homemade machine learning
1.0.0
?? UCRANIA ESTÁ SIENDO ATACADA POR EL EJÉRCITO RUSO. LOS CIVILES ESTÁN MUERTOS. LAS ZONAS RESIDENCIALES ESTÁN SIENDO BOMBARDEADAS.
- Ayuda a Ucrania a través de:
- Fundación benéfica Serhiy Prytula
- Fundación Benéfica Vuelve Viva
- Banco Nacional de Ucrania
- Más información en war.ukraine.ua y MFA de Ucrania
Lea esto en otros idiomas: Español
Quizás te interese:
- GPT casero • JS
- Experimentos interactivos de aprendizaje automático
Para la versión Octave/MatLab de este repositorio, consulte el proyecto machine-learning-octave.
Este repositorio contiene ejemplos de algoritmos populares de aprendizaje automático implementados en Python y se explican las matemáticas detrás de ellos. Cada algoritmo tiene una demostración interactiva de Jupyter Notebook que le permite jugar con datos de entrenamiento, configuraciones de algoritmos y ver inmediatamente los resultados, gráficos y predicciones directamente en su navegador . En la mayoría de los casos, las explicaciones se basan en este fantástico curso de aprendizaje automático impartido por Andrew Ng.
El propósito de este repositorio no es implementar algoritmos de aprendizaje automático mediante el uso de frases ingeniosas de bibliotecas de terceros , sino más bien practicar la implementación de estos algoritmos desde cero y obtener una mejor comprensión de las matemáticas detrás de cada algoritmo. Es por eso que todas las implementaciones de algoritmos se denominan "caseras" y no están destinadas a ser utilizadas en producción.
En el aprendizaje supervisado tenemos un conjunto de datos de entrenamiento como entrada y un conjunto de etiquetas o "respuestas correctas" para cada conjunto de entrenamiento como salida. Luego, entrenamos nuestro modelo (parámetros del algoritmo de aprendizaje automático) para asignar la entrada a la salida correctamente (para hacer una predicción correcta). El objetivo final es encontrar parámetros de modelo que continúen con éxito el mapeo (predicciones) de entrada → salida correcta incluso para nuevos ejemplos de entrada.
En los problemas de regresión hacemos predicciones de valores reales. Básicamente, intentamos dibujar una línea/plano/plano de n dimensiones a lo largo de los ejemplos de entrenamiento.
Ejemplos de uso: previsión del precio de las acciones, análisis de ventas, dependencia de cualquier número, etc.
country happiness según economy GDPcountry happiness según economy GDP y freedom indexEn los problemas de clasificación dividimos los ejemplos de entrada según determinada característica.
Ejemplos de uso: filtros de spam, detección de idioma, búsqueda de documentos similares, reconocimiento de cartas escritas a mano, etc.
class de flor del iris en función de petal_length y petal_widthvalidity del microchip en función de param_1 y param_228x28 píxeles28x28 píxeles El aprendizaje no supervisado es una rama del aprendizaje automático que aprende a partir de datos de prueba que no han sido etiquetados, clasificados o categorizados. En lugar de responder a la retroalimentación, el aprendizaje no supervisado identifica puntos en común en los datos y reacciona en función de la presencia o ausencia de dichos puntos en común en cada nuevo dato.
En los problemas de agrupamiento dividimos los ejemplos de entrenamiento por características desconocidas. El propio algoritmo decide qué característica utilizar para dividir.
Ejemplos de uso: segmentación de mercado, análisis de redes sociales, organización de clusters informáticos, análisis de datos astronómicos, compresión de imágenes, etc.
petal_length y petal_widthLa detección de anomalías (también detección de valores atípicos) es la identificación de elementos, eventos u observaciones raros que generan sospechas al diferir significativamente de la mayoría de los datos.
Ejemplos de uso: detección de intrusiones, detección de fraude, monitoreo del estado del sistema, eliminación de datos anómalos del conjunto de datos, etc.
latency y threshold La red neuronal en sí no es un algoritmo, sino más bien un marco para que muchos algoritmos diferentes de aprendizaje automático trabajen juntos y procesen entradas de datos complejas.
Ejemplos de uso: como sustituto de todos los demás algoritmos en general, reconocimiento de imágenes, reconocimiento de voz, procesamiento de imágenes (aplicando un estilo específico), traducción de idiomas, etc.
28x28 píxeles28x28 píxeles 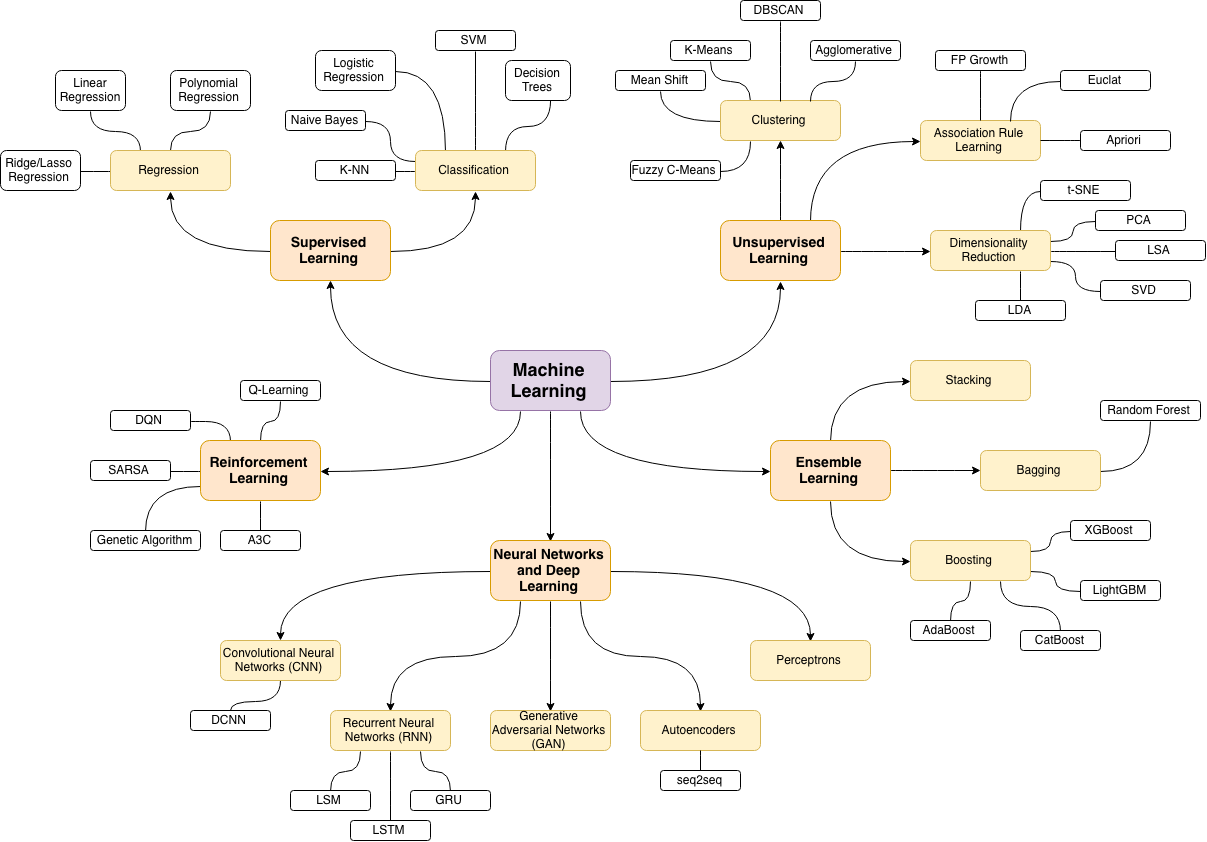
La fuente del siguiente mapa de temas de aprendizaje automático es esta maravillosa publicación de blog.
Asegúrese de tener Python instalado en su máquina.
Es posible que desee utilizar la biblioteca Python estándar de venv para crear entornos virtuales y tener Python, pip y todos los paquetes dependientes para instalarlos y servirlos desde el directorio del proyecto local para evitar problemas con los paquetes de todo el sistema y sus versiones.
Instale todas las dependencias necesarias para el proyecto ejecutando:
pip install -r requirements.txtTodas las demostraciones del proyecto se pueden ejecutar directamente en su navegador sin instalar Jupyter localmente. Pero si desea iniciar Jupyter Notebook localmente, puede hacerlo ejecutando el siguiente comando desde la carpeta raíz del proyecto:
jupyter notebook Después de esto, se podrá acceder a Jupyter Notebook mediante http://localhost:8888 .
Cada sección de algoritmo contiene enlaces de demostración a Jupyter NBViewer. Esta es una vista previa rápida en línea para portátiles Jupyter donde puede ver códigos de demostración, gráficos y datos directamente en su navegador sin instalar nada localmente. En caso de que desee cambiar el código y experimentar con el cuaderno de demostración, deberá iniciar el cuaderno en Binder. Puede hacerlo simplemente haciendo clic en el enlace "Ejecutar en Binder" en la esquina superior derecha de NBViewer.
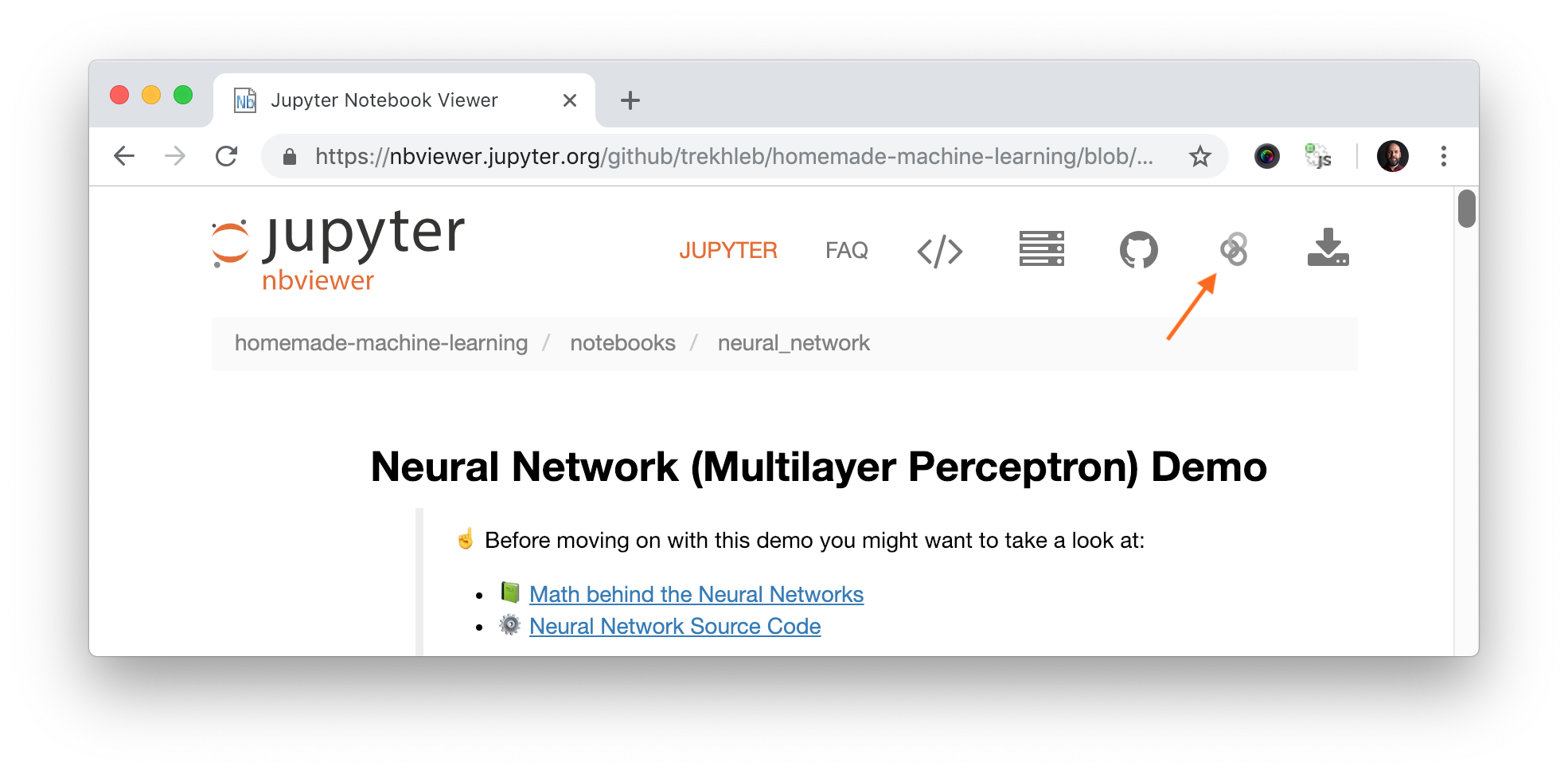
La lista de conjuntos de datos que se utilizan para las demostraciones de Jupyter Notebook se puede encontrar en la carpeta de datos.
Puedes apoyar este proyecto a través de ❤️️ GitHub o ❤️️ Patreon.


