Image to text chrome extension
1.0.0
Una extensión de Chrome que puede reconocer cualquier tipo de texto en su navegador a partir de cualquier vídeo o imagen utilizando el concepto de OCR. OCR es la forma abreviada de reconocimiento óptico de caracteres o cualquier otro texto para buscar palabras en imágenes. Google había lanzado previamente un motor llamado Tesseract OCR, esto significa que Google te proporciona un programa que ya tiene el reconocimiento de texto entrenado, por lo que no tengo que hacer cosas complicadas como entrenar los datos en OCR yo mismo. Pero para ser más precisos, debemos preprocesar la imagen antes de pasarla por Tesseract, ya que Tesseract tiene algunas circunstancias predefinidas que deben seguirse para obtener un resultado preciso. Entonces, para la funcionalidad de nuestra extensión, primero toma una captura de pantalla de la pestaña abierta actualmente, luego recorta la parte deseada usando el lienzo y la ajusta usando la binarización de umbral para que pueda cumplir con los requisitos de OCR para brindar resultados más precisos. Luego envíelo a pytesseract (versión Python de Tesseract) para que pueda convertirlo. Al final, obtenga el texto y descárguelo en formato de archivo .txt. De modo que el usuario puede abrirlo en el Bloc de notas o en cualquier otro editor de texto y comparar y modificar el texto si es necesario.
Muy a menudo encuentro fragmentos de código en YouTube o en cualquier otro sitio web, pero ahora aprecio mucho el esfuerzo que los creadores de tutoriales ponen en sus videos cada vez que encuentro un fragmento de código que no proporciona un enlace para descargarlo o copiarlo. Entonces, para obtener códigos de esos videos, hice este proyecto con la ayuda del complemento tesseract para poder extraer texto de esos videos o imágenes.
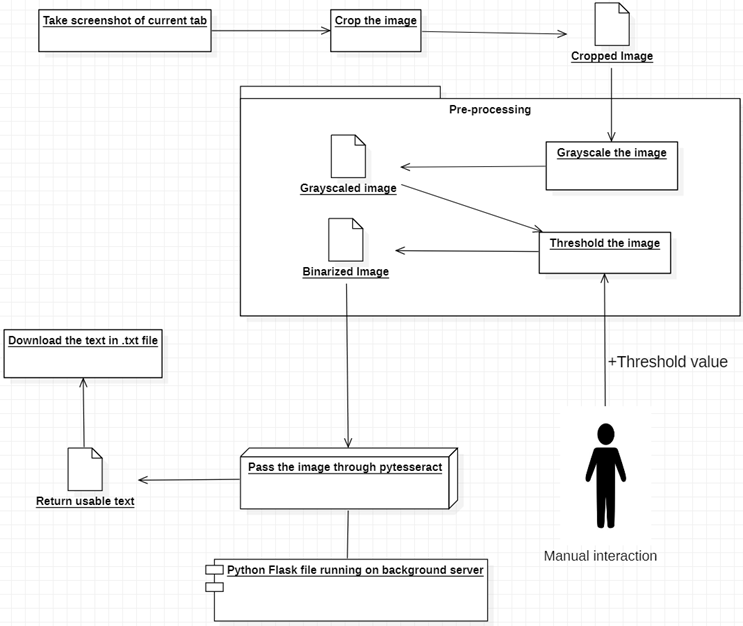
La implementación y demostración de los módulos se pueden encontrar en el ppt.
pip install pytesseract
npm i flask
El archivo jQuery min se adjunta con los archivos, en caso de que desee cambiarlo o utilizar el método cdn, puede cambiarlo.


