icl selective annotation
1.0.0
Código para papel La anotación selectiva hace que los modelos de lenguaje sean mejores para los estudiantes con pocas oportunidades
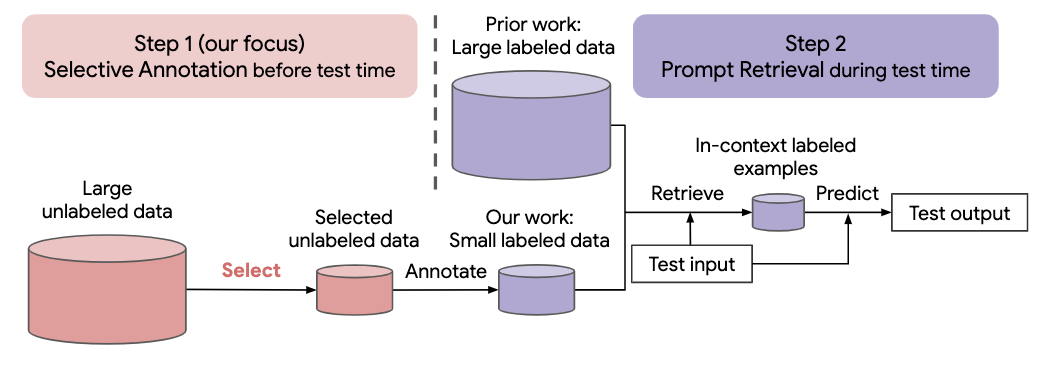
Muchos enfoques recientes de tareas de lenguaje natural se basan en las notables capacidades de grandes modelos de lenguaje. Los modelos de lenguaje grandes pueden realizar un aprendizaje en contexto, donde aprenden una nueva tarea a partir de algunas demostraciones de tareas, sin ninguna actualización de parámetros. Este trabajo examina las implicaciones del aprendizaje en contexto para la creación de conjuntos de datos para nuevas tareas de lenguaje natural. Partiendo de métodos recientes de aprendizaje en contexto, formulamos un marco de dos pasos eficiente en la anotación: anotación selectiva que elige un grupo de ejemplos para anotar de datos sin etiquetar por adelantado, seguida de una recuperación rápida que recupera ejemplos de tareas del grupo anotado en tiempo de prueba. Con base en este marco, proponemos un método de anotación selectiva basado en gráficos, no supervisado, vote-k , para seleccionar ejemplos diversos y representativos para anotar. Amplios experimentos en 10 conjuntos de datos (que cubren clasificación, razonamiento de sentido común, diálogo y generación de texto/código) demuestran que nuestro método de anotación selectiva mejora el desempeño de la tarea por un amplio margen. En promedio, vote-k logra una ganancia relativa del 12,9%/11,4% con un presupuesto de anotación de 18/100, en comparación con la selección aleatoria de ejemplos para anotar. En comparación con los enfoques de ajuste supervisados de última generación, produce un rendimiento similar con un costo de anotación entre 10 y 100 veces menor en 10 tareas. Analizamos más a fondo la efectividad de nuestro marco en varios escenarios: modelos de lenguaje con diferentes tamaños, métodos alternativos de anotación selectiva y casos en los que hay un cambio en el dominio de los datos de prueba. Esperamos que nuestros estudios sirvan como base para las anotaciones de datos a medida que los modelos de lenguaje grandes se apliquen cada vez más a nuevas tareas.
Ejecute el siguiente comando para clonar este repositorio
git clone https://github.com/HKUNLP/icl-selective-annotation
Para establecer el entorno, ejecute este código en el shell:
conda env create -f selective_annotation.yml
conda activate selective_annotation
cd transformers
pip install -e .
Eso creará el entorno de anotación selectiva que utilizamos.
Activa el entorno ejecutando
conda activate selective_annotation
GPT-J como modelo de aprendizaje en contexto, DBpedia como tarea y vote-k como método de anotación selectiva (1 GPU, 40 GB de memoria)
python main.py --task_name dbpedia_14 --selective_annotation_method votek --model_cache_dir models --data_cache_dir datasets --output_dir outputs
Si encuentra útil nuestro trabajo, cítenos
@article{Selective_Annotation,
title={Selective Annotation Makes Language Models Better Few-Shot Learners},
author={Hongjin Su and Jungo Kasai and Chen Henry Wu and Weijia Shi and Tianlu Wang and Jiayi Xin and Rui Zhang and Mari Ostendorf and Luke Zettlemoyer and Noah A. Smith and Tao Yu},
journal={ArXiv},
year={2022},
}


