vaex
Version linked to the paper
Vaex es una biblioteca de Python de alto rendimiento para marcos de datos fuera del núcleo (similares a Pandas), para visualizar y explorar grandes conjuntos de datos tabulares. Calcula estadísticas como media, suma, recuento, desviación estándar, etc., en una cuadrícula de N dimensiones para más de mil millones ( 10^9 ) muestras/filas por segundo . La visualización se realiza mediante histogramas , gráficos de densidad y renderizado de volúmenes 3D , lo que permite la exploración interactiva de big data. Vaex utiliza mapeo de memoria, política de copia de memoria cero y cálculos diferidos para obtener el mejor rendimiento (sin desperdiciar memoria).
Con pepita:
$ pip install vaex
O conda:
$ conda install -c conda-forge vaex
Para más detalles, consulte la documentación.
Compatible con HDF5 y Apache Arrow.

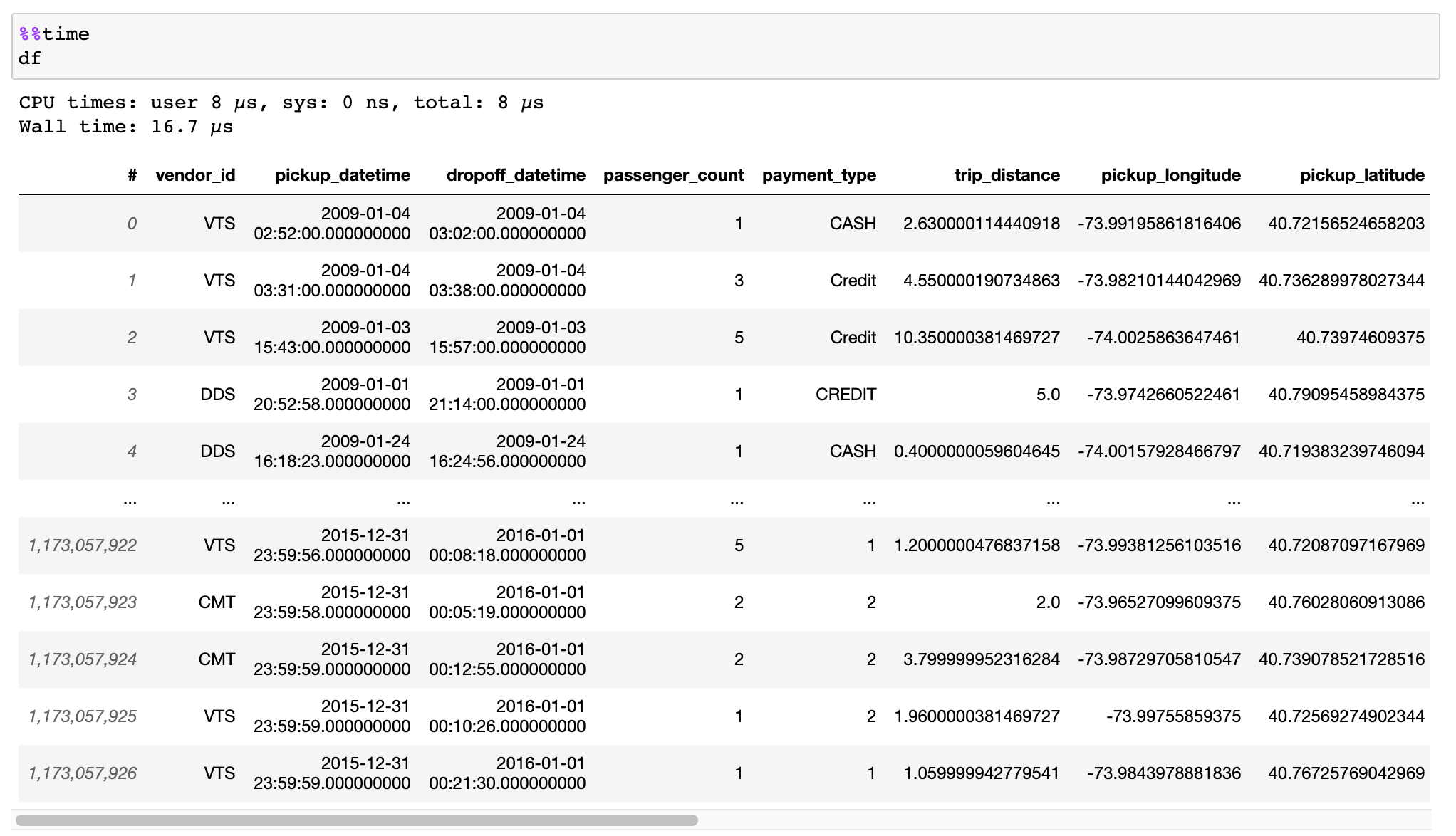
Lea la documentación sobre cómo convertir de manera eficiente sus datos desde archivos CSV, Pandas DataFrames u otras fuentes.
Se admite transmisión diferida desde S3 en combinación con mapeo de memoria.

No pierda memoria ni tiempo con la ingeniería de funciones, transformamos (perezosamente) sus datos cuando sea necesario.
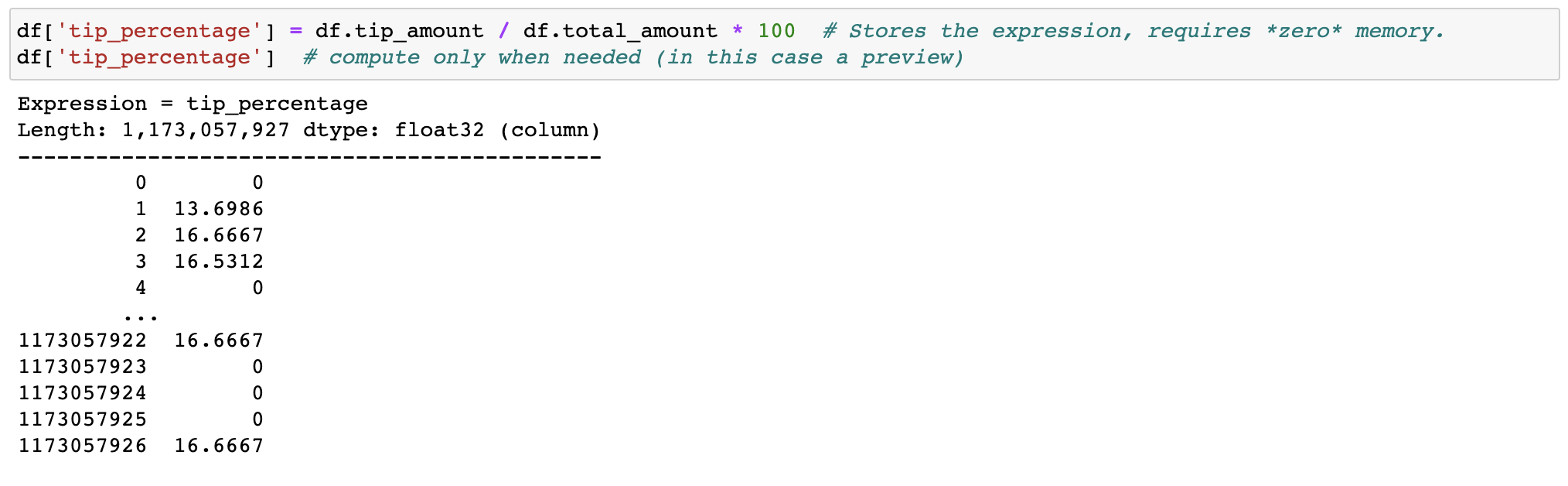
Filtrar y evaluar expresiones no desperdiciará memoria al hacer copias; los datos se mantienen intactos en el disco y se transmitirán solo cuando sea necesario. Retrase el tiempo antes de que necesite un clúster.
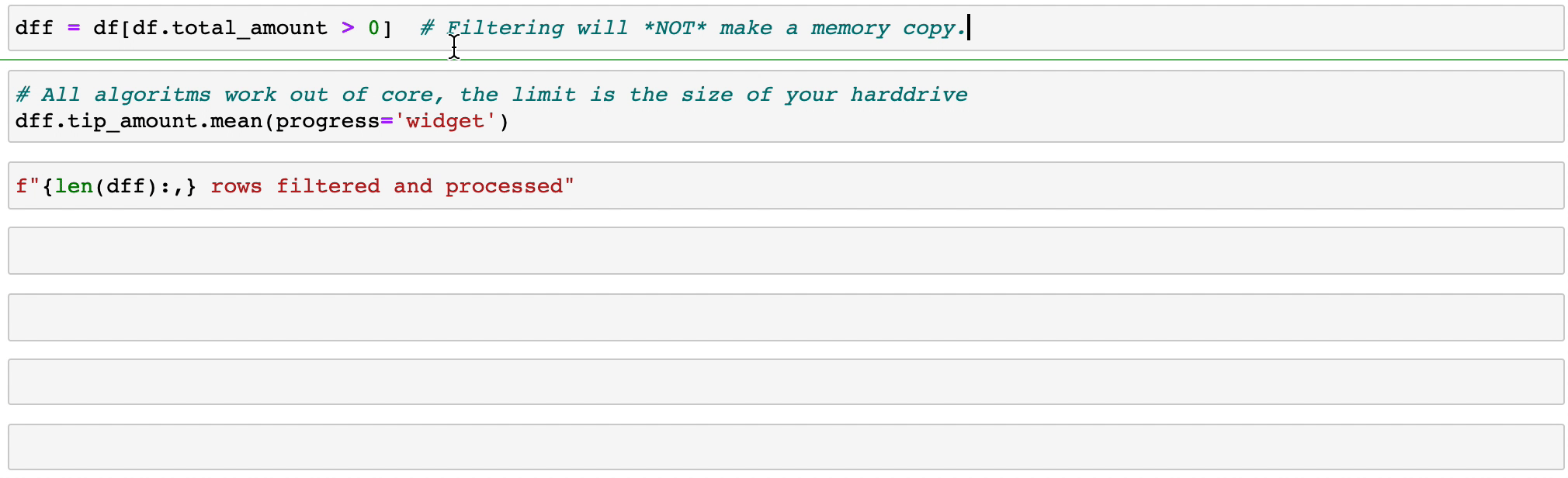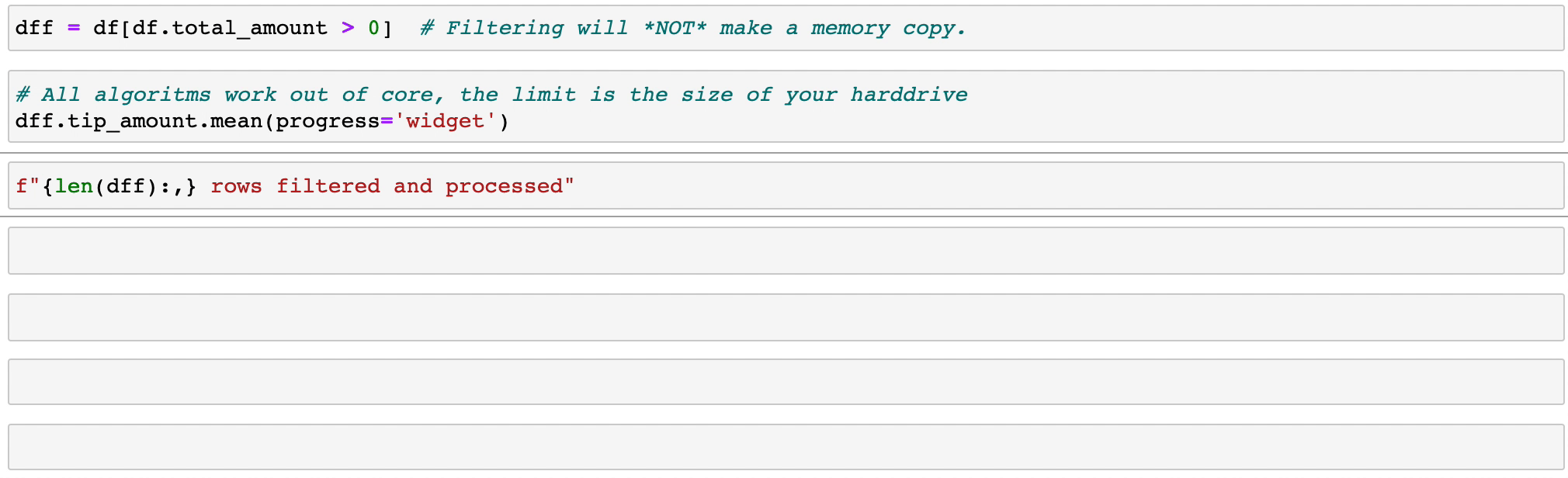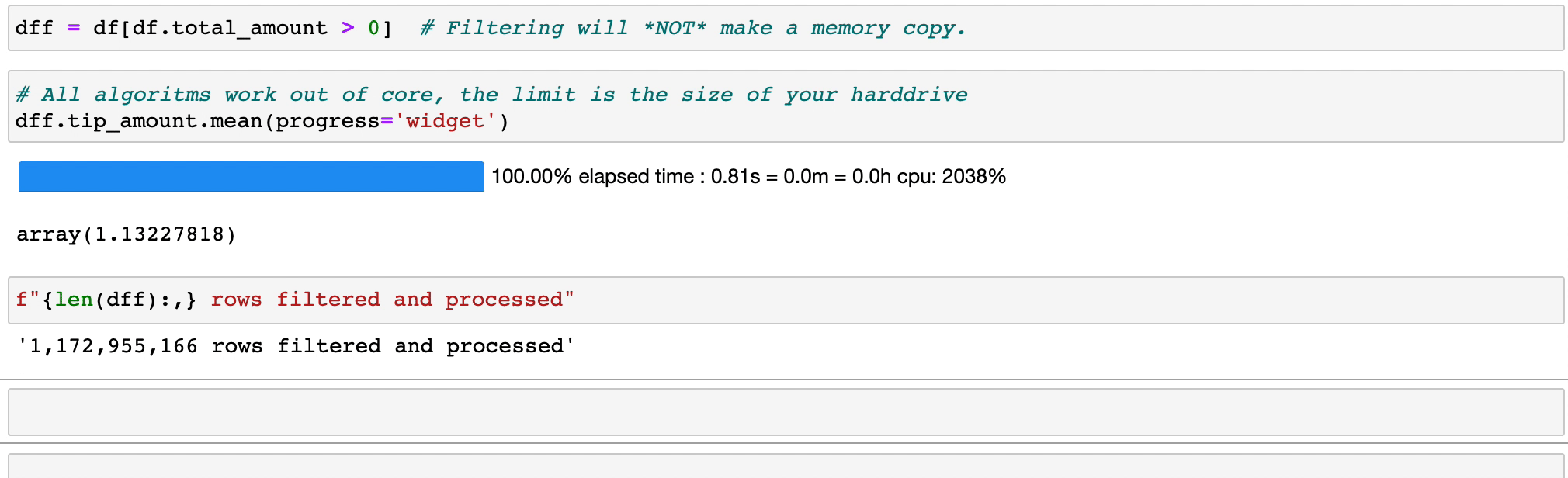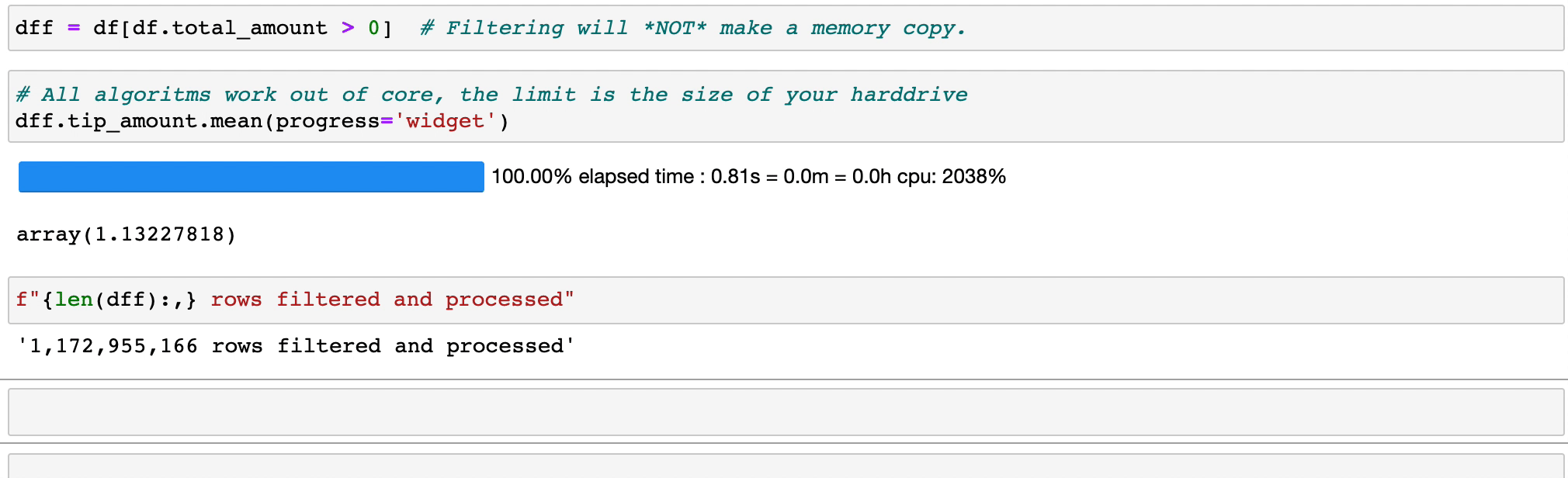
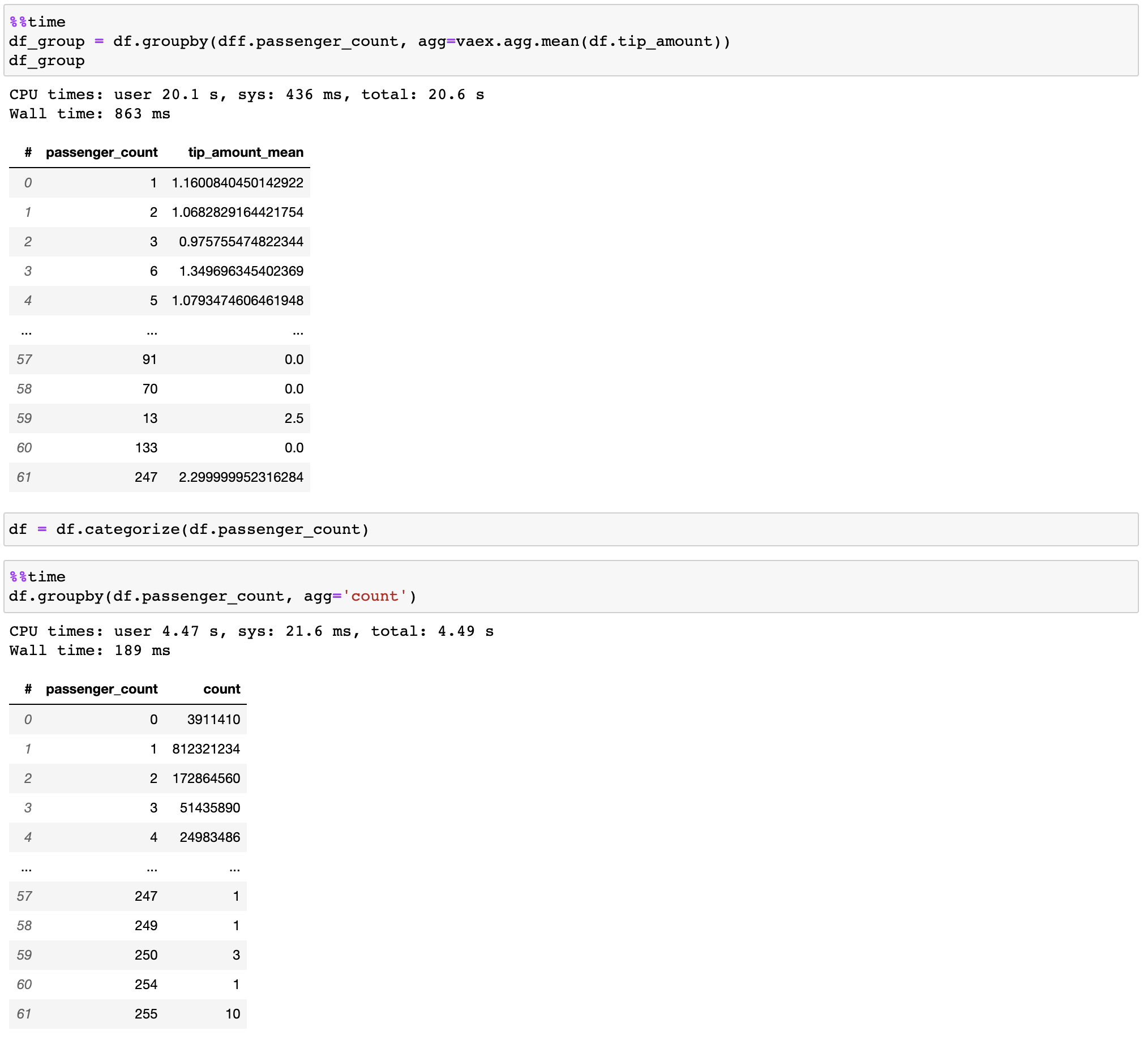
Vaex implementa operaciones groupby paralelizadas y de alto rendimiento, especialmente cuando se utilizan categorías (>1 mil millones/segundo).
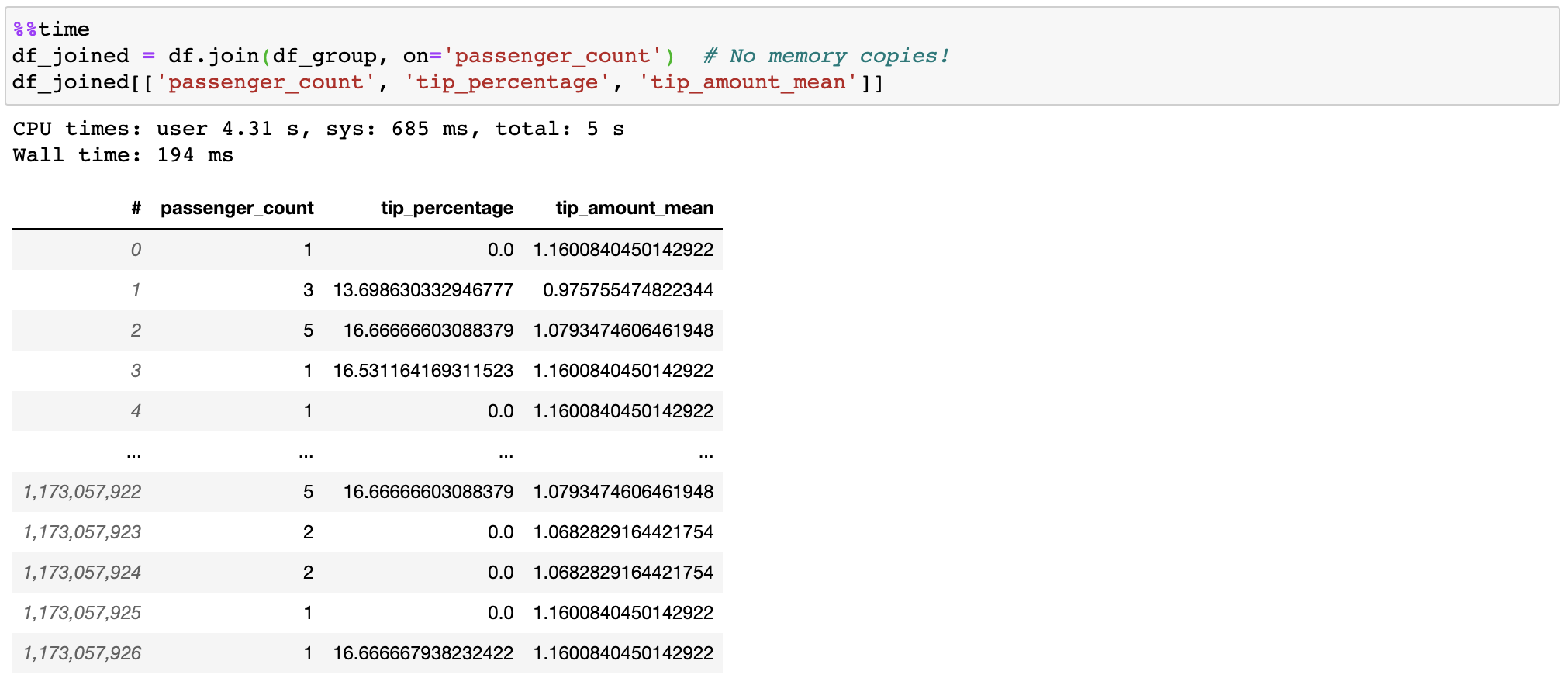
Vaex no copia/materializa la tabla "correcta" al unirse, lo que ahorra gigabytes de memoria. Con uniones de menos de un segundo en mil millones de filas, ¡es bastante rápido!
Ver página de contribución.
¡Únase a la discusión en nuestro canal Slack!
Artículos
Sigue nuestros tutoriales
Mire nuestras charlas más recientes:
Contáctenos para soluciones de ciencia de datos, capacitación o soporte empresarial en https://vaex.io/


