genai knowledge capture
1.0.0
Esta solución de prueba de concepto explica una solución potencial que se puede utilizar para capturar el conocimiento tribal a través de grabaciones de voz de altos empleados de una empresa. Describe metodologías para utilizar el servicio Amazon Transcribe y Amazon Bedrock para la documentación sistemática y la verificación de los datos de entrada. Al proporcionar una estructura para la formalización de este conocimiento informal, la solución garantiza su longevidad y aplicabilidad para grupos posteriores de empleados en una organización. Este esfuerzo no sólo garantiza el mantenimiento sostenido de la excelencia operativa sino que también mejora la eficacia de los programas de capacitación mediante la incorporación de conocimientos prácticos adquiridos a través de la experiencia directa.
Esta aplicación de demostración es una prueba de concepto para una aplicación de generación de documentos mediante Amazon Transcribe y Amazon Bedrock.
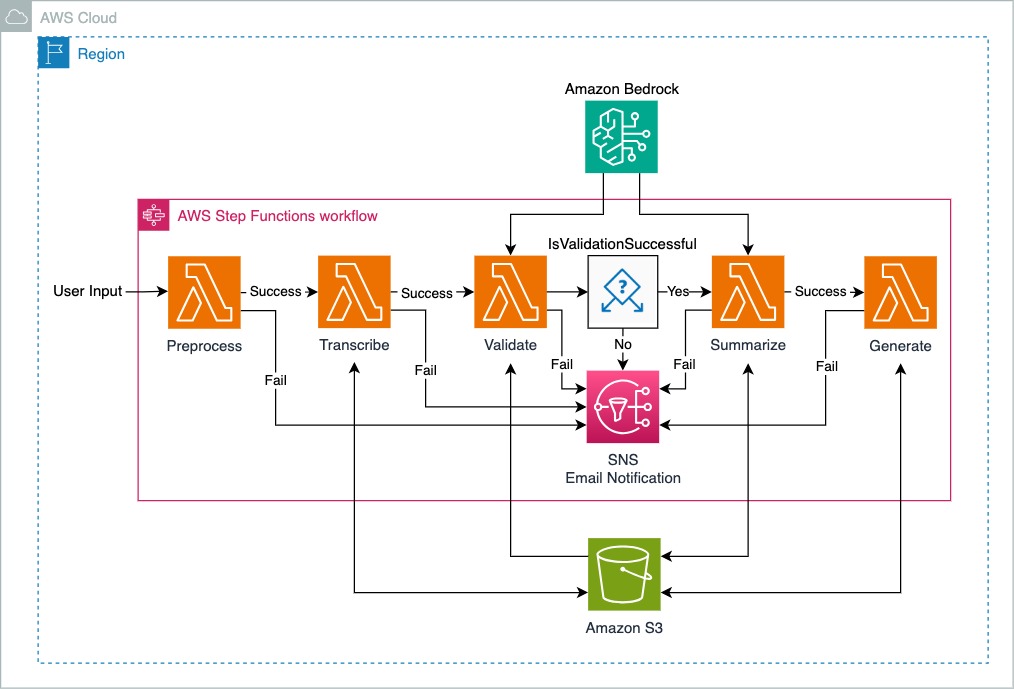
El diagrama muestra una arquitectura de solución para un flujo de trabajo orquestado por AWS Step Functions dentro de una región de la nube de AWS. El flujo de trabajo consta de varios pasos diseñados para procesar la entrada del usuario, con mecanismos para el manejo del éxito y el fracaso en cada paso. A continuación se muestra una descripción del flujo del proceso:
Entrada del usuario : el flujo de trabajo se inicia con la entrada del usuario para activar la función Lambda preprocess .
Preproceso : la entrada se preprocesa primero. Si tiene éxito, pasa al paso transcribe ; si falla, hace que Amazon SNS envíe notificaciones.
Transcribir : este paso toma el resultado del paso anterior. Una transcripción exitosa pasa al paso Validar y los resultados de la transcripción se almacenan en el depósito de Amazon S3.
Validar : Se validan los datos transcritos. Según el resultado de la validación, el flujo de trabajo diverge:
Resumir : después de la validación, si los datos se resumen correctamente, el texto resumido se almacena en el depósito de Amazon S3. Si falla, hace que Amazon SNS envíe notificaciones.
Amazon Bedrock es el servicio principal que respalda las funciones Validar y Resumir Lambda.
Generar : este último paso genera el documento final a partir del texto resumido. Si falla, hace que Amazon SNS envíe notificaciones.
Cada paso del proceso está marcado con rutas de "Éxito" o "Fallo", lo que indica la capacidad del flujo de trabajo para manejar errores en varias etapas. En caso de error, Amazon SNS se utiliza para enviar notificaciones al usuario.
El flujo de trabajo de AWS Step Functions funciona como un orquestador central, lo que garantiza que cada tarea se ejecute en el orden correcto y maneja el éxito o el fracaso de cada paso de manera adecuada.
El archivo cdk.json le indica al CDK Toolkit cómo ejecutar su aplicación.
Este proyecto está configurado como un proyecto Python estándar. El proceso de inicialización también crea un virtualenv dentro de este proyecto, almacenado en el directorio .venv . Para crear virtualenv, se supone que hay un ejecutable python3 (o python para Windows) en su ruta con acceso al paquete venv . Si por algún motivo falla la creación automática del virtualenv, puede crear el virtualenv manualmente.
Para crear manualmente un virtualenv en MacOS y Linux:
$ python3 -m venv .venvUna vez que se completa el proceso de inicio y se crea el virtualenv, puede utilizar el siguiente paso para activar su virtualenv.
$ source .venv/bin/activateSi tiene una plataforma Windows, activaría virtualenv de esta manera:
% .venvScripts activate.batUna vez que virtualenv esté activado, puede instalar las dependencias necesarias.
$ pip install -r requirements.txt Para agregar dependencias adicionales, por ejemplo otras bibliotecas CDK, simplemente agréguelas a su archivo setup.py y vuelva a ejecutar el comando pip install -r requirements.txt .
En este punto, ahora puede sintetizar la plantilla de CloudFormation para este código.
$ cdk synth Para agregar dependencias adicionales, por ejemplo otras bibliotecas CDK, simplemente agréguelas a su archivo setup.py y vuelva a ejecutar el comando pip install -r requirements.txt .
Deberá iniciarlo si es la primera vez que ejecuta cdk en una cuenta y región en particular.
$ cdk bootstrap
Una vez que se haya iniciado, puede proceder a implementar cdk.
$ cdk deploy
Si es la primera vez que lo implementa, el proceso puede tardar aproximadamente entre 30 y 45 minutos para crear varias imágenes de Docker en ECS (Amazon Elastic Container Service). Tenga paciencia hasta que esté completo. Luego, comenzará a implementar la pila de documentos, lo que normalmente demora entre 5 y 8 minutos.
Una vez que se complete el proceso de implementación, verá la salida del cdk en la terminal y también podrá verificar el estado en su consola de CloudFormation.
Para eliminar el cdk una vez que haya terminado de usarlo para evitar costos futuros, puede eliminarlo a través de la consola o ejecutar el siguiente comando en la terminal.
$ cdk destroyEs posible que también deba eliminar manualmente el depósito S3 generado por el cdk. Asegúrese de eliminar todos los recursos generados para evitar incurrir en costos.
cdk ls enumera todas las pilas en la aplicacióncdk synth emite la plantilla de CloudFormation sintetizadacdk deploy implemente esta pila en su cuenta/región de AWS predeterminadacdk diff compara la pila implementada con el estado actualcdk docs abre la documentación de CDKcdk destroy destruye una o más pilas especificadas code # Root folder for code for this solution
├── lambdas # Root folder for all lambda functions
│ ├── preprocess # Lambda function that processes user input, and outputs audio files uris for Amazon Transcribe
│ ├── transcribe # Lambda function that triggers Amazon Transcribe batch transcription
│ ├── validate # Lambda function that analyzes answers from Amazon Transcribe using LLMs from Amazon Bedrock
│ ├── summarize # Lambda function that summarizes on-topic texts from Amazon Transcribe using LLMs from Amazon Bedrock
│ └── generate # Lambda function that generates documents from the summary.
└── code_stack.py # Amazon CDK stack that deploys all AWS resources
Para adaptar la aplicación DocGen para incorporar sus propios datos, se deben seguir los siguientes pasos:
Tras la implementación, la infraestructura de AWS CDK facilitará la transferencia automática de archivos de audio al depósito de Amazon S3 designado. Posteriormente, se puede iniciar la ejecución de la función de paso de AWS para comenzar la fase de procesamiento.
Una vez implementada la solución, puede suscribir su correo electrónico al tema SNS para recibir notificaciones.
Siga las notificaciones por correo electrónico de SNS.
Si falla algún paso dentro del flujo de trabajo de StepFunction, recibirá una notificación por correo electrónico.
Después de la implementación, puede activar la AWS State Machine implementada mediante el siguiente comando:
aws stepfunctions start-execution
--state-machine-arn "arn:aws:states:<your aws region>:<your account id>:stateMachine:genai-knowledge-capture-stack-state-machine"
--input "{"documentName": "<your document name>", "audioFileFolderUri": "s3://<your s3 bucket>/assets/audio_samples/what is amazon bedrock/"}"
Consulte CONTRIBUCIÓN para obtener más información.
Esta biblioteca tiene la licencia MIT-0. Ver el archivo de LICENCIA.


