Interactive RAG
1.0.0
Los agentes están revolucionando la forma en que aprovechamos los modelos lingüísticos para la toma de decisiones y el desempeño de tareas. Los agentes son sistemas que utilizan modelos de lenguaje para tomar decisiones y realizar tareas. Están diseñados para manejar escenarios complejos y proporcionar más flexibilidad en comparación con los enfoques tradicionales. Se puede considerar a los agentes como motores de razonamiento que aprovechan los modelos de lenguaje para procesar información, recuperar datos relevantes, ingerir (fragmentar/incrustar) y generar respuestas.
En el futuro, los agentes desempeñarán un papel vital en el procesamiento de texto, la automatización de tareas y la mejora de las interacciones entre humanos y computadoras a medida que avancen los modelos de lenguaje.
En este ejemplo, nos centraremos específicamente en aprovechar los agentes en la generación aumentada de recuperación dinámica (RAG). Al utilizar ActionWeaver y MongoDB Atlas, tendrá la capacidad de modificar su estrategia RAG en tiempo real a través de interacciones conversacionales. Ya sea seleccionando más fragmentos, aumentando el tamaño de los fragmentos o modificando otros parámetros, puede ajustar su enfoque RAG para lograr la calidad y precisión de respuesta deseadas. ¡Incluso puedes agregar/eliminar fuentes a tu base de datos vectorial usando lenguaje natural!
# LLM Config
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
"summarize_chunks": True, # adds latency at ingest, everything comes at a cost
}
Fragmentar texto es genial, pero ¿cómo se almacena?
Resumir ahorra espacio y acelera las cosas, pero puede perder detalles.
El almacenamiento de datos sin procesar es preciso, pero voluminoso, más lento y "ruidoso".
Ventajas de resumir:
Contras de resumir:
¿Qué es lo correcto para ti? ¡Depende de tus necesidades! Considerar:
DEMOSTRACIÓN 1
Crear un nuevo entorno Python
python3 -m venv envActivar el nuevo entorno Python
source env/bin/activateInstalar los requisitos
pip3 install -r requirements.txtEstablezca los parámetros en params.py:
# MongoDB
MONGODB_URI = " "
DATABASE_NAME = " genai "
COLLECTION_NAME = " rag "
# If using OpenAI
OPENAI_API_KEY = " "
# If using Azure OpenAI
OPENAI_TYPE = " azure "
OPENAI_API_VERSION = " 2023-10-01-preview "
OPENAI_AZURE_ENDPOINT = " https://.openai.azure.com/ "
OPENAI_AZURE_DEPLOYMENT = " "
Cree un índice de búsqueda con la siguiente definición
{
"mappings" : {
"dynamic" : true ,
"fields" : {
"embedding" : {
"dimensions" : 384 ,
"similarity" : " cosine " ,
"type" : " knnVector "
}
}
}
}Establecer el entorno
export OPENAI_API_KEY=Para ejecutar la aplicación RAG
env/bin/streamlit run rag/app.pyLa información de registro generada por la aplicación se agregará a app.log.
Este bot admite las siguientes acciones: responder preguntas, buscar en la web, leer URL, eliminar fuentes, enumerar todas las fuentes y restablecer mensajes. También admite una acción llamada iRAG que le permite controlar dinámicamente la estrategia RAG de su agente.
Ej: "establecer la configuración de RAG en 3 fuentes y tamaño de fragmento 1250" => Nueva configuración de RAG:{'num_sources': 3, 'source_chunk_size': 1250, 'min_rel_score': 0, 'unique': True}.
def __call__(self, text):
text = self.preprocess_query(text)
self.messages += [{"role": "user", "content":text}]
response = self.llm.create(messages=self.messages, actions = [
self.read_url,self.answer_question,self.remove_source,self.reset_messages,
self.iRAG, self.get_sources_list,self.search_web
], stream=True)
return response
Si el bot no puede proporcionar una respuesta a la pregunta a partir de los datos almacenados en la tienda Atlas Vector y su estrategia RAG (número de fuentes, tamaño del fragmento, min_rel_score, etc.), iniciará una búsqueda en la web para encontrar información relevante. Luego puede indicarle al bot que lea y aprenda de esos resultados.
RAG es genial y todo eso, pero idear la "estrategia RAG" correcta es complicado. El tamaño del fragmento y la cantidad de fuentes únicas tendrán un impacto directo en la respuesta generada por el LLM.
En el desarrollo de una estrategia RAG eficaz, el proceso de ingesta de fuentes web, la fragmentación, la incrustación, el tamaño de la porción y la cantidad de fuentes utilizadas desempeñan papeles cruciales. La fragmentación desglosa el texto de entrada para una mejor comprensión, la incrustación captura el significado y la cantidad de fuentes impacta la diversidad de respuestas. Encontrar el equilibrio adecuado entre el tamaño del fragmento y el número de fuentes es esencial para obtener respuestas precisas y relevantes. Es necesario experimentar y realizar ajustes para determinar la configuración óptima.
Antes de sumergirnos en la 'Recuperación', hablemos primero del "Proceso de ingesta".
¿Por qué tener un proceso separado para "ingerir" su contenido en su base de datos vectorial? Usando la magia de los agentes, podemos agregar fácilmente contenido nuevo a la base de datos vectorial.
Hay muchos tipos de bases de datos que pueden almacenar estas incrustaciones, cada una con sus propios usos especiales. Pero para tareas que involucran aplicaciones GenAI, recomiendo MongoDB.
Piensa en MongoDB como un pastel que puedes comer y comer. Te brinda el poder de su lenguaje para realizar consultas, Mongo Query Language. También incluye todas las excelentes funciones de MongoDB. Además de eso, le permite almacenar estos bloques de construcción (incrustaciones de vectores) y realizar operaciones matemáticas con ellos, todo en un solo lugar. ¡Esto convierte a MongoDB Atlas en una ventanilla única para todas sus necesidades de incrustación de vectores!
@action("read_url", stop=True)
def read_url(self, urls: List[str]):
"""
Invoke this ONLY when the user asks you to 'read', 'add' or 'learn' some URL(s).
This function reads the content from specified sources, and ingests it into the Knowledgebase.
URLs may be provided as a single string or as a list of strings.
IMPORTANT! Use conversation history to make sure you are reading/learning/adding the right URLs.
Parameters
----------
urls : List[str]
List of URLs to scrape.
Returns
-------
str
A message indicating successful reading of content from the provided URLs.
"""
with self.st.spinner(f"```Analyzing the content in {urls}```"):
loader = PlaywrightURLLoader(urls=urls, remove_selectors=["header", "footer"])
documents = loader.load_and_split(self.text_splitter)
self.index.add_documents(
documents
)
return f"```Contents in URLs {urls} have been successfully ingested (vector embeddings + content).```"
{
"mappings": {
"dynamic": true,
"fields": {
"embedding": {
"dimensions": 384, #dimensions depends on the model
"similarity": "cosine",
"type": "knnVector"
}
}
}
}
def recall(self, text, n_docs=2, min_rel_score=0.25, chunk_max_length=800,unique=True):
#$vectorSearch
print("recall=>"+str(text))
response = self.collection.aggregate([
{
"$vectorSearch": {
"index": "default",
"queryVector": self.gpt4all_embd.embed_query(text), #GPT4AllEmbeddings()
"path": "embedding",
#"filter": {},
"limit": 15, #Number (of type int only) of documents to return in the results. Value can't exceed the value of numCandidates.
"numCandidates": 50 #Number of nearest neighbors to use during the search. You can't specify a number less than the number of documents to return (limit).
}
},
{
"$addFields":
{
"score": {
"$meta": "vectorSearchScore"
}
}
},
{
"$match": {
"score": {
"$gte": min_rel_score
}
}
},{"$project":{"score":1,"_id":0, "source":1, "text":1}}])
tmp_docs = []
str_response = []
for d in response:
if len(tmp_docs) == n_docs:
break
if unique and d["source"] in tmp_docs:
continue
tmp_docs.append(d["source"])
str_response.append({"URL":d["source"],"content":d["text"][:chunk_max_length],"score":d["score"]})
kb_output = f"Knowledgebase Results[{len(tmp_docs)}]:n```{str(str_response)}```n## n```SOURCES: "+str(tmp_docs)+"```nn"
self.st.write(kb_output)
return str(kb_output)
Usando ActionWeaver, un contenedor liviano para API de llamada de funciones, podemos crear un agente proxy de usuario que recupere e ingiera de manera eficiente información relevante usando MongoDB Atlas.
Un agente proxy es un intermediario que envía solicitudes de clientes a otros servidores o recursos y luego devuelve respuestas.
Este agente presenta los datos al usuario de forma interactiva y personalizable, mejorando la experiencia general del usuario.
UserProxyAgent tiene varios parámetros RAG que se pueden personalizar, como chunk_size (por ejemplo, 1000), num_sources (por ejemplo, 2), unique (por ejemplo, True) y min_rel_score (por ejemplo, 0,00).
class UserProxyAgent:
def __init__(self, logger, st):
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
}
A continuación se detallan algunos beneficios clave que influyeron en nuestra decisión de elegir ActionWeaver:
Un agente es básicamente un programa o sistema informático diseñado para percibir su entorno, tomar decisiones y lograr objetivos específicos.
Piense en un agente como una entidad de software que muestra cierto grado de autonomía y realiza acciones en su entorno en nombre de su usuario o propietario, pero de una manera relativamente independiente. Toma iniciativas para realizar acciones por sí solo deliberando sus opciones para lograr su(s) objetivo(s). La idea central de los agentes es utilizar un modelo de lenguaje para elegir una secuencia de acciones a realizar. A diferencia de las cadenas, donde una secuencia de acciones está codificada en código, los agentes utilizan un modelo de lenguaje como motor de razonamiento para determinar qué acciones tomar y en qué orden.
Las acciones son funciones que un agente puede invocar. Hay dos consideraciones de diseño importantes en torno a las acciones:
Giving the agent access to the right actions
Describing the actions in a way that is most helpful to the agent
Sin pensar en ambos, no podrá crear un agente que funcione. Si no le da al agente acceso a un conjunto correcto de acciones, nunca podrá lograr los objetivos que le asigna. Si no describe bien las acciones, el agente no sabrá utilizarlas correctamente.
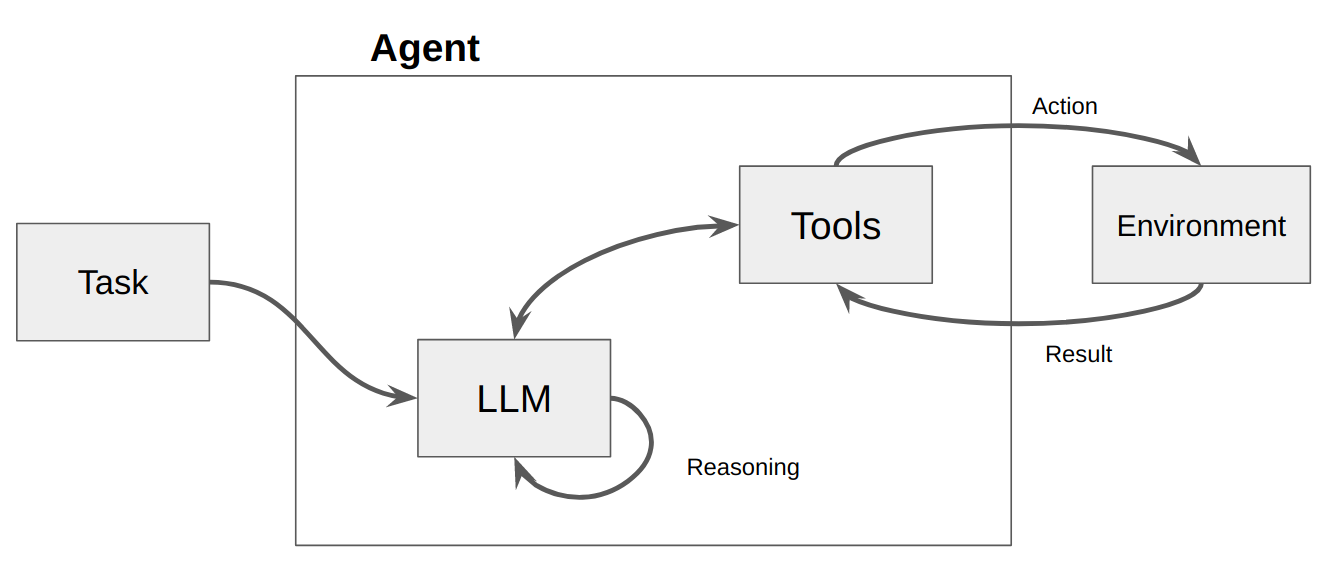
Luego se llama a un LLM, lo que da como resultado una respuesta al usuario O acciones a tomar. Si se determina que se requiere una respuesta, se pasa al usuario y el ciclo finaliza. Si se determina que se requiere una acción, entonces se toma esa acción y se hace una observación (resultado de la acción). Esa acción y la observación correspondiente se agregan nuevamente al mensaje (a esto lo llamamos "bloc de notas del agente") y el bucle se restablece, es decir. Se vuelve a llamar al LLM (con el bloc de notas del agente actualizado).
En ActionWeaver, podemos influir en el bucle agregando stop=True|False a una acción. Si stop=True , el LLM devolverá inmediatamente la salida de la función. Esto también impedirá que el LLM realice múltiples llamadas a funciones. En esta demostración solo usaremos stop=True
ActionWeaver también admite un control de bucle más complejo usando orch_expr(SelectOne[actions]) y orch_expr(RequireNext[actions]) , pero lo dejaré para la PARTE II.
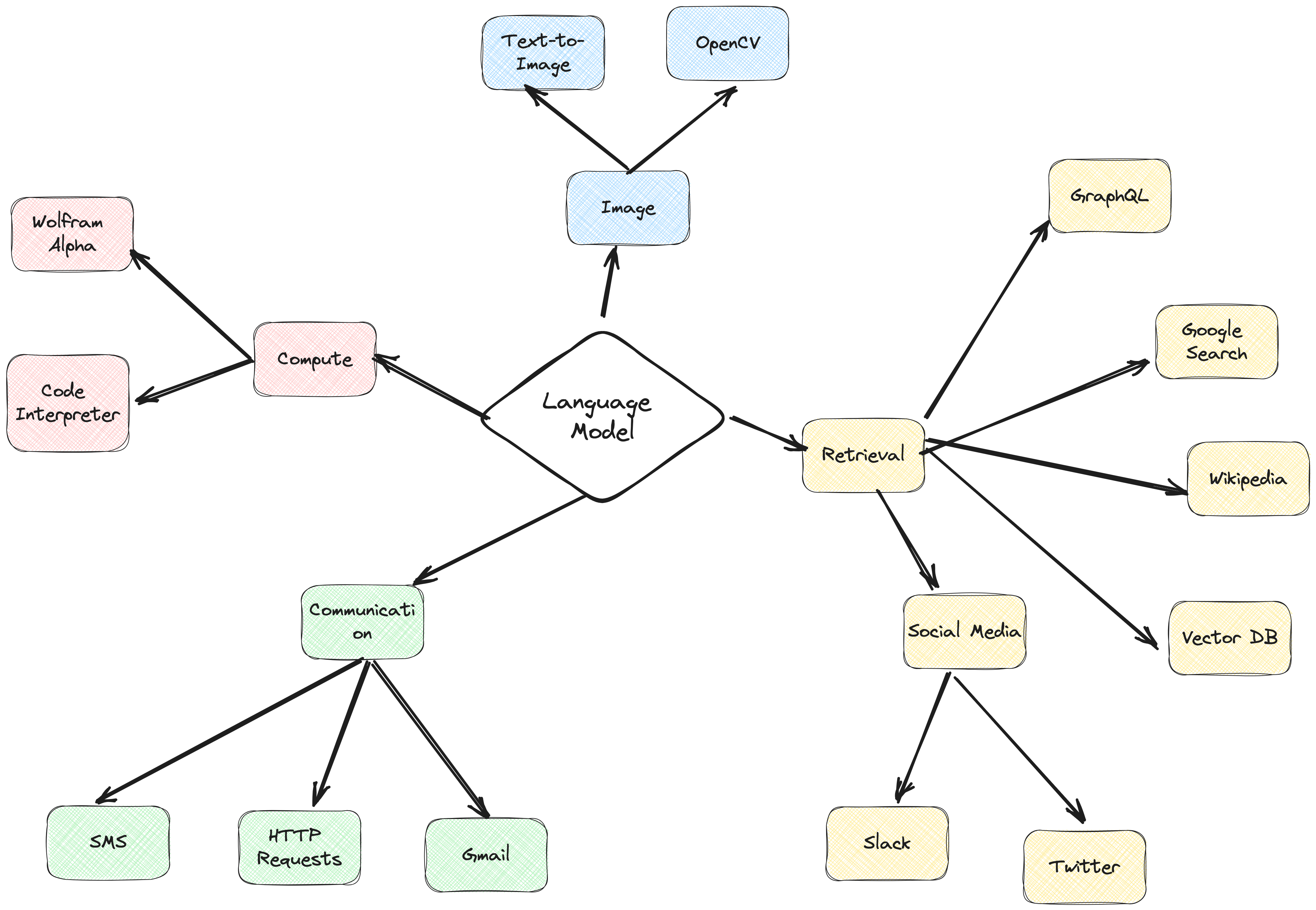
El marco del agente ActionWeaver es un marco de aplicación de IA que sitúa la llamada de funciones en su núcleo. Está diseñado para permitir una fusión perfecta de los sistemas informáticos tradicionales con las potentes capacidades de razonamiento de los modelos de lenguaje. ActionWeaver se basa en el concepto de llamada a funciones LLM, mientras que marcos populares como Langchain y Haystack se basan en el concepto de canalizaciones.

Lea más en: https://thinhdanggroup.github.io/function-calling-openai/
Los desarrolladores pueden adjuntar CUALQUIER función de Python como herramienta con un decorador simple. En el siguiente ejemplo, presentamos la acción get_sources_list, que será invocada por la API de OpenAI.
ActionWeaver utiliza la firma y la cadena de documentación del método decorado como descripción y las pasa a la función API de OpenAI.
ActionWeaver proporciona un contenedor ligero que se encarga de convertir la información de la cadena de documentación/decorador al formato correcto para la API de OpenAI.
@action(name="get_sources_list", stop=True)
def get_sources_list(self):
"""
Invoke this to respond to list all the available sources in your knowledge base.
Parameters
----------
None
"""
sources = self.collection.distinct("source")
if sources:
result = f"Available Sources [{len(sources)}]:n"
result += "n".join(sources[:5000])
return result
else:
return "N/A"
stop=True cuando se agrega a una acción significa que el LLM devolverá inmediatamente la salida de la función, pero esto también restringe que el LLM realice múltiples llamadas a funciones. Por ejemplo, si se le preguntara sobre el clima en Nueva York y San Francisco, el modelo invocaría dos funciones separadas secuencialmente para cada ciudad. Sin embargo, con stop=True , este proceso se interrumpe una vez que la primera función devuelve información meteorológica para Nueva York o San Francisco, dependiendo de qué ciudad consulte primero.
Para obtener una comprensión más profunda de cómo funciona este bot en su interior, consulte el archivo bot.py. Además, puede explorar el repositorio de ActionWeaver para obtener más detalles.
La generación de rastros de razonamiento permite que el modelo induzca, rastree y actualice planes de acción, e incluso maneje excepciones. Este ejemplo utiliza ReAct combinado con cadena de pensamiento (CoT).
Cadena de pensamiento
Razonamiento + Acción
[EXAMPLES]
- User Input: What is MongoDB?
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "answer_question".
- Action: "answer_question"('What is MongoDB?')
- User Input: Reset chat history
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "reset_messages".
- Action: "reset_messages"()
- User Input: remove source https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "remove_source".
- Action: "remove_source"(['https://www.google.com', 'https://www.example.com'])
- User Input: read https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "read_url".
- Action: "read_url"(['https://www.google.com','https://www.example.com'])
[END EXAMPLES]
En estos ejemplos entran en juego las técnicas de estimulación Chain of Thought (CoT) y ReAct. He aquí cómo:
Cadena de pensamiento (CoT):
Reaccionar solicitando:
En resumen, tanto CoT como ReAct desempeñan un papel crucial en estos ejemplos. CoT permite que el modelo razone paso a paso y elija las acciones apropiadas, mientras que ReAct amplía esta funcionalidad al permitir que el modelo interactúe con su entorno y actualice sus planes en consecuencia. Esta combinación de razonamiento y acción hace que los modelos de lenguaje grandes sean más flexibles y versátiles, permitiéndoles manejar una gama más amplia de tareas y situaciones.
Comencemos haciéndole una pregunta a nuestro agente. En este caso, "¿Qué es un mango?" . Lo primero que sucederá es que intentará "recordar" cualquier información relevante utilizando la similitud de incrustación de vectores. Luego formulará una respuesta con el contenido que "recordó" o realizará una búsqueda en la web. Dado que nuestra base de conocimientos está actualmente vacía, debemos agregar algunas fuentes antes de que pueda formular una respuesta.
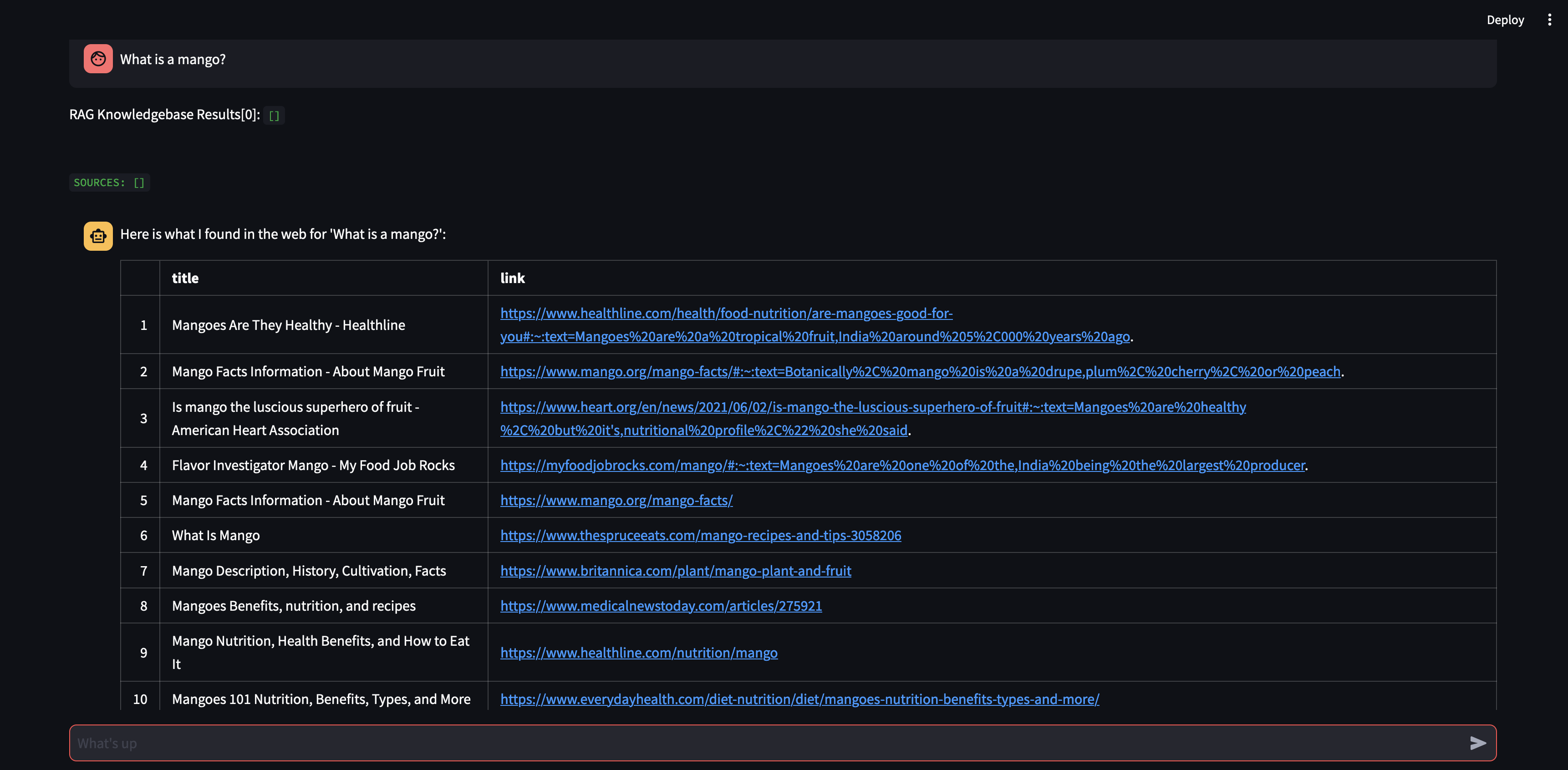
Dado que el robot no puede proporcionar una respuesta utilizando el contenido de la base de datos vectorial, inició una búsqueda en Google para encontrar información relevante. Ahora podemos decirle qué fuentes debería "aprender". En este caso, le diremos que aprenda las dos primeras fuentes de los resultados de la búsqueda.
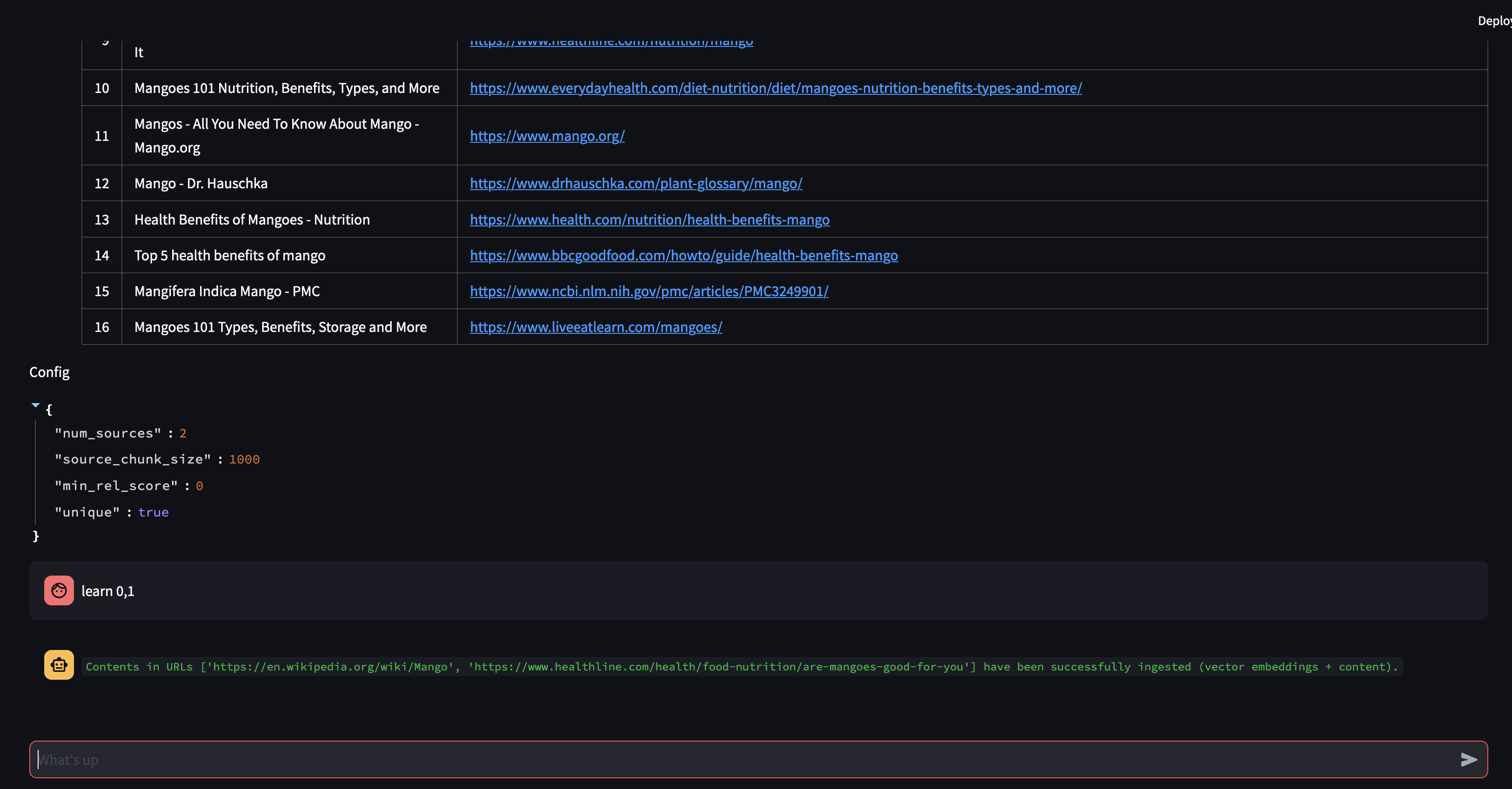
A continuación, ¡modifiquemos la estrategia RAG! Hagamos que use solo una fuente y que use un tamaño de fragmento pequeño de 500 caracteres.
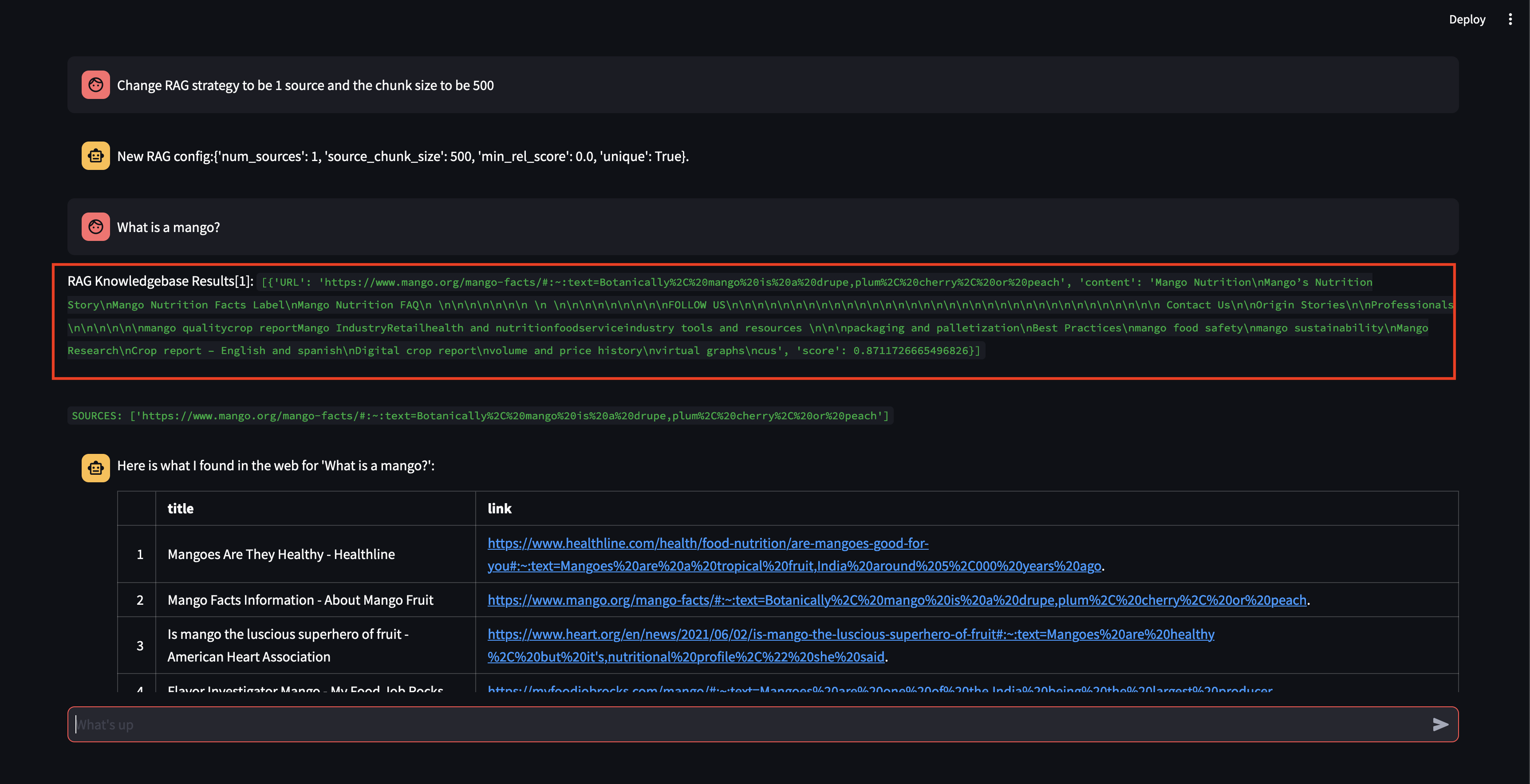
Observe que, aunque pudo recuperar un fragmento, con una puntuación de relevancia bastante alta, no pudo generar una respuesta porque el tamaño del fragmento era demasiado pequeño y el contenido del fragmento no era lo suficientemente relevante como para formular una respuesta. Como no pudo generar una respuesta con el fragmento pequeño, realizó una búsqueda web en nombre del usuario.
Veamos qué sucede si aumentamos el tamaño del fragmento a 3000 caracteres en lugar de 500.
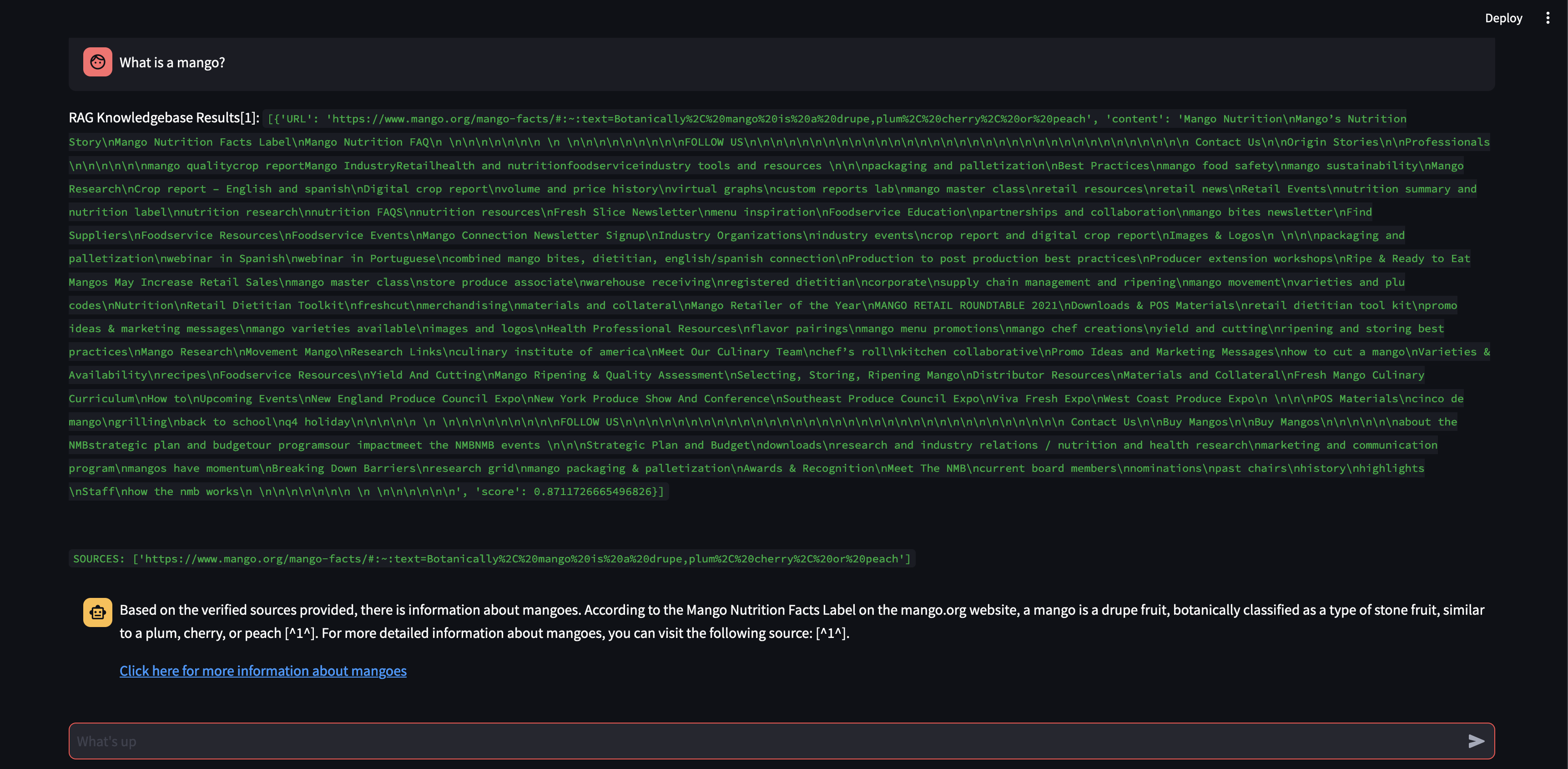
Ahora, con un tamaño de fragmento mayor, pudo formular con precisión la respuesta utilizando el conocimiento de la base de datos vectorial.
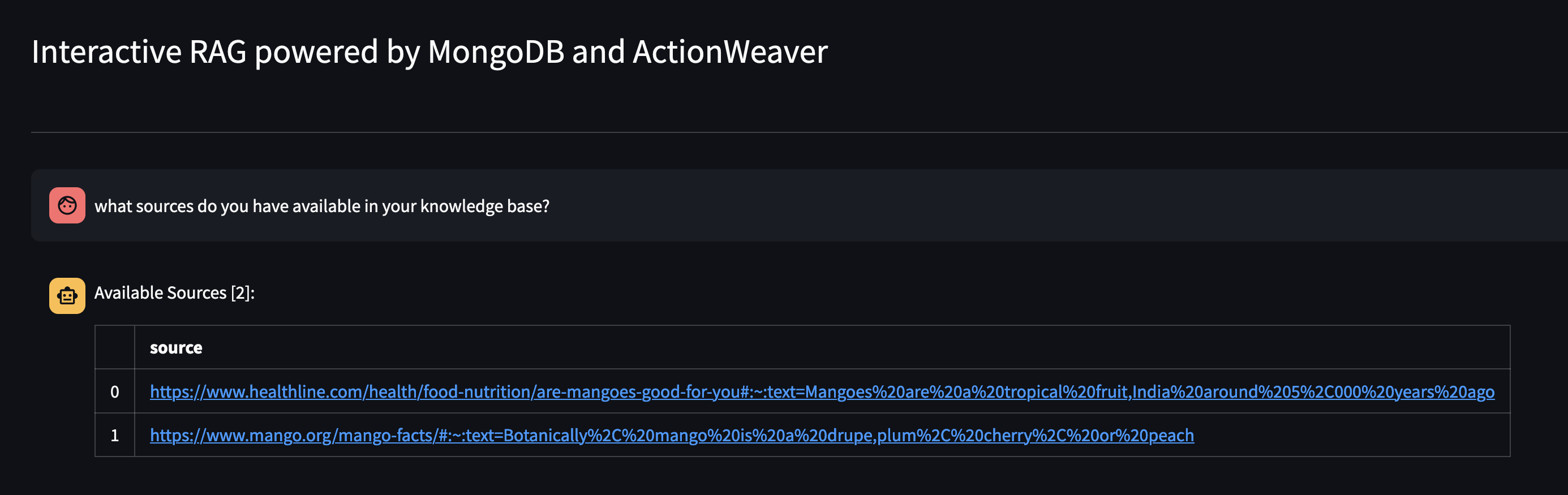
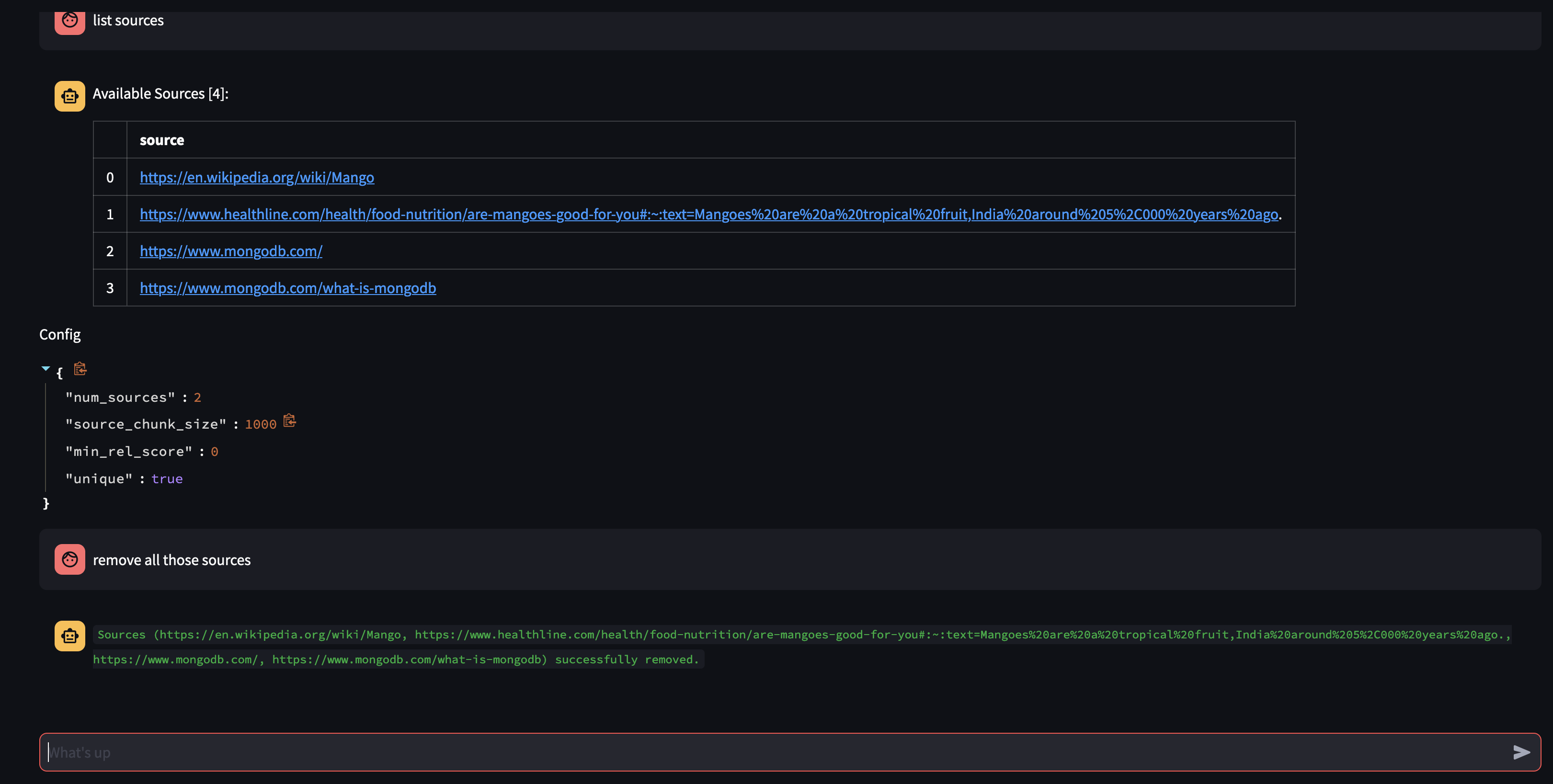
Veamos qué hay disponible en la base de conocimientos del Agente preguntándole: ¿Qué fuentes tiene en su base de conocimientos?
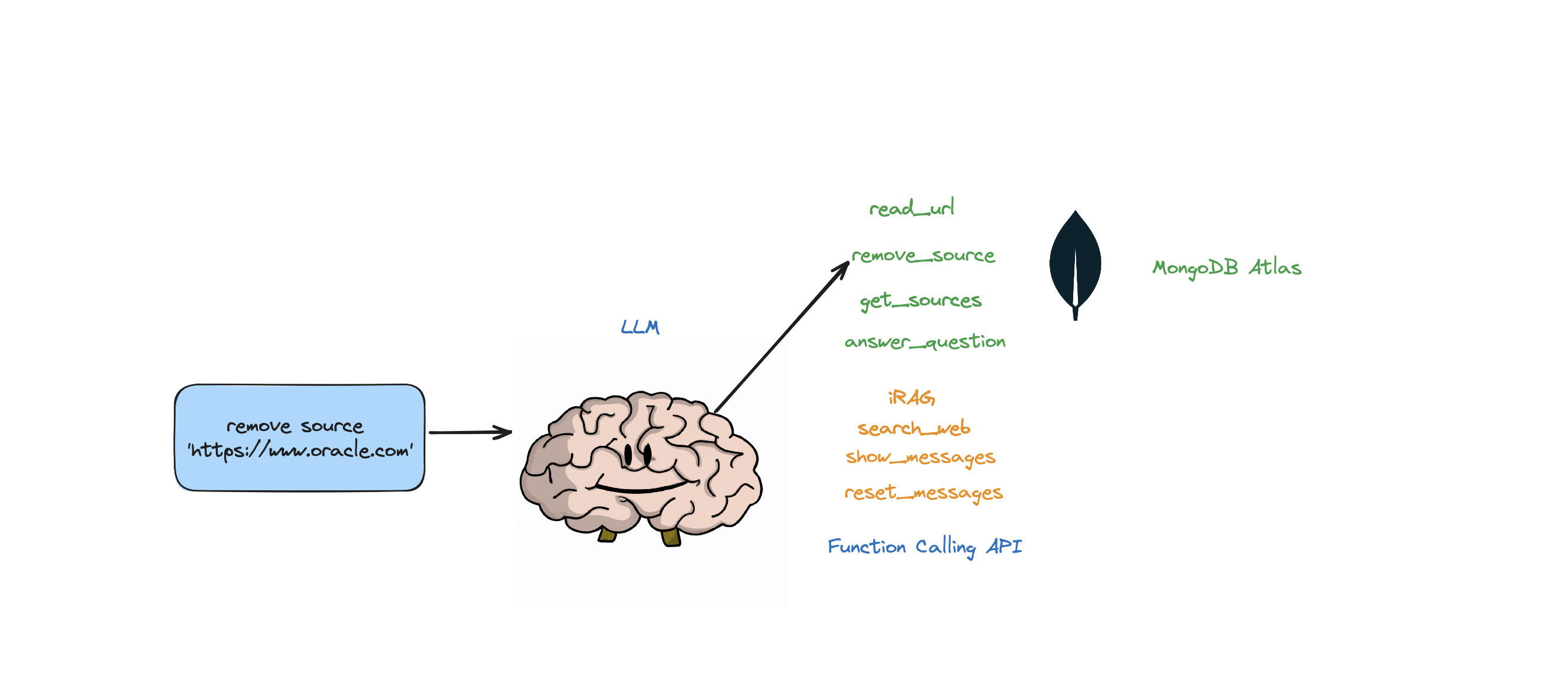
Si desea eliminar un recurso específico, puede hacer algo como:
USER: remove source 'https://www.oracle.com' from the knowledge base
Para eliminar todas las fuentes de la colección, podríamos hacer algo como:
USER: what sources do you have in your knowledge base?
AGENT: {response}
USER: remove all those sources please
Esta demostración ha brindado una idea del funcionamiento interno de nuestro agente de IA, mostrando su capacidad para aprender y responder a las consultas de los usuarios de manera interactiva. Hemos sido testigos de cómo combina a la perfección su base de conocimientos interna con búsqueda web en tiempo real para brindar información completa y precisa. El potencial de esta tecnología es enorme y va mucho más allá de la simple respuesta a preguntas. Nada de esto sería posible sin la magia de la API de llamada a funciones .
Esto fue inspirado por https://github.com/TengHu/Interactive-RAG
Agradecemos las contribuciones de la comunidad de código abierto.
Licencia Apache 2.0


