reflexion
1.0.0
Este repositorio contiene el código, demostraciones y archivos de registro para reflexion : Agentes lingüísticos con aprendizaje por refuerzo verbal de Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, Shunyu Yao.
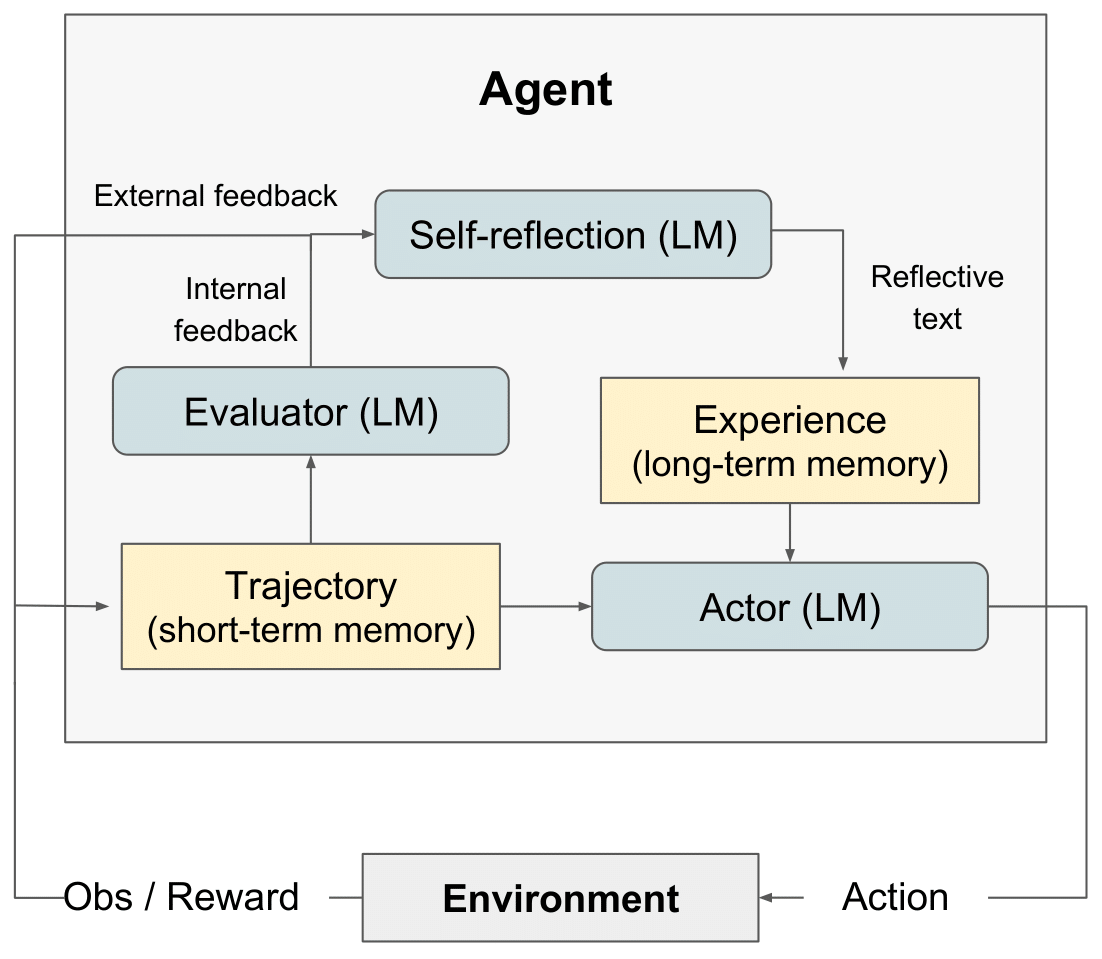 diagrama RL de reflexión" style="max-width: 100%;">
diagrama RL de reflexión" style="max-width: 100%;">
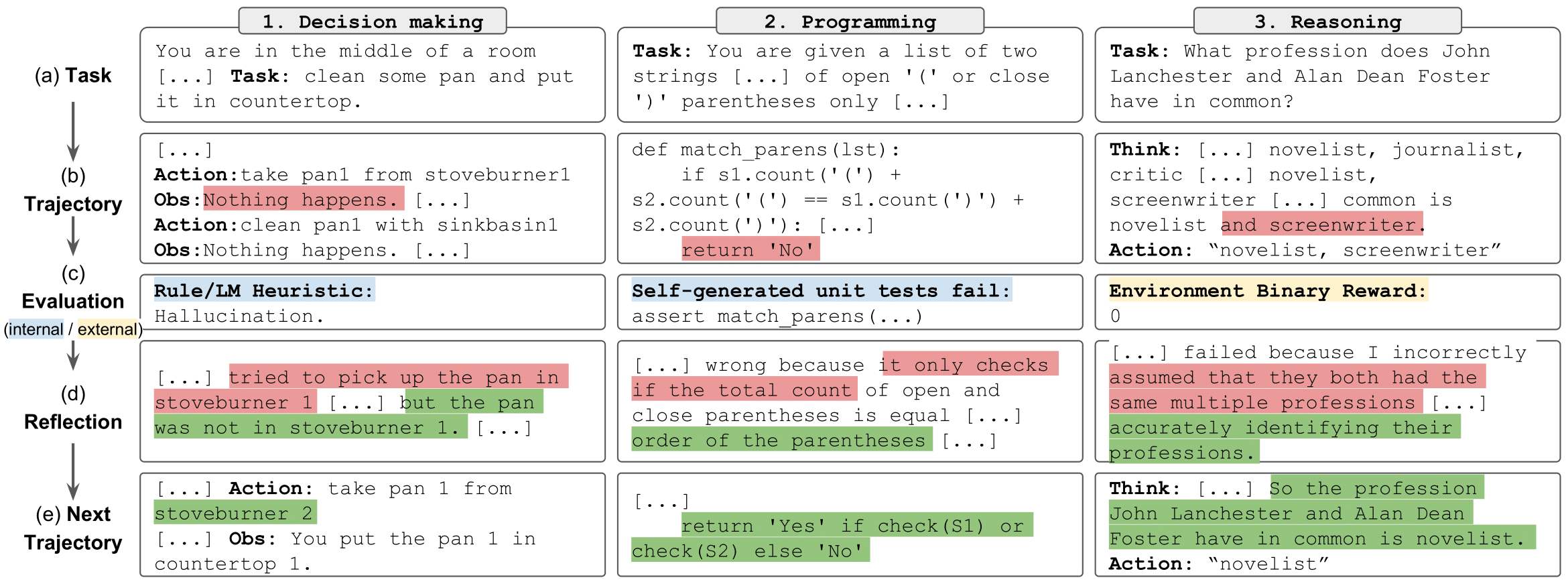 tareas de reflexión" style="max-width: 100%;">
tareas de reflexión" style="max-width: 100%;">
Hemos lanzado LeetcodeHardGym aquí
Proporcionamos un conjunto de cuadernos para ejecutar, explorar e interactuar fácilmente con los resultados de los experimentos de razonamiento. Cada experimento consta de una muestra aleatoria de 100 preguntas del conjunto de datos del distractor HotPotQA. Cada pregunta de la muestra es respondida por un agente con un tipo y una estrategia reflexion específicos.
Para empezar:
git clone https://github.com/noahshinn/reflexion && cd ./hotpotqa_runspip install -r requirements.txtOPENAI_API_KEY en su clave API de OpenAI: export OPENAI_API_KEY= < your key > El tipo de agente está determinado por el cuaderno que elija ejecutar. Los tipos de agentes disponibles incluyen:
ReAct - Agente ReAct
CoT_context : al agente de CoT se le proporciona un contexto de apoyo sobre la pregunta.
CoT_no_context : al agente de CoT no se le proporcionó ningún contexto de apoyo sobre la pregunta
El cuaderno para cada tipo de agente se encuentra en el directorio ./hotpot_runs/notebooks .
Cada cuaderno permite especificar la estrategia reflexion que utilizarán los agentes. Las estrategias reflexion disponibles, que se definen en un Enum , incluyen:
reflexion Strategy.NONE : el agente no recibe ninguna información sobre su último intento.
reflexion Strategy.LAST_ATTEMPT : el agente recibe su rastro de razonamiento desde su último intento sobre la pregunta como contexto.
reflexion Strategy. reflexion : al agente se le da su autorreflexión sobre el último intento como contexto.
reflexion Strategy.LAST_ATTEMPT_AND_ reflexion : al agente se le proporciona tanto su rastro de razonamiento como su autorreflexión sobre el último intento como contexto.
Clona este repositorio y muévete al directorio de AlfWorld
git clone https://github.com/noahshinn/reflexion && cd ./alfworld_runs Especifique los parámetros de ejecución en ./run_ reflexion .sh . num_trials : número de pasos de aprendizaje iterativos num_envs : número de pares de tarea-entorno por prueba run_name : el nombre de esta ejecución use_memory : usa memoria persistente para almacenar autorreflexiones (desactívala para ejecutar una ejecución de referencia) is_resume : usa el directorio de registro para reanudar una ejecución anterior resume_dir : el directorio de registro desde el cual reanudar la ejecución anterior start_trial_num : si se reanuda la ejecución, entonces el número de prueba con el que comenzar
ejecutar la prueba
./run_ reflexion .sh Los registros se enviarán a ./root/<run_name> .
Debido a la naturaleza de estos experimentos, puede que no sea factible para los desarrolladores individuales volver a ejecutar los resultados, ya que GPT-4 tiene acceso limitado y cargos de API importantes. Todas las ejecuciones del artículo y los resultados adicionales se registran en ./alfworld_runs/root para la toma de decisiones, ./hotpotqa_runs/root para razonamiento y ./programming_runs/root para programación.
Consulte el código del código original aquí.
Lea una publicación de blog aquí
Vea una implementación interesante de predicción de tipos aquí: OpenTau
Para todas las preguntas, comuníquese con [email protected]
@misc { shinn2023 reflexion ,
title = { reflexion : Language Agents with Verbal Reinforcement Learning } ,
author = { Noah Shinn and Federico Cassano and Edward Berman and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao } ,
year = { 2023 } ,
eprint = { 2303.11366 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.AI }
}

