mlmm evaluation
1.0.0
Marco de evaluación para modelos multilingües de lenguajes grandes
Este repositorio contiene conjuntos de datos de referencia y scripts de evaluación para modelos multilingües de lenguajes grandes (LLM). Estos conjuntos de datos se pueden utilizar para evaluar los modelos en 26 idiomas diferentes y abarcan tres tareas distintas: ARC, HellaSwag y MMLU. Esto se publica como parte de nuestro marco Okapi para LLM multilingües ajustados a la instrucción con aprendizaje reforzado a partir de comentarios humanos.
Actualmente, nuestros conjuntos de datos admiten 26 idiomas: ruso, alemán, chino, francés, español, italiano, holandés, vietnamita, indonesio, árabe, húngaro, rumano, danés, eslovaco, ucraniano, catalán, serbio, croata, hindi, bengalí, tamil. Nepalí, malayalam, marathi, telugu y kannada.
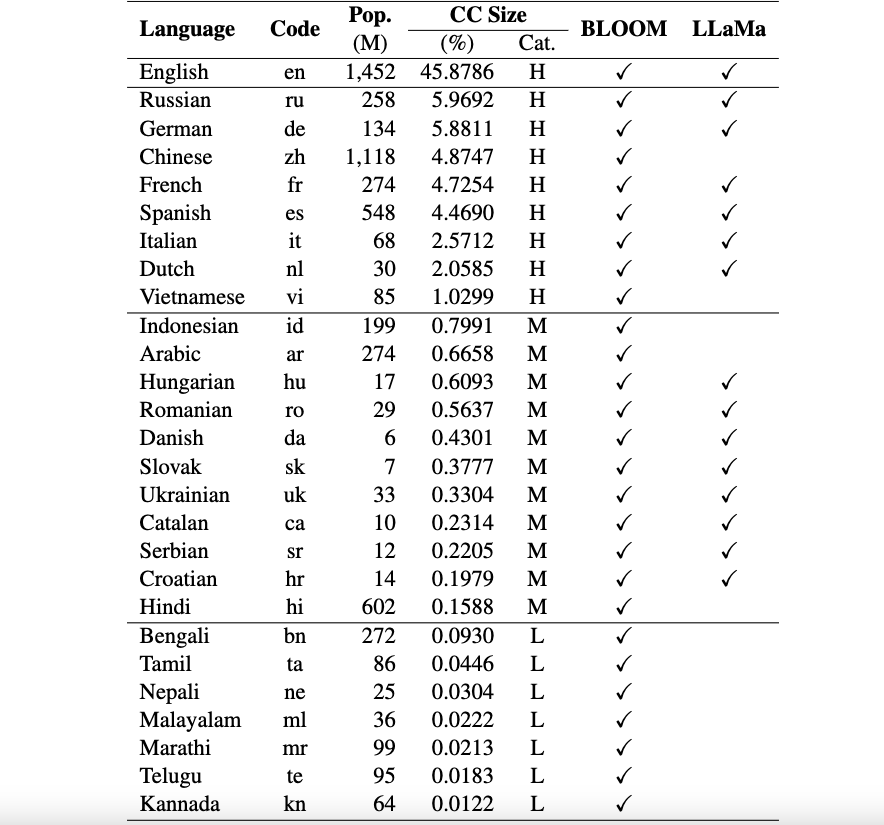
Estos conjuntos de datos se traducen de los conjuntos de datos originales ARC, HellaSwag y MMLU en inglés mediante ChatGPT. Nuestro documento técnico para Okapi para describir los conjuntos de datos junto con los resultados de la evaluación de varios LLM multilingües (por ejemplo, BLOOM, LLaMa y nuestros modelos Okapi) se puede encontrar aquí.
Avisos de uso y licencia : nuestro marco de evaluación está diseñado y tiene licencia para uso exclusivo en investigación. Los conjuntos de datos son CC BY NC 4.0 (permite únicamente el uso no comercial) y no deben utilizarse fuera de fines de investigación.
Para instalar lm-eval desde la rama principal de nuestro repositorio, ejecute:
git clone https://github.com/nlp-uoregon/mlmm-evaluation.git
cd mlmm-evaluation
pip install -e " .[multilingual] " En primer lugar, debe descargar los conjuntos de datos de evaluación multilingües mediante el siguiente script:
bash scripts/download.shPara evaluar su modelo en tres tareas, puede utilizar el siguiente script:
bash scripts/run.sh [LANG] [YOUR-MODEL-PATH]Por ejemplo, si desea evaluar nuestro modelo vietnamita Okapi, puede ejecutar:
bash scripts/run.sh vi uonlp/okapi-vi-bloomMantenemos una tabla de clasificación para seguir el progreso del LLM multilingüe.
Nuestro marco heredó en gran medida del repositorio lm-evaluación-arnés de EleutherAI. Por favor, cite también su repositorio si utiliza el código.
Si utiliza los datos, el modelo o el código de este repositorio, cite:
@article { dac2023okapi ,
title = { Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback } ,
author = { Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu } ,
journal = { arXiv e-prints } ,
pages = { arXiv--2307 } ,
year = { 2023 }
}

