del sistema operativo portátil) es un conjunto de estándares que definen la interfaz entre un sistema operativo y programas de aplicación similar a UNIX.
Explique qué es semáforo y cuál es su papel en los sistemas operativos.
Un semáforo es un primitivo de sincronización utilizado en los sistemas operativos y la programación concurrente para controlar el acceso a los recursos compartidos. Es un tipo de datos variable o abstracto que actúa como un contador o un mecanismo de señalización para administrar el acceso a los recursos mediante múltiples procesos o hilos.
¿Qué es el caché? ¿Qué es el amortiguador?
Cache: el caché generalmente se usa cuando los procesos están leyendo y escribiendo en el disco para hacer que el proceso sea más rápido, haciendo datos similares utilizados por diferentes programas fácilmente accesibles. Buffer: lugar reservado en RAM, que se utiliza para mantener datos con fines temporales.
Virtualización
¿Qué es la virtualización?
La virtualización utiliza el software para crear una capa de abstracción sobre el hardware de la computadora, que permite que los elementos de hardware de una sola computadora (procesadores, memoria, almacenamiento y más) se dividan en múltiples computadoras virtuales, comúnmente llamadas máquinas virtuales (VM).
¿Qué es un hipervisor?
Red Hat: "Un hipervisor es un software que crea y ejecuta máquinas virtuales (VMS). Un hipervisor, a veces llamado Monitor de máquina virtual (VMM), aísla el sistema operativo y los recursos de Hypervisor de las máquinas virtuales y permite la creación y administración de aquellos Máquinas virtuales ".
Leer más aquí
¿Qué tipos de hipervisores hay?
Hypervisores alojados e hipervisores de metal desnudo.
¿Cuáles son las ventajas y desventajas del hipervisor de metal desnudo sobre un hipervisor alojado?
Debido a tener sus propios controladores y un acceso directo a los componentes de hardware, un hipervisor Baremetal a menudo tendrá un mejor rendimiento junto con la estabilidad y la escalabilidad.
Por otro lado, probablemente habrá cierta limitación con respecto a la carga (cualquiera) de los controladores, por lo que un hipervisor alojado generalmente se beneficiará de tener una mejor compatibilidad de hardware.
¿Qué tipos de virtualización hay?
Funciones de la red de virtualización del sistema operativo Virtualización Virtualización de escritorio
¿Es la contenedores es un tipo de virtualización?
Sí, es una virtualización a nivel de sistema operativo, donde se comparte el núcleo y permite usar múltiples instancias de espacios de usuario aislados.
¿Cómo la introducción de máquinas virtuales cambió la industria y la forma en que se implementaron las aplicaciones?
La introducción de máquinas virtuales permitió a las empresas implementar múltiples aplicaciones comerciales en el mismo hardware, mientras que cada aplicación se separa entre sí de manera segura, donde cada una se ejecuta en su propio sistema operativo separado.
Máquinas virtuales
¿Necesitamos máquinas virtuales en la era de los contenedores? ¿Siguen siendo relevantes?
Sí, las máquinas virtuales siguen siendo relevantes incluso en la era de los contenedores. Si bien los contenedores proporcionan una alternativa liviana y portátil a las máquinas virtuales, tienen ciertas limitaciones. Las máquinas virtuales aún importan porque ofrecen aislamiento y seguridad, pueden ejecutar diferentes sistemas operativos y son buenas para aplicaciones heredadas. Las limitaciones de los contenedores, por ejemplo, comparten el núcleo host.
Prometeo
¿Qué es Prometeo? ¿Cuáles son algunas de las principales características de Prometeo?
Prometheus es un popular kit de herramientas de monitoreo y alerta de sistemas de código abierto, desarrollado originalmente en SoundCloud. Está diseñado para recopilar y almacenar datos de series de tiempo, y para permitir la consulta y el análisis de esos datos utilizando un poderoso lenguaje de consulta llamado PROMQL. Prometeo se usa con frecuencia para monitorear aplicaciones nativas de nube, microservicios y otra infraestructura moderna.
Algunas de las principales características de Prometeo incluyen:
1. Data model: Prometheus uses a flexible data model that allows users to organize and label their time-series data in a way that makes sense for their particular use case. Labels are used to identify different dimensions of the data, such as the source of the data or the environment in which it was collected.
2. Pull-based architecture: Prometheus uses a pull-based model to collect data from targets, meaning that the Prometheus server actively queries its targets for metrics data at regular intervals. This architecture is more scalable and reliable than a push-based model, which would require every target to push data to the server.
3. Time-series database: Prometheus stores all of its data in a time-series database, which allows users to perform queries over time ranges and to aggregate and analyze their data in various ways. The database is optimized for write-heavy workloads, and can handle a high volume of data with low latency.
4. Alerting: Prometheus includes a powerful alerting system that allows users to define rules based on their metrics data and to send alerts when certain conditions are met. Alerts can be sent via email, chat, or other channels, and can be customized to include specific details about the problem.
5. Visualization: Prometheus has a built-in graphing and visualization tool, called PromDash, which allows users to create custom dashboards to monitor their systems and applications. PromDash supports a variety of graph types and visualization options, and can be customized using CSS and JavaScript.
En general, Prometheus es una herramienta poderosa y flexible para monitorear y analizar sistemas y aplicaciones, y se usa ampliamente en la industria para el monitoreo y la observabilidad nativos de la nube.
¿En qué escenarios podría ser mejor no usar Prometeo?
De la documentación de Prometheus: "Si necesita una precisión del 100%, como para la facturación por solicitud".
Describe la arquitectura y los componentes de Prometeo
La arquitectura Prometheus consta de cuatro componentes principales:
1. Prometheus Server: The Prometheus server is responsible for collecting and storing metrics data. It has a simple built-in storage layer that allows it to store time-series data in a time-ordered database.
2. Client Libraries: Prometheus provides a range of client libraries that enable applications to expose their metrics data in a format that can be ingested by the Prometheus server. These libraries are available for a range of programming languages, including Java, Python, and Go.
3. Exporters: Exporters are software components that expose existing metrics from third-party systems and make them available for ingestion by the Prometheus server. Prometheus provides exporters for a range of popular technologies, including MySQL, PostgreSQL, and Apache.
4. Alertmanager: The Alertmanager component is responsible for processing alerts generated by the Prometheus server. It can handle alerts from multiple sources and provides a range of features for deduplicating, grouping, and routing alerts to appropriate channels.
En general, la arquitectura Prometheus está diseñada para ser altamente escalable y resistente. Las bibliotecas de servidor y cliente se pueden implementar de manera distribuida para admitir el monitoreo en entornos a gran escala y altamente dinámicos
¿Puede comparar Prometeo con otras soluciones como InfluxDB, por ejemplo?
En comparación con otras soluciones de monitoreo, como InfluxDB, Prometheus es conocido por su alto rendimiento y escalabilidad. Puede manejar grandes volúmenes de datos y puede integrarse fácilmente con otras herramientas en el ecosistema de monitoreo. InfluxDB, por otro lado, es conocido por su facilidad de uso y simplicidad. Tiene una interfaz fácil de usar y proporciona API fáciles de usar para recopilar y consultar datos.
Otra solución popular, Nagios, es un sistema de monitoreo más tradicional que se basa en un modelo basado en push para recopilar datos. Nagios ha existido durante mucho tiempo y es conocido por su estabilidad y confiabilidad. Sin embargo, en comparación con Prometeo, Nagios carece de algunas de las características más avanzadas, como el modelo de datos multidimensional y el poderoso lenguaje de consulta.
En general, la elección de una solución de monitoreo depende de las necesidades y requisitos específicos de la organización. Si bien Prometheus es una gran opción para el monitoreo y la alerta a gran escala, la InfluxDB puede ser mejor para entornos más pequeños que requieren facilidad de uso y simplicidad. Nagios sigue siendo una opción sólida para las organizaciones que priorizan la estabilidad y la confiabilidad sobre las características avanzadas.
¿Qué es una alerta?
En Prometeo, una alerta es una notificación activada cuando se cumple una condición o umbral específico. Las alertas se pueden configurar para activar cuando ciertas métricas cruzan un cierto umbral o cuando ocurren eventos específicos. Una vez que se activa una alerta, se puede enrutar a varios canales, como correo electrónico, buscapersonas o chat, para notificar a los equipos o personas relevantes para que tomen las medidas apropiadas. Las alertas son un componente crítico de cualquier sistema de monitoreo, ya que permiten a los equipos detectar y responder de manera proactiva a los problemas antes de afectar a los usuarios o causar tiempo de inactividad del sistema. ¿Qué es una instancia? ¿Qué es un trabajo?
En Prometeo, una instancia se refiere a un solo objetivo que se está monitoreando. Por ejemplo, un solo servidor o servicio. Un trabajo es un conjunto de instancias que realizan la misma función, como un conjunto de servidores web que sirven la misma aplicación. Los trabajos le permiten definir y administrar un grupo de objetivos juntos.
En esencia, una instancia es un objetivo individual que Prometheus recolecta métricas de, mientras que un trabajo es una colección de instancias similares que se pueden administrar como grupo.
¿Qué tipos de métricos centrales admiten Prometheus?
Prometheus admite varios tipos de métricas, incluyendo: 1. Counter: A monotonically increasing value used for tracking counts of events or samples. Examples include the number of requests processed or the total number of errors encountered. 2. Gauge: A value that can go up or down, such as CPU usage or memory usage. Unlike counters, gauge values can be arbitrary, meaning they can go up and down based on changes in the system being monitored. 3. Histogram: A set of observations or events that are divided into buckets based on their value. Histograms help in analyzing the distribution of a metric, such as request latencies or response sizes. 4. Summary: A summary is similar to a histogram, but instead of buckets, it provides a set of quantiles for the observed values. Summaries are useful for monitoring the distribution of request latencies or response sizes over time.
Prometheus también admite varias funciones y operadores para agregar y manipular métricas, como Sum, Max, Min y Tarifa. Estas características lo convierten en una herramienta poderosa para monitorear y alertar sobre las métricas del sistema.
¿Qué es un exportador? ¿Para qué se utiliza?
El exportador sirve como un puente entre el sistema de terceros o la aplicación y Prometheus, lo que hace posible que Prometheus monitoree y recopile datos de ese sistema o aplicación. El exportador actúa como un servidor, escuchando en un puerto de red específico para solicitudes de Prometheus para raspar métricos. Recopila métricas del sistema o aplicación de terceros y las transforma en un formato que Prometeo puede entenderse. El exportador expone estas métricas a Prometeo a través de un punto final HTTP, haciéndolas disponibles para la recolección y el análisis.
Los exportadores se usan comúnmente para monitorear varios tipos de componentes de infraestructura, como bases de datos, servidores web y sistemas de almacenamiento. Por ejemplo, hay exportadores disponibles para monitorear bases de datos populares como MySQL y PostgreSQL, así como servidores web como Apache y Nginx.
En general, los exportadores son un componente crítico del ecosistema Prometheus, lo que permite el monitoreo de una amplia gama de sistemas y aplicaciones, y proporciona un alto grado de flexibilidad y extensibilidad a la plataforma.
¿Qué mejores prácticas de Prometheus?
Aquí hay tres de ellos: 1. Label carefully: Careful and consistent labeling of metrics is crucial for effective querying and alerting. Labels should be clear, concise, and include all relevant information about the metric. 2. Keep metrics simple: The metrics exposed by exporters should be simple and focus on a single aspect of the system being monitored. This helps avoid confusion and ensures that the metrics are easily understandable by all members of the team. 3. Use alerting sparingly: While alerting is a powerful feature of Prometheus, it should be used sparingly and only for the most critical issues. Setting up too many alerts can lead to alert fatigue and result in important alerts being ignored. It is recommended to set up only the most important alerts and adjust the thresholds over time based on the actual frequency of alerts.
¿Cómo obtener solicitudes totales en un período de tiempo determinado?
Para obtener las solicitudes totales en un período de tiempo determinado utilizando Prometheus, puede usar la función * sum * junto con la función * tasa *. Aquí hay una consulta de ejemplo que le dará el número total de solicitudes en la última hora: sum(rate(http_requests_total[1h]))
En esta consulta, http_requests_total es el nombre de la métrica que rastrea el número total de solicitudes HTTP, y la función de tasa calcula la tasa de solicitudes por segundo durante la última hora. La función de suma luego suma todas las solicitudes para brindarle el número total de solicitudes en la última hora.
Puede ajustar el rango de tiempo cambiando la duración en la función de velocidad . Por ejemplo, si desea obtener el número total de solicitudes en el último día, podría cambiar la función a la calificación (http_requests_total [1D]) .
¿Qué significa en Prometeo?
HA significa alta disponibilidad. Esto significa que el sistema está diseñado para ser altamente confiable y siempre disponible, incluso ante fallas u otros problemas. En la práctica, esto generalmente implica establecer múltiples instancias de Prometeo y garantizar que todos estén sincronizados y capaces de trabajar juntos sin problemas. Esto se puede lograr a través de una variedad de técnicas, como el equilibrio de carga, la replicación y los mecanismos de conmutación por error. Al implementar HA en Prometeo, los usuarios pueden asegurarse de que sus datos de monitoreo siempre estén disponibles y están actualizados, incluso frente a fallas de hardware o software, problemas de red u otros problemas que de otro modo podrían causar tiempo de inactividad o pérdida de datos.
¿Cómo te unes a dos métricas?
En Prometeo, unir dos métricas se pueden lograr utilizando la función * Join () *. La función * Join () * combina dos o más series de tiempo basadas en los valores de sus etiquetas. Se necesitan dos argumentos obligatorios: *en *y *tabla *. El argumento ON especifica las etiquetas para unirse * en * y el argumento * Tabla * especifica la serie de tiempo para unirse. Aquí hay un ejemplo de cómo unir dos métricas usando la función Join () :
sum_series(
join(
on(service, instance) request_count_total,
on(service, instance) error_count_total,
)
)
En este ejemplo, la función Join () combina la serie de tiempo request_count_total y ERROR_COUNT_TOTAL basada en sus valores de etiqueta de servicio e instancia . La función Sum_Series () luego calcula la suma de la serie temporal resultante
¿Cómo escribir una consulta que devuelva el valor de una etiqueta?
Para escribir una consulta que devuelva el valor de una etiqueta en Prometheus, puede usar la función * etiqueta_values *. La función * etiqueta_values * toma dos argumentos: el nombre de la etiqueta y el nombre de la métrica. Por ejemplo, si tiene una métrica llamada http_requests_total con una etiqueta llamada método , y desea devolver todos los valores de la etiqueta del método , puede usar la siguiente consulta:
label_values(http_requests_total, method)
Esto devolverá una lista de todos los valores para la etiqueta del método en la métrica http_requests_total . Luego puede usar esta lista en consultas adicionales o para filtrar sus datos.
¿Cómo se convierte CPU_USER_SECONDS en uso de CPU en porcentaje?
Para convertir * CPU_USER_SECONDS * en uso de CPU en porcentaje, debe dividirlo por el tiempo total transcurrido y el número de núcleos de CPU, y luego multiplicar por 100. La fórmula es la siguiente: 100 * sum(rate(process_cpu_user_seconds_total{job="<job-name>"}[<time-period>])) by (instance) / (<time-period> * <num-cpu-cores>)
Aquí, es el nombre del trabajo que desea consultar, es el rango de tiempo que desea consultar (por ejemplo, 5m , 1h ) y es el número de núcleos de CPU en la máquina que está consultando.
Por ejemplo, para obtener el uso de la CPU en porcentaje durante los últimos 5 minutos para un trabajo llamado My-Job que se ejecuta en una máquina con 4 núcleos de CPU, puede usar la siguiente consulta:
100 * sum(rate(process_cpu_user_seconds_total{job="my-job"}[5m])) by (instance) / (5m * 4)
Ir
¿Cuáles son algunas características del lenguaje de programación GO?
Tipo de mecanografía fuerte y estática: el - tipo
de variables no - se
- puede cambiar con el tiempo y deben definirse en el tiempo de compilación
- Simplicidad
- rápida
- Compilación
- Tiempos
- se compilará en un binario. Muy útil para la gestión de versiones en tiempo de ejecución.
Go también tiene una buena comunidad.
¿Cuál es la diferencia entre var x int = 2 y x := 2 ?
El resultado es el mismo, una variable con el valor 2.
Con var x int = 2 estamos configurando el tipo de variable en entero mientras que con x := 2 estamos dejando ir por sí solo el tipo.
¿Verdadero o falso? En Go podemos redeclare las variables y una vez declaramos que debemos usarlo.
FALSO. No podemos redeclare las variables, pero sí, debemos usar variables declaradas.
¿Qué bibliotecas de GO has usado?
Esto debe responderse según su uso, pero algunos ejemplos son:
¿Cuál es el problema con el siguiente bloque de código? ¿Cómo solucionarlo? func main() {
var x float32 = 13.5
var y int
y = x
}
El siguiente bloque de código intenta convertir el entero 101 en una cadena, pero en su lugar obtenemos "E". ¿Porqué es eso? ¿Cómo solucionarlo? package main
import "fmt"
func main () {
var x int = 101
var y string
y = string ( x )
fmt . Println ( y )
}
Parece que el valor de Unicode se establece en 101 y lo usa para convertir el entero en una cadena. Si desea obtener "101", debe usar el paquete "strconv" y reemplazar y = string(x) con y = strconv.Itoa(x)
¿Qué pasa con el siguiente código?: package main
func main() {
var x = 2
var y = 3
const someConst = x + y
}
Las constantes en GO solo pueden declararse utilizando expresiones constantes. Pero x , y y su suma son variables.
const initializer x + y is not a constant
¿Cuál será la salida del siguiente bloque de código?: package main
import "fmt"
const (
x = iota
y = iota
)
const z = iota
func main () {
fmt . Printf ( "%v n " , x )
fmt . Printf ( "%v n " , y )
fmt . Printf ( "%v n " , z )
}
El identificador IOTA de GO se usa en declaraciones constante para simplificar las definiciones de números de incremento. Debido a que se puede usar en expresiones, proporciona una generalidad más allá de la de enumeraciones simples.
x e y en el primer grupo IOTA, z en el segundo.
Página de IOTA en Go Wiki
¿Para qué se usa en GO?
Evita tener que declarar todas las variables para los valores de devoluciones. Se llama identificador en blanco.
respuesta en
¿Cuál será la salida del siguiente bloque de código?: package main
import "fmt"
const (
_ = iota + 3
x
)
func main () {
fmt . Printf ( "%v n " , x )
}
Dado que el primer iota se declara con el valor 3 ( + 3 ), el siguiente tiene el valor 4
¿Cuál será la salida del siguiente bloque de código?: package main
import (
"fmt"
"sync"
"time"
)
func main () {
var wg sync. WaitGroup
wg . Add ( 1 )
go func () {
time . Sleep ( time . Second * 2 )
fmt . Println ( "1" )
wg . Done ()
}()
go func () {
fmt . Println ( "2" )
}()
wg . Wait ()
fmt . Println ( "3" )
}
Salida: 2 1 3
ARITCLE ABCELO SYNC/WAITGROUP
Sincronización del paquete de golang
¿Cuál será la salida del siguiente bloque de código?: package main
import (
"fmt"
)
func mod1 ( a [] int ) {
for i := range a {
a [ i ] = 5
}
fmt . Println ( "1:" , a )
}
func mod2 ( a [] int ) {
a = append ( a , 125 ) // !
for i := range a {
a [ i ] = 5
}
fmt . Println ( "2:" , a )
}
func main () {
s1 := [] int { 1 , 2 , 3 , 4 }
mod1 ( s1 )
fmt . Println ( "1:" , s1 )
s2 := [] int { 1 , 2 , 3 , 4 }
mod2 ( s2 )
fmt . Println ( "2:" , s2 )
}
Producción:
1 [5 5 5 5]
1 [5 5 5 5]
2 [5 5 5 5 5]
2 [1 2 3 4]
En mod1 A es el enlace, y cuando estamos usando a[i] , estamos cambiando el valor s1 a. Pero en mod2 , append crea una nueva porción, y estamos cambiando solo a valor, no s2 .
Aritcle sobre matrices, publicación de blog sobre append
¿Cuál será la salida del siguiente bloque de código?: package main
import (
"container/heap"
"fmt"
)
// An IntHeap is a min-heap of ints.
type IntHeap [] int
func ( h IntHeap ) Len () int { return len ( h ) }
func ( h IntHeap ) Less ( i , j int ) bool { return h [ i ] < h [ j ] }
func ( h IntHeap ) Swap ( i , j int ) { h [ i ], h [ j ] = h [ j ], h [ i ] }
func ( h * IntHeap ) Push ( x interface {}) {
// Push and Pop use pointer receivers because they modify the slice's length,
// not just its contents.
* h = append ( * h , x .( int ))
}
func ( h * IntHeap ) Pop () interface {} {
old := * h
n := len ( old )
x := old [ n - 1 ]
* h = old [ 0 : n - 1 ]
return x
}
func main () {
h := & IntHeap { 4 , 8 , 3 , 6 }
heap . Init ( h )
heap . Push ( h , 7 )
fmt . Println (( * h )[ 0 ])
}
Salida: 3
Paquete de contenedor/montón de Golang
mongo
¿Cuáles son las ventajas de MongoDB? O en otras palabras, ¿por qué elegir MongoDB y no otra implementación de NoSQL?
Las ventajas de MongoDB son las siguientes:
- Esquema
- Fácil de escalar
- No se unen a un complejo
- La estructura de un solo objeto es clara
¿Cuál es la diferencia entre SQL y NoSQL?
La principal diferencia es que las bases de datos SQL están estructuradas (los datos se almacenan en forma de tablas con filas y columnas, como una tabla de hoja de cálculo de Excel) mientras que NoSQL no se estructuró, y el almacenamiento de datos puede variar según cómo se configura el DB NoSQL, tales como par de valor clave, orientado a documentos, etc.
¿En qué escenarios preferirías usar NoSQL/Mongo sobre SQL?
Datos heterogéneos que cambian a menudo- La consistencia e integridad de los datos no es la prioridad
- Mejor si la base de datos necesita escalar rápidamente
¿Qué es un documento? ¿Qué es una colección?
Un documento es un registro en MongoDB, que se almacena en formato BSON (Binario JSON) y es la unidad básica de datos en MongoDB.- Una colección es un grupo de documentos relacionados almacenados en una sola base de datos en MongoDB.
¿Qué es un agregador?
- Un agregador es un marco en MongoDB que realiza operaciones en un conjunto de datos para devolver un solo resultado calculado.
¿Qué es mejor? ¿Documentos incrustados o referenciados?
- No hay una respuesta definitiva a cuál es mejor, depende del caso de uso específico y los requisitos. Algunas explicaciones: los documentos integrados proporcionan actualizaciones atómicas, mientras que los documentos referenciados permiten una mejor normalización.
¿Ha realizado optimizaciones de recuperación de datos en Mongo? Si no es así, ¿puede pensar en formas de optimizar una recuperación de datos lento?
- Algunas formas de optimizar la recuperación de datos en MongoDB son: indexación, diseño de esquema adecuado, optimización de consultas y equilibrio de carga de base de datos.
Consultas
Explique esta consulta: db.books.find({"name": /abc/})
Explique esta consulta: db.books.find().sort({x:1})
¿Cuál es la diferencia entre find () y find_one ()?
find() Devuelve todos los documentos que coinciden con las condiciones de consulta.- find_one () Devuelve solo un documento que coincide con las condiciones de consulta (o NULL si no se encuentra ninguna coincidencia).
¿Cómo puede exportar datos de Mongo DB?
mongoExport- lenguajes de programación
SQL
Ejercicios SQL
| Nombre | Tema | Objetivo e instrucciones | Solución | Comentarios |
|---|
| Funciones versus comparaciones | Mejoras de consulta | Ejercicio | Solución | |
Auto evaluación de SQL
¿Qué es SQL?
SQL (lenguaje de consulta estructurado) es un lenguaje estándar para bases de datos relacionales (como MySQL, Mariadb, ...).
Se usa para leer, actualizar, eliminar y crear datos en una base de datos relacional.
¿En qué se diferencia SQL de NoSQL?
La principal diferencia es que las bases de datos SQL están estructuradas (los datos se almacenan en forma de tablas con filas y columnas, como una tabla de hoja de cálculo de Excel) mientras que NoSQL no se estructuró, y el almacenamiento de datos puede variar según cómo se configura el DB NoSQL, tales como par de valor clave, orientado a documentos, etc.
¿Cuándo es mejor usar SQL? Nosql?
SQL: se usa mejor cuando la integridad de los datos es crucial. SQL generalmente se implementa con muchas empresas y áreas dentro del campo de finanzas debido a su cumplimiento ácido.
NoSQL: excelente si necesita escalar las cosas rápidamente. NoSQL fue diseñado teniendo en cuenta las aplicaciones web, por lo que funciona muy bien si necesita difundir rápidamente la misma información a múltiples servidores
Además, dado que NoSQL no se adhiere a la tabla estricta con columnas y estructura de filas que requieren las bases de datos relacionales, puede almacenar diferentes tipos de datos juntos.
SQL práctico - Conceptos básicos
Para estas preguntas, utilizaremos las tablas de clientes y pedidos que se muestran a continuación:
Clientes
| Cliente_id | Nombre de cliente | Items_in_cart | Cash_spent_to_date |
|---|
| 100204 | Juan Smith | 0 | 20.00 |
| 100205 | fulana | 3 | 40.00 |
| 100206 | Bobby Frank | 1 | 100.20 |
PEDIDOS
| Cliente_id | Orden_id | Artículo | Precio | Date_sold |
|---|
| 100206 | A123 | patito de goma | 2.20 | 2019-09-18 |
| 100206 | A123 | Baño de burbujas | 8.00 | 2019-09-18 |
| 100206 | Q987 | TP de paquete de 80 | 90.00 | 2019-09-20 |
| 100205 | Z001 | Comida para gatos - pescado de atún | 10.00 | 2019-08-05 |
| 100205 | Z001 | Comida de gato - pollo | 10.00 | 2019-08-05 |
| 100205 | Z001 | Comida para gatos - carne de res | 10.00 | 2019-08-05 |
| 100205 | Z001 | Cat Food - Kitty Quesadilla | 10.00 | 2019-08-05 |
| 100204 | X202 | Café | 20.00 | 2019-04-29 |
¿Cómo seleccionaría todos los campos de esta tabla?
Seleccionar *
De los clientes;
¿Cuántos artículos hay en el carro de John?
Seleccione elementos_in_cart
De clientes
Donde customer_name = "John Smith";
¿Cuál es la suma de todo el efectivo gastado en todos los clientes?
Seleccione SUM (Cash_spent_to_date) como Sum_Cash
De los clientes;
¿Cuántas personas tienen artículos en su carrito?
Seleccione Count (1) como Number_of_people_w_items
De clientes
donde items_in_cart> 0;
¿Cómo se uniría a la tabla de clientes a la tabla de pedidos?
Te unirías a ellos en la clave única. En este caso, la clave única es customer_id en la tabla de la tabla y los pedidos de los clientes
¿Cómo mostraría qué cliente ordenó qué artículos?
Seleccione C.Customer_Name, O.Item
De los clientes c
Izquierda unir órdenes o
En c.customer_id = o.customer_id;
Usando una declaración con una declaración, ¿cómo mostraría quién ordenó la comida para gatos y la cantidad total de dinero gastado?
con cat_food como (
Seleccione Customer_id, suma (precio) como Total_Price
De las órdenes
Donde artículo como "%de alimentos para gatos%"
Grupo por Customer_ID
)
Seleccione Customer_Name, Total_Price
De los clientes c
Inner Unirse Cat_food F
En c.customer_id = f.customer_id
donde c.customer_id in (seleccione Customer_id de CAT_FOOD);
Aunque esta era una declaración simple, la cláusula "con" realmente brilla cuando una consulta compleja debe ejecutarse en una mesa antes de unirse a otra. Con declaraciones son buenas, porque creas una pseudo temperatura al ejecutar tu consulta, en lugar de crear una tabla completamente nueva.
La suma de todas las compras de alimentos para gatos no estaba fácilmente disponible, por lo que utilizamos una declaración con la declaración para crear la pseudo tabla para recuperar la suma de los precios gastados por cada cliente, luego unirse a la tabla normalmente.
¿Cuál de las siguientes consultas usaría? SELECT count(*) SELECT count(*)
FROM shawarma_purchases FROM shawarma_purchases
WHERE vs. WHERE
YEAR(purchased_at) == '2017' purchased_at >= '2017-01-01' AND
purchased_at <= '2017-31-12'
SELECT count(*) FROM shawarma_purchases WHERE purchased_at >= '2017-01-01' AND purchased_at <= '2017-31-12'
Cuando usa una función ( YEAR(purchased_at) ) tiene que escanear toda la base de datos en lugar de usar índices y básicamente la columna tal como está, en su estado natural.
pila abierta
¿Con qué componentes/proyectos de OpenStack está familiarizado?
¿Puedes decirme de qué es responsable cada uno de los siguientes servicios/proyectos?:- Estrella nueva
- Neutrón
- Ceniza
- Mirada
- Piedra clave
Nova - Administrar instancias virtuales- Neutrones: administrar redes proporcionando red como servicio (NAAS)
- Cinder - almacenamiento de bloques
- Glance: administrar imágenes para máquinas y contenedores virtuales (buscar, obtener y registrarse)
- Keystone - Servicio de autenticación en toda la nube
Identifique el servicio/proyecto utilizado para cada uno de los siguientes:- Copias o instancias de instantáneas
- GUI para ver y modificar recursos
- Almacenamiento de bloques
- Administrar instancias virtuales
Glance - Servicio de imágenes. También se usa para copiar o instancias de instantáneas- Horizon - GUI para ver y modificar recursos
- Cinder - almacenamiento de bloques
- Nova - Administrar instancias virtuales
¿Qué es un inquilino/proyecto?
Determinar verdadero o falso:- OpenStack es gratuito de usar
- El servicio responsable de las redes es un vistazo
- El propósito del inquilino/proyecto es compartir recursos entre diferentes proyectos y usuarios de OpenStack
Describa en detalle cómo menciona una instancia con una IP flotante
Recibes una llamada de un cliente que dice: "Puedo hacer ping a mi instancia pero no puedo conectarla (SSH)". ¿Cuál podría ser el problema?
¿Qué tipos de redes OpenStack admite?
¿Cómo depuggas los problemas de almacenamiento de OpenStack? (Herramientas, registros, ...)
¿Cómo debuges los problemas de cómputo de OpenStack? (Herramientas, registros, ...)
Despliegue de OpenStack y triple
¿Ha implementado OpenStack en el pasado? En caso afirmativo, ¿puedes describir cómo lo hiciste?
¿Estás familiarizado con Tripleo? ¿Cómo es diferente de Devstack o Packstack?
Puedes leer sobre triple aquí
OpenStack Compute
¿Puedes describir a Nova en detalle?
Se utiliza para aprovisionar y administrar instancias virtuales- Admite múltiples tenientes en diferentes niveles: registro, control de usuario final, auditoría, etc.
- Altamente escalable
- La autenticación se puede hacer utilizando el sistema interno o LDAP
- Admite múltiples tipos de almacenamiento de bloques
- Intenta ser hardware e hipervisor agnostice
¿Qué sabes sobre la arquitectura y los componentes de Nova?
Nova -API: el servidor que sirve metadatos y compute API- Los diferentes componentes de Nova se comunican mediante el uso de una cola (RabbitMQ generalmente) y una base de datos
- Nova-Scheduler inspecciona una solicitud para crear una instancia que determine dónde se creará y se ejecutará la instancia
- Nova-Compute es el componente responsable de comunicarse con el hipervisor para crear la instancia y administrar su ciclo de vida
Networking OpenStack (neutrón)
Explica al neutrón en detalle
Uno de los componentes centrales de OpenStack y un proyecto independiente- Neutrones se centró en entregar redes como servicio
- Con Neutron, los usuarios pueden configurar redes en la nube y configurar y administrar una variedad de servicios de red
- El neutrón interactúa con:
Keystone - Autorizar llamadas de API
- Nova - Nova se comunica con neutrones para enchufar las NIC a una red
- Horizon: admite entidades de red en el tablero y también proporciona una vista de topología que incluye detalles de redes
Explique cada uno de los siguientes componentes:- neutrón-dhcp-agente
- neutrón-l3-agente
- agente de metro de neutrones
- Neutrones-*-Agtent
- servidor de neutrones
Neutron-L3-Agent-Reenvío L3/NAT (proporciona acceso de red externo para máquinas virtuales, por ejemplo)- Neutron-DHCP-agent-Servicios DHCP
- agente de metro de neutrones-medición de tráfico L3
- Neutron-*-Agtent-administra la configuración de Vswitch local en cada cómputo (basado en el complemento elegido)
- servidor de neutrones: expone la API de red y pasa las solicitudes a otros complementos si es necesario
Explique estos tipos de red:- Red de gestión
- Red de invitados
- Red API
- Red externa
Red de gestión: se utiliza para la comunicación interna entre los componentes de OpenStack. Cualquier dirección IP en esta red solo es accesible dentro del DataCetner- Red de invitados: utilizado para la comunicación entre instancias/máquinas virtuales
- Red API: utilizado para la comunicación de API de servicios. Cualquier dirección IP en esta red es accesible públicamente
- Red externa: utilizada para la comunicación pública. Cualquier persona en Internet accede a cualquier dirección IP en esta red en Internet
¿En qué orden debe eliminar las siguientes entidades:- Red
- Puerto
- Enrutador
- Subred
- Red
- de enrutador de
- subred
- de puertos
Hay muchas razones para eso. Uno, por ejemplo: no puede eliminar el enrutador si hay puertos activos asignados a él.
¿Qué es una red de proveedores?
¿Qué componentes y servicios existen para L2 y L3?
¿Cuál es el complemento ML2? Explicar su arquitectura
¿Qué es el agente L2? ¿Cómo funciona y de qué es responsable?
¿Qué es el agente L3? ¿Cómo funciona y de qué es responsable?
Explicar de qué es responsable el agente de metadatos
¿Qué entidades de redes respaldan el neutrón?
¿Cómo debuges los problemas de networking de OpenStack? (Herramientas, registros, ...)
OpenStack - Glance
Explicar la mirada en detalle
Glance es el servicio de imagen OpenStack- Maneja solicitudes relacionadas con discos e imágenes de instancias
- Glance también se usa para crear instantáneas para copias de seguridad de instancias rápidas
- Los usuarios pueden usar una mirada para crear nuevas imágenes o cargar las existentes
Describe la arquitectura de miradas
Glance -API: responsable del manejo de llamadas de API de imagen, como recuperación y almacenamiento. It consists of two APIs: 1. registry-api - responsible for internal requests 2. user API - can be accessed publicly- glance-registry - responsible for handling image metadata requests (eg size, type, etc). This component is private which means it's not available publicly
- metadata definition service - API for custom metadata
- database - for storing images metadata
- image repository - for storing images. This can be a filesystem, swift object storage, HTTP, etc.
OpenStack - Swift
Explain Swift in detail
Swift is Object Store service and is an highly available, distributed and consistent store designed for storing a lot of data- Swift is distributing data across multiple servers while writing it to multiple disks
- One can choose to add additional servers to scale the cluster. All while swift maintaining integrity of the information and data replications.
Can users store by default an object of 100GB in size?
Not by default. Object Storage API limits the maximum to 5GB per object but it can be adjusted.
Explain the following in regards to Swift:
Container - Defines a namespace for objects.- Account - Defines a namespace for containers
- Object - Data content (eg image, document, ...)
¿Verdadero o falso? there can be two objects with the same name in the same container but not in two different containers
FALSO. Two objects can have the same name if they are in different containers.
OpenStack - Cinder
Explain Cinder in detail
Cinder is OpenStack Block Storage service- It basically provides used with storage resources they can consume with other services such as Nova
- One of the most used implementations of storage supported by Cinder is LVM
- From user perspective this is transparent which means the user doesn't know where, behind the scenes, the storage is located or what type of storage is used
Describe Cinder's components
cinder-api - receives API requests- cinder-volume - manages attached block devices
- cinder-scheduler - responsible for storing volumes
OpenStack - Keystone
Can you describe the following concepts in regards to Keystone?- Role
- Tenant/Project
- Servicio
- Punto final
- Simbólico
Role - A list of rights and privileges determining what a user or a project can perform- Tenant/Project - Logical representation of a group of resources isolated from other groups of resources. It can be an account, organization, ...
- Service - An endpoint which the user can use for accessing different resources
- Endpoint - a network address which can be used to access a certain OpenStack service
- Token - Used for access resources while describing which resources can be accessed by using a scope
What are the properties of a service? In other words, how a service is identified?
Usando:
Nombre- número de identificación
- Tipo
- Descripción
Explain the following: - PublicURL - InternalURL - AdminURL
PublicURL - Publicly accessible through public internet- InternalURL - Used for communication between services
- AdminURL - Used for administrative management
What is a service catalog?
A list of services and their endpoints
OpenStack Advanced - Services
Describe each of the following services- Rápido
- Sáhara
- Irónico
- tesoro
- Aodh
- Ceilometer
Swift - highly available, distributed, eventually consistent object/blob store- Sahara - Manage Hadoop Clusters
- Ironic - Bare Metal Provisioning
- Trove - Database as a service that runs on OpenStack
- Aodh - Alarms Service
- Ceilometer - Track and monitor usage
Identify the service/project used for each of the following:- Database as a service which runs on OpenStack
- Bare Metal Provisioning
- Track and monitor usage
- Alarms Service
- Manage Hadoop Clusters
- highly available, distributed, eventually consistent object/blob store
Database as a service which runs on OpenStack - Trove- Bare Metal Provisioning - Ironic
- Track and monitor usage - Ceilometer
- Alarms Service - Aodh
- Manage Hadoop Clusters
- Manage Hadoop Clusters - Sahara
- highly available, distributed, eventually consistent object/blob store - Swift
OpenStack Advanced - Keystone
Can you describe Keystone service in detail?
You can't have OpenStack deployed without Keystone- It Provides identity, policy and token services
- The authentication provided is for both users and services
- The authorization supported is token-based and user-based.
- There is a policy defined based on RBAC stored in a JSON file and each line in that file defines the level of access to apply
Describe Keystone architecture
There is a service API and admin API through which Keystone gets requests- Keystone has four backends:
- Token Backend - Temporary Tokens for users and services
- Policy Backend - Rules management and authorization
- Identity Backend - users and groups (either standalone DB, LDAP, ...)
- Catalog Backend - Endpoints
- It has pluggable environment where you can integrate with:
- KVS (Key Value Store)
- SQL
- PAM
- Memcached
Describe the Keystone authentication process
Keystone gets a call/request and checks whether it's from an authorized user, using username, password and authURL- Once confirmed, Keystone provides a token.
- A token contains a list of user's projects so there is no to authenticate every time and a token can submitted instead
OpenStack Advanced - Compute (Nova)
What each of the following does?:- nova-api
- nova-compuate
- nova-conductor
- nova-cert
- nova-consoleauth
- nova-scheduler
nova-api - responsible for managing requests/calls- nova-compute - responsible for managing instance lifecycle
- nova-conductor - Mediates between nova-compute and the database so nova-compute doesn't access it directly
What types of Nova proxies are you familiar with?
Nova-novncproxy - Access through VNC connections- Nova-spicehtml5proxy - Access through SPICE
- Nova-xvpvncproxy - Access through a VNC connection
OpenStack Advanced - Networking (Neutron)
Explain BGP dynamic routing
What is the role of network namespaces in OpenStack?
OpenStack Advanced - Horizon
Can you describe Horizon in detail?
Django-based project focusing on providing an OpenStack dashboard and the ability to create additional customized dashboards- You can use it to access the different OpenStack services resources - instances, images, networks, ...
- By accessing the dashboard, users can use it to list, create, remove and modify the different resources
- It's also highly customizable and you can modify or add to it based on your needs
What can you tell about Horizon architecture?
API is backward compatible- There are three type of dashboards: user, system and settings
- It provides core support for all OpenStack core projects such as Neutron, Nova, etc. (out of the box, no need to install extra packages or plugins)
- Anyone can extend the dashboards and add new components
- Horizon provides templates and core classes from which one can build its own dashboard
Marioneta
What is Puppet? How does it works?
- Puppet is a configuration management tool ensuring that all systems are configured to a desired and predictable state.
Explain Puppet architecture
- Puppet has a primary-secondary node architecture. The clients are distributed across the network and communicate with the primary-secondary environment where Puppet modules are present. The client agent sends a certificate with its ID to the server; the server then signs that certificate and sends it back to the client. This authentication allows for secure and verifiable communication between the client and the master.
Can you compare Puppet to other configuration management tools? Why did you chose to use Puppet?
- Puppet is often compared to other configuration management tools like Chef, Ansible, SaltStack, and cfengine. The choice to use Puppet often depends on an organization's needs, such as ease of use, scalability, and community support.
Explain the following:
Modules - are a collection of manifests, templates, and files- Manifests - are the actual codes for configuring the clients
- Node - allows you to assign specific configurations to specific nodes
Explain Facter
- Facter is a standalone tool in Puppet that collects information about a system and its configuration, such as the operating system, IP addresses, memory, and network interfaces. This information can be used in Puppet manifests to make decisions about how resources should be managed, and to customize the behavior of Puppet based on the characteristics of the system. Facter is integrated into Puppet, and its facts can be used within Puppet manifests to make decisions about resource management.
What is MCollective?
- MCollective is a middleware system that integrates with Puppet to provide orchestration, remote execution, and parallel job execution capabilities.
Do you have experience with writing modules? Which module have you created and for what?
Explain what is Hiera
- Hiera is a hierarchical data store in Puppet that is used to separate data from code, allowing data to be more easily separated, managed, and reused.
Elástico
What is the Elastic Stack?
The Elastic Stack consists of:
- Búsqueda elástica
- Kibana
- Logstash
- Latidos
- Elastic Hadoop
- APM Server
Elasticsearch, Logstash and Kibana are also known as the ELK stack.
Explain what is Elasticsearch
From the official docs:
"Elasticsearch is a distributed document store. Instead of storing information as rows of columnar data, Elasticsearch stores complex data structures that have been serialized as JSON documents"
What is Logstash?
From the blog:
"Logstash is a powerful, flexible pipeline that collects, enriches and transports data. It works as an extract, transform & load (ETL) tool for collecting log messages."
Explain what beats are
Beats are lightweight data shippers. These data shippers installed on the client where the data resides. Examples of beats: Filebeat, Metricbeat, Auditbeat. There are much more.
What is Kibana?
From the official docs:
"Kibana is an open source analytics and visualization platform designed to work with Elasticsearch. You use Kibana to search, view, and interact with data stored in Elasticsearch indices. You can easily perform advanced data analysis and visualize your data in a variety of charts, tables, and maps."
Describe what happens from the moment an app logged some information until it's displayed to the user in a dashboard when the Elastic stack is used
The process may vary based on the chosen architecture and the processing you may want to apply to the logs. One possible workflow is:
The data logged by the application is picked by filebeat and sent to logstash- Logstash process the log based on the defined filters. Once done, the output is sent to Elasticsearch
- Elasticsearch stores the document it got and the document is indexed for quick future access
- The user creates visualizations in Kibana which based on the indexed data
- The user creates a dashboard which composed out of the visualization created in the previous step
Búsqueda elástica
What is a data node?
This is where data is stored and also where different processing takes place (eg when you search for a data).
What is a master node?
Part of a master node responsibilities:
- Track the status of all the nodes in the cluster
- Verify replicas are working and the data is available from every data node.
- No hot nodes (no data node that works much harder than other nodes)
While there can be multiple master nodes in reality only of them is the elected master node.
What is an ingest node?
A node which responsible for processing the data according to ingest pipeline. In case you don't need to use logstash then this node can receive data from beats and process it, similarly to how it can be processed in Logstash.
What is Coordinating only node?
From the official docs:
Coordinating only nodes can benefit large clusters by offloading the coordinating node role from data and master-eligible nodes. They join the cluster and receive the full cluster state, like every other node, and they use the cluster state to route requests directly to the appropriate place(s).
How data is stored in Elasticsearch?
Data is stored in an index- The index is spread across the cluster using shards
What is an Index?
Index in Elasticsearch is in most cases compared to a whole database from the SQL/NoSQL world.
You can choose to have one index to hold all the data of your app or have multiple indices where each index holds different type of your app (eg index for each service your app is running).
The official docs also offer a great explanation (in general, it's really good documentation, as every project should have):
"An index can be thought of as an optimized collection of documents and each document is a collection of fields, which are the key-value pairs that contain your data"
Explain Shards
An index is split into shards and documents are hashed to a particular shard. Each shard may be on a different node in a cluster and each one of the shards is a self contained index.
This allows Elasticsearch to scale to an entire cluster of servers.
What is an Inverted Index?
From the official docs:
"An inverted index lists every unique word that appears in any document and identifies all of the documents each word occurs in."
What is a Document?
Continuing with the comparison to SQL/NoSQL a Document in Elasticsearch is a row in table in the case of SQL or a document in a collection in the case of NoSQL. As in NoSQL a document is a JSON object which holds data on a unit in your app. What is this unit depends on the your app. If your app related to book then each document describes a book. If you are app is about shirts then each document is a shirt.
You check the health of your elasticsearch cluster and it's red. ¿Qué significa? What can cause the status to be yellow instead of green?
Red means some data is unavailable in your cluster. Some shards of your indices are unassigned. There are some other states for the cluster. Yellow means that you have unassigned shards in the cluster. You can be in this state if you have single node and your indices have replicas. Green means that all shards in the cluster are assigned to nodes and your cluster is healthy.
¿Verdadero o falso? Elasticsearch indexes all data in every field and each indexed field has the same data structure for unified and quick query ability
FALSO. From the official docs:
"Each indexed field has a dedicated, optimized data structure. For example, text fields are stored in inverted indices, and numeric and geo fields are stored in BKD trees."
What reserved fields a document has?
_índice- _identificación
- _tipo
Explain Mapping
What are the advantages of defining your own mapping? (or: when would you use your own mapping?)
You can optimize fields for partial matching- You can define custom formats of known fields (eg date)
- You can perform language-specific analysis
Explain Replicas
In a network/cloud environment where failures can be expected any time, it is very useful and highly recommended to have a failover mechanism in case a shard/node somehow goes offline or disappears for whatever reason. To this end, Elasticsearch allows you to make one or more copies of your index's shards into what are called replica shards, or replicas for short.
Can you explain Term Frequency & Document Frequency?
Term Frequency is how often a term appears in a given document and Document Frequency is how often a term appears in all documents. They both are used for determining the relevance of a term by calculating Term Frequency / Document Frequency.
You check "Current Phase" under "Index lifecycle management" and you see it's set to "hot". ¿Qué significa?
"The index is actively being written to". More about the phases here
What this command does? curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H 'Content-Type: application/json' -d'{ "name": "John Doe" }'
It creates customer index if it doesn't exists and adds a new document with the field name which is set to "John Dow". Also, if it's the first document it will get the ID 1.
What will happen if you run the previous command twice? What about running it 100 times?
If name value was different then it would update "name" to the new value- In any case, it bumps version field by one
What is the Bulk API? ¿Para qué lo usarías?
Bulk API is used when you need to index multiple documents. For high number of documents it would be significantly faster to use rather than individual requests since there are less network roundtrips.
Query DSL
Explain Elasticsearch query syntax (Booleans, Fields, Ranges)
Explain what is Relevance Score
Explain Query Context and Filter Context
From the official docs:
"In the query context, a query clause answers the question “How well does this document match this query clause?” Besides deciding whether or not the document matches, the query clause also calculates a relevance score in the _score meta-field."
"In a filter context, a query clause answers the question “Does this document match this query clause?” The answer is a simple Yes or No — no scores are calculated. Filter context is mostly used for filtering structured data"
Describe how would an architecture of production environment with large amounts of data would be different from a small-scale environment
There are several possible answers for this question. One of them is as follows:
A small-scale architecture of elastic will consist of the elastic stack as it is. This means we will have beats, logstash, elastcsearch and kibana.
A production environment with large amounts of data can include some kind of buffering component (eg Reddis or RabbitMQ) and also security component such as Nginx.
Logstash
What are Logstash plugins? What plugins types are there?
Input Plugins - how to collect data from different sources- Filter Plugins - processing data
- Output Plugins - push data to different outputs/services/platforms
What is grok?
A logstash plugin which modifies information in one format and immerse it in another.
How grok works?
What grok patterns are you familiar with?
What is `_grokparsefailure?`
How do you test or debug grok patterns?
What are Logstash Codecs? What codecs are there?
Kibana
What can you find under "Discover" in Kibana?
The raw data as it is stored in the index. You can search and filter it.
You see in Kibana, after clicking on Discover, "561 hits". ¿Qué significa?
Total number of documents matching the search results. If not query used then simply the total number of documents.
What can you find under "Visualize"?
"Visualize" is where you can create visual representations for your data (pie charts, graphs, ...)
What visualization types are supported/included in Kibana?
What visualization type would you use for statistical outliers
Describe in detail how do you create a dashboard in Kibana
Filebeat
What is Filebeat?
Filebeat is used to monitor the logging directories inside of VMs or mounted as a sidecar if exporting logs from containers, and then forward these logs onward for further processing, usually to logstash.
If one is using ELK, is it a must to also use filebeat? In what scenarios it's useful to use filebeat?
Filebeat is a typical component of the ELK stack, since it was developed by Elastic to work with the other products (Logstash and Kibana). It's possible to send logs directly to logstash, though this often requires coding changes for the application. Particularly for legacy applications with little test coverage, it might be a better option to use filebeat, since you don't need to make any changes to the application code.
What is a harvester?
Leer aquí
¿Verdadero o falso? a single harvester harvest multiple files, according to the limits set in filebeat.yml
FALSO. One harvester harvests one file.
What are filebeat modules?
These are pre-configured modules for specific types of logging locations (eg, Traefik, Fargate, HAProxy) to make it easy to configure forwarding logs using filebeat. They have different configurations based on where you're collecting logs from.
Pila elástica
How do you secure an Elastic Stack?
You can generate certificates with the provided elastic utils and change configuration to enable security using certificates model.
Repartido
Explain Distributed Computing (or Distributed System)
According to Martin Kleppmann:
"Many processes running on many machines...only message-passing via an unreliable network with variable delays, and the system may suffer from partial failures, unreliable clocks, and process pauses."
Another definition: "Systems that are physically separated, but logically connected"
What can cause a system to fail?
Do you know what is "CAP theorem"? (aka as Brewer's theorem)
According to the CAP theorem, it's not possible for a distributed data store to provide more than two of the following at the same time:
Availability: Every request receives a response (it doesn't has to be the most recent data)- Consistency: Every request receives a response with the latest/most recent data
- Partition tolerance: Even if some the data is lost/dropped, the system keeps running
What are the problems with the following design? How to improve it?
1. The transition can take time. In other words, noticeable downtime. 2. Standby server is a waste of resources - if first application server is running then the standby does nothing What are the problems with the following design? How to improve it?
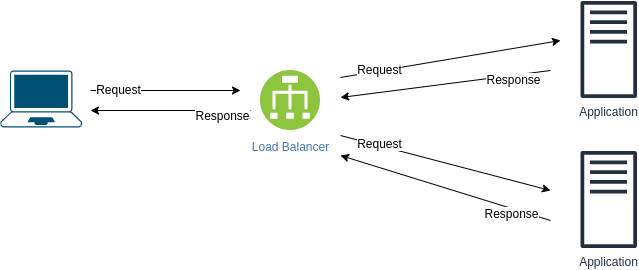
Issues: If load balancer dies , we lose the ability to communicate with the application. Ways to improve:
Add another load balancer- Use DNS A record for both load balancers
- Use message queue
What is "Shared-Nothing" architecture?
It's an architecture in which data is and retrieved from a single, non-shared, source usually exclusively connected to one node as opposed to architectures where the request can get to one of many nodes and the data will be retrieved from one shared location (storage , memoria, ...).
Explain the Sidecar Pattern (Or sidecar proxy)
Varios
| Nombre | Tema | Objective & Instructions | Solución | Comentarios |
|---|
| Highly Available "Hello World" | Ejercicio | Solución | | |
What happens when you type in a URL in an address bar in a browser?
- The browser searches for the record of the domain name IP address in the DNS in the following order:
- Browser cache
- Operating system cache
- The DNS server configured on the user's system (can be ISP DNS, public DNS, ...)
- If it couldn't find a DNS record locally, a full DNS resolution is started.
- It connects to the server using the TCP protocol
- The browser sends an HTTP request to the server
- The server sends an HTTP response back to the browser
- The browser renders the response (eg HTML)
- The browser then sends subsequent requests as needed to the server to get the embedded links, javascript, images in the HTML and then steps 3 to 5 are repeated.
TODO: add more details!
API
Explain what is an API
I like this definition from blog.christianposta.com:
"An explicitly and purposefully defined interface designed to be invoked over a network that enables software developers to get programmatic access to data and functionality within an organization in a controlled and comfortable way."
What is an API specification?
From swagger.io:
"An API specification provides a broad understanding of how an API behaves and how the API links with other APIs. It explains how the API functions and the results to expect when using the API"
¿Verdadero o falso? API Definition is the same as API Specification
FALSO. From swagger.io:
"An API definition is similar to an API specification in that it provides an understanding of how an API is organized and how the API functions. But the API definition is aimed at machine consumption instead of human consumption of APIs."
What is an API gateway?
An API gateway is like the gatekeeper that controls how different parts talk to each other and how information is exchanged between them.
The API gateway provides a single point of entry for all clients, and it can perform several tasks, including routing requests to the appropriate backend service, load balancing, security and authentication, rate limiting, caching, and monitoring.
By using an API gateway, organizations can simplify the management of their APIs, ensure consistent security and governance, and improve the performance and scalability of their backend services. They are also commonly used in microservices architectures, where there are many small, independent services that need to be accessed by different clients.
What are the advantages of using/implementing an API gateway?
Ventajas:
- Simplifies API management: Provides a single entry point for all requests, which simplifies the management and monitoring of multiple APIs.
- Improves security: Able to implement security features like authentication, authorization, and encryption to protect the backend services from unauthorized access.
- Enhances scalability: Can handle traffic spikes and distribute requests to backend services in a way that maximizes resource utilization and improves overall system performance.
- Enables service composition: Can combine different backend services into a single API, providing more granular control over the services that clients can access.
- Facilitates integration with external systems: Can be used to expose internal services to external partners or customers, making it easier to integrate with external systems and enabling new business models.
What is a Payload in API?
What is Automation? How it's related or different from Orchestration?
Automation is the act of automating tasks to reduce human intervention or interaction in regards to IT technology and systems.
While automation focuses on a task level, Orchestration is the process of automating processes and/or workflows which consists of multiple tasks that usually across multiple systems.
Tell me about interesting bugs you've found and also fixed
What is a Debugger and how it works?
What services an application might have?
Autorización- Explotación florestal
- Autenticación
- Realizar pedidos
- Interfaz
- Back-end ...
What is Metadata?
Data about data. Basically, it describes the type of information that an underlying data will hold.
You can use one of the following formats: JSON, YAML, XML. Which one would you use? ¿Por qué?
I can't answer this for you :)
What's KPI?
What's OKR?
What's DSL (Domain Specific Language)?
Domain Specific Language (DSLs) are used to create a customised language that represents the domain such that domain experts can easily interpret it.
What's the difference between KPI and OKR?
YAML
What is YAML?
Data serialization language used by many technologies today like Kubernetes, Ansible, etc.
¿Verdadero o falso? Any valid JSON file is also a valid YAML file
Verdadero. Because YAML is superset of JSON.
What is the format of the following data? {
applications: [
{
name: "my_app",
language: "python",
version: 20.17
}
]
}
JSON What is the format of the following data? applications:
- app: "my_app"
language: "python"
version: 20.17
YAML How to write a multi-line string with YAML? What use cases is it good for?
someMultiLineString: | look mama I can write a multi-line string I love YAML
It's good for use cases like writing a shell script where each line of the script is a different command.
What is the difference between someMultiLineString: | to someMultiLineString: > ?
using > will make the multi-line string to fold into a single line
someMultiLineString: >
This is actually
a single line
do not let appearances fool you
What are placeholders in YAML?
They allow you reference values instead of directly writing them and it is used like this:
username: {{ my.user_name }}
How can you define multiple YAML components in one file?
Using this: --- For Examples:
document_number: 1
---
document_number: 2
firmware
Explain what is a firmware
Wikipedia: "In computing, firmware is a specific class of computer software that provides the low-level control for a device's specific hardware. Firmware, such as the BIOS of a personal computer, may contain basic functions of a device, and may provide hardware abstraction services to higher-level software such as operating systems."
casandra
When running a cassandra cluster, how often do you need to run nodetool repair in order to keep the cluster consistent?- Within the columnFamily GC-grace Once a week
- Less than the compacted partition minimum bytes
- Depended on the compaction strategy
HTTP
What is HTTP?
Avinetworks: HTTP stands for Hypertext Transfer Protocol. HTTP uses TCP port 80 to enable internet communication. It is part of the Application Layer (L7) in OSI Model.
Describe HTTP request lifecycle
Resolve host by request to DNS resolver- Client SYN
- Server SYN+ACK
- Client SYN
- HTTP request
- HTTP response
¿Verdadero o falso? HTTP is stateful
FALSO. It doesn't maintain state for incoming request.
How HTTP request looks like?
Consta de:
Request line - request type- Headers - content info like length, encoding, etc.
- Body (not always included)
What HTTP method types are there?
CONSEGUIR- CORREO
- CABEZA
- PONER
- BORRAR
- CONECTAR
- OPCIONES
- RASTRO
What HTTP response codes are there?
1xx - informational- 2xx - Success
- 3xx - Redirect
- 4xx - Error, client fault
- 5xx - Error, server fault
What is HTTPS?
HTTPS is a secure version of the HTTP protocol used to transfer data between a web browser and a web server. It encrypts the communication using SSL/TLS encryption to ensure that the data is private and secure.
Learn more: https://www.cloudflare.com/learning/ssl/why-is-http-not-secure/
Explain HTTP Cookies
HTTP is stateless. To share state, we can use Cookies.
TODO: explain what is actually a Cookie
What is HTTP Pipelining?
You get "504 Gateway Timeout" error from an HTTP server. ¿Qué significa?
The server didn't receive a response from another server it communicates with in a timely manner.
What is a proxy?
A proxy is a server that acts as a middleman between a client device and a destination server. It can help improve privacy, security, and performance by hiding the client's IP address, filtering content, and caching frequently accessed data.
- Proxies can be used for load balancing, distributing traffic across multiple servers to help prevent server overload and improve website or application performance. They can also be used for data analysis, as they can log requests and traffic, providing useful insights into user behavior and preferences.
What is a reverse proxy?
A reverse proxy is a type of proxy server that sits between a client and a server, but it is used to manage traffic going in the opposite direction of a traditional forward proxy. In a forward proxy, the client sends requests to the proxy server, which then forwards them to the destination server. However, in a reverse proxy, the client sends requests to the destination server, but the requests are intercepted by the reverse proxy before they reach the server.
- They're commonly used to improve web server performance, provide high availability and fault tolerance, and enhance security by preventing direct access to the back-end server. They are often used in large-scale web applications and high-traffic websites to manage and distribute requests to multiple servers, resulting in improved scalability and reliability.
When you publish a project, you usually publish it with a license. What types of licenses are you familiar with and which one do you prefer to use?
Explain what is "X-Forwarded-For"
Wikipedia: "The X-Forwarded-For (XFF) HTTP header field is a common method for identifying the originating IP address of a client connecting to a web server through an HTTP proxy or load balancer."
Load Balancers
What is a load balancer?
A load balancer accepts (or denies) incoming network traffic from a client, and based on some criteria (application related, network, etc.) it distributes those communications out to servers (at least one).
Why to used a load balancer?
Scalability - using a load balancer, you can possibly add more servers in the backend to handle more requests/traffic from the clients, as opposed to using one server.- Redundancy - if one server in the backend dies, the load balancer will keep forwarding the traffic/requests to the second server so users won't even notice one of the servers in the backend is down.
What load balancer techniques/algorithms are you familiar with?
Ronda Robin- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
What are the drawbacks of round robin algorithm in load balancing?
A simple round robin algorithm knows nothing about the load and the spec of each server it forwards the requests to. It is possible, that multiple heavy workloads requests will get to the same server while other servers will got only lightweight requests which will result in one server doing most of the work, maybe even crashing at some point because it unable to handle all the heavy workloads requests by its own.- Each request from the client creates a whole new session. This might be a problem for certain scenarios where you would like to perform multiple operations where the server has to know about the result of operation so basically, being sort of aware of the history it has with the client. In round robin, first request might hit server X, while second request might hit server Y and ask to continue processing the data that was processed on server X already.
What is an Application Load Balancer?
In which scenarios would you use ALB?
At what layers a load balancer can operate?
L4 and L7
Can you perform load balancing without using a dedicated load balancer instance?
Yes, you can use DNS for performing load balancing.
What is DNS load balancing? What its advantages? When would you use it?
Load Balancers - Sticky Sessions
What are sticky sessions? What are their pros and cons?
Recommended read:
Contras:
Can cause uneven load on instance (since requests routed to the same instances) Pros:- Ensures in-proc sessions are not lost when a new request is created
Name one use case for using sticky sessions
You would like to make sure the user doesn't lose the current session data.
What sticky sessions use for enabling the "stickiness"?
Galletas. There are application based cookies and duration based cookies.
Explain application-based cookies
Generated by the application and/or the load balancer- Usually allows to include custom data
Explain duration-based cookies
Generated by the load balancer- Session is not sticky anymore once the duration elapsed
Load Balancers - Load Balancing Algorithms
Explain each of the following load balancing techniques- Ronda Robin
- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
Explain use case for connection draining?
To ensure that a Classic Load Balancer stops sending requests to instances that are de-registering or unhealthy, while keeping the existing connections open, use connection draining. This enables the load balancer to complete in-flight requests made to instances that are de-registering or unhealthy. The maximum timeout value can be set between 1 and 3,600 seconds on both GCP and AWS.
Licencias
Are you familiar with "Creative Commons"? ¿Qué sabes al respecto?
The Creative Commons license is a set of copyright licenses that allow creators to share their work with the public while retaining some control over how it can be used. The license was developed as a response to the restrictive standards of traditional copyright laws, which limited access of creative works. Its creators to choose the terms under which their works can be shared, distributed, and used by others. They're six main types of Creative Commons licenses, each with different levels of restrictions and permissions, the six licenses are:
- Attribution (CC BY): Allows others to distribute, remix, and build upon the work, even commercially, as long as they credit the original creator.
- Attribution-ShareAlike (CC BY-SA): Allows others to remix and build upon the work, even commercially, as long as they credit the original creator and release any new creations under the same license.
- Attribution-NoDerivs (CC BY-ND): Allows others to distribute the work, even commercially, but they cannot remix or change it in any way and must credit the original creator.
- Attribution-NonCommercial (CC BY-NC): Allows others to remix and build upon the work, but they cannot use it commercially and must credit the original creator.
- Attribution-NonCommercial-ShareAlike (CC BY-NC-SA): Allows others to remix and build upon the work, but they cannot use it commercially, must credit the original creator, and must release any new creations under the same license.
- Attribution-NonCommercial-NoDerivs (CC BY-NC-ND): Allows others to download and share the work, but they cannot use it commercially, remix or change it in any way, and must credit the original creator.
Simply stated, the Creative Commons licenses are a way for creators to share their work with the public while retaining some control over how it can be used. The licenses promote creativity, innovation, and collaboration, while also respecting the rights of creators while still encouraging the responsible use of creative works.
More information: https://creativecommons.org/licenses/
Explain the differences between copyleft and permissive licenses
In Copyleft, any derivative work must use the same licensing while in permissive licensing there are no such condition. GPL-3 is an example of copyleft license while BSD is an example of permissive license.
Aleatorio
How a search engine works?
How auto completion works?
What is faster than RAM?
CPU cache. Fuente
What is a memory leak?
A memory leak is a programming error that occurs when a program fails to release memory that is no longer needed, causing the program to consume increasing amounts of memory over time.
The leaks can lead to a variety of problems, including system crashes, performance degradation, and instability. Usually occurring after failed maintenance on older systems and compatibility with new components over time.
What is your favorite protocol?
SSH HTTP DHCP DNS ...
What is Cache API?
What is the C10K problem? Is it relevant today?
https://idiallo.com/blog/c10k-2016
Almacenamiento
What types of storage are there?
Explain Object Storage
Data is divided to self-contained objects- Objects can contain metadata
What are the pros and cons of object storage?
Ventajas:
Usually with object storage, you pay for what you use as opposed to other storage types where you pay for the storage space you allocate- Scalable storage: Object storage mostly based on a model where what you use, is what you get and you can add storage as need Cons:
- Usually performs slower than other types of storage
- No granular modification: to change an object, you have re-create it
What are some use cases for using object storage?
Explain File Storage
File Storage used for storing data in files, in a hierarchical structure- Some of the devices for file storage: hard drive, flash drive, cloud-based file storage
- Files usually organized in directories
What are the pros and cons of File Storage?
Ventajas:
Users have full control of their own files and can run variety of operations on the files: delete, read, write and move.- Security mechanism allows for users to have a better control at things such as file locking
What are some examples of file storage?
Local filesystem Dropbox Google Drive
What types of storage devices are there?
Explain IOPS
Explain storage throughput
What is a filesystem?
A file system is a way for computers and other electronic devices to organize and store data files. It provides a structure that helps to organize data into files and directories, making it easier to find and manage information. A file system is crucial for providing a way to store and manage data in an organized manner.
Commonly used filed systems: Windows:
Mac OS:
Explain Dark Data
Explain MBR
Questions you CAN ask
A list of questions you as a candidate can ask the interviewer during or after the interview. These are only a suggestion, use them carefully. Not every interviewer will be able to answer these (or happy to) which should be perhaps a red flag warning for your regarding working in such place but that's really up to you.
¿Qué te gusta de trabajar aquí?
How does the company promote personal growth?
What is the current level of technical debt you are dealing with?
Be careful when asking this question - all companies, regardless of size, have some level of tech debt. Phrase the question in the light that all companies have the deal with this, but you want to see the current pain points they are dealing with
This is a great way to figure how managers deal with unplanned work, and how good they are at setting expectations with projects.
Why I should NOT join you? (or 'what you don't like about working here?')
What was your favorite project you've worked on?
This can give you insights in some of the cool projects a company is working on, and if you would enjoy working on projects like these. This is also a good way to see if the managers are allowing employees to learn and grow with projects outside of the normal work you'd do.
If you could change one thing about your day to day, what would it be?
Similar to the tech debt question, this helps you identify any pain points with the company. Additionally, it can be a great way to show how you'd be an asset to the team.
For Example, if they mention they have problem X, and you've solved that in the past, you can show how you'd be able to mitigate that problem.
Let's say that we agree and you hire me to this position, after X months, what do you expect that I have achieved?
Not only this will tell you what is expected from you, it will also provide big hint on the type of work you are going to do in the first months of your job.
Pruebas
Explain white-box testing
Explain black-box testing
What are unit tests?
Unit test are a software testing technique that involves systimatically breaking down a system and testing each individual part of the assembly. These tests are automated and can be run repeatedly to allow developers to catch edge case scenarios or bugs quickly while developing.
The main objective of unit tests are to verify each function is producing proper outputs given a set of inputs.
What types of tests would you run to test a web application?
Explain test harness?
What is A/B testing?
What is network simulation and how do you perform it?
What types of performances tests are you familiar with?
Explain the following types of tests:- Load Testing
- Stress Testing
- Capacity Testing
- Volume Testing
- Endurance Testing
Regex
Given a text file, perform the following exercises
Extracto
Extract all the numbers
Extract the first word of each line
"^w+" Bonus: extract the last word of each line
-
"w+(?=W*$)" (in most cases, depends on line formatting)
Extract all the IP addresses
- "b(?:d{1,3} .){3}d{1,3}b" IPV4:(This format looks for 1 to 3 digit sequence 3 times)
Extract dates in the format of yyyy-mm-dd or yyyy-dd-mm
Extract email addresses
- "b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+ .[A-Za-z]{2,}b"
Reemplazar
Replace tabs with four spaces
Replace 'red' with 'green'
System Design
Explain what a "single point of failure" is.
A "single point of failure", in a system or organization, if it were to fail would cause the entire system to fail or significantly disrupt it's operation. In other words, it is a vulnerability where there is no backup in place to compensate for the failure. What is CDN?
CDN (Content Delivery Network) responsible for distributing content geographically. Part of it, is what is known as edge locations, aka cache proxies, that allows users to get their content quickly due to cache features and geographical distribution.
Explain Multi-CDN
In single CDN, the whole content is originated from content delivery network.
In multi-CDN, content is distributed across multiple different CDNs, each might be on a completely different provider/cloud.
What are the benefits of Multi-CDN over a single CDN?
Resiliency: Relying on one CDN means no redundancy. With multiple CDNs you don't need to worry about your CDN being down- Flexibility in Costs: Using one CDN enforces you to specific rates of that CDN. With multiple CDNs you can take into consideration using less expensive CDNs to deliver the content.
- Performance: With Multi-CDN there is bigger potential in choosing better locations which more close to the client asking the content
- Scale: With multiple CDNs, you can scale services to support more extreme conditions
Explain "3-Tier Architecture" (including pros and cons)
A "3-Tier Architecture" is a pattern used in software development for designing and structuring applications. It divides the application into 3 interconnected layers: Presentation, Business logic and Data storage. PROS: * Scalability * Security * Reusability CONS: * Complexity * Performance overhead * Cost and development time Explain Mono-repo vs. Multi-repo.What are the cons and pros of each approach?
In a Mono-repo, all the code for an organization is stored in a single,centralized repository. PROS (Mono-repo): * Unified tooling * Code Sharing CONS (Mono-repo): * Increased complexity * Slower cloning In a Multi-repo setup, each component is stored in it's own separate repository. Each repository has it's own version control history. PROS (Multi-repo):
Simpler to manage- Different teams and developers can work on different parts of the project independently, making parallel development easier. CONS (Multi-repo):
- Code duplication
- Integration challenges
What are the drawbacks of monolithic architecture?
Not suitable for frequent code changes and the ability to deploy new features- Not designed for today's infrastructure (like public clouds)
- Scaling a team to work monolithic architecture is more challenging
- If a single component in this architecture fails, then the entire application fails.
What are the advantages of microservices architecture over a monolithic architecture?
Each of the services individually fail without escalating into an application-wide outage.- Each service can be developed and maintained by a separate team and this team can choose its own tools and coding language
What's a service mesh?
It is a layer that facilitates communication management and control between microservices in a containerized application. It handles tasks such as load balancing, encryption, and monitoring. Explain "Loose Coupling"
In "Loose Coupling", components of a system communicate with each other with a little understanding of each other's internal workings. This improves scalability and ease of modification in complex systems. What is a message queue? When is it used?
It is a communication mechanism used in distributed systems to enable asynchronous communication between different components. It is generally used when the systems use a microservices approach. Escalabilidad
Explain Scalability
The ability easily grow in size and capacity based on demand and usage.
Explain Elasticity
The ability to grow but also to reduce based on what is required
Explain Disaster Recovery
Disaster recovery is the process of restoring critical business systems and data after a disruptive event. The goal is to minimize the impact and resume normal business activities quickly. This involves creating a plan, testing it, backing up critical data, and storing it in safe locations. In case of a disaster, the plan is then executed, backups are restored, and systems are hopefully brought back online. The recovery process may take hours or days depending on the damages of infrastructure. This makes business planning important, as a well-designed and tested disaster recovery plan can minimize the impact of a disaster and keep operations going.
Explain Fault Tolerance and High Availability
Fault Tolerance - The ability to self-heal and return to normal capacity. Also the ability to withstand a failure and remain functional.
High Availability - Being able to access a resource (in some use cases, using different platforms)
What is the difference between high availability and Disaster Recovery?
wintellect.com: "High availability, simply put, is eliminating single points of failure and disaster recovery is the process of getting a system back to an operational state when a system is rendered inoperative. In essence, disaster recovery picks up when high availability fails, so HA first."
Explain Vertical Scaling
Vertical Scaling is the process of adding resources to increase power of existing servers. For example, adding more CPUs, adding more RAM, etc.
What are the disadvantages of Vertical Scaling?
With vertical scaling alone, the component still remains a single point of failure. In addition, it has hardware limit where if you don't have more resources, you might not be able to scale vertically.
Which type of cloud services usually support vertical scaling?
Databases, cache. It's common mostly for non-distributed systems.
Explain Horizontal Scaling
Horizontal Scaling is the process of adding more resources that will be able handle requests as one unit
What is the disadvantage of Horizontal Scaling? What is often required in order to perform Horizontal Scaling?
A load balancer. You can add more resources, but if you would like them to be part of the process, you have to serve them the requests/responses. Also, data inconsistency is a concern with horizontal scaling.
Explain in which use cases will you use vertical scaling and in which use cases you will use horizontal scaling
Explain Resiliency and what ways are there to make a system more resilient
Explain "Consistent Hashing"
How would you update each of the services in the following drawing without having app (foo.com) downtime?
What is the problem with the following architecture and how would you fix it?
The load on the producers or consumers may be high which will then cause them to hang or crash.
Instead of working in "push mode", the consumers can pull tasks only when they are ready to handle them. It can be fixed by using a streaming platform like Kafka, Kinesis, etc. This platform will make sure to handle the high load/traffic and pass tasks/messages to consumers only when the ready to get them.

Users report that there is huge spike in process time when adding little bit more data to process as an input. What might be the problem?

How would you scale the architecture from the previous question to hundreds of users?
Cache
What is "cache"? In which cases would you use it?
What is "distributed cache"?
What is a "cache replacement policy"?
Echa un vistazo aquí
Which cache replacement policies are you familiar with?
You can find a list here
Explain the following cache policies:
Read about it here
Why not writing everything to cache instead of a database/datastore?
Caching and databases serve different purposes and are optimized for different use cases. Caching is used to speed up read operations by storing frequently accessed data in memory or on a fast storage medium. By keeping data close to the application, caching reduces the latency and overhead of accessing data from a slower, more distant storage system such as a database or disk.
On the other hand, databases are optimized for storing and managing persistent data. Databases are designed to handle concurrent read and write operations, enforce consistency and integrity constraints, and provide features such as indexing and querying.
Migrations
How you prepare for a migration? (or plan a migration)
You can mention:
roll-back & roll-forward cut over dress rehearsals DNS redirection
Explain "Branch by Abstraction" technique
Design a system
Can you design a video streaming website?
Can you design a photo upload website?
How would you build a URL shortener?
More System Design Questions
Additional exercises can be found in system-design-notebook repository.

Hardware
What is a CPU?
A central processing unit (CPU) performs basic arithmetic, logic, controlling, and input/output (I/O) operations specified by the instructions in the program. This contrasts with external components such as main memory and I/O circuitry, and specialized processors such as graphics processing units (GPUs).
What is RAM?
RAM (Random Access Memory) is the hardware in a computing device where the operating system (OS), application programs and data in current use are kept so they can be quickly reached by the device's processor. RAM is the main memory in a computer. It is much faster to read from and write to than other kinds of storage, such as a hard disk drive (HDD), solid-state drive (SSD) or optical drive.
What is a GPU?
A GPU, or Graphics Processing Unit, is a specialized electronic circuit designed to expedite image and video processing for display on a computer screen.
What is an embedded system?
An embedded system is a computer system - a combination of a computer processor, computer memory, and input/output peripheral devices—that has a dedicated function within a larger mechanical or electronic system. It is embedded as part of a complete device often including electrical or electronic hardware and mechanical parts.
Can you give an example of an embedded system?
A common example of an embedded system is a microwave oven's digital control panel, which is managed by a microcontroller.
When committed to a certain goal, Raspberry Pi can serve as an embedded system.
What types of storage are there?
There are several types of storage, including hard disk drives (HDDs), solid-state drives (SSDs), and optical drives (CD/DVD/Blu-ray). Other types of storage include USB flash drives, memory cards, and network-attached storage (NAS).
What are some considerations DevOps teams should keep in mind when selecting hardware for their job?
Choosing the right DevOps hardware is essential for ensuring streamlined CI/CD pipelines, timely feedback loops, and consistent service availability. Here's a distilled guide on what DevOps teams should consider:
Understanding Workloads :
- CPU : Consider the need for multi-core or high-frequency CPUs based on your tasks.
- RAM : Enough memory is vital for activities like large-scale coding or intensive automation.
- Storage : Evaluate storage speed and capacity. SSDs might be preferable for swift operations.
Expandability :
- Horizontal Growth : Check if you can boost capacity by adding more devices.
- Vertical Growth : Determine if upgrades (like RAM, CPU) to individual machines are feasible.
Connectivity Considerations :
- Data Transfer : Ensure high-speed network connections for activities like code retrieval and data transfers.
- Speed : Aim for low-latency networks, particularly important for distributed tasks.
- Backup Routes : Think about having backup network routes to avoid downtimes.
Consistent Uptime :
- Plan for hardware backups like RAID configurations, backup power sources, or alternate network connections to ensure continuous service.
System Compatibility :
- Make sure your hardware aligns with your software, operating system, and intended platforms.
Power Efficiency :
- Hardware that uses energy efficiently can reduce costs in long-term, especially in large setups.
Safety Measures :
- Explore hardware-level security features, such as TPM, to enhance protection.
Overseeing & Control :
- Tools like ILOM can be beneficial for remote handling.
- Make sure the hardware can be seamlessly monitored for health and performance.
Budgeting :
- Consider both initial expenses and long-term costs when budgeting.
Support & Community :
- Choose hardware from reputable vendors known for reliable support.
- Check for available drivers, updates, and community discussions around the hardware.
Planning Ahead :
- Opt for hardware that can cater to both present and upcoming requirements.
Operational Environment :
- Temperature Control : Ensure cooling systems to manage heat from high-performance units.
- Space Management : Assess hardware size considering available rack space.
- Reliable Power : Factor in consistent and backup power sources.
Cloud Coordination :
- If you're leaning towards a hybrid cloud setup, focus on how local hardware will mesh with cloud resources.
Life Span of Hardware :
- Be aware of the hardware's expected duration and when you might need replacements or upgrades.
Optimized for Virtualization :
- If utilizing virtual machines or containers, ensure the hardware is compatible and optimized for such workloads.
Adaptability :
- Modular hardware allows individual component replacements, offering more flexibility.
Avoiding Single Vendor Dependency :
- Try to prevent reliance on a single vendor unless there are clear advantages.
Eco-Friendly Choices :
- Prioritize sustainably produced hardware that's energy-efficient and environmentally responsible.
In essence, DevOps teams should choose hardware that is compatible with their tasks, versatile, gives good performance, and stays within their budget. Furthermore, long-term considerations such as maintenance, potential upgrades, and compatibility with impending technological shifts must be prioritized.
What is the role of hardware in disaster recovery planning and implementation?
Hardware is critical in disaster recovery (DR) solutions. While the broader scope of DR includes things like standard procedures, norms, and human roles, it's the hardware that keeps business processes running smoothly. Here's an outline of how hardware works with DR:
Storing Data and Ensuring Its Duplication :
- Backup Equipment : Devices like tape storage, backup servers, and external HDDs keep essential data stored safely at a different location.
- Disk Arrays : Systems such as RAID offer a safety net. If one disk crashes, the others compensate.
Alternate Systems for Recovery :
- Backup Servers : These step in when the main servers falter, maintaining service flow.
- Traffic Distributors : Devices like load balancers share traffic across servers. If a server crashes, they reroute users to operational ones.
Alternate Operation Hubs :
- Ready-to-use Centers : Locations equipped and primed to take charge immediately when the main center fails.
- Basic Facilities : Locations with necessary equipment but lacking recent data, taking longer to activate.
- Semi-prepped Facilities : Locations somewhat prepared with select systems and data, taking a moderate duration to activate.
Power Backup Mechanisms :
- Instant Power Backup : Devices like UPS offer power during brief outages, ensuring no abrupt shutdowns.
- Long-term Power Solutions : Generators keep vital systems operational during extended power losses.
Networking Equipment :
- Backup Internet Connections : Having alternatives ensures connectivity even if one provider faces issues.
- Secure Connection Tools : Devices ensuring safe remote access, especially crucial during DR situations.
On-site Physical Setup :
- Organized Housing : Structures like racks to neatly store and manage hardware.
- Emergency Temperature Control : Backup cooling mechanisms to counter server overheating in HVAC malfunctions.
Alternate Communication Channels :
- Orbit-based Phones : Handy when regular communication methods falter.
- Direct Communication Devices : Devices like radios useful when primary systems are down.
Protection Mechanisms :
- Electronic Barriers & Alert Systems : Devices like firewalls and intrusion detection keep DR systems safeguarded.
- Physical Entry Control : Systems controlling entry and monitoring, ensuring only cleared personnel have access.
Uniformity and Compatibility in Hardware :
- It's simpler to manage and replace equipment in emergencies if hardware configurations are consistent and compatible.
Equipment for Trials and Upkeep :
- DR drills might use specific equipment to ensure the primary systems remain unaffected. This verifies the equipment's readiness and capacity to manage real crises.
In summary, while software and human interventions are important in disaster recovery operations, it is the hardware that provides the underlying support. It is critical for efficient disaster recovery plans to keep this hardware resilient, duplicated, and routinely assessed.
What is a RAID?
RAID is an acronym that stands for "Redundant Array of Independent Disks." It is a technique that combines numerous hard drives into a single device known as an array in order to improve performance, expand storage capacity, and/or offer redundancy to prevent data loss. RAID levels (for example, RAID 0, RAID 1, and RAID 5) provide varied benefits in terms of performance, redundancy, and storage efficiency.
What is a microcontroller?
A microcontroller is a small integrated circuit that controls certain tasks in an embedded system. It typically includes a CPU, memory, and input/output peripherals.
What is a Network Interface Controller or NIC?
A Network Interface Controller (NIC) is a piece of hardware that connects a computer to a network and allows it to communicate with other devices.
What is a DMA?
Direct memory access (DMA) is a feature of computer systems that allows certain hardware subsystems to access main system memory independently of the central processing unit (CPU).DMA enables devices to share and receive data from the main memory in a computer. It does this while still allowing the CPU to perform other tasks.
What is a Real-Time Operating Systems?
A real-time operating system (RTOS) is an operating system (OS) for real-time computing applications that processes data and events that have critically defined time constraints. An RTOS is distinct from a time-sharing operating system, such as Unix, which manages the sharing of system resources with a scheduler, data buffers, or fixed task prioritization in a multitasking or multiprogramming environment. Processing time requirements need to be fully understood and bound rather than just kept as a minimum. All processing must occur within the defined constraints. Real-time operating systems are event-driven and preemptive, meaning the OS can monitor the relevant priority of competing tasks, and make changes to the task priority. Event-driven systems switch between tasks based on their priorities, while time-sharing systems switch the task based on clock interrupts.
List of interrupt types
There are six classes of interrupts possible:
Externo- Machine check
- E/S
- Programa
- Reanudar
- Supervisor call (SVC)
Grandes datos
Explain what is exactly Big Data
As defined by Doug Laney:
Volume: Extremely large volumes of data- Velocity: Real time, batch, streams of data
- Variety: Various forms of data, structured, semi-structured and unstructured
- Veracity or Variability: Inconsistent, sometimes inaccurate, varying data
What is DataOps? How is it related to DevOps?
DataOps seeks to reduce the end-to-end cycle time of data analytics, from the origin of ideas to the literal creation of charts, graphs and models that create value. DataOps combines Agile development, DevOps and statistical process controls and applies them to data analytics.
What is Data Architecture?
An answer from talend.com:
"Data architecture is the process of standardizing how organizations collect, store, transform, distribute, and use data. The goal is to deliver relevant data to people who need it, when they need it, and help them make sense of it."
Explain the different formats of data
Structured - data that has defined format and length (eg numbers, words)- Semi-structured - Doesn't conform to a specific format but is self-describing (eg XML, SWIFT)
- Unstructured - does not follow a specific format (eg images, test messages)
What is a Data Warehouse?
Wikipedia's explanation on Data Warehouse Amazon's explanation on Data Warehouse
What is Data Lake?
Data Lake - Wikipedia
Can you explain the difference between a data lake and a data warehouse?
What is "Data Versioning"? What models of "Data Versioning" are there?
What is ETL?
apache hadoop
Explain what is Hadoop
Apache Hadoop - Wikipedia
Explain Hadoop YARN
Responsible for managing the compute resources in clusters and scheduling users' applications
Explain Hadoop MapReduce
A programming model for large-scale data processing
Explain Hadoop Distributed File Systems (HDFS)
Distributed file system providing high aggregate bandwidth across the cluster.- For a user it looks like a regular file system structure but behind the scenes it's distributed across multiple machines in a cluster
- Typical file size is TB and it can scale and supports millions of files
- It's fault tolerant which means it provides automatic recovery from faults
- It's best suited for running long batch operations rather than live analysis
What do you know about HDFS architecture?
HDFS Architecture
Master-slave architecture- Namenode - master, Datanodes - slaves
- Files split into blocks
- Blocks stored on datanodes
- Namenode controls all metadata
Ceph
Explain what is Ceph
Ceph is an Open-Source Distributed Storage System designed to provide excellent performance, reliability, and scalability. It's often used in cloud computing environments and Data Centers. ¿Verdadero o falso? Ceph favor consistency and correctness over performances
Verdadero Which services or types of storage Ceph supports?
Object (RGW)- Block (RBD)
- File (CephFS)
What is RADOS?
Reliable Autonomic Distributed Object Storage- Provides low-level data object storage service
- Strong Consistency
- Simplifies design and implementation of higher layers (block, file, object)
Describe RADOS software components
Monitor- Central authority for authentication, data placement, policy
- Coordination point for all other cluster components
- Protect critical cluster state with Paxos
- Gerente
- Aggregates real-time metrics (throughput, disk usage, etc.)
- Host for pluggable management functions
- 1 active, 1+ standby per cluster
- OSD (Object Storage Daemon)
Stores data on an HDD or SSD
- Services client IO requests
What is the workflow of retrieving data from Ceph?
The work flow is as follows: - The client sends a request to the ceph cluster to retrieve data:
Client could be any of the following
- Ceph Block Device
- Ceph Object Gateway
- Any third party ceph client
- The client retrieves the latest cluster map from the Ceph Monitor
- The client uses the CRUSH algorithm to map the object to a placement group. The placement group is then assigned to a OSD.
- Once the placement group and the OSD Daemon are determined, the client can retrieve the data from the appropriate OSD
What is the workflow of writing data to Ceph?
The work flow is as follows: - The client sends a request to the ceph cluster to retrieve data
- The client retrieves the latest cluster map from the Ceph Monitor
- The client uses the CRUSH algorithm to map the object to a placement group. The placement group is then assigned to a Ceph OSD Daemon dynamically.
- The client sends the data to the primary OSD of the determined placement group. If the data is stored in an erasure-coded pool, the primary OSD is responsible for encoding the object into data chunks and coding chunks, and distributing them to the other OSDs.
What are "Placement Groups"?
Describe in the detail the following: Objects -> Pool -> Placement Groups -> OSDs
What is OMAP?
What is a metadata server? ¿Cómo funciona?
Envasador
What is Packer? ¿Para qué se utiliza?
In general, Packer automates machine images creation. It allows you to focus on configuration prior to deployment while making the images. This allows you start the instances much faster in most cases.
Packer follows a "configuration->deployment" model or "deployment->configuration"?
A configuration->deployment which has some advantages like:
Deployment Speed - you configure once prior to deployment instead of configuring every time you deploy. This allows you to start instances/services much quicker.- More immutable infrastructure - with configuration->deployment it's not likely to have very different deployments since most of the configuration is done prior to the deployment. Issues like dependencies errors are handled/discovered prior to deployment in this model.
Liberar
Explain Semantic Versioning
This page explains it perfectly:
Given a version number MAJOR.MINOR.PATCH, increment the:
MAJOR version when you make incompatible API changes
MINOR version when you add functionality in a backwards compatible manner
PATCH version when you make backwards compatible bug fixes
Additional labels for pre-release and build metadata are available as extensions to the MAJOR.MINOR.PATCH format.
Certificados
If you are looking for a way to prepare for a certain exam this is the section for you. Here you'll find a list of certificates, each references to a separate file with focused questions that will help you to prepare to the exam. Buena suerte :)
AWS
- Cloud Practitioner (Latest update: 2020)
- Solutions Architect Associate (Latest update: 2021)
- Cloud SysOps Administration Associate (Latest update: Oct 2022)
Azur
- AZ-900 (Latest update: 2021)
Kubernetes
- Certified Kubernetes Administrator (CKA) (Latest update: 2022)
Additional DevOps and SRE Projects




Créditos
Thanks to all of our amazing contributors who make it easy for everyone to learn new things :)
Logos credits can be found here
Licencia


