ACM MM'18 Mejor artículo estudiantil
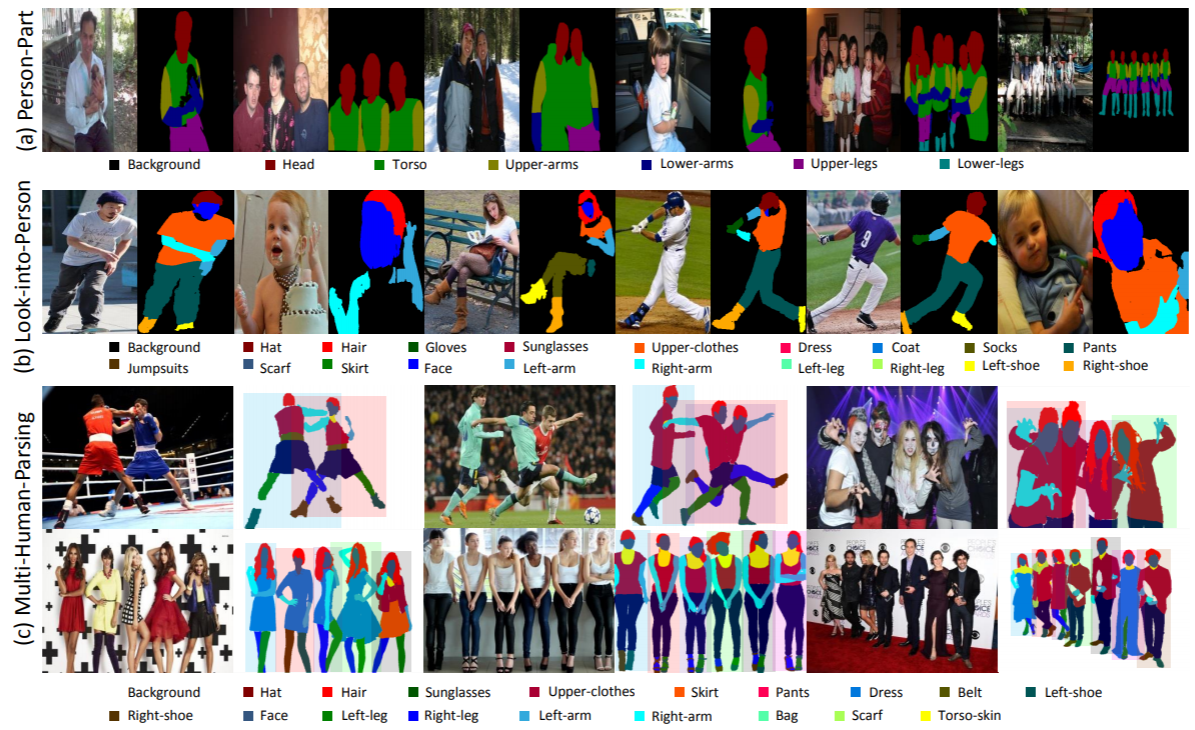
El proyecto Multi-Human Parsing del Grupo Learning and Vision (LV) de la Universidad Nacional de Singapur (NUS) se propone ampliar las fronteras de la comprensión visual detallada de los humanos en escenas de multitudes.
El análisis multihumano es significativamente diferente de las tareas tradicionales de reconocimiento de objetos bien definidos, como la detección de objetos, que solo proporciona predicciones de nivel aproximado de la ubicación de los objetos (cuadros delimitadores); segmentación de instancias, que solo predice la máscara a nivel de instancia sin ninguna información detallada sobre partes del cuerpo y categorías de moda; análisis humano, que opera en la predicción de píxeles a nivel de categoría sin diferenciar diferentes identidades.
En un escenario del mundo real, el escenario de múltiples personas con interacciones es más realista y habitual. Por lo tanto, es muy deseable una tarea, conjuntos de datos correspondientes y métodos de referencia para considerar tanto la información semántica detallada de cada persona individual como las relaciones e interacciones de todo el grupo de personas.
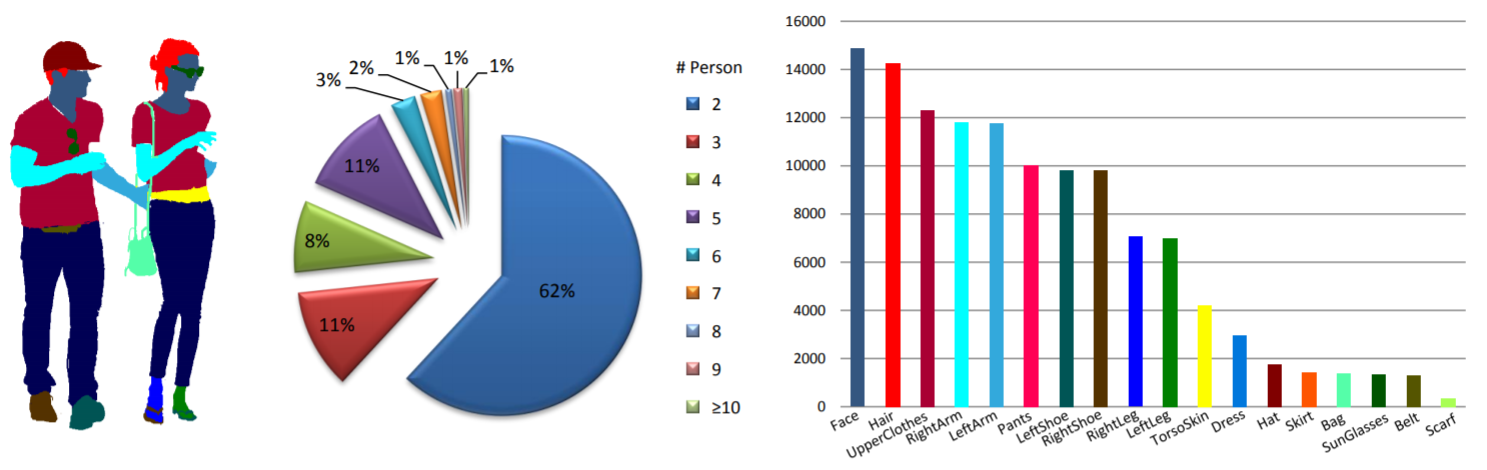
Estadísticas: el conjunto de datos de MHP v1.0 contiene 4980 imágenes, cada una con al menos dos personas (el promedio es 3). Elegimos aleatoriamente 980 imágenes y sus correspondientes anotaciones como conjunto de prueba. El resto forma un conjunto de entrenamiento de 3000 imágenes y un conjunto de validación de 1000 imágenes. Para cada caso, se definen y anotan 18 categorías semánticas, excepto la categoría "fondo", es decir, "sombrero", "pelo", "gafas de sol", "ropa superior", "falda", "pantalones", "vestido", " cinturón”, “zapato izquierdo”, “zapato derecho”, “rostro”, “pierna izquierda”, “pierna derecha”, “brazo izquierdo”, “brazo derecho”, “bolso”, “bufanda” y “piel de torso”. Cada instancia tiene un conjunto completo de anotaciones siempre que la categoría correspondiente aparece en la imagen actual.
Noticias de WeChat.
Descargar: el conjunto de datos MHP v1.0 está disponible en Google Drive y Baidu Drive (contraseña: cmtp).
Consulte nuestro documento MHP v1.0 (enviado a IJCV) para obtener más detalles.

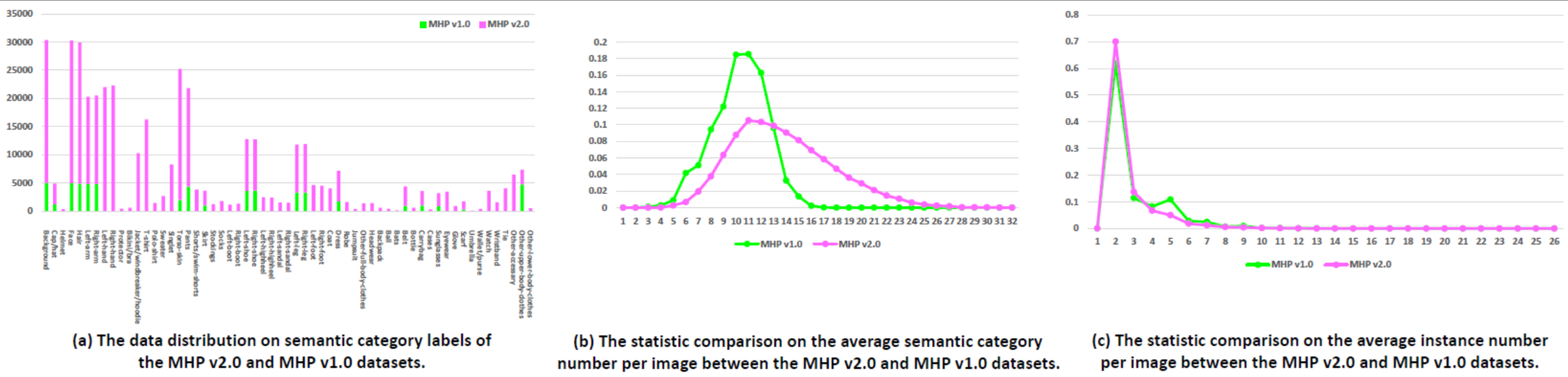

Estadísticas: el conjunto de datos de MHP v2.0 contiene 25.403 imágenes, cada una con al menos dos personas (el promedio es 3). Elegimos aleatoriamente 5000 imágenes y sus correspondientes anotaciones como conjunto de prueba. El resto forma un conjunto de entrenamiento de 15.403 imágenes y un conjunto de validación de 5.000 imágenes. Para cada caso, se definen y anotan 58 categorías semánticas, excepto la categoría "fondo", es decir, "gorra/sombrero", "casco", "cara", "pelo", "brazo izquierdo", "brazo derecho", "mano izquierda", "mano derecha", "protector", "bikini/sujetador", "chaqueta/cortavientos/sudadera con capucha", "camiseta", "polo", "suéter", "camiseta", "torso-piel", "pantalones", "pantalones cortos/shorts de baño", "falda", "medias", "calcetines", "bota izquierda", "bota derecha", "zapato izquierdo", "zapato derecho", "tacón izquierdo", "tacón derecho", "sandalia izquierda", "sandalia derecha", "pierna izquierda", "pierna derecha", "pie izquierdo", "pie derecho", "abrigo", "vestido", "bata", "mono", "otra ropa para el cuerpo completo", "sombreros", "mochila", "pelota", "murciélagos", "cinturón", "botella", "bolsa de transporte", "estuches", "gafas de sol", "gafas", "guante", "bufanda", "paraguas", "cartera/monedero", "reloj", "pulsera", "corbata", "otro-accesorio", "otra-ropa-de-la-parte-superior-del-cuerpo" y "otra-ropa-inferior". -ropa-cuerpo". Cada instancia tiene un conjunto completo de anotaciones siempre que la categoría correspondiente aparece en la imagen actual. Además, poses humanas en 2D con 16 puntos clave densos ("hombro derecho", "codo derecho", "muñeca derecha", "hombro izquierdo", "codo izquierdo", "muñeca izquierda", "muñeca derecha"). cadera", "rodilla derecha", "tobillo derecho", "cadera izquierda", "rodilla izquierda", "tobillo izquierdo", "cabeza", "cuello", "columna vertebral" y "pelvis". El punto clave tiene una bandera que indica si es visible-0/occluded-1/out-of-image-2) y cuadros delimitadores de cabeza e instancia también se proporcionan para facilitar la investigación de estimación de posturas multihumanas.
Descargar: el conjunto de datos MHP v2.0 está disponible en Google Drive y Baidu Drive (contraseña: uxrb).
Consulte nuestro documento MHP v2.0 (ACM MM'18 Best Student Paper) para obtener más detalles.
Análisis multihumano: utilizamos dos métricas centradas en los humanos para la evaluación del análisis multihumano, que se informan inicialmente en nuestro artículo MHP v1.0. Las dos métricas son Precisión promedio basada en la parte (AP p ) (%) y Porcentaje de partes semánticas correctamente analizadas (PCP) (%). Para obtener el código de evaluación, consulte la carpeta "Evaluación" en nuestro repositorio "Multi-Human-Parsing_MHP".
Estimación de pose multihumana: seguido de MPII, utilizamos la medida de evaluación mAP (%).
Hemos organizado el Taller CVPR 2018 sobre comprensión visual de los humanos en escenas de multitudes (VUHCS 2018). Este taller cuenta con la colaboración de NUS, CMU y SYSU. Basado en VUHCS 2017, hemos fortalecido aún más este taller al aumentarlo con 5 pistas de competencia: el análisis humano de una sola persona, el análisis humano de varias personas, la estimación de pose de una sola persona, la estimación de pose de múltiples humanos y la evaluación fina. análisis detallado multihumano.
Envío de resultados y tabla de clasificación.
Noticias de WeChat.
Por favor consulte y considere citar los siguientes artículos:
@article{zhao2018understanding,
title={Understanding Humans in Crowded Scenes: Deep Nested Adversarial Learning and A New Benchmark for Multi-Human Parsing},
author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Zhou, Li and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
journal={arXiv preprint arXiv:1804.03287},
year={2018}
}
@article{li2017towards,
title={Multi-Human Parsing in the Wild},
author={Li, Jianshu and Zhao, Jian and Wei, Yunchao and Lang, Congyan and Li, Yidong and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
journal={arXiv preprint arXiv:1705.07206},
year={2017}
}


