amazon sagemaker clip search
1.0.0
Este repositorio tiene como objetivo construir un prototipo de motor de búsqueda impulsado por aprendizaje automático (ML) para recuperar y recomendar productos basados en consultas de texto o imágenes. Esta es una guía paso a paso sobre cómo crear modelos de SageMaker con entrenamiento previo de imágenes y lenguaje contrastivo (CLIP), usar los modelos para codificar imágenes y texto en incrustaciones, ingerir incrustaciones en el índice de Amazon OpenSearch Service y consultar el índice. utilizando la funcionalidad de vecinos más cercanos (KNN) del servicio OpenSearch.
La recuperación basada en incrustación (EBR) se utiliza bien en sistemas de búsqueda y recomendación. Utiliza algoritmos de búsqueda de vecinos más cercanos (aproximados) para encontrar elementos similares o estrechamente relacionados en una tienda integrada (también conocida como base de datos vectorial). Los mecanismos de búsqueda clásicos dependen en gran medida de la coincidencia de palabras clave e ignoran el significado léxico o el contexto de la consulta. El objetivo de EBR es brindar a los usuarios la posibilidad de encontrar los productos más relevantes utilizando texto libre. Es popular porque, en comparación con la concordancia de palabras clave, aprovecha los conceptos semánticos en el proceso de recuperación.
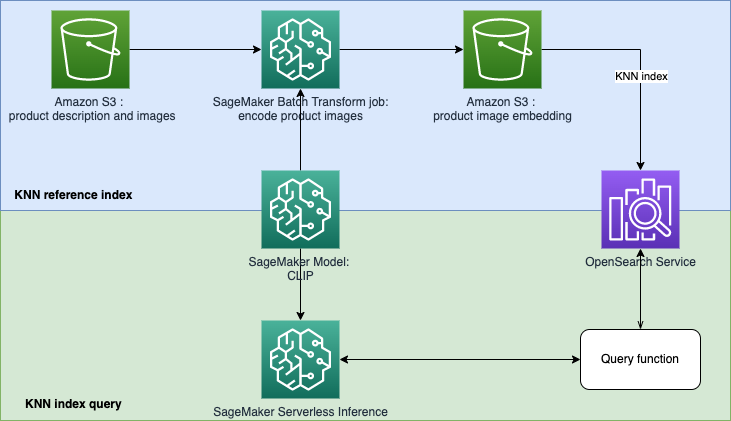
En este repositorio, nos centramos en crear un prototipo de motor de búsqueda impulsado por aprendizaje automático (ML) para recuperar y recomendar productos basados en consultas de texto o imágenes. Esto utiliza Amazon OpenSearch Service y su funcionalidad de k-vecinos más cercanos (KNN), así como Amazon SageMaker y su función de inferencia sin servidor. Amazon SageMaker es un servicio totalmente administrado que brinda a todos los desarrolladores y científicos de datos la capacidad de crear, entrenar e implementar modelos de aprendizaje automático para cualquier caso de uso con infraestructura, herramientas y flujos de trabajo totalmente administrados. Amazon OpenSearch Service es un servicio totalmente administrado que facilita la realización de análisis de registros interactivos, monitoreo de aplicaciones en tiempo real, búsqueda de sitios web y más.
El preentrenamiento de imagen y lenguaje contrastivo (CLIP) es una red neuronal entrenada en una variedad de pares de imágenes y texto. Las redes neuronales CLIP pueden proyectar imágenes y texto en el mismo espacio latente, lo que significa que se pueden comparar utilizando una medida de similitud, como la similitud del coseno. Puede utilizar CLIP para codificar las imágenes o la descripción de sus productos en incrustaciones y luego almacenarlas en una base de datos vectorial. Luego, sus clientes pueden realizar consultas en la base de datos para recuperar productos que puedan interesarles. Para consultar la base de datos, sus clientes deben proporcionar imágenes o texto de entrada, y luego la entrada se codificará con CLIP antes de enviarla a la base de datos de vectores para la búsqueda KNN.
La base de datos vectorial desempeña aquí el papel de motor de búsqueda. Esta base de datos vectorial admite imágenes unificadas y búsqueda basada en texto, lo que es particularmente útil en las industrias del comercio electrónico y la venta minorista. Un ejemplo de búsqueda basada en imágenes es que sus clientes pueden buscar un producto tomando una fotografía y luego consultar la base de datos utilizando la imagen. En cuanto a la búsqueda basada en texto, sus clientes pueden describir un producto en texto de formato libre y luego utilizar el texto como consulta. Los resultados de la búsqueda se ordenarán por una puntuación de similitud (similitud de coseno), si un elemento de su inventario es más similar a la consulta (una imagen o texto de entrada), la puntuación estará más cerca de 1; de lo contrario, la puntuación estará más cerca de 0. Los K productos principales de sus resultados de búsqueda son los productos más relevantes de su inventario.
El servicio OpenSearch proporciona búsqueda basada en KNN integrada y de coincidencia de texto. Usaremos la integración de búsqueda basada en KNN en esta solución. Puede utilizar tanto imagen como texto como consulta para buscar artículos del inventario. La implementación de esta aplicación de búsqueda unificada basada en KNN de prueba e imagen consta de dos fases:
La solución utiliza los siguientes servicios y características de AWS:
En la plantilla opensearch.yml , creará un dominio OpenSearch y le otorgará su función de ejecución de SageMaker Studio para usar el dominio.
En la plantilla sagemaker-studio-opensearch.yml , creará un nuevo dominio SageMaker, un perfil de usuario en el dominio y un dominio OpenSearch. Por lo tanto, puede utilizar el perfil de usuario de StageMaker para crear esta prueba de concepto.
Puede elegir una de las plantillas para ejecutar siguiendo los pasos que se enumeran a continuación.
Paso 1: vaya al servicio CloudFormation en su consola de AWS. 
Paso 2: cargue una plantilla para crear una pila clip-poc-stack de CloudFormation.
Si ya tiene SageMaker Studio en ejecución, puede usar la plantilla opensearch.yml . 
Si no tiene SageMaker Studio en este momento, puede usar la plantilla sagemaker-studio-opensearch.yml . Creará un dominio de Studio y un perfil de usuario para usted.
Paso 3: Verifique el estado de la pila de CloudFormation. Tardará unos 20 minutos en finalizar la creación. 
Una vez creada la pila, puede ir a SageMaker Console y hacer clic en Open Studio para ingresar al entorno de Jupyter. 
Si durante la ejecución, CloudFormation muestra errores sobre la función vinculada al servicio OpenSearch, no se puede encontrar. Debe crear un rol vinculado al servicio ejecutando aws iam create-service-linked-role --aws-service-name es.amazonaws.com en su cuenta de AWS.
Abra el archivo blog_clip.ipynb con SageMaker Studio y utilice el kernel Data Science Python 3 . Puedes ejecutar celdas desde el principio.
En la implementación se utiliza el conjunto de datos de objetos de Amazon Berkeley. El conjunto de datos es una colección de 147.702 listados de productos con metadatos multilingües y 398.212 imágenes de catálogo únicas. Solo utilizaremos las imágenes y los nombres de los artículos en inglés de EE. UU. Para fines de demostración, utilizaremos ~1600 productos.
Esta sección describe las consideraciones de costos para ejecutar esta demostración. Al completar la prueba de concepto se implementará un OpenSearch Cluster y un SageMaker Studio que costará menos de $2 por hora. Notado: el precio que se indica a continuación se calcula utilizando la región us-east-1. El costo varía de una región a otra. Y el costo también puede cambiar con el tiempo (el precio aquí está registrado el 22/11/2022).
A continuación se desglosan más costos.
Servicio OpenSearch : los precios varían según el uso del tipo de instancia y el costo de almacenamiento. Para obtener más información, consulte Precios del servicio Amazon OpenSearch.
t3.small.search se ejecuta durante aproximadamente 1 hora a 0,036 dólares la hora.SageMaker : los precios varían según el uso de la instancia EC2 para las aplicaciones Studio, los trabajos de transformación por lotes y los puntos finales de inferencia sin servidor. Para obtener más información, consulte Precios de Amazon SageMaker.
ml.t3.medium para Studio Notebooks se ejecuta durante aproximadamente 1 hora a $0,05 por hora.ml.c5.xlarge para Batch Transform se ejecuta durante aproximadamente 6 minutos a $0,204 por hora.S3 – Bajo costo, los precios variarán dependiendo del tamaño de los modelos/artefactos almacenados. Los primeros 50 TB de cada mes costarán sólo 0,023 dólares por GB almacenado. Para obtener más información, consulte Precios de Amazon S3.
Consulte CONTRIBUCIÓN para obtener más información.
Esta biblioteca tiene la licencia MIT-0. Ver el archivo de LICENCIA.


