YAYI UIE
1.0.0

[README] [?HF Repo] [?Versión web]
chino | inglés
[2024.03.28] Todos los modelos y datos se cargan en la Comunidad Magic.
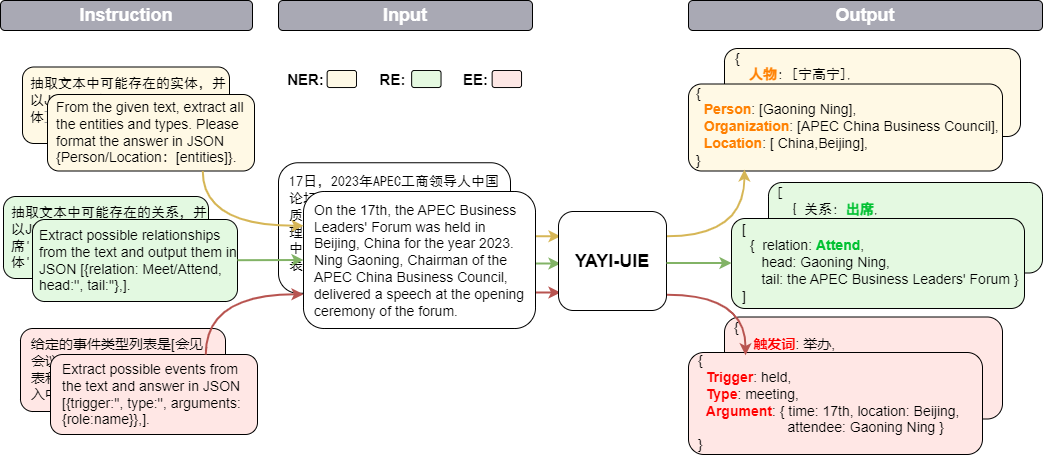
El modelo grande unificado de extracción de información de Yayi (YAYI-UIE) afina las instrucciones de millones de datos de extracción de información de alta calidad construidos manualmente. Las tareas de extracción de información de capacitación unificada incluyen el reconocimiento de entidades con nombre (NER), la extracción de relaciones (RE) y la extracción de eventos (. EE) para lograr una extracción estructurada en escenarios generales, de seguridad, financieros, biológicos, médicos, comerciales, personales, vehiculares, cinematográficos, industriales, gastronómicos, científicos y otros.
A través del código abierto del modelo grande Yayi UIE, contribuiremos con nuestros propios esfuerzos para promover el desarrollo de la comunidad china de código abierto de modelos grandes previamente capacitados. A través del código abierto, construiremos el ecosistema del modelo grande Yayi con cada socio. Para obtener más detalles técnicos, lea nuestro informe técnico YAYI-UIE: Un marco de ajuste de instrucciones mejorado por chat para la extracción universal de información.
| nombre | ? Identificación del modelo HF | Descargar dirección | Logotipo del modelo mágico | Descargar dirección |
|---|---|---|---|---|
| YAYI-UIE | wengué-investigación/yayi-uie | Descarga de modelo | wengué-investigación/yayi-uie | Descarga de modelo |
| Datos de YAYI-UIE | wenge-research/yayi_uie_sft_data | Descarga del conjunto de datos | wenge-research/yayi_uie_sft_data | Descarga del conjunto de datos |
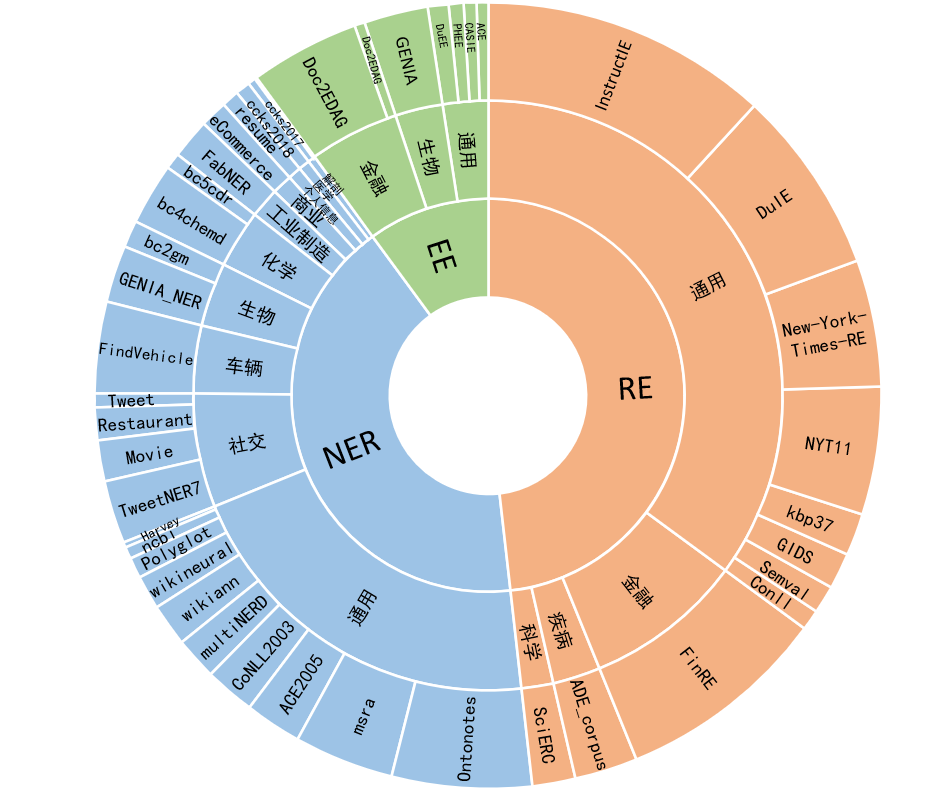
El 54% del corpus de un millón de niveles está en chino y el 46% en inglés. El conjunto de datos incluye 12 campos que incluyen finanzas, sociedad, biología, comercio, fabricación industrial, química, vehículos, ciencia, enfermedades y tratamientos médicos, vida personal y seguridad; y generales. Cubre cientos de escenarios
git clone https://github.com/wenge-research/yayi-uie.git
cd yayi-uieconda create --name uie python=3.8
conda activate uiepip install -r requirements.txt No se recomienda que las versiones torch y transformers sean inferiores a las versiones recomendadas.
El modelo ha sido de código abierto en nuestro repositorio de modelos de Huggingface y puede descargarlo y utilizarlo. El siguiente es un código de muestra que simplemente llama YAYI-UIE para la inferencia de tareas posteriores. Se puede ejecutar en una sola GPU como A100/A800. Ocupa aproximadamente 33 GB de memoria de video cuando se usa la inferencia de precisión bf16.
> >> import torch
> >> from transformers import AutoModelForCausalLM , AutoTokenizer
> >> from transformers . generation . utils import GenerationConfig
> >> tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi-uie" , use_fast = False , trust_remote_code = True )
> >> model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi-uie" , device_map = "auto" , torch_dtype = torch . bfloat16 , trust_remote_code = True )
> >> generation_config = GenerationConfig . from_pretrained ( "wenge-research/yayi-uie" )
> >> prompt = "文本:氧化锆陶瓷以其卓越的物理和化学特性在多个行业中发挥着关键作用。这种材料因其高强度、高硬度和优异的耐磨性,广泛应用于医疗器械、切削工具、磨具以及高端珠宝制品。在制造这种高性能陶瓷时,必须遵循严格的制造标准,以确保其最终性能。这些标准涵盖了从原材料选择到成品加工的全过程,保障产品的一致性和可靠性。氧化锆的制造过程通常包括粉末合成、成型、烧结和后处理等步骤。原材料通常是高纯度的氧化锆粉末,通过精确控制的烧结工艺,这些粉末被转化成具有特定微观结构的坚硬陶瓷。这种独特的微观结构赋予氧化锆陶瓷其显著的抗断裂韧性和耐腐蚀性。此外,氧化锆陶瓷的热膨胀系数与铁类似,使其在高温应用中展现出良好的热稳定性。因此,氧化锆陶瓷不仅在工业领域,也在日常生活中的应用日益增多,成为现代材料科学中的一个重要分支。 n抽取文本中可能存在的实体,并以json{制造品名称/制造过程/制造材料/工艺参数/应用/生物医学/工程特性:[实体]}格式输出。"
> >> # "<reserved_13>" is a reserved token for human, "<reserved_14>" is a reserved token for assistant
>> > prompt = "<reserved_13>" + prompt + "<reserved_14>"
> >> inputs = tokenizer ( prompt , return_tensors = "pt" ). to ( model . device )
> >> response = model . generate ( ** inputs , max_new_tokens = 512 , temperature = 0 )
> >> print ( tokenizer . decode ( response [ 0 ], skip_special_tokens = True ))Nota:
文本:xx
【实体抽取】抽取文本中可能存在的实体,并以json{人物/机构/地点:[实体]}格式输出。
文本:xx
【关系抽取】已知关系列表是[注资,拥有,纠纷,自己,增持,重组,买资,签约,持股,交易]。根据关系列表抽取关系三元组,按照json[{'relation':'', 'head':'', 'tail':''}, ]的格式输出。
文本:xx
抽取文本中可能存在的关系,并以json[{'关系':'会见/出席', '头实体':'', '尾实体':''}, ]格式输出。
文本:xx
已知论元角色列表是[时间,地点,会见主体,会见对象],请根据论元角色列表从给定的输入中抽取可能的论元,以json{角色:论元}格式输出。
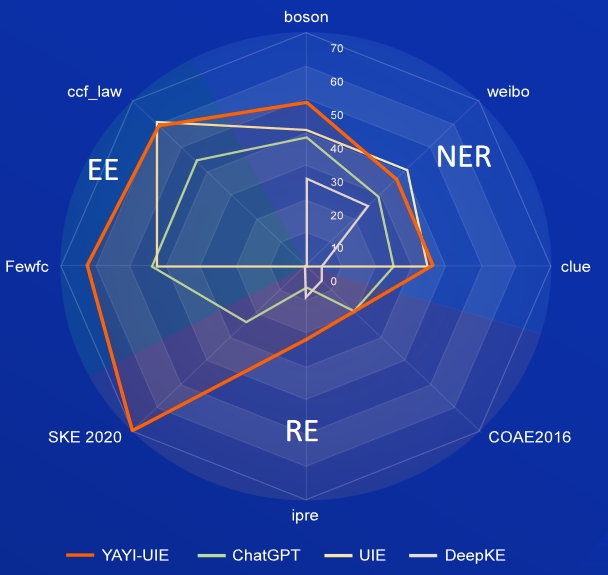
La IA, la literatura, la música, la política y la ciencia son conjuntos de datos en inglés, y bosón, pista y weibo son conjuntos de datos chinos.
| Modelo | AI | Literatura | Música | Política | Ciencia | promedio ingles | bosón | clave | promedio chino | |
|---|---|---|---|---|---|---|---|---|---|---|
| davinci | 2,97 | 9,87 | 13.83 | 18.42 | 10.04 | 11.03 | - | - | - | 31.09 |
| ChatGPT 3.5 | 54.4 | 54.07 | 61.24 | 59.12 | 63 | 58,37 | 38.53 | 25.44 | 29.3 | |
| UEI | 31.14 | 38,97 | 33,91 | 46,28 | 41,56 | 38.37 | 40,64 | 34,91 | 40,79 | 38,78 |
| USM | 28.18 | 56 | 44,93 | 36.1 | 44.09 | 41,86 | - | - | - | - |
| InstruirUIE | 49 | 47.21 | 53.16 | 48.15 | 49.3 | 49,36 | - | - | - | - |
| SaberLM | 13.76 | 20.18 | 14,78 | 33,86 | 9.19 | 18.35 | 25,96 | 4.44 | 25.2 | 18.53 |
| YAYI-UIE | 52,4 | 45,99 | 51.2 | 51,82 | 50,53 | 50,39 | 49,25 | 36,46 | 36,78 | 40,83 |
FewRe, Wiki-ZSL son conjuntos de datos en inglés, SKE 2020, COAE2016, IPRE son conjuntos de datos en chino
| Modelo | PocosRel | Wiki-ZSL | promedio ingles | SEK 2020 | COAE2016 | IPRE | promedio chino |
|---|---|---|---|---|---|---|---|
| ChatGPT 3.5 | 9,96 | 13.14 | 11,55 24,47 | 19.31 | 6.73 | 16,84 | |
| ZETT(T5-pequeño) | 30.53 | 31,74 | 31.14 | - | - | - | - |
| ZETT(base T5) | 33,71 | 31.17 | 32,44 | - | - | - | - |
| InstruirUIE | 39,55 | 35.2 | 37,38 | - | - | - | - |
| SaberLM | 17.46 | 15.33 | 16.40 | 0,4 | 6.56 | 9,75 | 5.57 |
| YAYI-UIE | 36.09 | 41.07 | 38,58 | 70,8 | 19,97 | 22,97 | 37,91 |
noticias sobre productos básicos es el conjunto de datos en inglés, FewFC, ccf_law es el conjunto de datos en chino
EET (identificación del tipo de evento)
| Modelo | noticias sobre productos básicos | pocos fc | ley_ccf | promedio chino |
|---|---|---|---|---|
| ChatGPT 3.5 | 1.41 | 16.15 | 0 | 8.08 |
| UEI | - | 50.23 | 2.16 | 26.20 |
| InstruirUIE | 23.26 | - | - | - |
| YAYI-UIE | 12.45 | 81,28 | 12,87 | 47.08 |
EEA (extracción de argumentos de eventos)
| Modelo | noticias sobre productos básicos | pocos fc | ley_ccf | promedio chino |
|---|---|---|---|---|
| ChatGPT 3.5 | 8.6 | 44.4 | 44,57 | 44,49 |
| UEI | - | 43.02 | 60,85 | 51,94 |
| InstruirUIE | 21,78 | - | - | - |
| YAYI-UIE | 19,74 | 63.06 | 59,42 | 61.24 |
El modelo SFT entrenado en base a datos actuales y modelos básicos todavía tiene los siguientes problemas en términos de efectividad:
Con base en las limitaciones del modelo anterior, exigimos a los desarrolladores que utilicen únicamente nuestro código fuente abierto, datos, modelos y derivados posteriores generados por este proyecto con fines de investigación y no con fines comerciales u otros usos que causen daño a la sociedad. Tenga cuidado al identificar y utilizar el contenido generado por Yayi Big Model y no difundir el contenido dañino generado en Internet. Si se produjera alguna consecuencia adversa, el comunicador será responsable. Este proyecto solo se puede utilizar con fines de investigación y el desarrollador del proyecto no es responsable de ningún daño o pérdida causado por el uso de este proyecto (incluidos, entre otros, datos, modelos, códigos, etc.). Consulte el descargo de responsabilidad para obtener más detalles.
El código y los datos de este proyecto son de código abierto de acuerdo con el protocolo Apache-2.0. Cuando la comunidad utilice el modelo YAYI UIE o sus derivados, siga el acuerdo comunitario y el acuerdo comercial de Baichuan2.
Si utiliza nuestro modelo en su trabajo, puede citar nuestro artículo:
@article{YAYI-UIE,
author = {Xinglin Xiao, Yijie Wang, Nan Xu, Yuqi Wang, Hanxuan Yang, Minzheng Wang, Yin Luo, Lei Wang, Wenji Mao, Dajun Zeng}},
title = {YAYI-UIE: A Chat-Enhanced Instruction Tuning Framework for Universal Information Extraction},
journal = {arXiv preprint arXiv:2312.15548},
url = {https://arxiv.org/abs/2312.15548},
year = {2023}
}


