LLaMA LoRA Tuner
v0.0.20230421
Facilitar la evaluación y el ajuste de modelos LLaMA con adaptación de rango bajo (LoRA).
Actualizar :
En la rama
dev, hay una nueva interfaz de usuario de chat y una nueva configuración del modo de demostración como una forma sencilla y fácil de demostrar nuevos modelos.Sin embargo, la nueva versión aún no tiene la función de ajuste fino y no es compatible con versiones anteriores, ya que utiliza una nueva forma de definir cómo se cargan los modelos y también un nuevo formato de plantillas de mensajes (de LangChain).
Para obtener más información, consulte: #28.
LLM.Tuner.Chat.UI.en.modo.demo.mp4
Ver una demostración en Hugging Face * Solo sirve para demostración de UI. Para probar la capacitación o la generación de texto, ejecútelo en Colab.
Con 1 clic en funcionamiento en Google Colab con un tiempo de ejecución de GPU estándar.
Carga y almacena datos en Google Drive.
Evalúe varios modelos de LLaMA LoRA almacenados en su carpeta o desde Hugging Face. 
Cambie entre modelos base como decapoda-research/llama-7b-hf , nomic-ai/gpt4all-j , databricks/dolly-v2-7b , EleutherAI/gpt-j-6b o EleutherAI/pythia-6.9b .
Ajuste los modelos LLaMA con diferentes plantillas de mensajes y formatos de conjuntos de datos de entrenamiento. 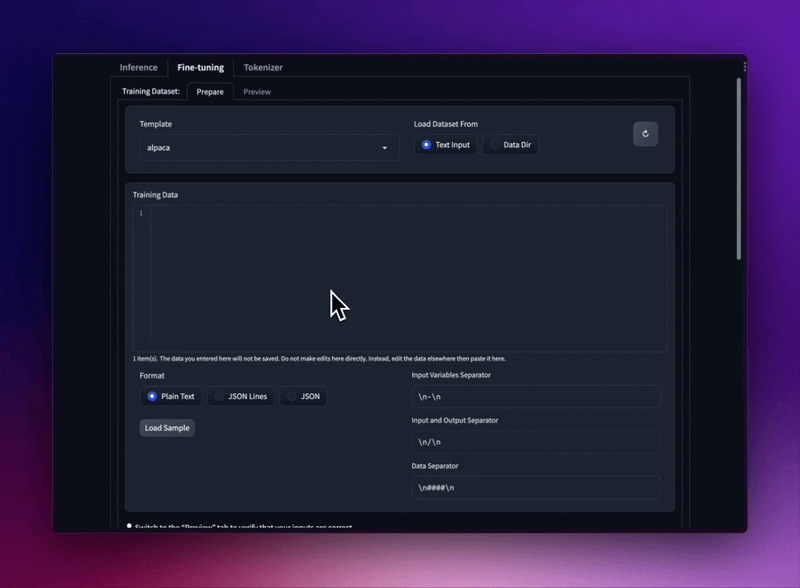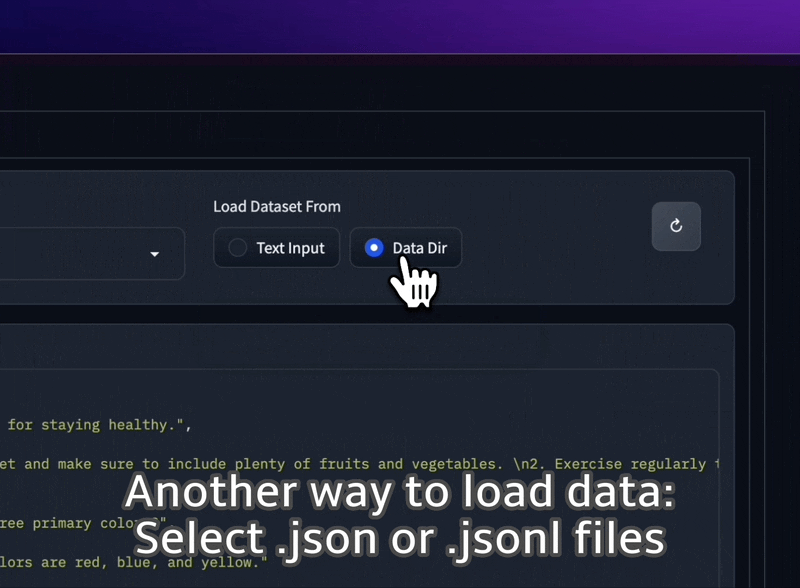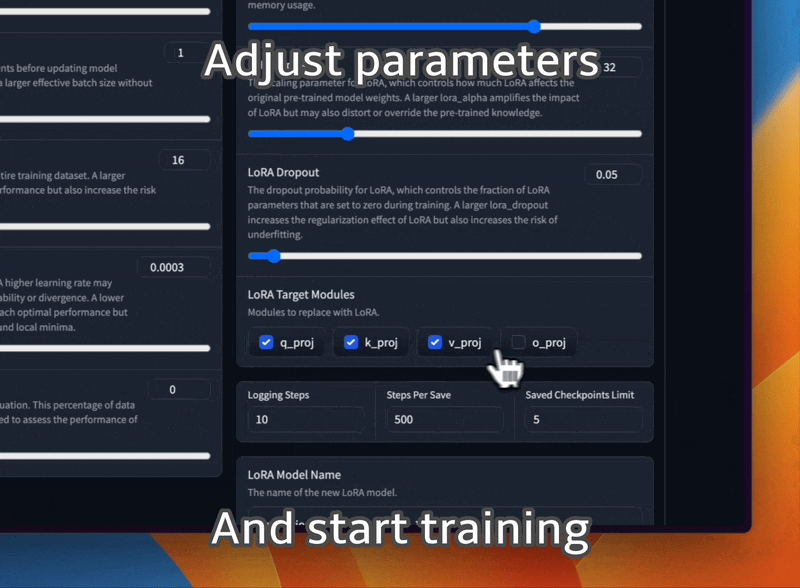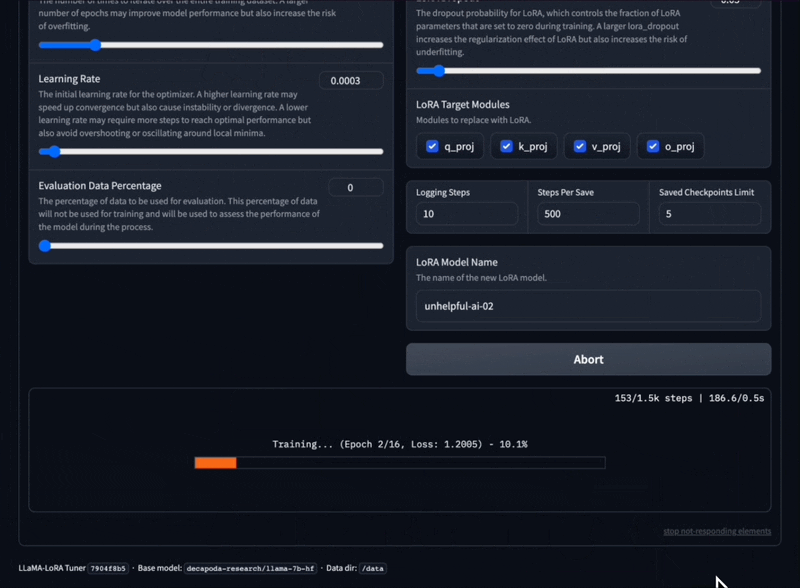
Cargue conjuntos de datos JSON y JSONL desde su carpeta, o incluso pegue texto sin formato directamente en la interfaz de usuario.
Admite el formato Stanford Alpaca seed_tasks, alpaca_data y OpenAI "prompt"-"completion".
Utilice plantillas de mensajes para mantener su conjunto de datos SECO.
Hay varias formas de ejecutar esta aplicación:
Ejecutar en Google Colab : la forma más sencilla de comenzar, todo lo que necesita es una cuenta de Google. El tiempo de ejecución de GPU estándar (gratuito) es suficiente para ejecutar la generación y el entrenamiento con un tamaño de micro lote de 8. Sin embargo, la generación de texto y el entrenamiento son mucho más lentos que en otros servicios en la nube, y Colab podría finalizar la ejecución en inactividad mientras se ejecutan tareas largas.
Ejecutar en un servicio en la nube a través de SkyPilot : si tiene una cuenta de servicio en la nube (Lambda Labs, GCP, AWS o Azure), puede usar SkyPilot para ejecutar la aplicación en un servicio en la nube. Se puede montar un depósito en la nube para preservar sus datos.
Ejecutar localmente : depende del hardware que tengas.
Vea el vídeo para obtener instrucciones paso a paso.
Abra este Colab Notebook y seleccione Runtime > Ejecutar todo ( ⌘/Ctrl+F9 ).
Se le pedirá que autorice el acceso a Google Drive, ya que se utilizará Google Drive para almacenar sus datos. Consulte la sección "Configuración"/"Google Drive" para conocer la configuración y más información.
Después de aproximadamente 5 minutos de ejecución, verá la URL pública en el resultado de la sección "Iniciar"/"Iniciar interfaz de usuario de Gradio" (como Running on public URL: https://xxxx.gradio.live ). Abra la URL en su navegador para usar la aplicación.
Después de seguir la guía de instalación de SkyPilot, cree un .yaml para definir una tarea para ejecutar la aplicación:
# llm-tuner.yamlresources: aceleradores: A10:1 # 1x GPU NVIDIA A10, aproximadamente 0,6 dólares estadounidenses por hora en Lambda Cloud. Ejecute `sky show-gpus` para los tipos de GPU compatibles y `sky show-gpus [GPU_NAME]` para obtener información detallada de un tipo de GPU.
nube: lambda # Opcional; si se omite, SkyPilot elegirá automáticamente la nube más barata.file_mounts: # Monta un almacenamiento en la nube predispuesto que se utilizará como directorio de datos.
# (para almacenar conjuntos de datos de trenes de modelos entrenados)
# Consulte https://skypilot.readthedocs.io/en/latest/reference/storage.html para obtener más detalles.
/data:name: llm-tuner-data # Asegúrese de que este nombre sea único o de que sea propietario de este depósito. Si no existe, SkyPilot intentará crear un depósito con este nombre.store: s3 # Podría ser cualquiera de los modos [s3, gcs]: MOUNT# Clonar el repositorio de LLaMA-LoRA Tuner e instalar sus dependencias.setup: | conda create -q python=3.8 -n llm-tuner -y conda enable llm-tuner # Clona el repositorio de LLaMA-LoRA Tuner e instala sus dependencias [! -d llm_tuner ] && git clone https://github.com/zetavg/LLaMA-LoRA-Tuner.git llm_tuner echo 'Instalando dependencias...' pip install -r llm_tuner/requirements.lock.txt # Opcional: instalar wandb en habilitar el registro en Weights & Biases pip install wandb # Opcional: parchear bitsandbytes para solucionar el error "libbitsandbytes_cpu.so: símbolo indefinido: cget_col_row_stats" BITSANDBYTES_LOCATION="$(pip show bitsandbytes | grep 'Ubicación' | awk '{print $2}')/bitsandbytes" [ -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" ] && [ ! -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so.bak" ] && [ -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cuda121.so" ] && echo 'Parcheando bitsandbytes para compatibilidad con GPU...' && mv "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so.bak" && cp "$BITSANDBYTES_LOCATION/libbitsandbytes_cuda121.so" "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" conda install -q cudatoolkit -y echo 'Dependencias instaladas.' # Opcional: instale y configure Cloudflare Tunnel para exponer la aplicación a Internet con un nombre de dominio personalizado [ -f /data/secrets/cloudflared_tunnel_token.txt ] && echo "Instalando Cloudflare" && curl -L --output cloudflared.deb https: //github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64.deb && sudo dpkg -i cloudflared.deb && desinstalación del servicio sudo cloudflared || : && sudo cloudflared service install "$(cat /data/secrets/cloudflared_tunnel_token.txt | tr -d 'n')" # Opcional: modelos predescargados echo "Predescarga de modelos base para que no tengas que esperar por mucho tiempo una vez que la aplicación esté lista..." python llm_tuner/download_base_model.py --base_model_names='decapoda-research/llama-7b-hf,nomic-ai/gpt4all-j'# Inicie la aplicación. `hf_access_token`, `wandb_api_key` y `wandb_project` son opcionales.ejecutar: | conda activar llm-tuner python llm_tuner/app.py --data_dir='/data' --hf_access_token="$([ -f /data/secrets/hf_access_token.txt ] && cat /data/secrets/hf_access_token.txt | tr -d 'n')" --wandb_api_key="$([ -f /data/secrets/wandb_api_key.txt ] && cat /data/secrets/wandb_api_key.txt | tr -d 'n')" --wandb_project='llm-tuner' --timezone='Atlántico/Reykjavik' --base_model= 'decapoda-research/llama-7b-hf' --base_model_choices='decapoda-research/llama-7b-hf,nomic-ai/gpt4all-j,databricks/dolly-v2-7b' --shareLuego inicie un clúster para ejecutar la tarea:
sky launch -c llm-tuner llm-tuner.yaml
-c ... es un indicador opcional para especificar un nombre de clúster. Si no se especifica, SkyPilot generará uno automáticamente.
Verás la URL pública de la aplicación en la terminal. Abra la URL en su navegador para usar la aplicación.
Tenga en cuenta que al salir de sky launch solo se cerrará la transmisión de registros y no se detendrá la tarea. Puede usar sky queue --skip-finished para ver el estado de las tareas en ejecución o pendientes, sky logs <cluster_name> <job_id> se conectan nuevamente a la transmisión de registros y sky cancel <cluster_name> <job_id> para detener una tarea.
Cuando haya terminado, ejecute sky stop <cluster_name> para detener el clúster. Para terminar un clúster, ejecute sky down <cluster_name> .
Recuerde detener o apagar el clúster cuando haya terminado para evitar incurrir en cargos inesperados. Ejecute sky cost-report para ver el costo de sus clústeres.
Para iniciar sesión en la máquina en la nube, ejecute ssh <cluster_name> , como ssh llm-tuner .
Si tiene sshfs instalado en su máquina local, puede montar el sistema de archivos de la máquina en la nube en su computadora local ejecutando un comando como el siguiente:
mkdir -p /tmp/llm_tuner_server && umount /tmp/llm_tuner_server || : && sshfs llm-tuner:/ /tmp/llm_tuner_server
conda crear -y python=3.8 -n llm-tuner conda activar sintonizador llm
instalación de pip -r requisitos.lock.txt python app.py --data_dir='./data' --base_model='decapoda-research/llama-7b-hf' --timezone='Atlántico/Reykjavik' --share
Verá las URL locales y públicas de la aplicación en la terminal. Abra la URL en su navegador para usar la aplicación.
Para obtener más opciones, consulte python app.py --help .
Para probar la interfaz de usuario sin cargar el modelo de lenguaje, use la opción --ui_dev_mode :
python app.py --data_dir='./data' --base_model='decapoda-research/llama-7b-hf' --share --ui_dev_mode
Para utilizar la recarga automática de Gradio, se requiere un archivo
config.yamlya que los argumentos de la línea de comando no son compatibles. Hay un archivo de muestra para comenzar:cp config.yaml.sample config.yaml. Luego, simplemente ejecutagradio app.py
Ver vídeo en YouTube.
https://github.com/tloen/alpaca-lora
https://github.com/lxe/simple-llama-finetuner
...
por confirmar


