korpatbert
1.0.0
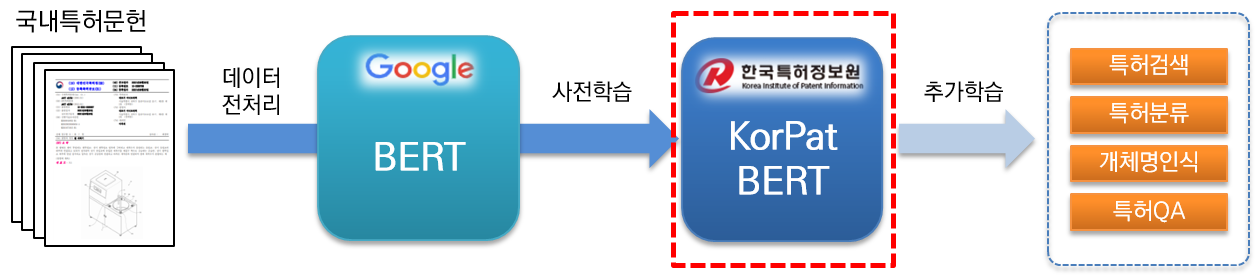
KorPatBERT (Patente coreana BERT) es un modelo de lenguaje de inteligencia artificial investigado y desarrollado por el Servicio de información de patentes de Corea.
Para resolver los problemas de procesamiento del lenguaje natural coreano en el campo de las patentes y preparar una infraestructura de información inteligente en la industria de patentes, es necesario realizar capacitación previa sobre una gran cantidad de documentos de patentes nacionales (base: alrededor de 4,06 millones de documentos, grande: alrededor de 5,06 millones de documentos). Se basa en la arquitectura del modelo base existente de Google BERT (preformación) y se proporciona de forma gratuita.
Es un modelo de lenguaje previamente entrenado de alto rendimiento especializado en el campo de las patentes y puede utilizarse en diversas tareas de procesamiento del lenguaje natural.
[Base KorPatBERT]
[KorPatBERT-grande]
[Base KorPatBERT]
[KorPatBERT-grande]
Se extrajeron aproximadamente 10 millones de sustantivos principales y compuestos de los documentos de patente utilizados en el aprendizaje de modelos lingüísticos, se agregaron al diccionario de usuario del analizador de morfemas coreano Mecab-ko y luego se dividieron en subpalabras a través de Google SentencePiece. Este es un MSP especializado. tokenizador (Tokenizador de patente Mecab-ko Sentencepiece).
| modelo | Arriba@1(ACC) |
|---|---|
| BERT de Google | 72,33 |
| KorBERT | 73,29 |
| KOBERTO | 33,75 |
| KrBERT | 72,39 |
| Base KorPatBERT | 76,32 |
| KorPatBERT-grande | 77.06 |
| modelo | Arriba@1(ACC) | Arriba@3(ACC) | Arriba@5(ACC) |
|---|---|---|---|
| Base KorPatBERT | 61,91 | 82.18 | 86,97 |
| KorPatBERT-grande | 62,89 | 82.18 | 87,26 |
| Nombre del programa | versión | Ruta de la guía de instalación | ¿Requerido? |
|---|---|---|---|
| pitón | 3.6 y superior | https://www.python.org/ | Y |
| anaconda | 4.6.8 y superior | https://www.anaconda.com/ | norte |
| flujo tensor | 2.2.0 y superior | https://www.tensorflow.org/install/pip?hl=ko | Y |
| pieza de oración | 0.1.96 o superior | https://github.com/google/sentencepiece | norte |
| mecab-ko | 0.996-ko-0.0.2 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Y |
| mecab-ko-dic | 2.1.1 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Y |
| mecab-python | 0.996-es-0.9.2 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Y |
| python-mecab-ko | 1.0.11 o superior | https://pypi.org/project/python-mecab-ko/ | Y |
| keras | 2.4.3 y superior | https://github.com/keras-team/keras | norte |
| bert_for_tf2 | 0.14.4 y superior | https://github.com/kpe/bert-for-tf2 | norte |
| tqdm | 4.59.0 y superior | https://github.com/tqdm/tqdm | norte |
| soylp | 0.0.493 o superior | https://github.com/lovit/soynlp | norte |
Installation URL: https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/
mecab-ko > 0.996-ko-0.9.2
mecab-ko-dic > 2.1.1
mecab-python > 0.996-ko-0.9.2
from korpat_tokenizer import Tokenizer
# (vocab_path=Vocabulary 파일 경로, cased=한글->True, 영문-> False)
tokenizer = Tokenizer(vocab_path="./korpat_vocab.txt", cased=True)
# 테스트 샘플 문장
example = "본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다."
# 샘플 토크나이즈
tokens = tokenizer.tokenize(example)
# 샘플 인코딩 (max_len=토큰 최대 길이)
ids, _ = tokenizer.encode(example, max_len=256)
# 샘플 디코딩
decoded_tokens = tokenizer.decode(ids)
# 결과 출력
print("Length of Token dictionary ===>", len(tokenizer._token_dict.keys()))
print("Input example ===>", example)
print("Tokenized example ===>", tokens)
print("Converted example to IDs ===>", ids)
print("Converted IDs to example ===>", decoded_tokens)
Length of Token dictionary ===> 21400
Input example ===> 본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다.
Tokenized example ===> ['[CLS]', '본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.', '[SEP]']
Converted example to IDs ===> [5, 58, 554, 32, 2716, 6554, 817, 20418, 20308, 20514, 15, 732, 15572, 39, 1634, 12, 11, 5934, 20514, 20367, 9, 315, 16, 5922, 17, 33, 279, 20399, 16971, 26, 5934, 20514, 13, 674, 26, 11, 10132, 1686, 33, 3781, 15, 11950, 12, 64, 87, 12, 3958, 315, 10, 51, 39, 25, 11, 5934, 20514, 15, 1803, 12889, 399, 24, 25, 118, 12, 11, 817, 20418, 20308, 299, 20367, 10, 439, 56, 13, 18, 14, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Converted IDs to example ===> ['본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.']
※ Es el mismo que el método de aprendizaje básico de Google BERT. Para ver ejemplos de uso, consulte la sección 2.3 특허분야 사전학습 언어모델(KorPatBERT) 사용자 매뉴얼 .
Estamos difundiendo el modelo lingüístico del Instituto de Información sobre Patentes de Corea a través de ciertos procedimientos a organizaciones, empresas e investigadores interesados en él. Complete el formulario de solicitud y el acuerdo de acuerdo con el procedimiento de solicitud a continuación y envíe la solicitud por correo electrónico a la persona a cargo.
| Nombre del archivo | explicación |
|---|---|
| pat_all_mecab_dic.csv | Diccionario de usuario de patentes de Mecab |
| lm_test_data.tsv | Conjunto de datos de muestra de clasificación |
| korpat_tokenizer.py | Programa de tokenizador KorPat |
| test_tokenize.py | Muestra de uso del tokenizador |
| test_tokenize.ipynb | Muestra de uso de Tokenizer (Júpiter) |
| prueba_lm.py | Ejemplo de uso del modelo de lenguaje |
| prueba_lm.ipynb | Ejemplo de uso del modelo de lenguaje (Jupyter) |
| korpat_bert_config.json | Archivo de configuración KorPatBERT |
| korpat_vocab.txt | Archivos de vocabulario KorPatBERT |
| modelo.ckpt-381250.meta | Archivo de modelo KorPatBERT |
| modelo.ckpt-381250.index | Archivo de modelo KorPatBERT |
| modelo.ckpt-381250.data-00000-of-00001 | Archivo de modelo KorPatBERT |


