baker example page template
1.0.0
Una demostración de cómo crear y publicar páginas con la herramienta de compilación Baker.
Los Angeles Times utiliza Baker para crear las páginas estáticas publicadas en latimes.com/projects. El sistema Times se basa en una versión privada de un repositorio muy parecido a este. Este ejemplo simplificado publica versiones de prueba y producción en depósitos públicos en Amazon S3.
Servidor de prueba local de actualización en vivo
Plantillas HTML con Nunjucks
CSS extendido con Sass
Paquete de JavaScript con Rollup y Babel
Importaciones de datos con quaff
Generación dinámica de páginas basada en entradas estructuradas.
Implementación automática de cada rama en un entorno de prueba en cada evento push a través de GitHub Action
Implementación de botones en el entorno de producción en cada evento release a través de GitHub Action
Mensajes de Slack que transmiten el estado de cada implementación a través de la acción de Github datadesk/notify-slack-on-build
Node.js versión 12, 14 o 16, aunque como mínimo 12.20, 14.14 o 16.0.
Administrador de paquetes de nodo
git
Con una pequeña configuración, puede utilizar esta plantilla para publicar fácilmente una página. Con un poco de personalización, puedes darle el aspecto que quieras. Esta guía le presentará los conceptos básicos.
Creando una nueva página
Explorando el repositorio
Accediendo a los activos
Accediendo a datos
Páginas dinámicas
Despliegue
variables globales
panadero.config.js
El primer paso es hacer clic en el botón "usar esta plantilla" de GitHub para hacer una copia del repositorio usted mismo.
Se le pedirá que proporcione un slug para su proyecto. Una vez hecho esto, habrá un nuevo repositorio disponible en https://github.com/your-username/your-slug .
A continuación, necesitarás clonarlo en tu computadora para trabajar con el código.
Abra su terminal y cd a su carpeta de códigos. Clona el proyecto en tu carpeta. Esto copiará el proyecto en su computadora.
clon de git https://github.com/your-username/your-slug
Si ese comando no funciona para usted, podría deberse a que su computadora estaba configurada de manera diferente y necesita clonar el repositorio usando SSH. Intenta ejecutar esto en tu terminal:
git clone [email protected]:tu-nombre de usuario/tu-slug.git
Una vez que el repositorio haya terminado de descargarse, ingrese a your-slug e instale las dependencias de Node.js.
instalación npm
Una vez que se hayan instalado las dependencias, estará listo para obtener una vista previa del proyecto. Ejecute lo siguiente para iniciar el servidor de prueba.
inicio de npm
Ahora vaya a localhost:3000 en su navegador. Debería ver una página estándar lista para sus personalizaciones.
Una ruta alternativa es crear una nueva página con bluprint, la herramienta de andamiaje de línea de comandos desarrollada por el departamento de gráficos de Reuters.
plano agregar https://github.com/datadesk/baker-example-page-template mkdir mi-nueva-páginacd mi-nueva-página bluprint start panadero-ejemplo-página
Estos son los archivos y carpetas estándar que encontrará cuando clone un nuevo proyecto desde nuestra plantilla de página. Pasará más tiempo trabajando con algunos archivos que con otros, pero es bueno tener una idea general de lo que hacen todos.
La carpeta de datos contiene datos relevantes para el proyecto. Usamos esta carpeta para almacenar la información requerida sobre cada proyecto, como en qué URL debe estar. También puede almacenar una variedad de otros tipos de datos aquí, incluidos .aml , .csv y .json .
El archivo meta.aml contiene información importante sobre la página, como el título, la firma, el slug, la fecha de publicación y otros campos. Completarlo garantiza que su página se muestre correctamente y pueda ser indexada por los motores de búsqueda. Puede encontrar una lista completa de todos los atributos en nuestros materiales de referencia. Puede ampliar esto para incluir tantas o tan pocas opciones como desee.
Esta carpeta que almacena la plantilla base de nuestro sitio y fragmentos de código reutilizables. Cuando estás empezando, es poco probable que cambies algo aquí. En casos de uso más avanzados, es donde puede almacenar código que se reutiliza en varias páginas.
base.htmlEl archivo base.html contiene todo el HTML fundamental que se encuentra en cada página que creamos. El ejemplo aquí es rudimentario por diseño. Probablemente quieras incluir mucho más en una implementación del mundo real.
El espacio de trabajo es un lugar para colocar cualquier cosa relevante para el proyecto que no necesite publicarse en la web. Archivos de IA, fragmentos de código, escritura, etc. Depende de usted.
Se utiliza para almacenar medios y otros activos como imágenes, vídeos, audio, fuentes, etc. Se pueden introducir en la página a través de las etiquetas de plantilla static .
Los archivos JavaScript se almacenan en esta carpeta. El archivo principal de JavaScript se llama app.js , en el que puedes escribir tu código directamente. Los paquetes instalados mediante npm se pueden importar y ejecutar como cualquier otro script de Node.js. Puede crear otros archivos para escribir su código JavaScript en esta carpeta, pero debe asegurarse de que el archivo se inicie desde app.js
Nuestras hojas de estilo están escritas en SASS, un potente lenguaje de hojas de estilo que brinda a los desarrolladores más control sobre CSS. Si no se siente cómodo con SASS, puede escribir CSS simple en las hojas de estilo.
La carpeta de estilos consta de una hoja de estilos ( app.scss ) donde puede agregar todos sus estilos personalizados a su proyecto, aunque a veces es posible que desee crear hojas de estilo adicionales e importarlas a app.scss . Este proyecto de ejemplo solo incluye lo mínimo necesario para simular un sitio simple. Probablemente quieras comenzar con mucho más en una implementación del mundo real.
El archivo baker.config.js es donde colocamos las opciones que Baker usa para servir y construir el proyecto. Ha sido completamente documentado en otra parte de este archivo. Con la excepción de la configuración domain , sólo los usuarios avanzados necesitarán cambiar este archivo.
La plantilla predeterminada para su página. Aquí es donde diseñarás tu página. Utiliza el sistema de plantillas Nujucks para crear HTML.
Estos archivos rastrean las dependencias de Node utilizadas en nuestros proyectos. Cuando ejecute npm install las bibliotecas que agregue se rastrearán automáticamente aquí.
Este es un directorio especial para almacenar archivos que GitHub usa para interactuar con nuestros proyectos y código. El directorio .github/workflows contiene la acción de GitHub que maneja nuestras implementaciones de desarrollo. No es necesario editar nada aquí.
Los almacenes de archivos en el directorio de activos se optimizan y se codifican como parte del proceso de implementación. Para asegurarse de que sus referencias a imágenes y otros archivos estáticos, debe utilizar la etiqueta {% static %} . Eso garantiza que el archivo esté almacenado en caché cuando se publique y que el enlace a la imagen funcione en todos los entornos. Querrás usarlo para todas las fotos y videos.
<figura>
<img src="{% static 'assets/images/baker.jpg' %}" alt="Logotipo de panadero" width=200>
</figura> Se puede acceder a los archivos de datos estructurados almacenados en su carpeta _data mediante etiquetas de plantilla o JavaScript. En esta demostración, se incluyó un archivo llamado example.json para ilustrar lo que es posible. Se admiten otros formatos de archivo como CSV, YAML y AML.
Los archivos en la carpeta _data están disponibles por su nombre dentro de sus plantillas. Entonces, con _data/example.json , puedes escribir algo como:
{% para obj en el ejemplo %}
{{ obj.año }}: {{ obj.trigo }}{% endfor %}Una necesidad común para cualquiera que cree un proyecto en Baker es el acceso a datos sin procesar dentro de un archivo JavaScript. A menudo, estos datos se pasan a un código escrito con d3 o Svelte para dibujar gráficos o crear tablas HTML en la página.
Si los datos a los que accede ya están disponibles en una URL en la que confía que permanecerá activa, esto es fácil. Pero, ¿qué pasa si no lo es y son datos que usted mismo ha preparado?
Es posible acceder a los registros en su carpeta _data. La única advertencia es que el trabajo de convertir este archivo a un estado utilizable es su responsabilidad. Una buena biblioteca para esto es d3-fetch .
Para crear la URL de este archivo de una manera que Baker entienda, utilice este formato:
import {json} de 'd3-fetch';// el primer parámetro debe ser la ruta al archivo// el segundo parámetro *debe* ser “import.meta.url”const url = new URL('../_data /example.json', import.meta.url);// Llámalo inconst data = await json(url); Otro enfoque es imprimir los datos en su plantilla como una etiqueta script . El filtro jsonScript toma la variable que se le pasa, ejecuta JSON.stringify en ella y genera el JSON en HTML dentro de una etiqueta <script> con el ID establecido que usted pasa como parámetro.
{{ ejemplo|jsonScript('datos-ejemplo') }}Una vez que esté implementado, ahora puede recuperar el JSON almacenado en la página por ID en su JavaScript.
// toma el elemento jsonScript creado usando el mismo ID que pasaste en const dataElement = document.getElementById('example-data');// convierte el contenido de ese elemento en JSON// haz lo que necesites hacer con los “datos” !datos constantes = JSON.parse(dataElement.textContent); Si bien se recomienda el método URL, es posible que aún se prefiera este método cuando se intenta evitar solicitudes de red adicionales. También tiene el beneficio adicional de no requerir una biblioteca especial para convertir datos .csv a JSON.
Puede generar una cantidad ilimitada de páginas estáticas alimentando una fuente de datos estructurados a la opción createPages en el archivo baker.config.js . Por ejemplo, este fragmento generará una página para cada registro en el archivo example.json .
exportar predeterminado {
// ... todas las demás opciones anteriores a esta han sido excluidas para dejar claro el punto
createPages: createPages(createPage, data) {// Toma los datos de la carpeta _dataconst pageList = data.example;// Recorre los registrosfor (const d of pageList) { // Establece la plantilla base que se utilizará para cada objeto . Está en la carpeta _layouts const template = 'year-detail.html'; // Establece la URL para la página const url = `${d.year}`; // Establece las variables que se pasarán al contexto de la plantilla const context = { obj: d }; // Utilice la función proporcionada para representar la página createPage(template, url, context);}
},}; Esto podría usarse para crear URL como /baker-example-page-template/1775/ y /baker-example-page-template/1780/] con una sola plantilla.
Antes de poder implementar una página creada por este repositorio, deberá configurar su cuenta de Amazon AWS y agregar un conjunto de credenciales a su cuenta de GitHub.
Primero, deberá crear dos depósitos en el servicio de almacenamiento S3 de Amazon. Uno es para su sitio de preparación. El otro es para su sitio de producción. Para este ejemplo simple, cada uno debe permitir el acceso público y estar configurado para servir un sitio web estático. En un arreglo más sofisticado, como el que presentamos en Los Angeles Times, los depósitos podrían vincularse con nombres de dominio registrados y el sitio de prueba podría protegerse de la vista del público mediante un esquema de autenticación.
Los nombres de esos depósitos deben almacenarse como "secretos" de GitHub accesibles para las Acciones que implementan el sitio. Debes visitar el panel de configuración de tu cuenta u organización. Comience agregando estos dos secretos.
| Nombre | Valor |
|---|---|
BAKER_AWS_S3_STAGING_BUCKET | El nombre de tu grupo de preparación |
BAKER_AWS_S3_STAGING_REGION | La región de S3 donde se creó su depósito provisional |
BAKER_AWS_S3_PRODUCTION_BUCKET | El nombre de su segmento de producción. |
BAKER_AWS_S3_PRODUCTION_REGION | La región de S3 donde se creó su depósito de producción |
A continuación, debe asegurarse de tener un par de claves de AWS que tenga la capacidad de cargar archivos públicos en sus dos depósitos. Los valores también deben agregarse a tus secretos.
| Nombre | Valor |
|---|---|
BAKER_AWS_ACCESS_KEY_ID | La clave de acceso de AWS |
BAKER_AWS_SECRET_ACCESS_KEY | La clave secreta de AWS |
Una acción de GitHub incluida con este repositorio publicará automáticamente una versión provisional para cada rama. Por ejemplo, el código enviado a la rama main predeterminada aparecerá en https://your-staging-bucket-url/your-repo/main/ .
Si creara una nueva rama de git llamada bugfix y enviara su código, pronto vería una nueva versión provisional en https://your-staging-bucket-url/your-repo/bugfix/ .
Antes de publicar su página, debe decidirse por un último párrafo para la URL. Esto establecerá el subdirectorio en su depósito donde se publicará la página. Esta característica permite a The Times publicar numerosas páginas dentro del mismo depósito y cada página administrada por un repositorio diferente.
El primer paso es ingresar el slug de su URL en el archivo de configuración _data/meta.aml .
babosa: tu-página-slug
Nunca es mala idea asegurarse de que no te hayan quitado ya la babosa. Puede hacerlo visitando https://your-production-bucket-url/your-slug/ y asegurándose de que devuelva un error de página no encontrada.
Si desea publicar su página en la raíz de su depósito, puede dejar el slug nulo.
babosa:
Luego confirmas tu cambio en el archivo de configuración y te aseguras de que se envíe a la rama principal de GitHub.
git agregar _data/meta.aml git commit -m “Establecer slug de página” git push origen principal
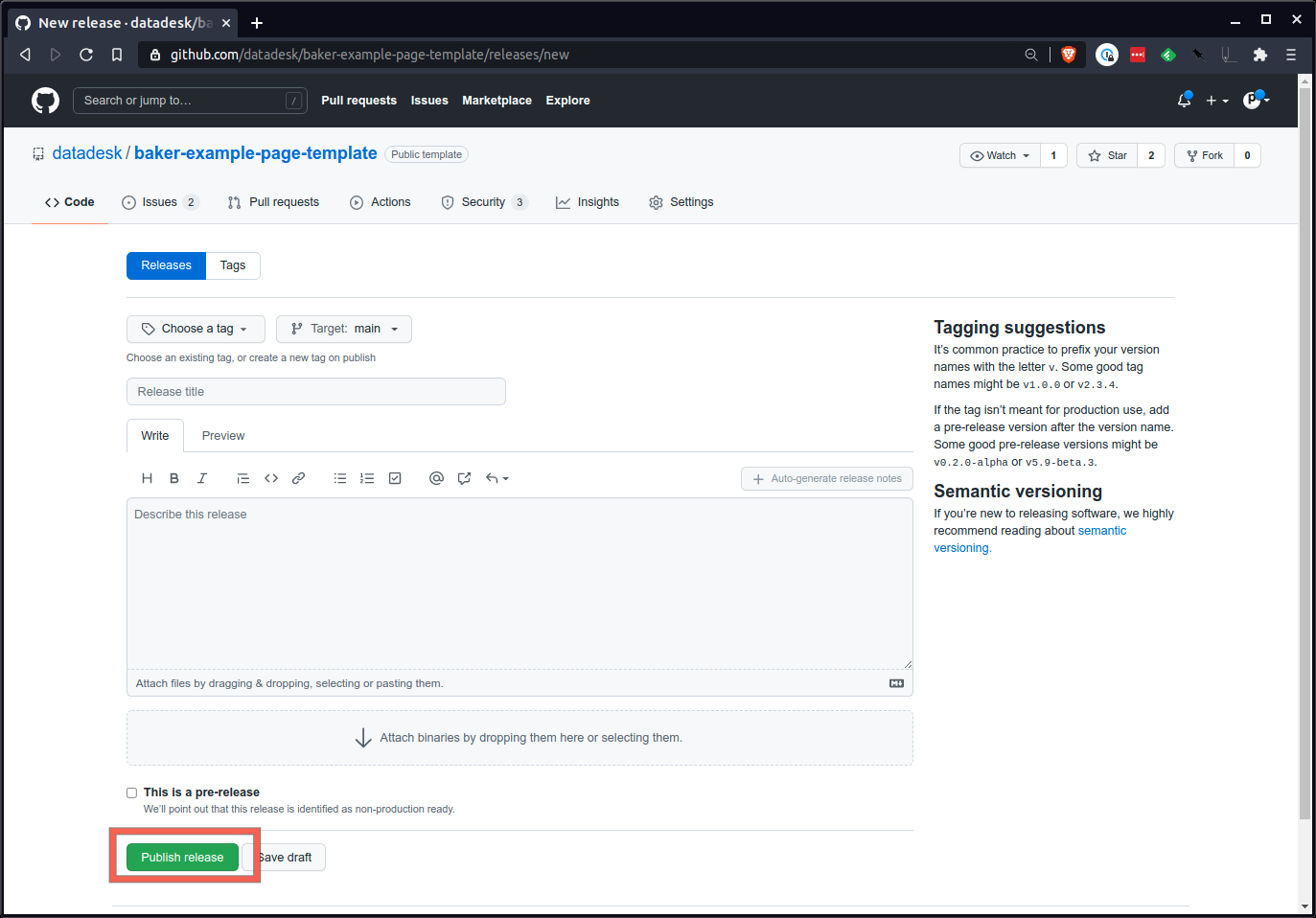
Visite la sección de lanzamientos de la página de su repositorio en GitHub. Puede encontrarlo en la página de inicio del repositorio.
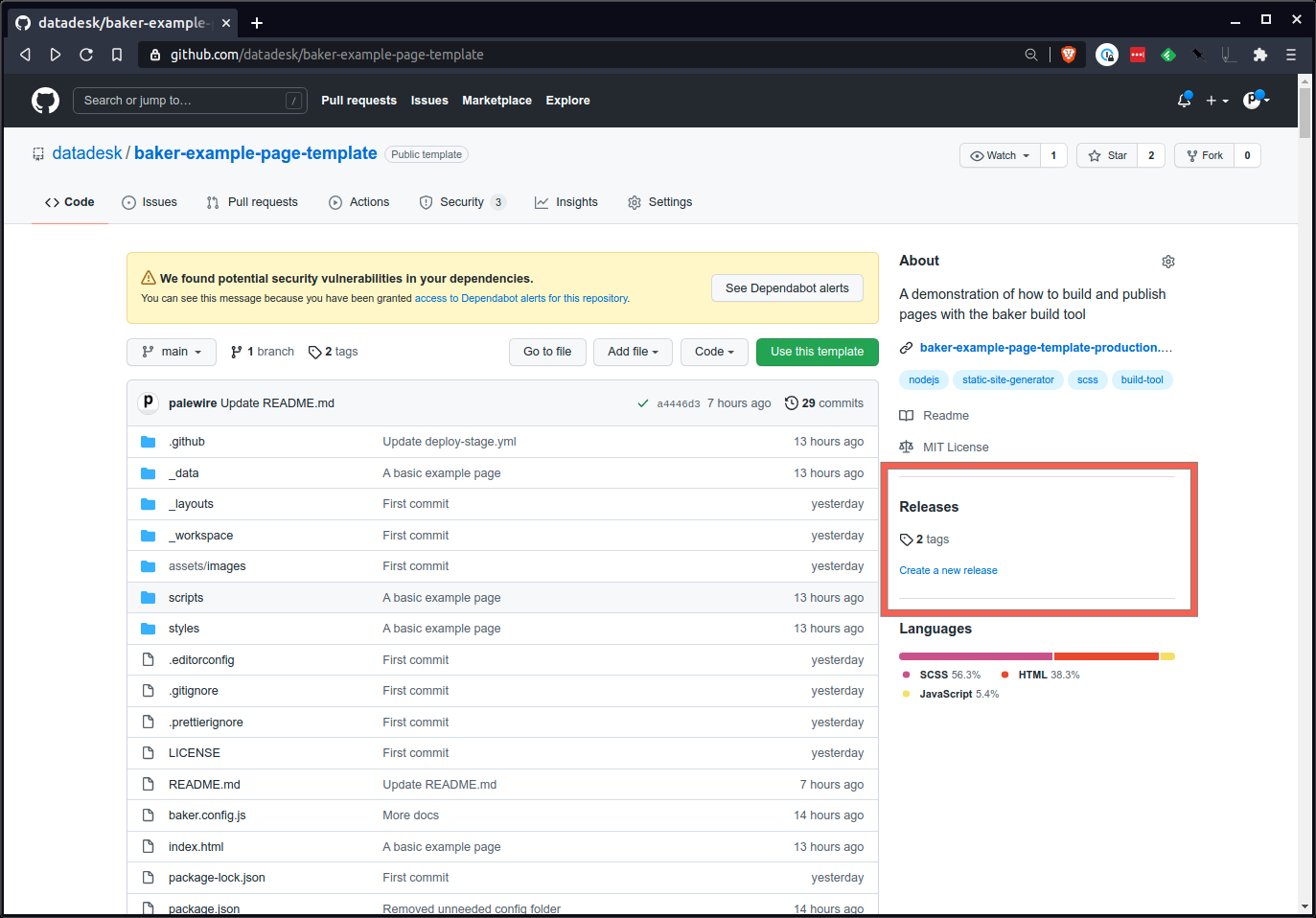
Redactar una nueva versión.
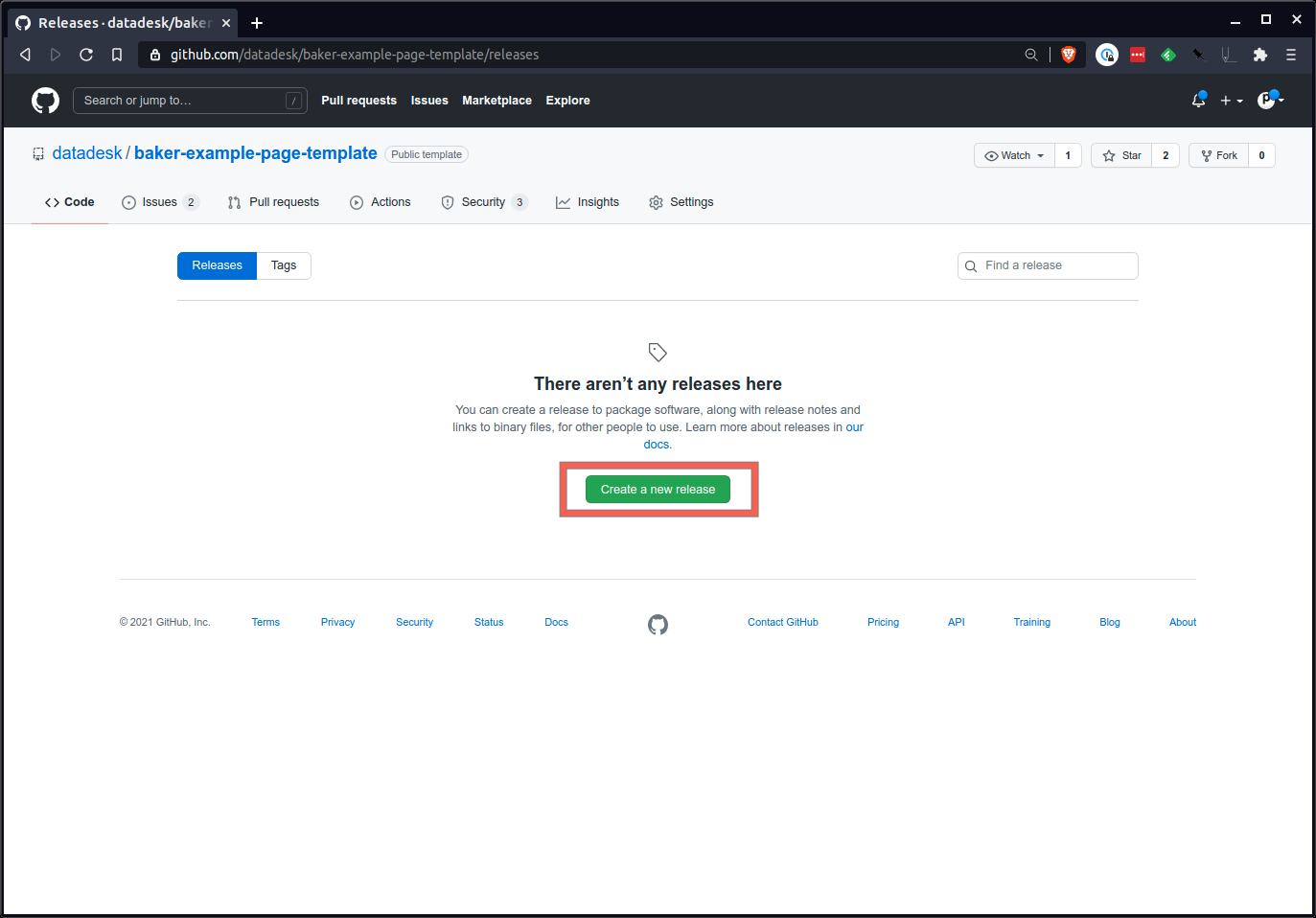
Allí creará un nuevo número de etiqueta. Un buen enfoque es comenzar con un número de formato xxx que siga los estándares de versiones semánticas. 1.0.0 es un buen comienzo.
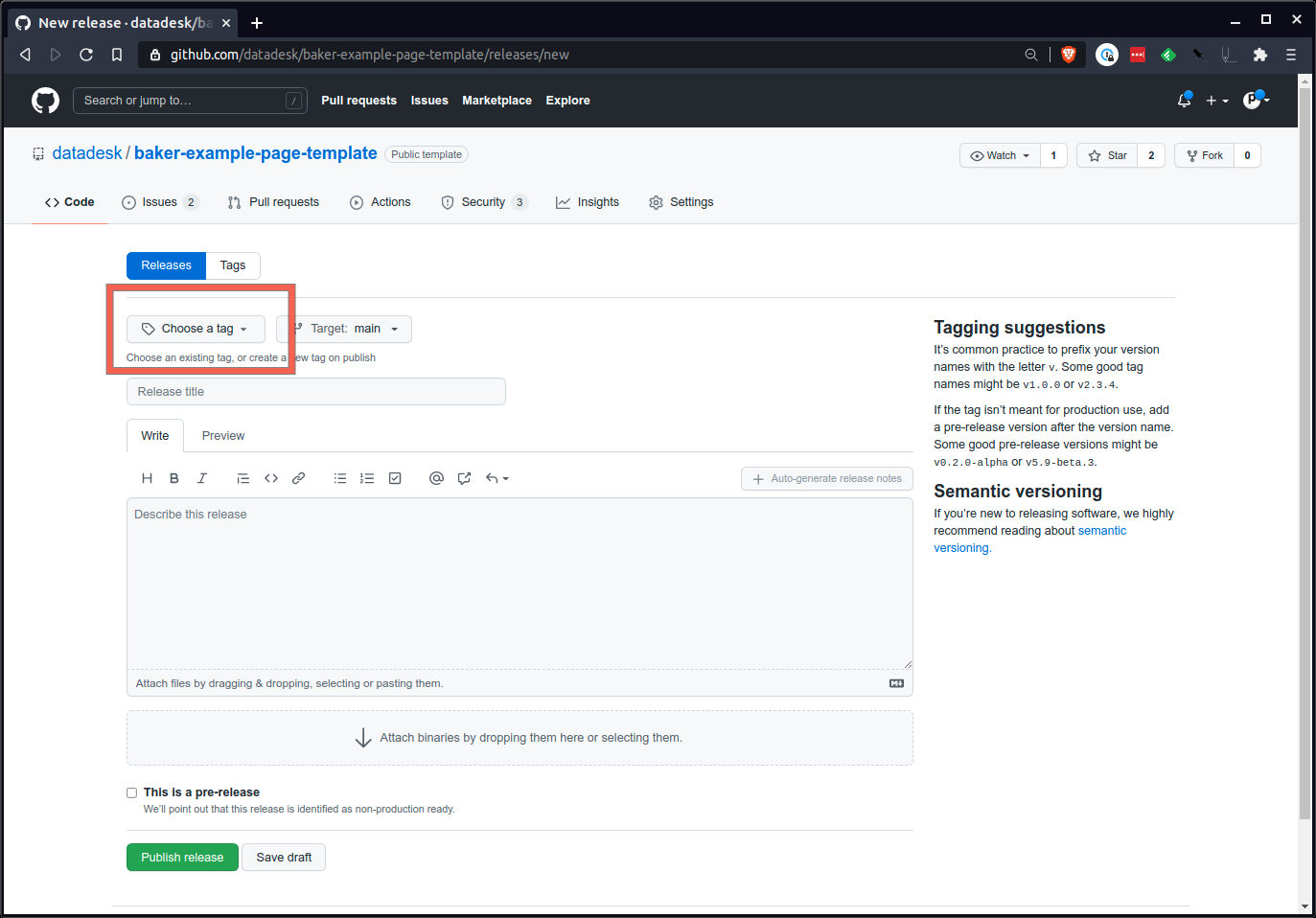
Finalmente, presione el gran botón verde en la parte inferior y envíe el comunicado.
Espere unos minutos y su página debería aparecer en https://your-production-bucket-url/your-slug/ .
El servidor de prueba de Baker puede iniciar sesión con mayor detalle comenzando con la siguiente opción.
DEBUG = inicio de 1 npm
Para limitar los registros a la ejecución del panadero:
DEBUG=panadero:* inicio npm
Si su compilación no tiene éxito, puede intentar crear el sitio estático usted mismo localmente a través de su terminal. Si hay errores con la creación de la página, se imprimirán en su terminal.
npm ejecutar compilación
Baker viene con un conjunto de variables globales que son las mismas en cada página que crea, y otro conjunto de variables específicas de la página que se configuran en función de la página que se está creando actualmente. Puede utilizar estas variables para agregar contenido condicionalmente a las páginas o filtrar datos no relacionados según la página actual.
NODE_ENV La variable NODE_ENV siempre será uno de dos valores: development o production . Corresponde al tipo de compilación que se ejecuta en la página.
Cuando ejecuta npm start , está en modo development . Cuando ejecuta npm run build , está en modo production .
Esto es más útil para agregar cosas a páginas sólo cuando estás en modo de development .
{% if NODE_ENV == 'development' %}<p>¡Nunca verás esto en el sitio activo!</p>{% endif %}DOMAIN La variable DOMAIN siempre será la misma que la opción domain pasada en baker.config.js , o una cadena vacía si no se pasó ninguna.
PATH_PREFIX La variable PATH_PREFIX siempre será la misma que la opción pathPrefix pasada en baker.config.js , o una sola barra diagonal ( / ) si no se pasó ninguna.
page.url La URL relativa al proyecto a la página actual. Incluirá el pathPrefix si se proporcionó uno en el archivo baker.config.js ; en otras palabras, tendrá en cuenta cualquier ruta del proyecto que se esté realizando y apuntará a la página correcta del proyecto.
page.absoluteUrl La URL absoluta de la página actual. Esto combina el domain , pathPrefix y la ruta actual en una URL completa. Esto se utiliza actualmente para generar la URL canónica y todas las URL de las etiquetas <meta> sociales.
<enlace rel="canonical" href="{{ página.absoluteUrl }}">page.inputUrl Esta es la ruta a la plantilla original utilizada para crear esta página en relación con el directorio del proyecto actual. Si tiene un archivo HTML ubicado en page-two/index.html , page.inputUrl sería page-two/index.html .
page.outputUrl Esta es la ruta al archivo HTML que se generó para crear esta página en relación con la carpeta _dist . Si tiene un archivo HTML ubicado en page-two.html , page.outputUrl sería page-two/index.html .
Cada proyecto de Baker en el que trabajamos incluye un archivo baker.config.js en el directorio raíz. Este archivo es responsable de pasar información a Baker para que pueda construir correctamente su proyecto.
exportar predeterminado {
// el directorio donde están los activos
activos: 'activos',
// crear páginas
crear páginas: indefinido,
// el directorio de datos
datos: '_datos',
// un dominio personalizado opcional para usar en la construcción de rutas
dominio: indefinido,
// una ruta o conjunto de rutas de cada punto de entrada de JavaScript
puntos de entrada: 'scripts/app.js',
// el directorio de entrada general, normalmente la carpeta actual
entrada: proceso.cwd(),
// donde se encuentran los diseños de plantilla, macros e inclusiones
diseños: '_layouts',
// un objeto con las claves y valores de las variables globales a ser
// pasado a todas las plantillas de Nunjucks
nunjucksVariables: indefinido,
// un objeto de clave (nombre) + valor (función) para agregar personalizado
// filtros a Nunjucks
nunjucksFiltros: indefinido,
// un objeto de clave (nombre) + valor (función) para agregar personalizado
// etiquetas a Nunjucks
nunjucksEtiquetas: indefinido,
// dónde generar los archivos compilados
salida: '_dist',
// un prefijo para agregar al comienzo de cada ruta resuelta, ¿cómo?
// las babosas funcionan
Prefijo de ruta: '/',
// un directorio opcional para colocar todos los activos, rara vez se usa
raíz estática: '',}; predeterminado: ”assets”
Esto le indica a Baker qué carpeta debe tratar como directorio de activos. Probablemente no tengas que cambiar esto.
predeterminado: undefined
createPages es un parámetro opcional que permite crear páginas dinámicamente utilizando datos y plantillas en el proyecto.
exportar predeterminado {
//…
// createPage - pasa una plantilla, un nombre de salida y el contexto de datos
// datos - los datos preparados en la carpeta `_data`
createPages(createPage, datos) {para (título constante de datos.títulos) { createPage('template.html', `${title}.html`, {context: { title }, });}
},}; predeterminado: ”_data”
La opción data le indica a Baker qué carpeta debe tratar como fuente de datos. Probablemente no necesites cambiar esto.
predeterminado: undefined
La opción domain le dice a Baker qué usar cuando crea URL absolutas. La bakery-template lo preestablece en https://www.latimes.com .
predeterminado: ”scripts/app.js”
La opción entrypoints le indica a Baker qué archivos JavaScript debe tratar como puntos de partida para los paquetes de scripts. Puede ser una ruta a un archivo o un conjunto de archivos, lo que permite crear varios paquetes al mismo tiempo.
predeterminado: process.cwd()
La opción input le dice a Baker qué carpeta debe tratar como directorio principal para todo el proyecto. De forma predeterminada, esta es la carpeta en la que se encuentra el archivo baker.config.js . Probablemente no necesite configurar esto.
predeterminado: ”_layouts”
La opción layouts le dice a Baker dónde se encuentran las plantillas, inclusiones y macros. De forma predeterminada, esta es la carpeta _layouts . Probablemente no necesite configurar esto.
predeterminado: undefined
Puede utilizar nunjucksFilters para pasar sus propios filtros personalizados. En el objeto, cada clave es el nombre del filtro y el valor de la función es lo que se llama cuando se usa el filtro.
exportar predeterminado {
//...
// pasa un objeto de filtros para agregar a Nunjucks
filtros nunjucks: {cuadrado(n) { n = +n; devolver n * n;}
},} {{ valor|cuadrado }} predeterminado: undefined
Puede utilizar nunjucksTags para pasar sus propias etiquetas personalizadas. Se diferencian de los filtros en que facilitan la generación de bloques de texto o HTML.
exportar predeterminado {
//...
// pasa un objeto de filtros para agregar a Nunjucks
nunjucksTags: {doubler(n) { return `<p>${n} duplicado es ${n * 2}</p>`;}
},}; {% valor duplicador %} predeterminado: ”_dist”
La opción output le dice a Baker dónde colocar los archivos cuando se ejecuta npm run build . Por defecto, esta es la carpeta _dist . Probablemente no necesite configurar esto.
por defecto: ”/”
pathPrefix le dice a Baker qué prefijo de ruta agregar a cualquier URL que cree. Si también se pasa domain , se combinará con pathPrefix al crear URL absolutas. Por lo general, no configurará esto manualmente; se usa durante las implementaciones para crear URL con slugs de proyecto.
por defecto: ””
La opción staticRoot le indica a Baker que coloque todos los activos en un directorio adicional. Esto es útil para proyectos que necesitan tener slugs únicos en cada página sin anidar, lo que les permite compartir recursos estáticos. Sin embargo, este es un caso especial y requiere una configuración personalizada para las implementaciones. No intente utilizar esto sin una buena razón.


