similarity
1.1.6
similitud, calcular puntuación de similitud entre cadenas de texto, escrito en Java.
Similitud, un conjunto de herramientas de cálculo de similitud, se puede utilizar para el cálculo de similitud de texto, análisis de sentimientos, etc., escrito en Java.
Similarity es una versión Java del kit de herramientas de cálculo de similitud compuesto por una serie de algoritmos. El objetivo es difundir el método de cálculo de similitud en el procesamiento del lenguaje natural. La similitud tiene las características de herramientas prácticas, rendimiento eficiente, estructura clara, corpus actualizado y personalización.
La similitud proporciona la siguiente funcionalidad:
Cálculo de similitud de palabras
Cálculo de similitud de frases
Cálculo de similitud de oraciones
Cálculo de similitud de párrafos
CNKI Yiyuan
análisis de sentimiento
palabras aproximadas
Si bien proporcionan funciones ricas, los módulos internos de Similarity insisten en un bajo acoplamiento, los modelos insisten en la carga diferida y los diccionarios insisten en publicar en texto sin formato. Son fáciles de usar y ayudan a los usuarios a entrenar sus propios corpus.
Introducir el paquete Jar
< repositories >
< repository >
< id >jitpack.io</ id >
< url >https://jitpack.io</ url >
</ repository >
</ repositories >< dependency >
< groupId >com.github.shibing624</ groupId >
< artifactId >similarity</ artifactId >
< version >1.1.6</ version >
</ dependency >Introducción de gradle:
import org . xm . Similarity ;
import org . xm . tendency . word . HownetWordTendency ;
public class demo {
public static void main ( String [] args ) {
double result = Similarity . cilinSimilarity ( "电动车" , "自行车" );
System . out . println ( result );
String word = "混蛋" ;
HownetWordTendency hownetWordTendency = new HownetWordTendency ();
result = hownetWordTendency . getTendency ( word );
System . out . println ( word + " 词语情感趋势值:" + result );
}
}Longitud del texto: granularidad de las palabras
Se recomienda utilizar la similitud de Cilin: org.xm.Similarity.cilinSimilarity , que es un método de cálculo de similitud basado en los sinónimos de Cilin.
ejemplo: src/test/java/org.xm/WordSimilarityDemo.java
package org . xm ;
public class WordSimilarityDemo {
public static void main ( String [] args ) {
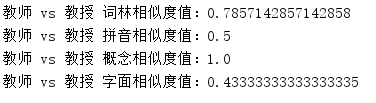
String word1 = "教师" ;
String word2 = "教授" ;
double cilinSimilarityResult = Similarity . cilinSimilarity ( word1 , word2 );
double pinyinSimilarityResult = Similarity . pinyinSimilarity ( word1 , word2 );
double conceptSimilarityResult = Similarity . conceptSimilarity ( word1 , word2 );
double charBasedSimilarityResult = Similarity . charBasedSimilarity ( word1 , word2 );
System . out . println ( word1 + " vs " + word2 + " 词林相似度值:" + cilinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 拼音相似度值:" + pinyinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 概念相似度值:" + conceptSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 字面相似度值:" + charBasedSimilarityResult );
}
}
Longitud del texto: granularidad de la frase
Se recomienda utilizar similitud de frase: org.xm.Similarity.phraseSimilarity , que es esencialmente un método para calcular la similitud de dos frases a través de los mismos caracteres y las posiciones de los mismos caracteres.
ejemplo: src/test/java/org.xm/PhraseSimilarityDemo.java
public static void main ( String [] args ) {
String phrase1 = "继续努力" ;
String phrase2 = "持续发展" ;
double result = Similarity . phraseSimilarity ( phrase1 , phrase2 );
System . out . println ( phrase1 + " vs " + phrase2 + " 短语相似度值:" + result );
}
Longitud del texto: granularidad de la oración
Se recomienda utilizar similitud de oraciones en forma y orden de palabras: org.xm.similarity.morphoSimilarity , un método de similitud que no solo considera el mismo texto literal de dos oraciones, sino que también considera el orden en que aparece el mismo texto.
ejemplo: src/test/java/org.xm/SentenceSimilarityDemo.java
public static void main ( String [] args ) {
String sentence1 = "中国人爱吃鱼" ;
String sentence2 = "湖北佬最喜吃鱼" ;
double morphoSimilarityResult = Similarity . morphoSimilarity ( sentence1 , sentence2 );
double editDistanceResult = Similarity . editDistanceSimilarity ( sentence1 , sentence2 );
double standEditDistanceResult = Similarity . standardEditDistanceSimilarity ( sentence1 , sentence2 );
double gregeorEditDistanceResult = Similarity . gregorEditDistanceSimilarity ( sentence1 , sentence2 );
System . out . println ( sentence1 + " vs " + sentence2 + " 词形词序句子相似度值:" + morphoSimilarityResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 优化的编辑距离句子相似度值:" + editDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 标准编辑距离句子相似度值:" + standEditDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " gregeor编辑距离句子相似度值:" + gregeorEditDistanceResult );
}
Longitud del texto: granularidad del párrafo (un párrafo, 25 caracteres < longitud (texto) < 500 caracteres)
Se recomienda utilizar la similitud de oraciones en el orden de las palabras: org.xm.similarity.text.CosineSimilarity , un método que considera el mismo texto en dos párrafos, lo pondera mediante la segmentación de palabras, la frecuencia de las palabras y el peso de la parte del discurso, y utiliza el coseno para calcular la similitud.
ejemplo: src/test/java/org.xm/similarity/text/CosineSimilarityTest.java
@ Test
public void getSimilarityScore () throws Exception {
String text1 = "对于俄罗斯来说,最大的战果莫过于夺取乌克兰首都基辅,也就是现任总统泽连斯基和他政府的所在地。目前夺取基辅的战斗已经打响。" ;
String text2 = "迄今为止,俄罗斯的入侵似乎没有完全按计划成功执行——英国国防部情报部门表示,在乌克兰军队激烈抵抗下,俄罗斯军队已经损失数以百计的士兵。尽管如此,俄军在继续推进。" ;
TextSimilarity cosSimilarity = new CosineSimilarity ();
double score1 = cosSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "cos相似度分值:" + score1 );
TextSimilarity editSimilarity = new EditDistanceSimilarity ();
double score2 = editSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "edit相似度分值:" + score2 );
}cos相似度分值:0.399143
edit相似度分值:0.0875ejemplo: src/test/java/org/xm/tendency/word/HownetWordTendencyTest.java
@ Test
public void getTendency () throws Exception {
HownetWordTendency hownet = new HownetWordTendency ();
String word = "美好" ;
double sim = hownet . getTendency ( word );
System . out . println ( word + ":" + sim );
System . out . println ( "混蛋:" + hownet . getTendency ( "混蛋" ));
}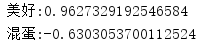
Este ejemplo es un análisis de polaridad de sentimiento granular de palabras basado en árboles de sememas. En cuanto al análisis de sentimiento de texto, existe pytextclassifier, que utiliza modelos de redes neuronales profundas y algoritmos de clasificación SVM para lograr mejores resultados.
ejemplo: src/test/java/org/xm/word2vec/Word2vecTest.java
@ Test
public void testHomoionym () throws Exception {
List < String > result = Word2vec . getHomoionym ( RAW_CORPUS_SPLIT_MODEL , "武功" , 10 );
System . out . println ( "武功 近似词:" + result );
}
@ Test
public void testHomoionymName () throws Exception {
String model = RAW_CORPUS_SPLIT_MODEL ;
List < String > result = Word2vec . getHomoionym ( model , "乔帮主" , 10 );
System . out . println ( "乔帮主 近似词:" + result );
List < String > result2 = Word2vec . getHomoionym ( model , "阿朱" , 10 );
System . out . println ( "阿朱 近似词:" + result2 );
List < String > result3 = Word2vec . getHomoionym ( model , "少林寺" , 10 );
System . out . println ( "少林寺 近似词:" + result3 );
}

El entrenamiento de vectores de palabras de Word2vec es una versión Java de la herramienta de entrenamiento de word2vec Word2VEC_java. El corpus de entrenamiento es el novedoso Tian Long Ba Bu, y los sinónimos se obtienen a través de vectores de palabras. Los usuarios pueden entrenar corpus personalizados o usar la Wikipedia china para entrenar vectores de palabras universales.
Medida de similitud de texto

El acuerdo de licencia es la Licencia Apache 2.0, que es gratuita para uso comercial. Adjunte un enlace de similitud y un acuerdo de licencia a la descripción del producto.
El código del proyecto aún es muy aproximado. Si tiene alguna mejora en el código, puede enviarlo nuevamente a este proyecto. Antes de enviarlo, preste atención a los dos puntos siguientes:
testLuego puede enviar un PR.


