Stable Diffusion fue posible gracias a una colaboración con Stability AI y Runway y se basa en nuestro trabajo anterior:
Síntesis de imágenes de alta resolución con modelos de difusión latente
Robin Rombach*, Andreas Blattmann*, Dominik Lorenz, Patrick Esser, Björn Ommer
CVPR '22 Oral | GitHub | arXiv | página del proyecto
 La difusión estable es un modelo de difusión latente de texto a imagen. Gracias a una generosa donación informática de Stability AI y al apoyo de LAION, pudimos entrenar un modelo de difusión latente en imágenes de 512x512 de un subconjunto de la base de datos LAION-5B. Similar a Imagen de Google, este modelo utiliza un codificador de texto CLIP ViT-L/14 congelado para condicionar el modelo a las indicaciones de texto. Con su codificador de texto 860M UNet y 123M, el modelo es relativamente liviano y funciona con una GPU con al menos 10 GB de VRAM. Consulte esta sección a continuación y la tarjeta del modelo.
La difusión estable es un modelo de difusión latente de texto a imagen. Gracias a una generosa donación informática de Stability AI y al apoyo de LAION, pudimos entrenar un modelo de difusión latente en imágenes de 512x512 de un subconjunto de la base de datos LAION-5B. Similar a Imagen de Google, este modelo utiliza un codificador de texto CLIP ViT-L/14 congelado para condicionar el modelo a las indicaciones de texto. Con su codificador de texto 860M UNet y 123M, el modelo es relativamente liviano y funciona con una GPU con al menos 10 GB de VRAM. Consulte esta sección a continuación y la tarjeta del modelo.
Se puede crear y activar un entorno conda adecuado llamado ldm con:
conda env create -f environment.yaml
conda activate ldm
También puede actualizar un entorno de difusión latente existente ejecutando
conda install pytorch torchvision -c pytorch
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
Stable Diffusion v1 se refiere a una configuración específica de la arquitectura del modelo que utiliza un codificador automático de factor de reducción de resolución 8 con un codificador de texto 860M UNet y CLIP ViT-L/14 para el modelo de difusión. El modelo se entrenó previamente en imágenes de 256x256 y luego se ajustó en imágenes de 512x512.
Nota: Stable Diffusion v1 es un modelo general de difusión de texto a imagen y, por lo tanto, refleja los sesgos y (erróneos) conceptos que están presentes en sus datos de entrenamiento. Los detalles sobre el procedimiento y los datos del entrenamiento, así como el uso previsto del modelo, se pueden encontrar en la ficha del modelo correspondiente.
Los pesos están disponibles a través de la organización CompVis en Hugging Face bajo una licencia que contiene restricciones específicas basadas en el uso para evitar el mal uso y daños según lo informado en la tarjeta modelo, pero por lo demás sigue siendo permisiva. Si bien el uso comercial está permitido según los términos de la licencia, no recomendamos utilizar las pesas proporcionadas para servicios o productos sin mecanismos y consideraciones de seguridad adicionales , ya que existen limitaciones y sesgos conocidos de las pesas, y se han realizado investigaciones sobre el uso seguro y ético de las pesas. Los modelos generales de texto a imagen son un esfuerzo continuo. Las pesas son artefactos de investigación y deben tratarse como tales.
La licencia CreativeML OpenRAIL M es una licencia Open RAIL M, adaptada del trabajo que BigScience y la Iniciativa RAIL están llevando a cabo conjuntamente en el área de licencias de IA responsable. Consulte también el artículo sobre la licencia BLOOM Open RAIL en la que se basa nuestra licencia.
Actualmente ofrecemos los siguientes puntos de control:
sd-v1-1.ckpt : 237k pasos con una resolución 256x256 en laion2B-en. Pasos de 194k con una resolución de 512x512 en laion de alta resolución (170 millones de ejemplos de LAION-5B con resolución >= 1024x1024 ).sd-v1-2.ckpt : reanudado desde sd-v1-1.ckpt . 515k pasos con una resolución de 512x512 en laion-aesthetics v2 5+ (un subconjunto de laion2B-en con una puntuación estética estimada > 5.0 y, además, filtrada a imágenes con un tamaño original >= 512x512 y una probabilidad estimada de marca de agua < 0.5 . La estimación de la marca de agua proviene de los metadatos de LAION-5B, la puntuación estética se estima utilizando el LAION-Predictor estético V2).sd-v1-3.ckpt : reanudado desde sd-v1-2.ckpt . 195.000 pasos con una resolución de 512x512 en "laion-aesthetics v2 5+" y una eliminación del 10 % del condicionamiento de texto para mejorar el muestreo de orientación sin clasificador.sd-v1-4.ckpt : reanudado desde sd-v1-2.ckpt . 225.000 pasos con una resolución de 512x512 en "laion-aesthetics v2 5+" y una eliminación del 10 % del condicionamiento de texto para mejorar el muestreo de orientación sin clasificador. Las evaluaciones con diferentes escalas de orientación sin clasificador (1,5, 2,0, 3,0, 4,0, 5,0, 6,0, 7,0, 8,0) y 50 pasos de muestreo PLMS muestran las mejoras relativas de los puntos de control: 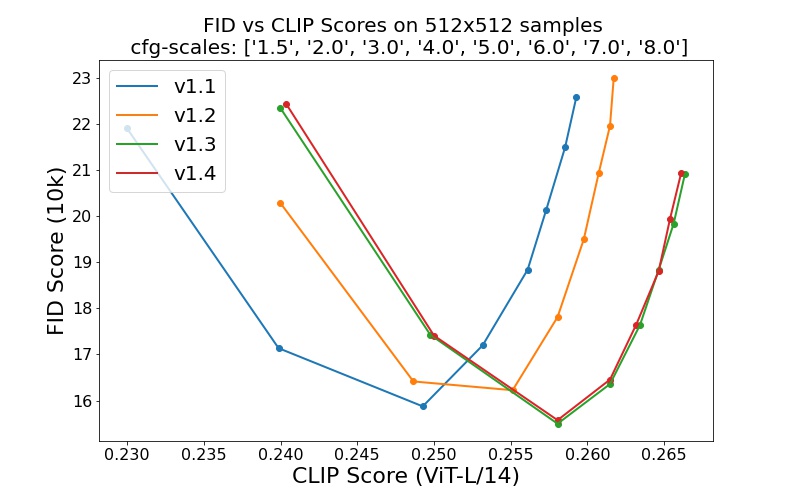


La difusión estable es un modelo de difusión latente condicionado a las incrustaciones de texto (no agrupadas) de un codificador de texto CLIP ViT-L/14. Proporcionamos un guión de referencia para el muestreo, pero también existe una integración de difusores, que esperamos ver un desarrollo comunitario más activo.
Proporcionamos un guión de muestreo de referencia, que incorpora
Después de obtener los pesos stable-diffusion-v1-*-original , vincúlelos
mkdir -p models/ldm/stable-diffusion-v1/
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt
y muestra con
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
De forma predeterminada, esto utiliza una escala de guía de --scale 7.5 , la implementación de Katherine Crowson del muestreador PLMS, y genera imágenes de tamaño 512x512 (en el que fue entrenado) en 50 pasos. Todos los argumentos admitidos se enumeran a continuación (escriba python scripts/txt2img.py --help ).
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
Nota: La configuración de inferencia para todas las versiones v1 está diseñada para usarse con puntos de control solo de EMA. Por esta razón, use_ema=False está configurado en la configuración; de lo contrario, el código intentará cambiar de pesos que no son EMA a pesos EMA. Si desea examinar el efecto de EMA versus no EMA, proporcionamos puntos de control "completos" que contienen ambos tipos de ponderaciones. Para estos, use_ema=False cargará y utilizará los pesos que no son EMA.
Una forma sencilla de descargar y probar Stable Diffusion es utilizando la biblioteca de difusores:
# make sure you're logged in with `huggingface-cli login`
from torch import autocast
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained (
"CompVis/stable-diffusion-v1-4" ,
use_auth_token = True
). to ( "cuda" )
prompt = "a photo of an astronaut riding a horse on mars"
with autocast ( "cuda" ):
image = pipe ( prompt )[ "sample" ][ 0 ]
image . save ( "astronaut_rides_horse.png" )Al utilizar un mecanismo de eliminación de ruido por difusión propuesto por primera vez por SDEdit, el modelo se puede utilizar para diferentes tareas, como la traducción de imagen a imagen guiada por texto y la ampliación de escala. De manera similar al script de muestreo txt2img, proporcionamos un script para realizar modificaciones de imágenes con Stable Diffusion.
A continuación se describe un ejemplo en el que un boceto realizado en Pinta se convierte en una obra de arte detallada.
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img <path-to-img.jpg> --strength 0.8
Aquí, la fuerza es un valor entre 0,0 y 1,0, que controla la cantidad de ruido que se agrega a la imagen de entrada. Los valores cercanos a 1.0 permiten muchas variaciones pero también producirán imágenes que no son semánticamente consistentes con la entrada. Vea el siguiente ejemplo.
Aporte

Salidas


Este procedimiento también se puede utilizar, por ejemplo, para mejorar muestras del modelo base.
Nuestra base de código para los modelos de difusión se basa en gran medida en la base de código ADM de OpenAI y https://github.com/lucidrains/denoising-diffusion-pytorch. ¡Gracias por el código abierto!
La implementación del codificador transformador proviene de transformadores x de lucidrains.
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


