cherche
2.2.1
búsqueda neuronal

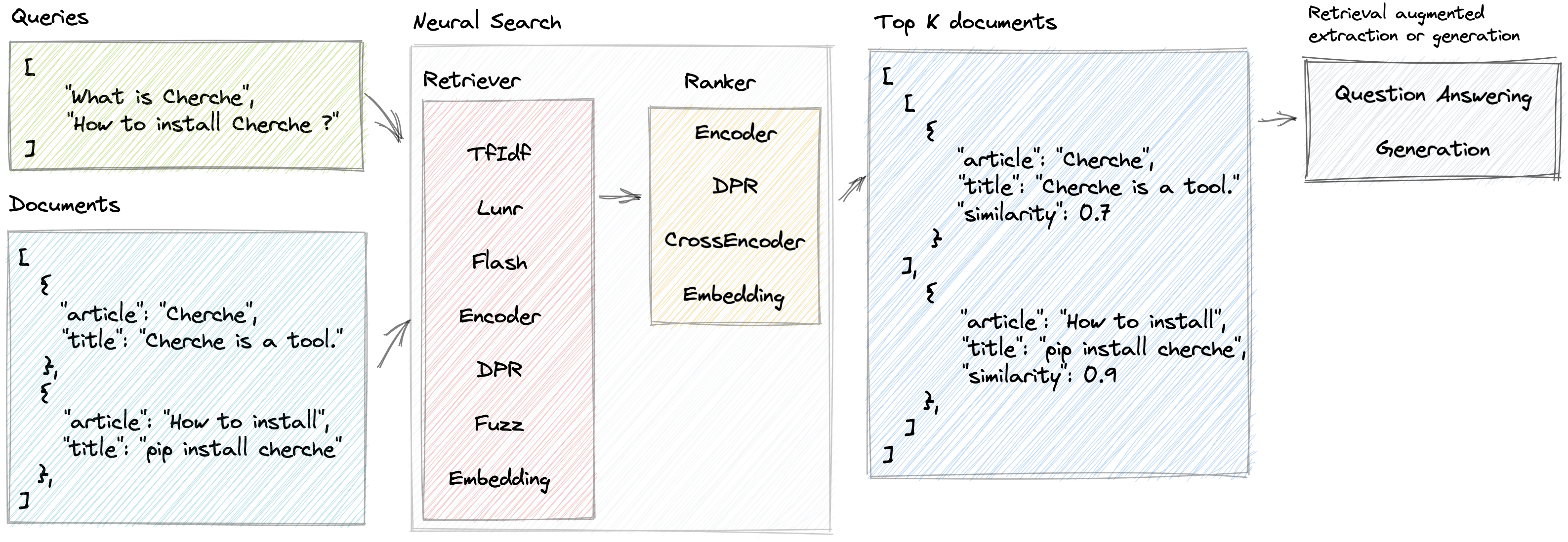
Cherche permite el desarrollo de un canal de búsqueda neuronal que emplea recuperadores y modelos de lenguaje previamente entrenados, tanto como recuperadores como clasificadores. La principal ventaja de Cherche radica en su capacidad para construir tuberías de un extremo a otro. Además, Cherche es muy adecuado para la búsqueda semántica fuera de línea debido a su compatibilidad con el cálculo por lotes.
Estas son algunas de las características que ofrece Cherche:
Demostración en vivo de un motor de búsqueda de PNL impulsado por Cherche
Para instalar Cherche y usarlo con un recuperador simple en la CPU, como TfIdf, Flash, Lunr, Fuzz, use el siguiente comando:
pip install cherchePara instalar Cherche y usarlo con cualquier recuperador o clasificador semántico en la CPU, use el siguiente comando:
pip install " cherche[cpu] "Finalmente, si planeas usar cualquier recuperador o clasificador semántico en GPU, usa el siguiente comando:
pip install " cherche[gpu] "Siguiendo estas instrucciones de instalación, podrá utilizar Cherche con los requisitos adecuados a sus necesidades.
La documentación está disponible aquí. Proporciona detalles sobre recuperadores, clasificadores, canalizaciones y ejemplos.
Cherche permite encontrar el documento correcto dentro de una lista de objetos. A continuación se muestra un ejemplo de corpus.
from cherche import data
documents = data . load_towns ()
documents [: 3 ]
[{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris is the capital and most populous city of France.' },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : "Since the 17th century, Paris has been one of Europe's major centres of science, and arts." },
{ 'id' : 2 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'The City of Paris is the centre and seat of government of the region and province of Île-de-France.'
}]A continuación se muestra un ejemplo de un canal de búsqueda neuronal compuesto por un TF-IDF que recupera documentos rápidamente, seguido de un modelo de clasificación. El modelo de clasificación clasifica los documentos producidos por el recuperador según la similitud semántica entre la consulta y los documentos. Podemos llamar a la canalización usando una lista de consultas y obtener documentos relevantes para cada consulta.
from cherche import data , retrieve , rank
from sentence_transformers import SentenceTransformer
from lenlp import sparse
# List of dicts
documents = data . load_towns ()
# Retrieve on fields title and article
retriever = retrieve . BM25 (
key = "id" ,
on = [ "title" , "article" ],
documents = documents ,
k = 30
)
# Rank on fields title and article
ranker = rank . Encoder (
key = "id" ,
on = [ "title" , "article" ],
encoder = SentenceTransformer ( "sentence-transformers/all-mpnet-base-v2" ). encode ,
k = 3 ,
)
# Pipeline creation
search = retriever + ranker
search . add ( documents = documents )
# Search documents for 3 queries.
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 , 'similarity' : 0.69513524 },
{ 'id' : 63 , 'similarity' : 0.6214994 },
{ 'id' : 65 , 'similarity' : 0.61809087 }],
[{ 'id' : 16 , 'similarity' : 0.59158516 },
{ 'id' : 0 , 'similarity' : 0.58217555 },
{ 'id' : 1 , 'similarity' : 0.57944715 }],
[{ 'id' : 26 , 'similarity' : 0.6925601 },
{ 'id' : 37 , 'similarity' : 0.63977146 },
{ 'id' : 28 , 'similarity' : 0.62772334 }]]Podemos asignar el índice a los documentos para acceder a sus contenidos mediante canalizaciones:
search += documents
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.69513524 },
{ 'id' : 63 ,
'title' : 'Bordeaux' ,
'similarity' : 0.6214994 },
{ 'id' : 65 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.61809087 }],
[{ 'id' : 16 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris received 12.' ,
'similarity' : 0.59158516 },
{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.58217555 },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.57944715 }],
[{ 'id' : 26 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.6925601 },
{ 'id' : 37 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.63977146 },
{ 'id' : 28 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.62772334 }]]Cherche proporciona recuperadores que filtran documentos de entrada según una consulta.
Cherche proporciona clasificadores que filtran documentos en la salida de los recuperadores.
Los clasificadores Cherche son compatibles con los modelos SentenceTransformers que están disponibles en el centro Hugging Face.
Cherche proporciona módulos dedicados a la respuesta a preguntas. Estos módulos son compatibles con los modelos previamente entrenados de Hugging Face y están completamente integrados en los canales de búsqueda neuronal.
Cherche fue creado para/por Renault y ahora está disponible para todos. Damos la bienvenida a todas las contribuciones.

Lunr retriever es un contenedor de Lunr.py. Flash Retriever es un contenedor de FlashText. Los clasificadores DPR, Encode y CrossEncoder son contenedores dedicados al uso de modelos previamente entrenados de SentenceTransformers en un canal de búsqueda neuronal.
Si utiliza cherche para producir resultados para su publicación científica, consulte nuestro artículo SIGIR:
@inproceedings { Sourty2022sigir ,
author = { Raphael Sourty and Jose G. Moreno and Lynda Tamine and Francois-Paul Servant } ,
title = { CHERCHE: A new tool to rapidly implement pipelines in information retrieval } ,
booktitle = { Proceedings of SIGIR 2022 } ,
year = { 2022 }
}El equipo de desarrollo de Cherche está formado por Raphaël Sourty, François-Paul Servant, Nicolas Bizzozzero y Jose G Moreno. ?


