qwen2 in a lambda
1.0.0
Actualizado el 09/11/2024
(¡Marcando la fecha debido a la rapidez con la que se mueven las API de LLM en Python y puede introducir cambios importantes cuando alguien más lea esto!)
Esta es una investigación menor sobre cómo podemos colocar archivos de modelo Qwen GGUF en AWS Lambda usando Docker y SAM CLI.
Adaptado de https://makit.net/blog/llm-in-a-lambda-function/
Quería saber si puedo reducir mi gasto en AWS aprovechando únicamente las capacidades de Lambda y no de Lambda + Bedrock, ya que ambos servicios generarían más costos a largo plazo.
La idea era adaptarse a un modelo de lenguaje pequeño que no consumiría tantos recursos en términos relativos y, con suerte, recibir una latencia de subsegundo a segundo en una configuración de memoria de 128 a 256 MB.
También quería usar modelos GGUF para usar diferentes niveles de cuantificación para descubrir cuál es el mejor rendimiento/tamaño de archivo para cargar en la memoria.
qwen2-1_5b-instruct-q5_k_m.gguf en qwen_fuction/function/app.y / LOCAL_PATH qwen_function/function/requirements.txt (preferiblemente en un entorno venv/conda)sam build / sam validatesam local start-api para realizar pruebas localmentecurl --header "Content-Type: application/json" --request POST --data '{"prompt":"hello"}' http://localhost:3000/generate para solicitar el LLMsam deploy --guided para implementar en AWS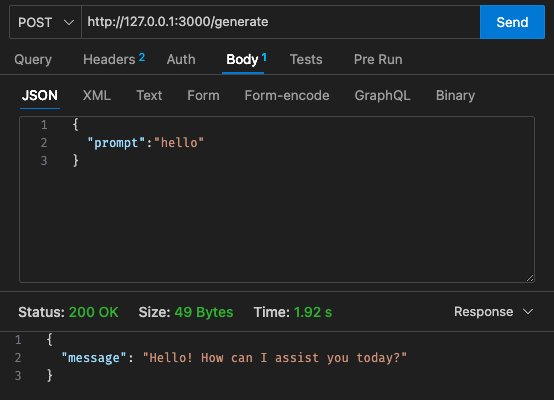
AWS
Configuración inicial: 128 MB, tiempo de espera de 30 s
Configuración ajustada n.º 1: 512 MB, tiempo de espera de 30 s
Configuración ajustada n.º 2: 512 MB, tiempo de espera de 30 s
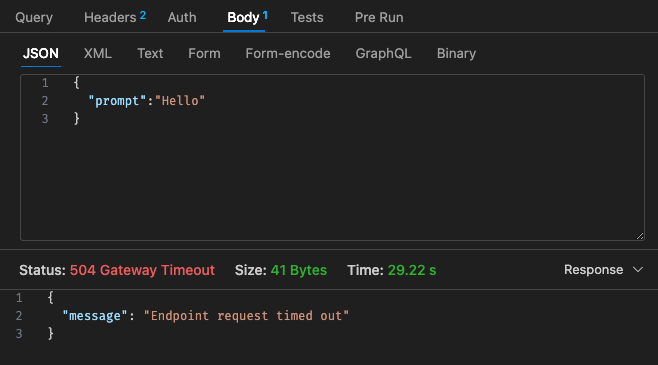
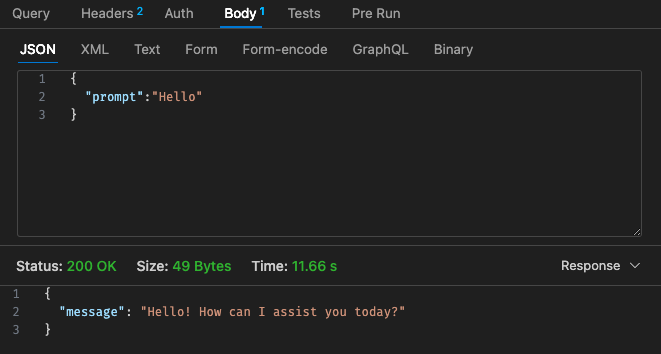
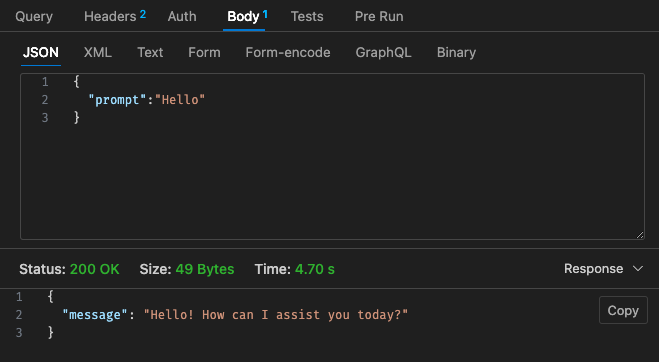
Volviendo a la estructura de precios de Lambda,
Puede ser más económico simplemente usar un LLM alojado usando AWS Bedrock, etc. en la nube, ya que la estructura de precios de Lambda con Qwen no parece más competitiva en comparación con Claude 3 Haiku.
Además, el tiempo de espera de la puerta de enlace API no se puede configurar fácilmente más allá del tiempo de espera de 30 segundos; dependiendo de su caso de uso, esto puede no ser muy ideal.
¡Los resultados vía local dependen de las especificaciones de su máquina! y puede distorsionar en gran medida su percepción, expectativa versus realidad
Dependiendo también de su caso de uso, la latencia por invocación y respuesta lambda puede generar malas experiencias de usuario.
Considerándolo todo, creo que este fue un pequeño experimento divertido a pesar de que no cumplió con los requisitos de presupuesto y latencia a través de Qwen 1.5b para mi proyecto paralelo. ¡Gracias a @makit nuevamente por la guía!


