stumpy
v1.13.0

STUMPY es una biblioteca Python potente y escalable que calcula eficientemente algo llamado perfil de matriz, que es solo una forma académica de decir "para cada subsecuencia (verde) dentro de su serie temporal, identifique automáticamente su correspondiente vecino más cercano (gris)":
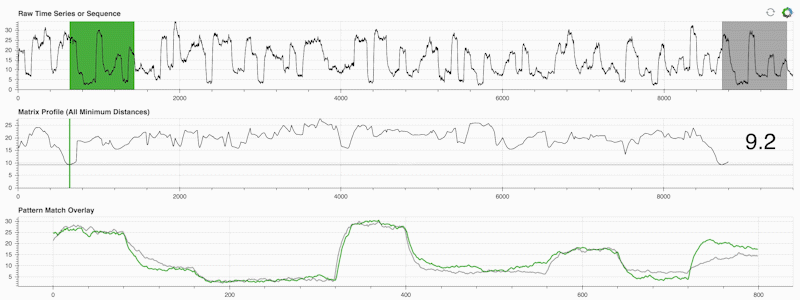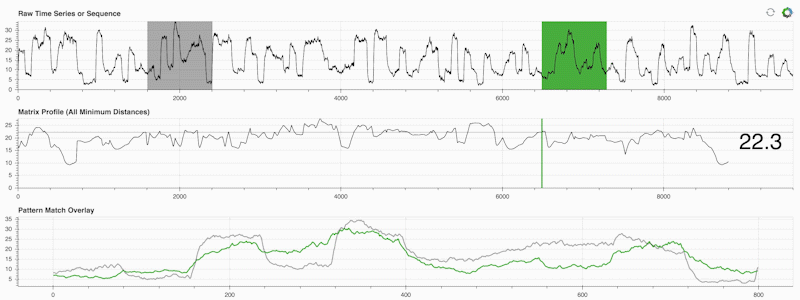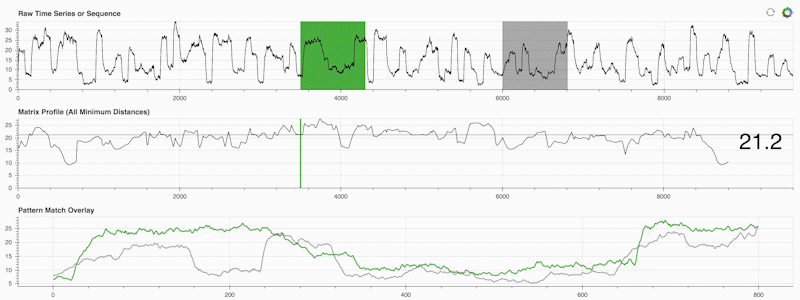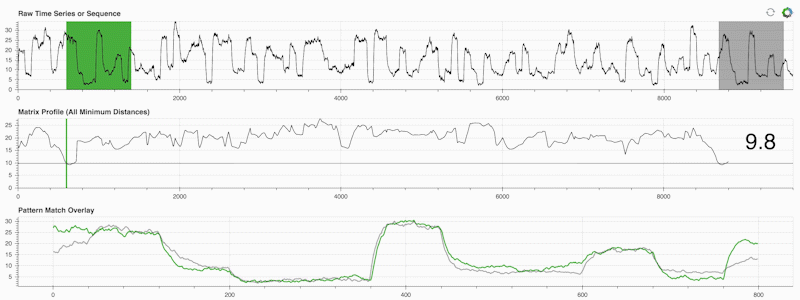
Lo importante es que una vez que haya calculado su perfil de matriz (panel central arriba), podrá utilizarlo para una variedad de tareas de minería de datos de series temporales, como:
Ya sea que sea un académico, un científico de datos, un desarrollador de software o un entusiasta de las series temporales, STUMPY es fácil de instalar y nuestro objetivo es permitirle obtener información sobre series temporales más rápido. Consulte la documentación para obtener más información.
Consulte nuestra documentación de API para obtener una lista completa de las funciones disponibles y consulte nuestros tutoriales informativos para ver casos de uso de ejemplo más completos. A continuación, encontrará fragmentos de código que demuestran rápidamente cómo utilizar STUMPY.
Uso típico (datos de series temporales unidimensionales) con STUMP:
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )Uso distribuido para datos de series temporales unidimensionales con Dask Distribuido a través de STUMPED:
import stumpy
import numpy as np
from dask . distributed import Client
if __name__ == "__main__" :
with Client () as dask_client :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stumped ( dask_client , your_time_series , m = window_size )Uso de GPU para datos de series temporales unidimensionales con GPU-STUMP:
import stumpy
import numpy as np
from numba import cuda
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
all_gpu_devices = [ device . id for device in cuda . list_devices ()] # Get a list of all available GPU devices
matrix_profile = stumpy . gpu_stump ( your_time_series , m = window_size , device_id = all_gpu_devices )Datos de series temporales multidimensionales con MSTUMP:
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 3 , 1000 ) # Each row represents data from a different dimension while each column represents data from the same dimension
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile , matrix_profile_indices = stumpy . mstump ( your_time_series , m = window_size )Análisis distribuido de datos de series temporales multidimensionales con Dask Distributed MSTUMPED:
import stumpy
import numpy as np
from dask . distributed import Client
if __name__ == "__main__" :
with Client () as dask_client :
your_time_series = np . random . rand ( 3 , 1000 ) # Each row represents data from a different dimension while each column represents data from the same dimension
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile , matrix_profile_indices = stumpy . mstumped ( dask_client , your_time_series , m = window_size )Cadenas de series temporales con cadenas de series temporales ancladas (ATSC):
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )
left_matrix_profile_index = matrix_profile [:, 2 ]
right_matrix_profile_index = matrix_profile [:, 3 ]
idx = 10 # Subsequence index for which to retrieve the anchored time series chain for
anchored_chain = stumpy . atsc ( left_matrix_profile_index , right_matrix_profile_index , idx )
all_chain_set , longest_unanchored_chain = stumpy . allc ( left_matrix_profile_index , right_matrix_profile_index )Segmentación semántica con segmentación semántica unipotente rápida y de bajo costo (FLUSS):
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )
subseq_len = 50
correct_arc_curve , regime_locations = stumpy . fluss ( matrix_profile [:, 1 ],
L = subseq_len ,
n_regimes = 2 ,
excl_factor = 1
)Las versiones admitidas de Python y NumPy se determinan de acuerdo con la política de obsolescencia de NEP 29.
Instalación de Conda (preferida):
conda install -c conda-forge stumpyInstalación de PyPI, suponiendo que tenga instalados numpy, scipy y numba:
python -m pip install stumpyPara instalar stumpy desde el código fuente, consulte las instrucciones en la documentación.
Para comprender y apreciar completamente los algoritmos y aplicaciones subyacentes, es imperativo que lea las publicaciones originales. Para obtener un ejemplo más detallado de cómo utilizar STUMPY, consulte la documentación más reciente o explore nuestros tutoriales prácticos.
Probamos el rendimiento de calcular el perfil de matriz exacto utilizando la versión compilada del código Numba JIT en datos de series de tiempo generados aleatoriamente con varias longitudes (es decir, np.random.rand(n) ) junto con diferentes recursos de hardware de CPU y GPU.
Los resultados sin procesar se muestran en la siguiente tabla como Horas:Minutos:Segundos.Milisegundos y con un tamaño de ventana constante de m = 50. Tenga en cuenta que estos tiempos de ejecución informados incluyen el tiempo que lleva mover los datos desde el host a todos los Dispositivo(s) GPU. Es posible que tengas que desplazarte hacia el lado derecho de la tabla para ver todos los tiempos de ejecución.
| i | norte = 2 yo | GPU-STOMP | MUÑÓN.2 | TOCÓN.16 | DESCONECTADO.128 | DESCONECTADO.256 | GPU-STUMP.1 | GPU-STUMP.2 | GPU-STUMP.DGX1 | GPU-STUMP.DGX2 |
|---|---|---|---|---|---|---|---|---|---|---|
| 6 | 64 | 00:00:10.00 | 00:00:00.00 | 00:00:00.00 | 00:00:05.77 | 00:00:06.08 | 00:00:00.03 | 00:00:01.63 | Yaya | Yaya |
| 7 | 128 | 00:00:10.00 | 00:00:00.00 | 00:00:00.00 | 00:00:05.93 | 00:00:07.29 | 00:00:00.04 | 00:00:01.66 | Yaya | Yaya |
| 8 | 256 | 00:00:10.00 | 00:00:00.00 | 00:00:00.01 | 00:00:05.95 | 00:00:07.59 | 00:00:00.08 | 00:00:01.69 | 00:00:06.68 | 00:00:25.68 |
| 9 | 512 | 00:00:10.00 | 00:00:00.00 | 00:00:00.02 | 00:00:05.97 | 00:00:07.47 | 00:00:00.13 | 00:00:01.66 | 00:00:06.59 | 00:00:27.66 |
| 10 | 1024 | 00:00:10.00 | 00:00:00.02 | 00:00:00.04 | 00:00:05.69 | 00:00:07.64 | 00:00:00.24 | 00:00:01.72 | 00:00:06.70 | 00:00:30.49 |
| 11 | 2048 | Yaya | 00:00:00.05 | 00:00:00.09 | 00:00:05.60 | 00:00:07.83 | 00:00:00.53 | 00:00:01.88 | 00:00:06.87 | 00:00:31.09 |
| 12 | 4096 | Yaya | 00:00:00.22 | 00:00:00.19 | 00:00:06.26 | 00:00:07.90 | 00:00:01.04 | 00:00:02.19 | 00:00:06.91 | 00:00:33.93 |
| 13 | 8192 | Yaya | 00:00:00.50 | 00:00:00.41 | 00:00:06.29 | 00:00:07.73 | 00:00:01.97 | 00:00:02.49 | 00:00:06.61 | 00:00:33.81 |
| 14 | 16384 | Yaya | 00:00:01.79 | 00:00:00.99 | 00:00:06.24 | 00:00:08.18 | 00:00:03.69 | 00:00:03.29 | 00:00:07.36 | 00:00:35.23 |
| 15 | 32768 | Yaya | 00:00:06.17 | 00:00:02.39 | 00:00:06.48 | 00:00:08.29 | 00:00:07.45 | 00:00:04.93 | 00:00:07.02 | 00:00:36.09 |
| 16 | 65536 | Yaya | 00:00:22.94 | 00:00:06.42 | 00:00:07.33 | 00:00:09.01 | 00:00:14.89 | 00:00:08.12 | 00:00:08.10 | 00:00:36.54 |
| 17 | 131072 | 00:00:10.00 | 00:01:29.27 | 00:00:19.52 | 00:00:09.75 | 00:00:10.53 | 00:00:29.97 | 00:00:15.42 | 00:00:09.45 | 00:00:37.33 |
| 18 | 262144 | 00:00:18.00 | 00:05:56.50 | 00:01:08.44 | 00:00:33.38 | 00:00:24.07 | 00:00:59.62 | 00:00:27.41 | 00:00:13.18 | 00:00:39.30 |
| 19 | 524288 | 00:00:46.00 | 00:25:34.58 | 00:03:56.82 | 00:01:35.27 | 00:03:43.66 | 00:01:56.67 | 00:00:54.05 | 00:00:19.65 | 00:00:41.45 |
| 20 | 1048576 | 00:02:30.00 | 01:51:13.43 | 00:19:54.75 | 00:04:37.15 | 00:03:01.16 | 00:05:06.48 | 00:02:24.73 | 00:00:32.95 | 00:00:46.14 |
| 21 | 2097152 | 00:09:15.00 | 09:25:47.64 | 03:05:07.64 | 00:13:36.51 | 00:08:47.47 | 00:20:27.94 | 00:09:41.43 | 00:01:06.51 | 00:01:02.67 |
| 22 | 4194304 | Yaya | 36:12:23.74 | 10:37:51.21 | 00:55:44.43 | 00:32:06.70 | 01:21:12.33 | 00:38:30.86 | 00:04:03.26 | 00:02:23.47 |
| 23 | 8388608 | Yaya | 143:16:09.94 | 38:42:51.42 | 03:33:30.53 | 02:00:49.37 | 05:11:44.45 | 02:33:14.60 | 00:15:46.26 | 00:08:03.76 |
| 24 | 16777216 | Yaya | Yaya | Yaya | 14:39:11.99 | 07:13:47.12 | 20:43:03.80 | 09:48:43.42 | 01:00:24.06 | 00:29:07.84 |
| Yaya | 17729800 | 09:16:12.00 | Yaya | Yaya | 15:31:31.75 | 07:18:42.54 | 23:09:22.43 | 10:54:08.64 | 01:07:35.39 | 00:32:51.55 |
| 25 | 33554432 | Yaya | Yaya | Yaya | 56:03:46.81 | 26:27:41.29 | 83:29:21.06 | 39:17:43.82 | 03:59:32.79 | 01:54:56.52 |
| 26 | 67108864 | Yaya | Yaya | Yaya | 211:17:37.60 | 106:40:17.17 | 328:58:04.68 | 157:18:30.50 | 15:42:15.94 | 07:18:52.91 |
| Yaya | 100000000 | 291:07:12.00 | Yaya | Yaya | Yaya | 234:51:35.39 | Yaya | Yaya | 35:03:44.61 | 16:22:40.81 |
| 27 | 134217728 | Yaya | Yaya | Yaya | Yaya | Yaya | Yaya | Yaya | 64:41:55.09 | 29:13:48.12 |
GPU-STOMP: Estos resultados se reproducen del documento Matrix Profile II original: NVIDIA Tesla K80 (contiene 2 GPU) y sirven como punto de referencia de rendimiento con el que comparar.
STUMP.2: stumpy.stump ejecutado con 2 CPU en total: 2 procesadores Intel(R) Xeon(R) CPU E5-2650 v4 a 2,20 GHz paralelizados con Numba en un solo servidor sin Dask.
STUMP.16: stumpy.stump ejecutado con 16 CPU en total: 16 procesadores Intel(R) Xeon(R) CPU E5-2650 v4 a 2,20 GHz paralelizados con Numba en un único servidor sin Dask.
STUMPED.128: stumpy.stumped ejecutado con 128 CPU en total: 8 procesadores Intel(R) Xeon(R) CPU E5-2650 v4 a 2,20 GHz x 16 servidores, paralelizados con Numba y distribuidos con Dask Distributed.
STUMPED.256: stumpy.stumped ejecutado con 256 CPU en total: 8 procesadores Intel(R) Xeon(R) CPU E5-2650 v4 a 2,20 GHz x 32 servidores, paralelizados con Numba y distribuidos con Dask Distributed.
GPU-STUMP.1: stumpy.gpu_stump ejecutado con 1 GPU NVIDIA GeForce GTX 1080 Ti, 512 subprocesos por bloque, límite de potencia de 200 W, compilado en CUDA con Numba y paralelizado con multiprocesamiento de Python
GPU-STUMP.2: stumpy.gpu_stump ejecutado con 2 GPU NVIDIA GeForce GTX 1080 Ti, 512 subprocesos por bloque, límite de potencia de 200 W, compilado en CUDA con Numba y paralelizado con multiprocesamiento de Python
GPU-STUMP.DGX1: stumpy.gpu_stump ejecutado con 8x NVIDIA Tesla V100, 512 subprocesos por bloque, compilado en CUDA con Numba y paralelizado con multiprocesamiento de Python
GPU-STUMP.DGX2: stumpy.gpu_stump ejecutado con 16x NVIDIA Tesla V100, 512 subprocesos por bloque, compilado en CUDA con Numba y paralelizado con multiprocesamiento de Python
Las pruebas se escriben en el directorio tests y se procesan mediante PyTest y requieren coverage.py para el análisis de cobertura del código. Las pruebas se pueden ejecutar con:
./test.shSTUMPY es compatible con Python 3.9+ y, debido al uso de nombres/identificadores de variables Unicode, no es compatible con Python 2.x. Dadas las pequeñas dependencias, STUMPY puede funcionar en versiones anteriores de Python, pero esto está fuera del alcance de nuestro soporte y le recomendamos encarecidamente que actualice a la versión más reciente de Python.
Primero, consulte las discusiones y problemas en Github para ver si su pregunta ya ha sido respondida allí. Si no hay una solución disponible, no dude en abrir una nueva discusión o problema y los autores intentarán responder de manera razonablemente oportuna.
¡Agradecemos contribuciones en cualquier forma! La ayuda con la documentación, en particular los tutoriales en expansión, siempre es bienvenida. Para contribuir, bifurque el proyecto, realice sus cambios y envíe una solicitud de extracción. Haremos todo lo posible para solucionar cualquier problema con usted y fusionar su código en la rama principal.
Si ha utilizado este código base en una publicación científica y desea citarlo, utilice el artículo del Journal of Open Source Software.
Ley SM, (2019). STUMPY: una biblioteca Python potente y escalable para minería de datos de series temporales . Revista de software de código abierto, 4(39), 1504.
@article { law2019stumpy ,
author = { Law, Sean M. } ,
title = { {STUMPY: A Powerful and Scalable Python Library for Time Series Data Mining} } ,
journal = { {The Journal of Open Source Software} } ,
volume = { 4 } ,
number = { 39 } ,
pages = { 1504 } ,
year = { 2019 }
}Sí, Chin-Chia Michael, et al. (2016) Perfil de matriz I: uniones de similitud de todos los pares para series temporales: una vista unificadora que incluye motivos, discordias y formas. ICDM: 1317-1322. Enlace
Zhu, Yan y col. (2016) Matrix Profile II: Explotación de un algoritmo novedoso y GPU para romper la barrera de los cien millones de motivos y uniones de series temporales. ICDM: 739-748. Enlace
Sí, Chin-Chia Michael, et al. (2017) Matrix Profile VI: Descubrimiento significativo de motivos multidimensionales. ICDM: 565-574. Enlace
Zhu, Yan y col. (2017) Matrix Profile VII: Cadenas de series temporales: un nuevo primitivo para la minería de datos de series temporales. ICDM: 695-704. Enlace
Gharghabi, Shaghayegh y otros. (2017) Matrix Profile VIII: Segmentación semántica en línea independiente del dominio en niveles de rendimiento sobrehumanos. ICDM: 117-126. Enlace
Zhu, Yan y col. (2017) Explotación de un algoritmo novedoso y GPU para romper la barrera de los diez mil billones de comparaciones por pares para uniones y motivos de series temporales. KAI:203-236. Enlace
Zhu, Yan y col. (2018) Matrix Profile XI: SCRIMP++: descubrimiento de motivos de series temporales a velocidades interactivas. ICDM: 837-846. Enlace
Sí, Chin-Chia Michael, et al. (2018) Uniones de series temporales, motivos, discordias y formas: una vista unificadora que explota el perfil de la matriz. Disco de conocimiento mínimo de datos: 83-123. Enlace
Gharghabi, Shaghayegh y otros. (2018) "Perfil de matriz XII: MPdist: una nueva medida de distancia de series temporales para permitir la extracción de datos en escenarios más desafiantes". ICDM: 965-970. Enlace
Zimmerman, Zachary y otros. (2019) Matrix Profile XIV: Ampliación del descubrimiento de motivos de series temporales con GPU para romper un trillón de comparaciones por pares por día y más. SoCC '19:74-86. Enlace
Akbarinia, Reza y Betrand Cloez. (2019) Cálculo eficiente del perfil matricial utilizando diferentes funciones de distancia. arXiv:1901.05708. Enlace
Kamgar, Kaveh y col. (2019) Matrix Profile XV: Explotación de motivos de consenso de series temporales para encontrar estructura en conjuntos de series temporales. ICDM: 1156-1161. Enlace


