KoGPT2
1.0.0
GPT-2 es un modelo de lenguaje aprendido para predecir bien la siguiente palabra en un texto determinado y está optimizado para la generación de oraciones. KoGPT2 es un modelo de lenguaje decoder coreano aprendido con más de 40 GB de texto para superar el rendimiento insuficiente del idioma coreano.
 |
Entrenado con Character BPE tokenizer del paquete tokenizers .
El tamaño del diccionario es 51.200 y la capacidad de reconocimiento de los tokens se ha aumentado añadiendo emoticones y emojis, como los que se utilizan con frecuencia en las conversaciones, como se muestra a continuación.
?, ?, ?, ?, ?, .. ,
:-),:),-),(-:...
Además, se definieron tokens no utilizados, como <unused0> a <unused99> para que pudieran definirse y usarse libremente según la tarea requerida.
> from transformers import PreTrainedTokenizerFast
> tokenizer = PreTrainedTokenizerFast . from_pretrained ( "skt/ KoGPT2 -base-v2" ,
bos_token = '</s>' , eos_token = '</s>' , unk_token = '<unk>' ,
pad_token = '<pad>' , mask_token = '<mask>' )
> tokenizer . tokenize ( "안녕하세요. 한국어 GPT-2 입니다.?:)l^o" )
[ '▁안녕' , '하' , '세' , '요.' , '▁한국어' , '▁G' , 'P' , 'T' , '-2' , '▁입' , '니다.' , '?' , ':)' , 'l^o' ]| Modelo | # de parámetros | Tipo | # de capas | # de cabezas | ffn_dim | atenuaciones_ocultas |
|---|---|---|---|---|---|---|
KoGPT2 -base-v2 | 125M | Descifrador | 12 | 12 | 3072 | 768 |
> import torch
> from transformers import GPT2LMHeadModel
> model = GPT2LMHeadModel . from_pretrained ( 'skt/ KoGPT2 -base-v2' )
> text = '근육이 커지기 위해서는'
> input_ids = tokenizer . encode ( text , return_tensors = 'pt' )
> gen_ids = model . generate ( input_ids ,
max_length = 128 ,
repetition_penalty = 2.0 ,
pad_token_id = tokenizer . pad_token_id ,
eos_token_id = tokenizer . eos_token_id ,
bos_token_id = tokenizer . bos_token_id ,
use_cache = True )
> generated = tokenizer . decode ( gen_ids [ 0 ])
> print ( generated )
근육이 커지기 위해서는 무엇보다 규칙적인 생활습관이 중요하다 .
특히 , 아침식사는 단백질과 비타민이 풍부한 과일과 채소를 많이 섭취하는 것이 좋다 .
또한 하루 30 분 이상 충분한 수면을 취하는 것도 도움이 된다 .
아침 식사를 거르지 않고 규칙적으로 운동을 하면 혈액순환에 도움을 줄 뿐만 아니라 신진대사를 촉진해 체내 노폐물을 배출하고 혈압을 낮춰준다 .
운동은 하루에 10 분 정도만 하는 게 좋으며 운동 후에는 반드시 스트레칭을 통해 근육량을 늘리고 유연성을 높여야 한다 .
운동 후 바로 잠자리에 드는 것은 피해야 하며 특히 아침에 일어나면 몸이 피곤해지기 때문에 무리하게 움직이면 오히려 역효과가 날 수도 있다 ...| NSMC(acc) | KorSTS(lancero) | |
|---|---|---|
| KoGPT2 2.0 | 89.1 | 77,8 |
Además de la Wikipedia coreana, se utilizaron varios datos, como noticias y el corpus v1.0 de todos, para entrenar el modelo.
enlace de demostración
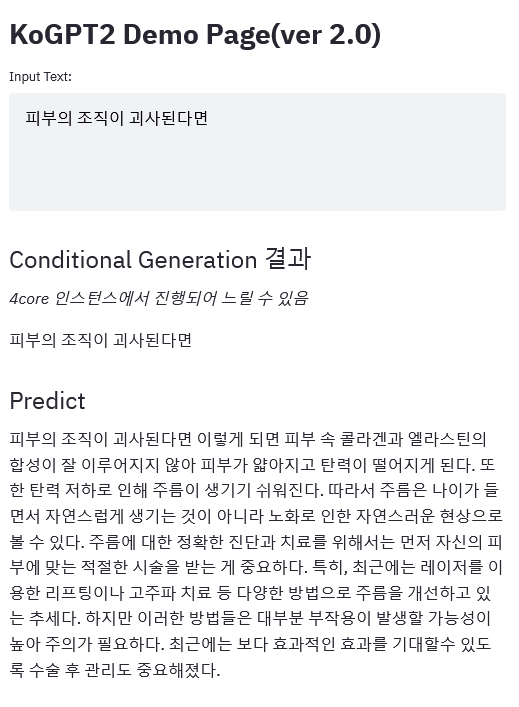 |
Publique problemas relacionados con KoGPT2 aquí.
KoGPT2 se publica bajo la licencia CC-BY-NC-SA 4.0. Cumpla con los términos de la licencia cuando utilice modelos y códigos. La licencia completa se puede encontrar en el archivo LICENCIA.


