doc genius ai
v1.0

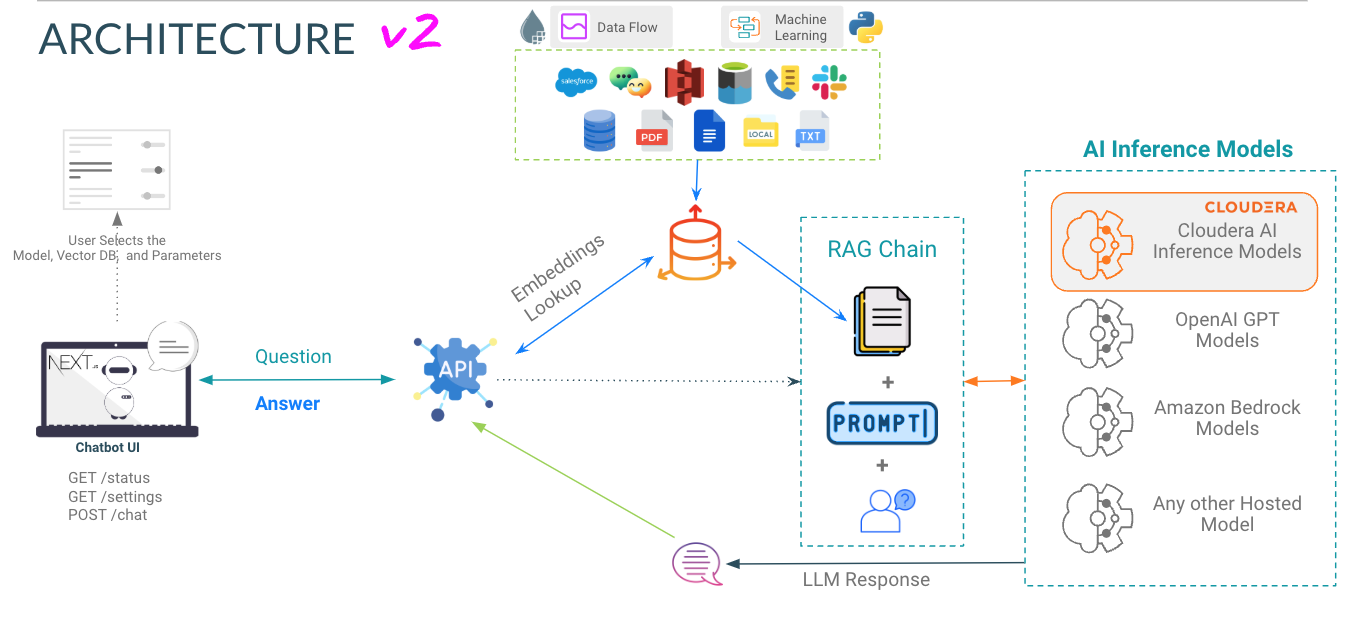
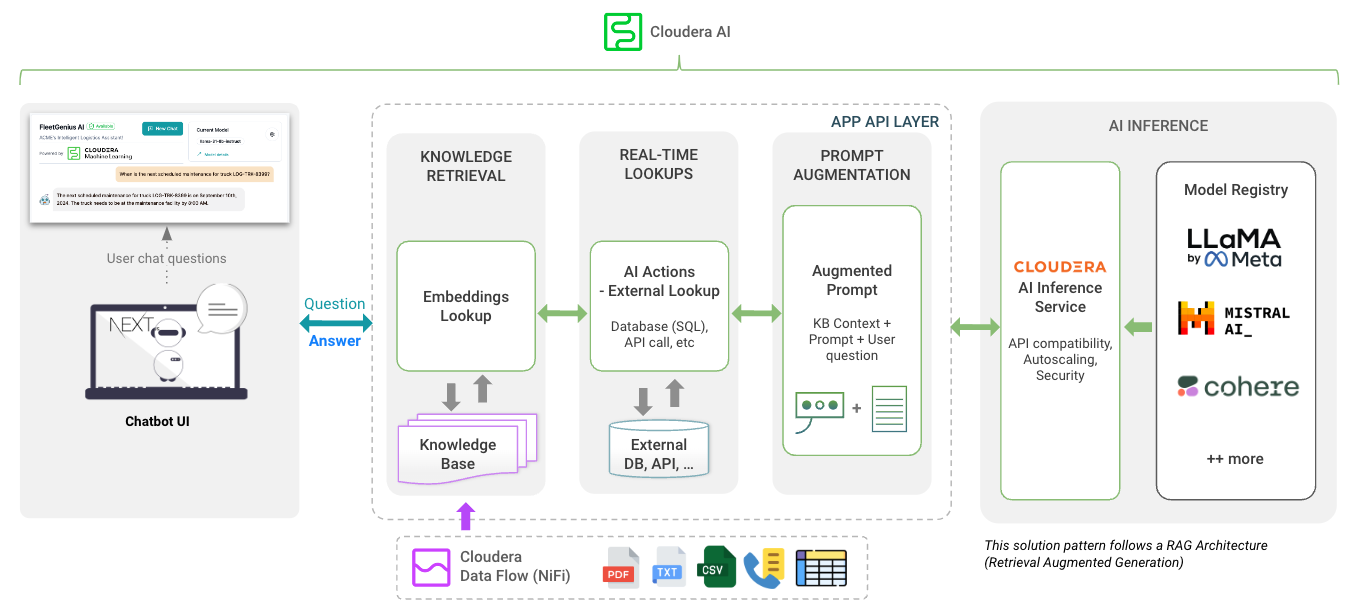
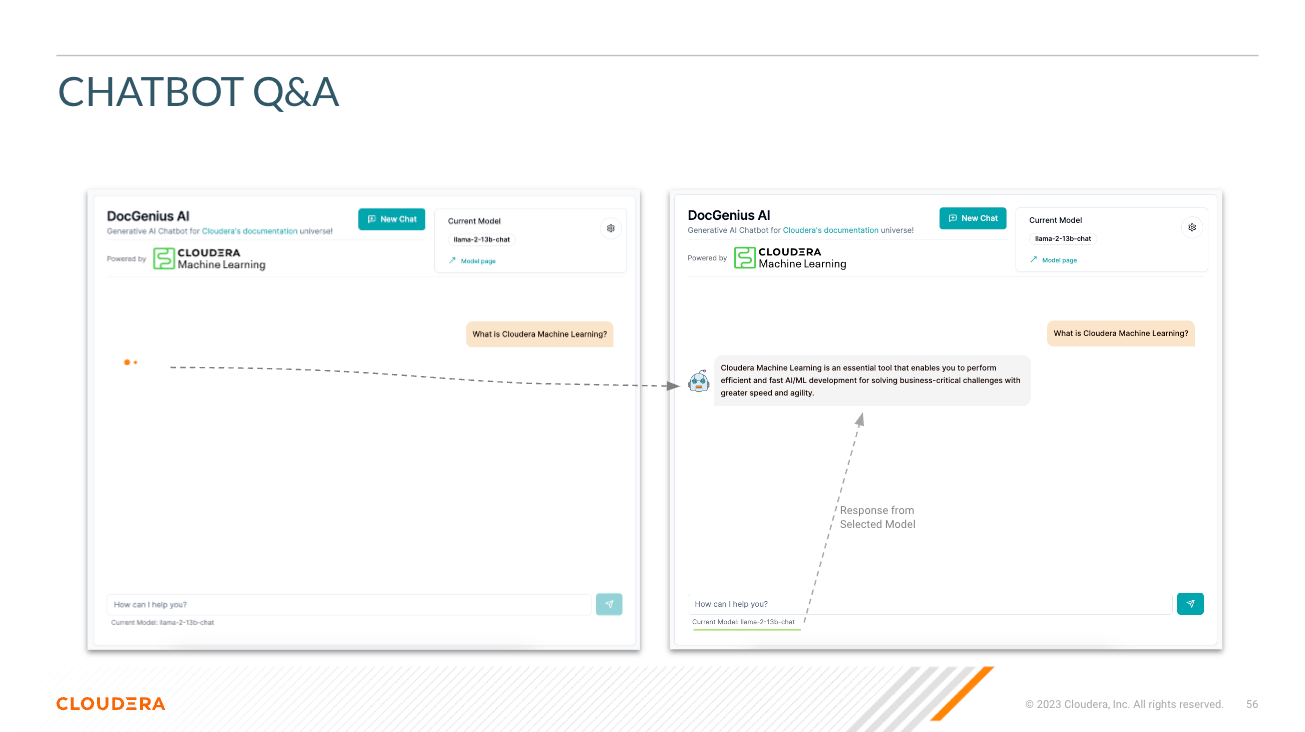
Seleccionar modelo : aquí el usuario puede seleccionar el modelo de chat de parámetros Llama3 70B ( llama-3-70b ).
Seleccione Temperatura (aleatoriedad de respuesta) : aquí el usuario puede escalar la aleatoriedad de la respuesta del modelo. Los números más bajos garantizan una respuesta más aproximada y objetiva, mientras que los números más altos fomentan la creatividad del modelo.
Seleccione el número de tokens (duración de la respuesta) : aquí se han proporcionado varias opciones. La cantidad de tokens que usa el usuario se correlaciona directamente con la longitud de la respuesta que devuelve el modelo.
Pregunta - Tal como suena; Aquí es donde el usuario puede hacer una pregunta al modelo.
Respuesta : esta es la respuesta generada por el modelo dado el contexto en su base de datos vectorial. Tenga en cuenta que si la pregunta no puede correlacionarse con el contenido de su base de conocimientos, es posible que obtenga respuestas alucinadas.
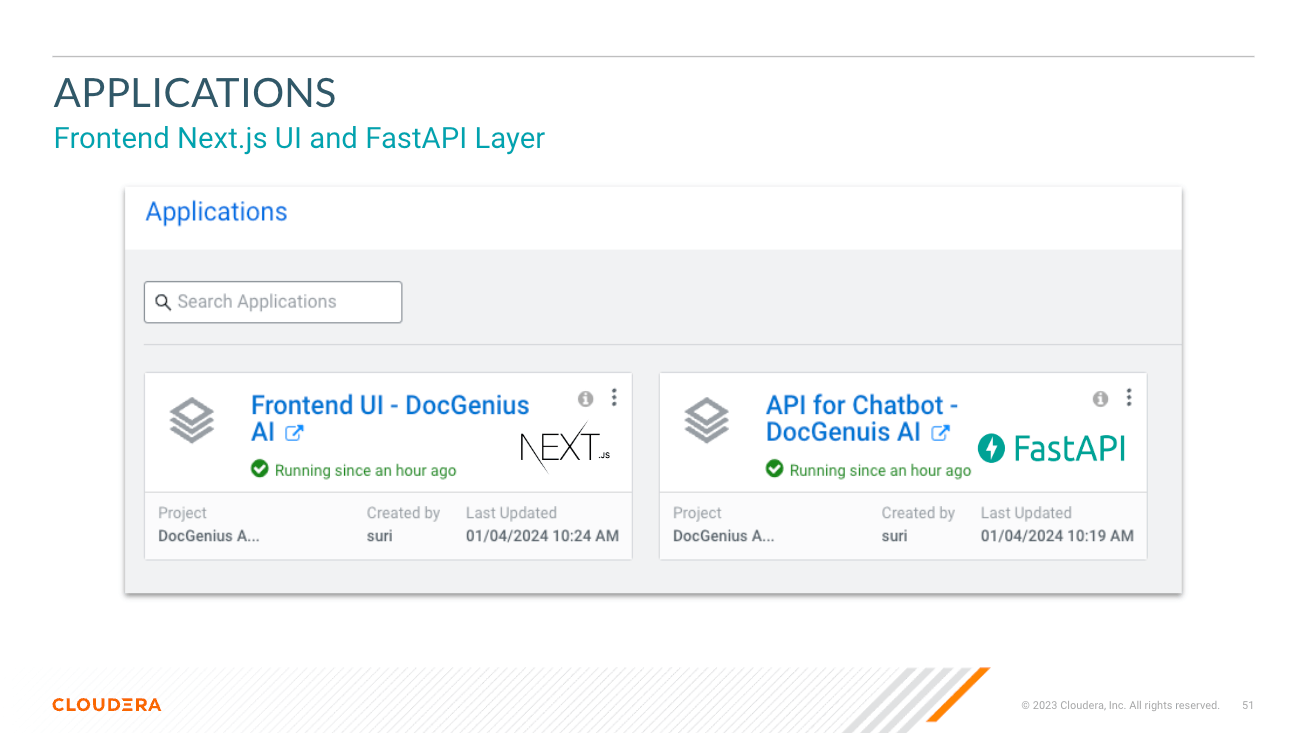
El directorio app aloja FastAPI para sus LLM.
El directorio chat-ui aloja el código para la interfaz de usuario de Chatbot.
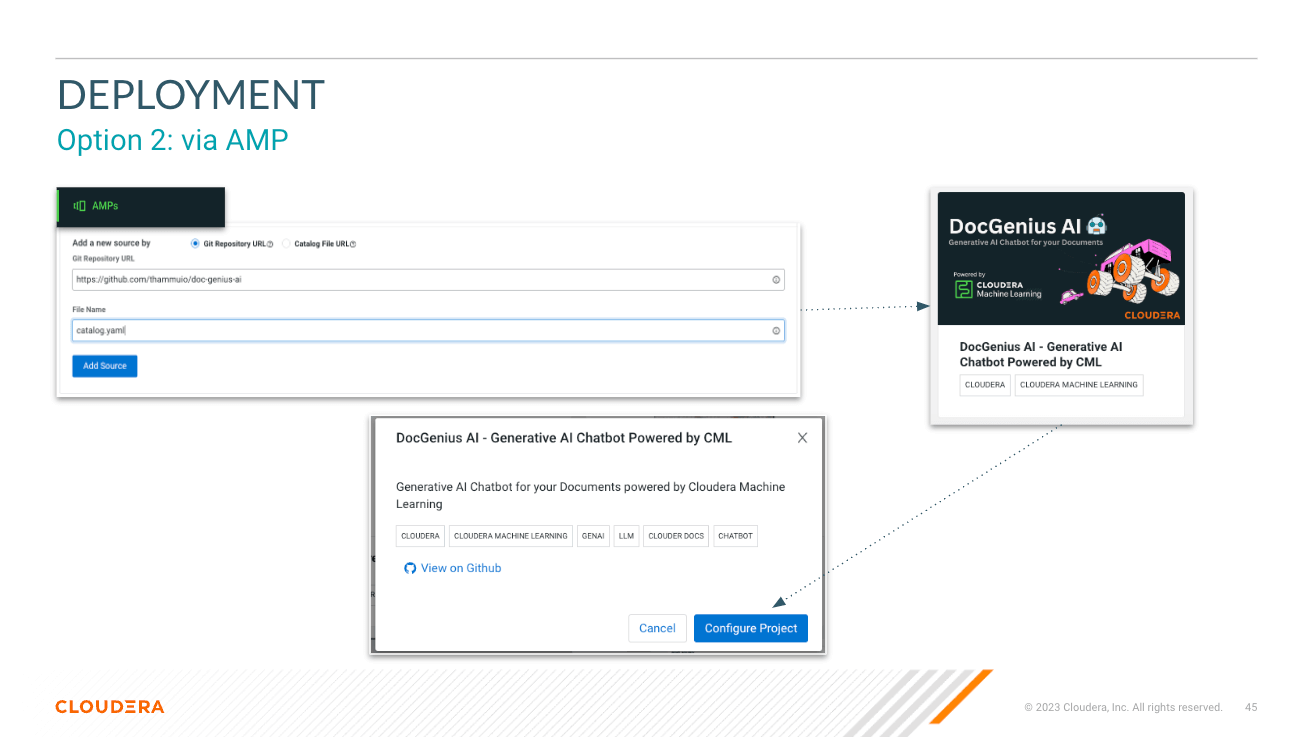
Mire las variables al implementar AMP. Consulte los documentos de inferencia de IA de Cloduera para obtener el punto final y la clave de inferencia.
JupyterLab - Python 3.11 - GPU Nvidia
https://docs.cloudera.com/machine-learning/cloud/applied-ml-prototypes/topics/ml-amp-project-spec.html
Esto crea las siguientes cargas de trabajo con requisitos de recursos:
2 CPU, 16GB MEM2 CPU, 8GB MEM2 CPU, 1 GPU, 16GB MEM doc-genius-ai/
├── app/ # Application directory for API and Model Serving
│ └── [..subdirs..]
│ └── chatbot/ # has the model serving python files for RAG, Prompt, Fine-tuning models
│ └── main.py # main.py file to start the API
├── chat-ui/ # Directory for the chatbot UI in Next.js
│ └── [..subdirs..]
│ └── app.py # app.py file to serve build files in .next directory via Flask
├── pipeline/ # Pipeline directory for data processing or workflow pipelines and vector load
├── data/ # Data directory for storing datasets or data files or RAG KB
├── models/ # Models directory for LLMs / ML models
├── session/ # Scripts for CML Sessions and Validation Tasks
├── images/ # Directory for storing project related images
├── api.md # Documentation for the APIs
├── README.md # Detailed description of the project
├── .gitignore # Specifies intentionally untracked files to ignore
├── catalog.yaml # YAML file that contains descriptive information and metadata for the displaying the AMP projects in the CML Project Catalog.
├─ .project-metadata.yaml # Project metadata file that provides configuration and setup details
├── cdsw-build.sh # Script for building the Model dependencies
└── requirements.txt # Python dependencies for Model Serving
IMPORTANTE: lea lo siguiente antes de continuar. Este AMP incluye o depende de ciertos paquetes de software de terceros. La información sobre dichos paquetes de software de terceros está disponible en el archivo de aviso asociado con este AMP. Al configurar e iniciar este AMP, hará que dichos paquetes de software de terceros se descarguen e instalen en su entorno, en algunos casos, desde sitios web de terceros. Para cada paquete de software de terceros, consulte el archivo de aviso y los sitios web correspondientes para obtener más información, incluidos los términos de licencia aplicables.
Si no desea descargar e instalar paquetes de software de terceros, no configure, inicie ni utilice de otro modo este AMP. Al configurar, iniciar o utilizar AMP, usted reconoce la declaración anterior y acepta que Cloudera no es responsable de ninguna manera por los paquetes de software de terceros.
Copyright (c) 2024 - Cloudera, Inc. Todos los derechos reservados.


