muse rpc
1.0.0
Introducción : ¡Un marco RPC liviano basado en Connect UDP, un protocolo de red personalizado (protocolo de respuesta de solicitud simple) y un modelo de red Reactor (un bucle por subproceso + grupo de subprocesos)!
C++ 17千级访问en un único reactor esclavo y cuatro subprocesos de trabajo!内网穿透en el caso de IP no públicas.留言mensaje.Uso actual :
# 需要提前安装zlib库
# 本人开发环境 GCC 11.3 CMake 3.25 clion ubuntu 22.04
git clone [email protected]:sorise/muse-rpc.git
cd muse-rpc
cmake -S . -B build
cmake --build
cd build
./muse #启动Diagrama de arquitectura :
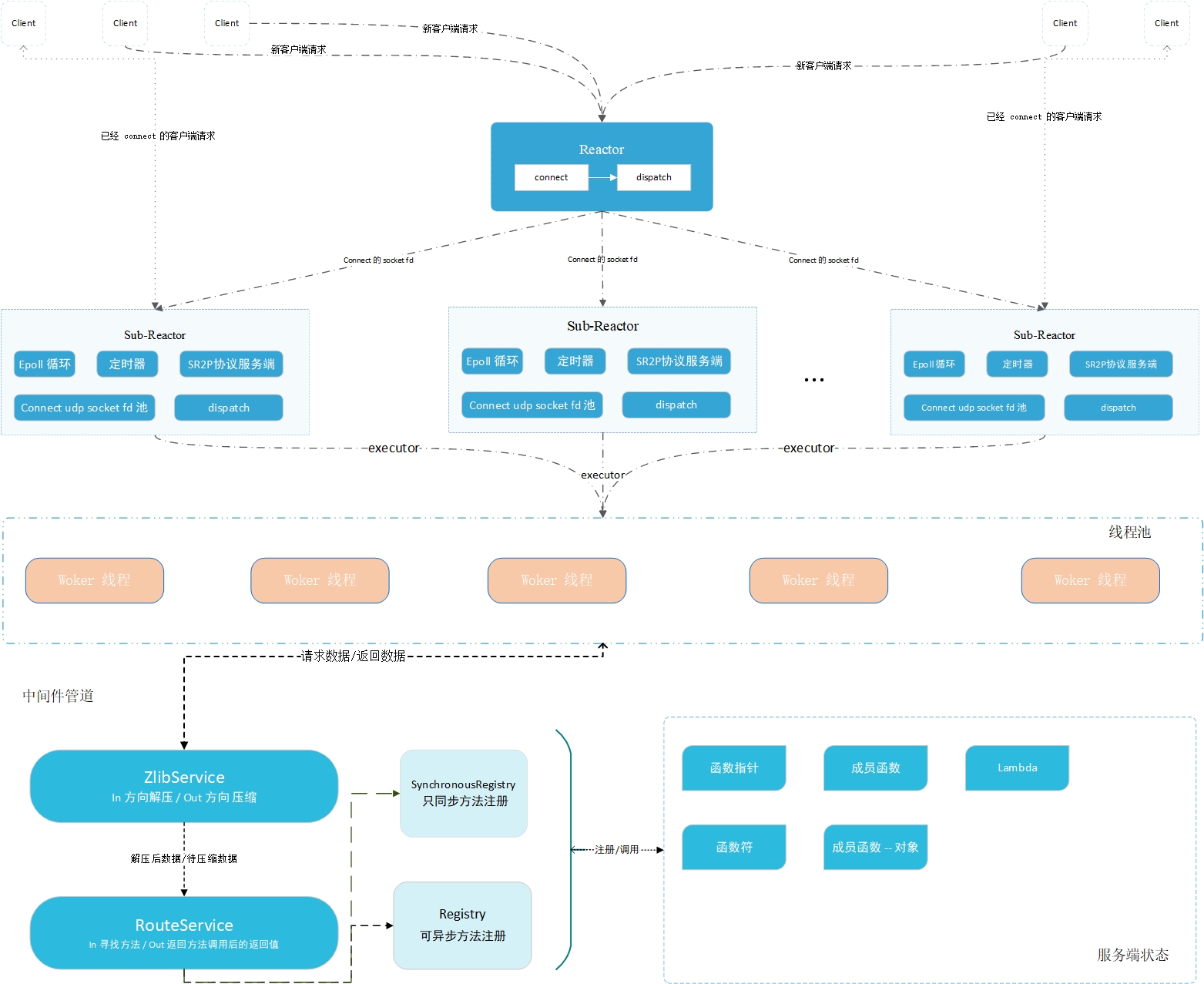
El contenido de la configuración básica es el siguiente.
int main () {
// 启动配置
// 4 设置 线程池最小线程数
// 4 设置 线程池最大线程数
// 4096 线程池任务缓存队列长度
// 3000ms; 动态线程空闲时间 3 秒
// 日志目录
// 是否将日志打印到控制台
muse::rpc::Disposition::Server_Configure ( 4 , 4 , 4096 , 3000ms, " /home/remix/log " , true );
//绑定方法的例子
Normal normal ( 10 , " remix " ); //用户自定义类
// 同步,意味着这个方法一次只能由一个线程执行,不能多个线程同时执行这个方法
muse_bind_sync ( " normal " , &Normal::addValue, & normal ); //绑定成员函数
muse_bind_async ( " test_fun1 " , test_fun1); // test_fun1、test_fun2 是函数指针
muse_bind_async ( " test_fun2 " , test_fun2);
// 开一个线程启动反应堆,等待请求
// 绑定端口 15000, 启动两个从反应堆,每个反应堆最多维持 1500虚链接
// ReactorRuntimeThread::Asynchronous 指定主反应堆新开一个线程运行,而不是阻塞当前线程
Reactor reactor ( 15000 , 2 , 1500 , ReactorRuntimeThread::Asynchronous);
try {
//开始运行
reactor. start ();
} catch ( const ReactorException &ex){
SPDLOG_ERROR ( " Main-Reactor start failed! " );
}
/*
* 当前线程的其他任务
* */
//程序结束
spdlog::default_logger ()-> flush (); //刷新日志
}Después del inicio:

Utilice las macros muse_bind_sync y muse_bind_async . El primero llama a SynchronousRegistry y el segundo llama a Registry. El prototipo es el siguiente.
# include < iostream >
# include " rpc/rpc.hpp "
using namespace muse ::rpc ;
using namespace muse ::pool ;
using namespace std ::chrono_literals ;
//绑定方法的例子
Normal normal ( 10 , " remix " );
// 绑定类的成员函数、使用 只同步方法 绑定
muse_bind_sync ( " normal " , &Normal::addValue, & normal );
// 绑定函数指针
muse_bind_async ( " test_fun1 " , test_fun1);
// 绑定 lambda 表达式
muse_bind_async ( " lambda test " , []( int val)->int{
printf ( " why call me n " );
return 10 + val;
});Los métodos de registro en el lado del servidor requieren el uso de objetos Registro y SynchronousRegistry.
Explicación de SynchronousRegistry: el valor es un campo utilizado para registrar cuántos clientes han solicitado el método addValue. Si 1000 clientes han solicitado addValue y están registrados mediante el Registro, el valor del valor puede no ser 1000 porque el acceso al valor no es seguro para subprocesos. registrado usando SynchronousRegistry, debe ser 1000.
class Counter {
public:
Counter ():value( 0 ){}
void addValue (){
this -> value ++;
}
private:
long value;
};Método de registro : las definiciones de las dos macros son las siguientes
# define muse_bind_async (...)
Singleton<Registry>()-> Bind (__VA_ARGS__);
//同步方法,一次只能一个线程执行此方法
# define muse_bind_sync (...)
Singleton<SynchronousRegistry>()-> Bind (__VA_ARGS__);El cliente utiliza el objeto Cliente, que devolverá un objeto Resultado <R> , y el método isOK indicará si la devolución fue exitosa. Si se devuelve falso, su miembro protocoloReason indicará si hay una anomalía en la red y el miembro de respuesta indicará si se trata de una solicitud rpc y un error de respuesta.
# include " rpc/rpc.hpp "
# include " rpc/client/client.hpp "
using namespace muse ::rpc ;
using namespace muse ::timer ;
using namespace std ::chrono_literals ;
int main{
// //启动客户端配置
muse::rpc::Disposition::Client_Configure ();
// MemoryPoolSingleton 返回一个 std::shared_ptr<std::pmr::synchronized_pool_resource>
//你可以自己定一个内存池
//传入 服务器地址和服务端端口号、一个C++ 17 标准内存池
Client remix ( " 127.0.0.1 " , 15000 , MemoryPoolSingleton ());
//调用远程方法
Outcome<std::vector< double >> result = remix. call <std::vector< double >>( " test_fun2 " ,scores);
std::cout << result. value . size () << std::endl;
//调用 无参无返回值方法
Outcome< void > result =remix. call < void >( " normal " );
if (result. isOK ()){
std::printf ( " success n " );
} else {
std::printf ( " failed n " );
}
//调用
auto ri = remix. call < int >( " test_fun1 " , 590 );
std::cout << ri. value << std::endl; // 600
};
Manejo de errores: en circunstancias normales, solo debe prestar atención a si el método isOk es verdadero. Si necesita conocer los detalles del error, puede utilizar los dos objetos de enumeración FailureReason y RpcFailureReason para señalar errores de red. y errores de solicitud RPC respectivamente.
auto resp = remix.call< int >( " test_fun1 " , 590 );
if (resp.isOK()){
//调用成功
std::cout << " request success n " << std::endl; // 600
std::cout << ri. value << std::endl; // 600
} else {
//调用失败
if (resp. protocolReason == FailureReason::OK){
//错误原因是RPC错误
std::printf ( " rpc error n " );
std::cout << resp. response . getReason () << std::endl;
//返回 int 值对应 枚举 RpcFailureReason
} else {
//错误原因是网络通信过程中的错误
std::printf ( " internet error n " );
std::cout << ( short )resp. protocolReason << std::endl; //错误原因
}
}
// resp.protocolReason() 返回 枚举FailureReason
enum class FailureReason : short {
OK, //没有失败
TheServerResourcesExhausted, //服务器资源耗尽,请勿链接
NetworkTimeout, //网络连接超时
TheRunningLogicOfTheServerIncorrect, //服务器运行逻辑错误,返回的报文并非所需
};
// resp.response.getReason() 返回值 是 int
enum class RpcFailureReason : int {
Success = 0 , // 成功
ParameterError = 1 , // 参数错误,
MethodNotExist = 2 , // 指定方法不存在
ClientInnerException = 3 , // 客户端内部异常,请求还没有到服务器
ServerInnerException = 4 , // 服务器内部异常,请求到服务器了,但是处理过程有异常
MethodExecutionError = 5 , // 方法执行错误
UnexpectedReturnValue = 6 , //返回值非预期
};Las solicitudes sin bloqueo significan que solo necesita configurar la tarea de solicitud y registrar una función de devolución de llamada para procesar los resultados de la solicitud. El proceso de envío es manejado por el objeto Transmisor, de modo que el hilo actual no se bloqueará por razones de red. El bloqueo se manejará en función de las devoluciones de llamada y se puede usar para manejar una gran cantidad de solicitudes. Aquí necesitamos un objeto Transmisor y la tarea de envío se configura a través deTransmisorEvent.
Nota : La cantidad de tareas enviadas por un solo transmisor al mismo tiempo debe ser inferior a 100. Si la cantidad de tareas de solicitud enviadas excede 100, es necesario aumentar el tiempo de espera. Puede llamar a la siguiente interfaz para configurar el tiempo de operación.
void test_v (){
//启动客户端配置
muse::rpc::Disposition::Client_Configure ();
Transmitter transmitter ( 14500 );
// transmitter.set_request_timeout(1500); //设置请求阶段的等待超时时间
// transmitter.set_response_timeout(2000); //设置响应阶段的等待超时时间
//测试参数
std::vector< double > score = {
100.526 , 95.84 , 75.86 , 99.515 , 6315.484 , 944.5 , 98.2 , 99898.26 ,
9645.54 , 484.1456 , 8974.4654 , 4894.156 , 89 , 12 , 0.56 , 95.56 , 41
};
std::string name {
" asdasd54986198456h487s1as8d7as5d1w877y98j34512g98ad "
" sf3488as31c98aasdasd54986198sdasdasd456h487s1as8d7a "
" s5d1w877y98j34512g98ad "
};
for ( int i = 0 ; i < 1000 ; ++i) {
TransmitterEvent event ( " 127.0.0.1 " , 15000 ); //指定远程IP 、Port
event. call < int >( " read_str " , name,score); //指定方法
event. set_callBack ([](Outcome< int > t){ //设置回调
if (t. isOK ()){
printf ( " OK lambda %d n " , t. value );
} else {
printf ( " fail lambda n " );
}
});
transmitter. send ( std::move (event));
}
//异步启动发射器,将会新开一个线程持续发送
transmitter. start (TransmitterThreadType::Asynchronous);
//停止发射器,这是个阻塞方法,如果发送器还有任务没有处理完,将会等待
transmitter. stop ();
//如果想直接停止可以使用 transmitter.stop_immediately()方法
}Admite la configuración de la cantidad de subprocesos principales, la cantidad máxima de subprocesos, la longitud de la cola de caché de tareas y el tiempo de inactividad de subprocesos dinámicos.
ThreadPoolSetting::MinThreadCount = 4 ; //设置 核心线程数
ThreadPoolSetting::MaxThreadCount = 4 ; //设置 核心线程数
ThreadPoolSetting::TaskQueueLength = 4096 ; //设置 任务缓存队列长度
ThreadPoolSetting::DynamicThreadVacantMillisecond = 3000ms; //动态线程空闲时间Introducción : El Protocolo de respuesta de solicitud simple (protocolo SR2P) es un protocolo de dos fases especialmente personalizado para RPC. Se divide en dos etapas: solicitud y respuesta sin establecer un enlace.
Los campos del protocolo son los siguientes: el encabezado del protocolo es de 26 bytes, el orden de los bytes del campo es big endian y la parte de datos es little endian. Debido a las limitaciones de MTU, el MTU estándar de la red es 576 y la parte de datos es hasta 522. bytes. Más Consulte Protocol.pdf.
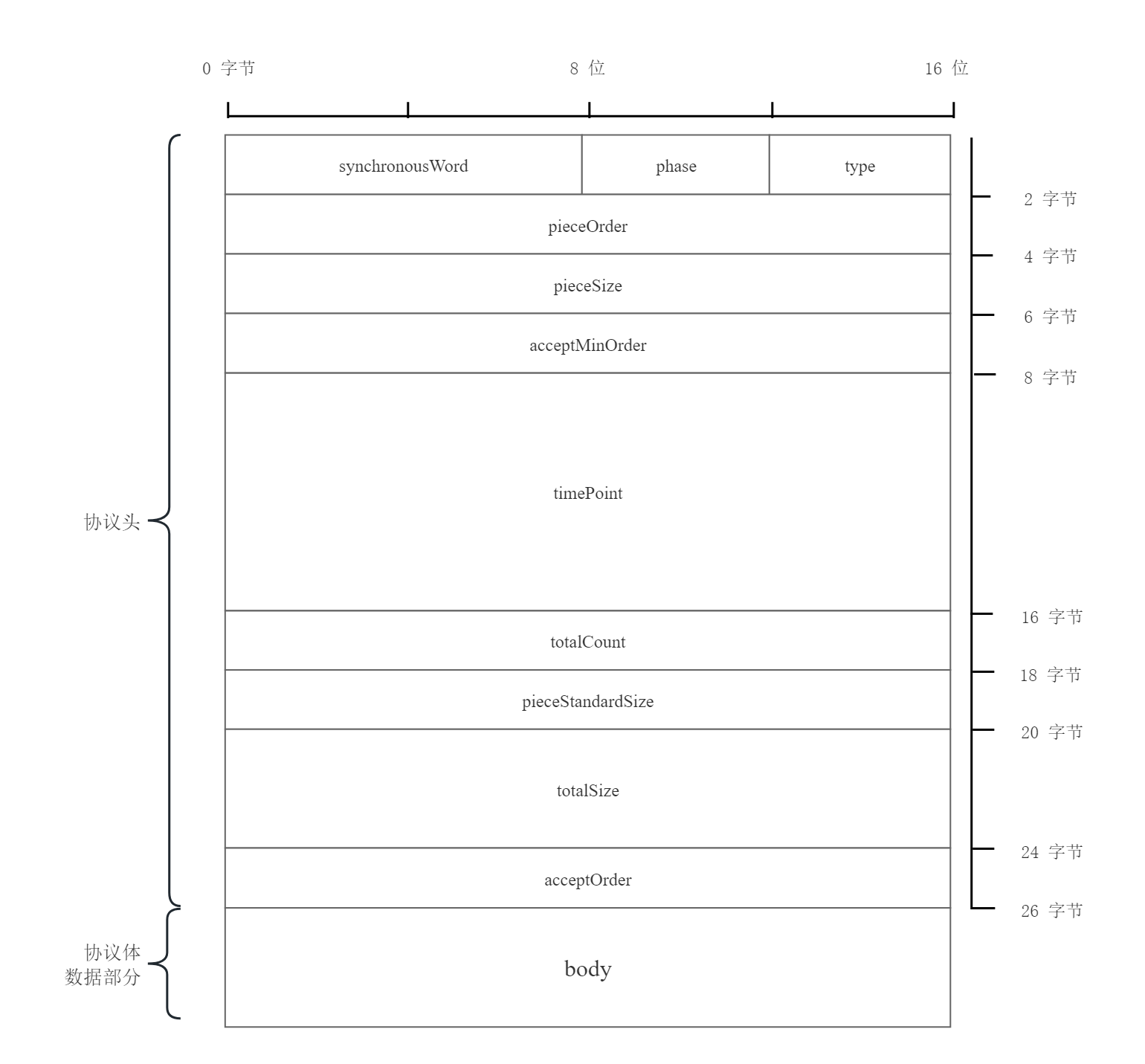
11110000 , un byte.El protocolo SR2P determinará cuántos datagramas se generan cada vez en función de la cantidad de datos generados. A continuación se toman 2 datagramas a la vez como ejemplo del diagrama de flujo de solicitudes en circunstancias básicamente normales.
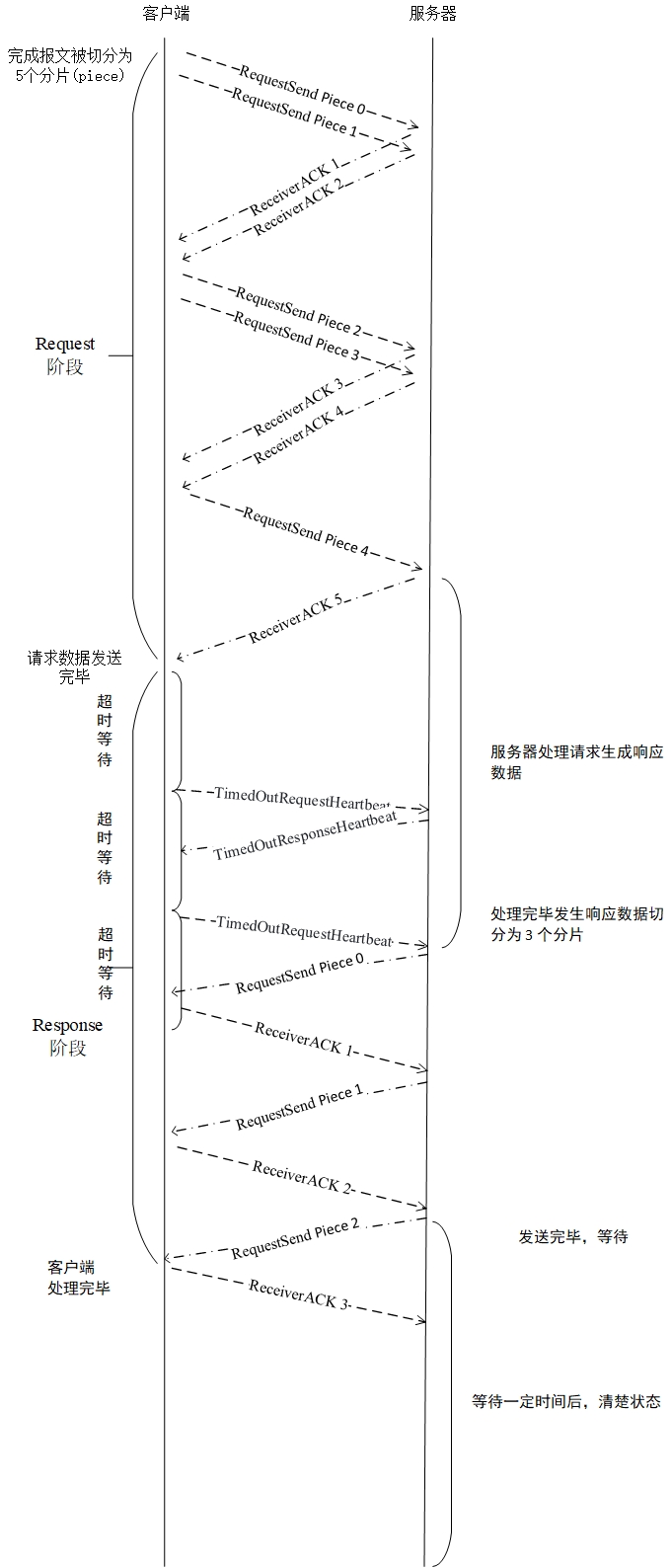
Para obtener detalles sobre el proceso de manejo de otras situaciones, consulte el documento Protocol.pdf.


