Phi2 mini Chinese
1.0.0
Este proyecto es un proyecto experimental, con código fuente abierto y pesos de modelo, y menos datos de entrenamiento previo. Si necesita un modelo pequeño chino mejor, puede consultar el proyecto ChatLM-mini-Chinese.
Precaución
Este proyecto es un proyecto experimental y puede estar sujeto a cambios importantes en cualquier momento, incluidos los datos de entrenamiento, la estructura del modelo, la estructura del directorio de archivos, etc. La primera versión del modelo y verifique tag v1.0
Por ejemplo, agregar puntos al final de oraciones, convertir chino tradicional a chino simplificado, eliminar signos de puntuación repetidos (por ejemplo, algunos materiales de diálogo tienen muchos "。。。。。" ), estandarización NFKC Unicode (principalmente el problema de la conversión de ancho a medio ancho y datos de página web u3000 xa0), etc.
Para conocer el proceso de limpieza de datos específico, consulte el proyecto ChatLM-mini-Chinese.
Este proyecto utiliza el tokenizador BPE byte level . Hay dos tipos de códigos de entrenamiento proporcionados para segmentadores de palabras: char level y byte level .
Después del entrenamiento, el tokenizador recuerda verificar si hay símbolos especiales comunes en el vocabulario, como t , n , etc. Puede intentar encode y decode un texto que contenga caracteres especiales para ver si se puede restaurar. Si estos caracteres especiales no están incluidos, agréguelos mediante la función add_tokens . Utilice len(tokenizer) para obtener el tamaño del vocabulario. tokenizer.vocab_size no cuenta los caracteres agregados mediante la función add_tokens .
El entrenamiento con Tokenizer consume mucha memoria:
Entrenar 100 millones de caracteres byte level requiere al menos 32G de memoria (de hecho, 32G no es suficiente y el intercambio se activará con frecuencia. El entrenamiento 13600k lleva aproximadamente una hora).
El entrenamiento char level de 650 millones de caracteres (que es exactamente la cantidad de datos en la Wikipedia china) requiere al menos 32 G de memoria. Debido a que el intercambio se activa varias veces, el uso real es mucho más que 32 G. El entrenamiento 13600K requiere aproximadamente la mitad. hora.
Por lo tanto, cuando el conjunto de datos es grande (nivel GB), se recomienda tomar muestras del conjunto de datos al entrenar tokenizer .
Utilice una gran cantidad de texto para el entrenamiento previo no supervisado, principalmente utilizando el conjunto de datos BELLE de bell open source .
Formato del conjunto de datos: una oración para una muestra si es demasiado larga, se puede truncar y dividir en varias muestras.
Durante el proceso de preentrenamiento de CLM, la entrada y la salida del modelo son las mismas y, al calcular la pérdida de entropía cruzada, se deben desplazar un bit ( shift ).
Al procesar corpus de enciclopedia, se recomienda agregar la marca '[EOS]' al final de cada entrada. Otro procesamiento de corpus es similar. El final de un doc (que puede ser el final de un artículo o el final de un párrafo) debe marcarse con '[EOS]' . La marca de inicio '[BOS]' se puede agregar o no.
Utilice principalmente el conjunto de datos de bell open source . Gracias jefa BELLA.
El formato de datos para el entrenamiento SFT es el siguiente:
text = f"##提问: n { example [ 'instruction' ] } n ##回答: n { example [ 'output' ][ EOS ]" Cuando el modelo calcula la pérdida, ignorará la parte anterior a la marca "##回答:" ( "##回答:" también se ignorará), comenzando desde el final de "##回答:" .
Recuerde agregar la marca especial de final de oración EOS ; de lo contrario, no sabrá cuándo detenerse al decode el modelo. La marca de inicio de la oración BOS se puede completar o dejar en blanco.
Adopte un método de optimización de preferencias de DPO más simple y que ahorre más memoria.
Ajuste el modelo SFT de acuerdo con las preferencias personales. El conjunto de datos debe construir tres columnas: prompt , chosen y rejected . La columna rejected tiene algunos datos del modelo primario en la etapa sft (por ejemplo, sft entrena 4 epoch y toma una). Modelo de punto de control epoch 0,5) Generar, si la similitud entre el rejected y chosen generado es superior a 0,9, entonces estos datos no serán necesarios.
Hay dos modelos en el proceso DPO, uno es el modelo a entrenar y el otro es el modelo de referencia. Cuando se carga, en realidad es el mismo modelo, pero el modelo de referencia no participa en la actualización de parámetros.
Repositorio de modelos de peso huggingface : Phi2-Chinese-0.2B
from transformers import AutoTokenizer , AutoModelForCausalLM , GenerationConfig
import torch
device = torch . device ( "cuda" ) if torch . cuda . is_available () else torch . device ( "cpu" )
tokenizer = AutoTokenizer . from_pretrained ( 'charent/Phi2-Chinese-0.2B' )
model = AutoModelForCausalLM . from_pretrained ( 'charent/Phi2-Chinese-0.2B' ). to ( device )
txt = '感冒了要怎么办?'
prompt = f"##提问: n { txt } n ##回答: n "
# greedy search
gen_conf = GenerationConfig (
num_beams = 1 ,
do_sample = False ,
max_length = 320 ,
max_new_tokens = 256 ,
no_repeat_ngram_size = 4 ,
eos_token_id = tokenizer . eos_token_id ,
pad_token_id = tokenizer . pad_token_id ,
)
tokend = tokenizer . encode_plus ( text = prompt )
input_ids , attention_mask = torch . LongTensor ([ tokend . input_ids ]). to ( device ),
torch . LongTensor ([ tokend . attention_mask ]). to ( device )
outputs = model . generate (
inputs = input_ids ,
attention_mask = attention_mask ,
generation_config = gen_conf ,
)
outs = tokenizer . decode ( outputs [ 0 ]. cpu (). numpy (), clean_up_tokenization_spaces = True , skip_special_tokens = True ,)
print ( outs ) ##提问:
感冒了要怎么办?
##回答:
感冒是由病毒引起的,感冒一般由病毒引起,以下是一些常见感冒的方法:
- 洗手,特别是在接触其他人或物品后。
- 咳嗽或打喷嚏时用纸巾或手肘遮住口鼻。
- 用手触摸口鼻,特别是喉咙和鼻子。
- 如果咳嗽或打喷嚏,可以用纸巾或手绢来遮住口鼻,但要远离其他人。
- 如果你感冒了,最好不要触摸自己的眼睛、鼻子和嘴巴。
- 在感冒期间,最好保持充足的水分和休息,以缓解身体的疲劳。
- 如果您已经感冒了,可以喝一些温水或盐水来补充体液。
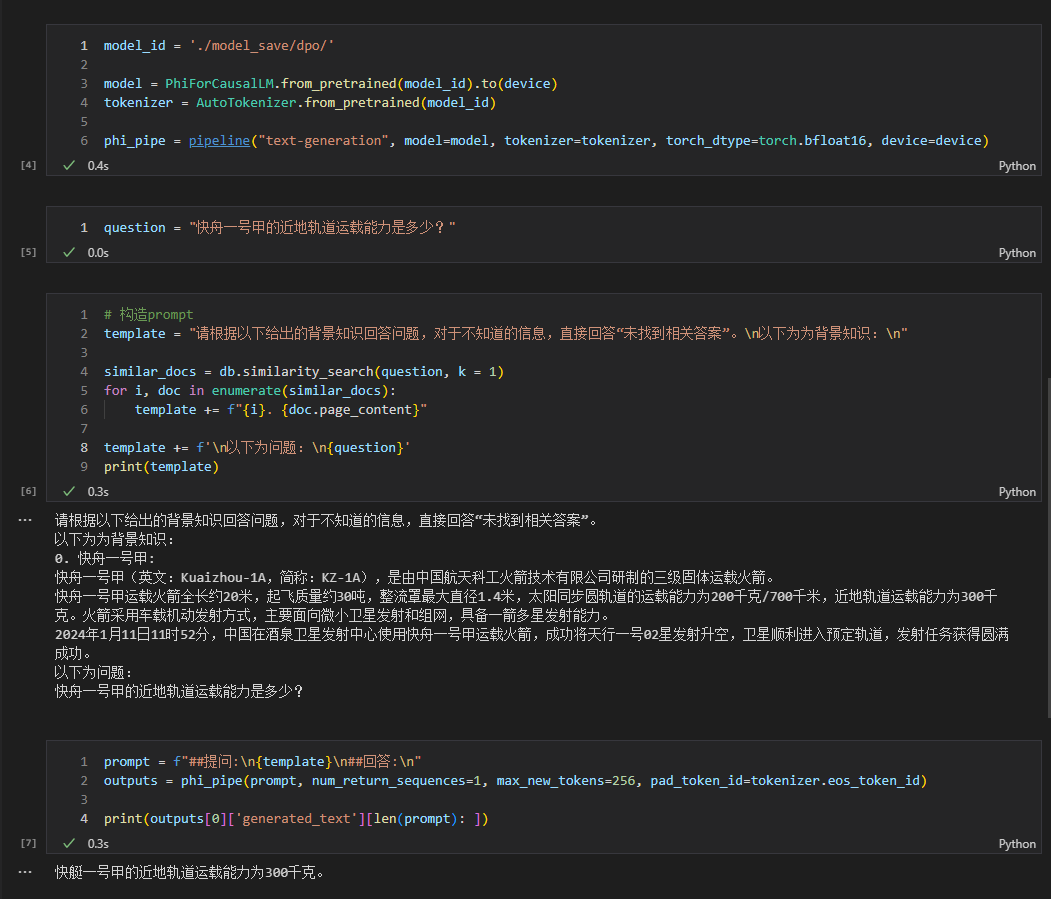
- 另外,如果感冒了,建议及时就医。 Consulte rag_with_langchain.ipynb para ver el código específico.
Si cree que este proyecto le resulta útil, cítelo.
@misc{Charent2023,
author={Charent Chen},
title={A small Chinese causal language model with 0.2B parameters base on Phi2},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/Phi2-mini-Chinese}},
}
Este proyecto no asume los riesgos y responsabilidades de la seguridad de los datos y los riesgos de la opinión pública causados por modelos y códigos de código abierto, o los riesgos y responsabilidades que surgen de cualquier modelo que sea engañado, abusado, difundido o explotado indebidamente.


