cape webservices
1.0.0
Punto de entrada para todos los servicios web de backend cape.
La demostración de Frontend está aquí (solo funciona si ya lanzó un Backend).
Cape es un conjunto de bibliotecas de código abierto para gestionar un modelo de respuesta a preguntas "leyendo" documentos automáticamente. Se basa en modelos de lectura automática de última generación entrenados en conjuntos de datos masivos e incluye varios mecanismos para facilitar su uso y mejorar en función de los comentarios de los usuarios. Ha sido diseñado para ser portátil , es decir, funciona en una sola computadora portátil o en un grupo de máquinas paralelas para acelerar el cálculo, y es amigable con el código abierto para ser utilizado en todos los niveles de experiencia.
Permite a los usuarios
Hay varias formas de utilizar Cape:
from cape_responder.responder_core import Responder
Responder.get_answers_from_documents('my-token','How easy is Cape to use', text ="Cape is an open source large-scale question answering system and is super easy to use!")
python3 -m cape_webservices.rundocker run -p 5050:5050 bloomsburyai/capeRecomendamos al menos 3 GB de RAM y al menos 2 núcleos de CPU modernos (4 si son virtuales). Si está utilizando Docker, asegúrese de aumentar los límites de recursos de memoria en las preferencias de Docker.
Puede ejecutar una versión independiente de la aplicación web que incluye un panel de administración. Después de instalar Docker, actualice y ejecute la imagen de Cape:
docker pull bloomsburyai/cape && docker run -ti -p 5050:5050 -p 5051:5051 bloomsburyai/cape
Esto iniciará los servicios web backend y frontend; de forma predeterminada, también creará túneles para ambos, generando las URL públicas:
RANDOM_STRING_HERE .ngrok.io?configuration={"api":{"backendURL":"https:// RANDOM_STRING_HERE .ngrok .io:5050","timeout":"15000"}} Extraiga la última versión de la imagen de Docker (tardará unos momentos para descargar todas las dependencias y un modelo de lectura automática): docker pull bloomsburyai/cape
Ejecute el contenedor Docker e inicie una consola IPython dentro de él usando el siguiente comando: docker run -ti -p 5050:5050 -p 5051:5051 bloomsburyai/cape ipython3
Importar Respondedor: from cape_responder.responder_core import Responder
Haga una pregunta y almacene la respuesta (que es una lista de respuestas) y muestre la primera respuesta usando: response = Responder.get_answers_from_documents('my-token','How easy is Cape to use?', text="Cape is an open source large-scale question answering system and is super easy to use!"); print(response[0]['answerText'])
Si está interesado en comprender un poco más cómo se ve la respuesta, muestre la respuesta completa usando: print(response)
Para instalar Cape de forma nativa en un sistema Linux, consulte implementación/Dockerfile.
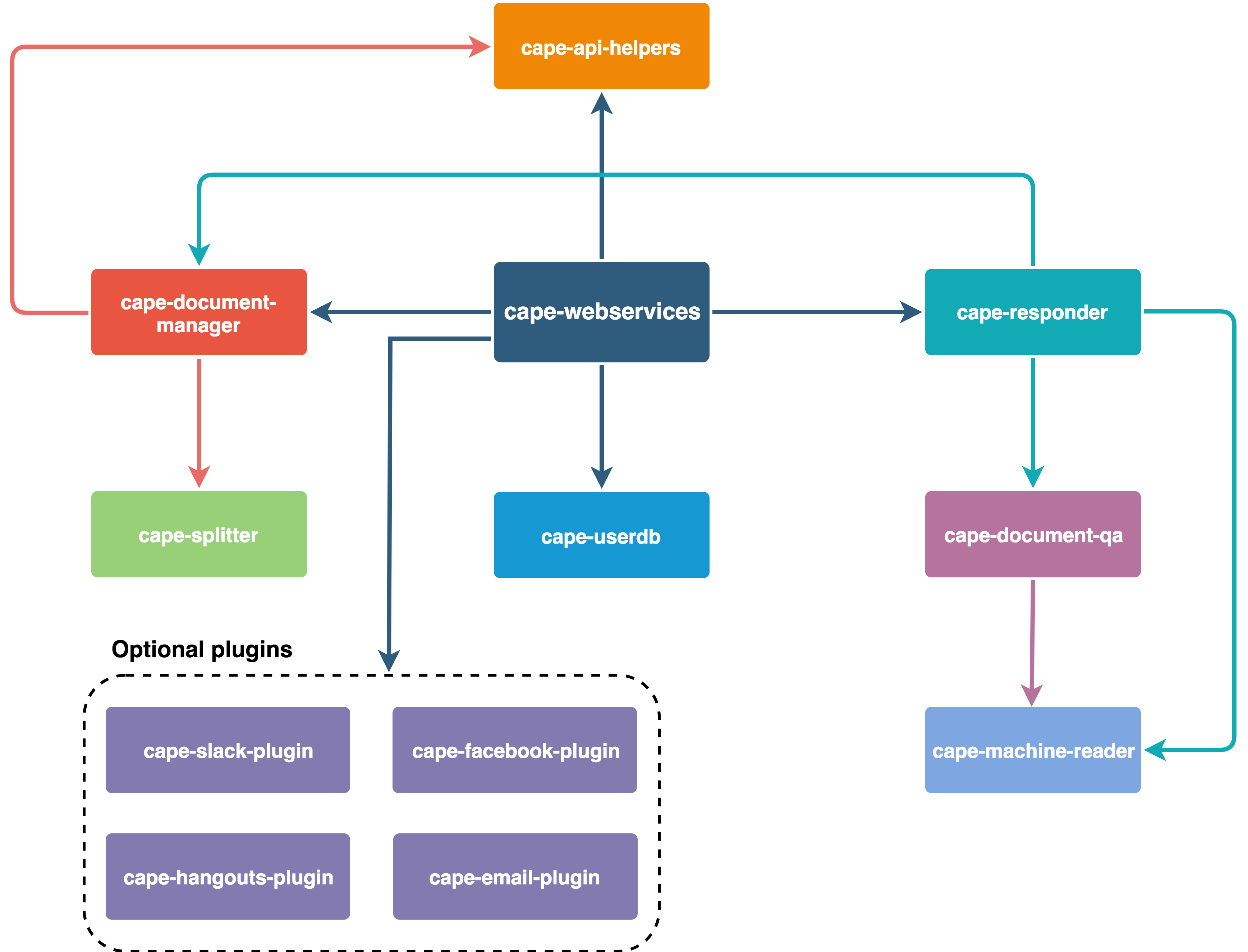
En resumen así está organizado Cabo:


