eye in the sky
1.0.0
Clasificación de imágenes satelitales, InterIIT Techmeet 2018, IIT Bombay.
Equipo: Manideep Kolla, Aniket Mandle, Apoorva Kumar
Este repositorio contiene la implementación de dos algoritmos, a saber, U-Net: redes convolucionales para segmentación de imágenes biomédicas y red de análisis de escenas piramidales modificada para el problema de clasificación de imágenes satelitales.
main_unet.py : código Python para entrenar el algoritmo con arquitectura U-Net, incluida la codificación de las verdades fundamentales.unet.py : Contiene nuestra implementación de capas U-Net.test_unet.py : Código para realizar pruebas, calcular precisiones, calcular matrices de confusión para entrenamiento y validación y guardar predicciones mediante el modelo U-Net en imágenes de entrenamiento, validación y prueba.Inter-IIT-CSRE : contiene todos los datos de capacitación, validación y pruebas.Comparison_Test.pdf : Comparación lado a lado de los datos de prueba con las predicciones del modelo U-Net sobre los datos.train_predictions : Predicciones del modelo U-Net sobre imágenes de entrenamiento y validación.plots : Gráficos de precisión y pérdida para entrenamiento y validación de la arquitectura U-Net.Test_images , Test_outputs : contiene imágenes de prueba y sus predicciones según el modelo U-Net.class_masks , compare_pred_to_gt , images_for_doc : contiene varias imágenes para documentación.PSPNet : contiene archivos de entrenamiento para la implementación del algoritmo PSPNet en la clasificación de imágenes satelitales. Clone el repositorio, cambie su directorio de trabajo actual al directorio clonado. Cree carpetas con los nombres train_predictions y test_outputs para guardar los resultados previstos del modelo en imágenes de entrenamiento y prueba (ahora no es necesario porque el repositorio ya contiene estas carpetas).
$ git clone https://github.com/manideep2510/eye-in-the-sky.git
$ cd eye-in-the-sky
$ mkdir train_predictions
$ mkdir test_outputs
Para entrenar el modelo U-Net y ahorrar pesos, ejecute el siguiente comando
$ python3 main_unet.py
Probar el modelo U-Net, calculando precisiones, calculando matrices de confusión para entrenamiento y validación y guardando predicciones del modelo en imágenes de entrenamiento, validación y prueba.
$ python3 test_unet.py
Es posible que reciba un error xrange is not defined mientras ejecuta nuestro código. Este error no se debe a errores en nuestro código, sino a que el paquete de Python no está actualizado llamado libtiff (algunas partes del código fuente del paquete están en python2 y otras en python3) que usamos para leer el conjunto de datos en el que las imágenes están en formato .tif. No pudimos utilizar otras bibliotecas como openCV o PIL para leer las imágenes ya que no admiten correctamente la lectura de imágenes .tif de 4 canales.
Este error se puede resolver editando el código fuente de la biblioteca libtiff .
Vaya al archivo en el código fuente de la biblioteca de donde surge el error (el nombre del archivo se mostrará en la terminal cuando muestre el error) y reemplace todas las funciones xrange() (python2) en el archivo por range() (python3).
Aquí proporcionamos algunos pesos preentrenados razonablemente buenos para que los usuarios no necesiten entrenar desde cero.
| Descripción | Tarea | Conjunto de datos | Modelo |
|---|---|---|---|
| Arquitectura UNet | Clasificación de imágenes de satélite | Conjunto de datos IITB (consulte la carpeta Inter-IIT-CSRE ) | descargar (.h5) |
Para utilizar los pesos previamente entrenados, cambie el nombre del archivo .h5 (archivo de pesos) mencionado en test_unet.py para que coincida con el nombre del archivo de pesos que descargó cuando sea necesario.
ahora hablemos
1. De qué se trata este proyecto,
2. Arquitecturas que hemos utilizado y experimentado y
3. Algunas estrategias de formación novedosas que hemos utilizado en el proyecto
La teledetección es la ciencia de obtener información sobre objetos o áreas a distancia, generalmente desde aviones o satélites.
Nos dimos cuenta del problema de la clasificación de imágenes satelitales como un problema de segmentación semántica y construimos algoritmos de segmentación semántica en aprendizaje profundo para abordarlo.
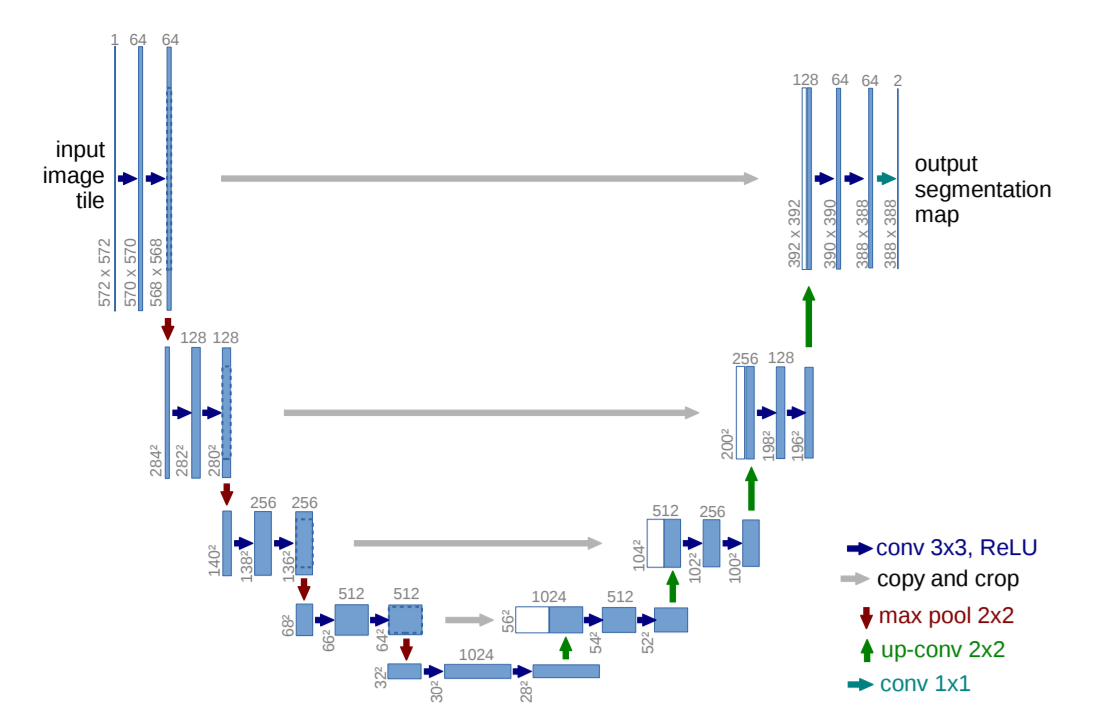
U-Net: Redes convolucionales para segmentación de imágenes biomédicas
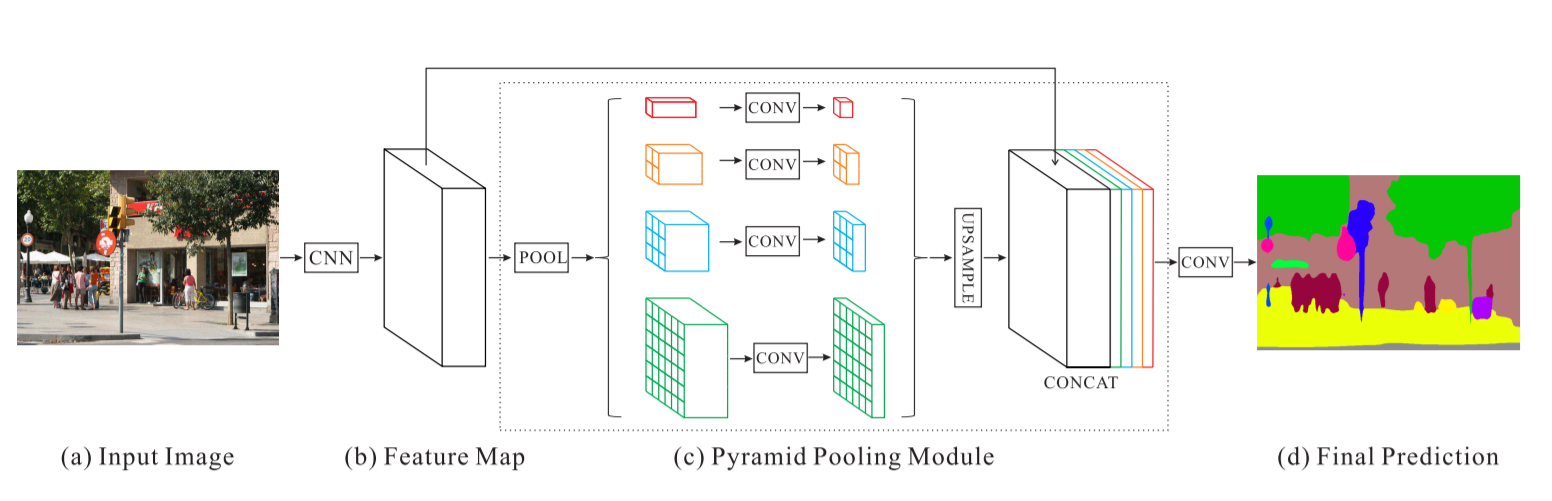
Red de análisis de escenas piramidales - PSPNet
Las verdades básicas proporcionadas son imágenes RGB de 3 canales. En el conjunto de datos actual, solo hay 9 valores RGB únicos en las verdades fundamentales, ya que hay 9 clases que deben clasificarse. Estos 9 valores RGB diferentes están codificados en caliente para generar una verdad básica codificada de 9 canales y cada canal representa una clase particular.
A continuación se muestra el esquema de codificación.
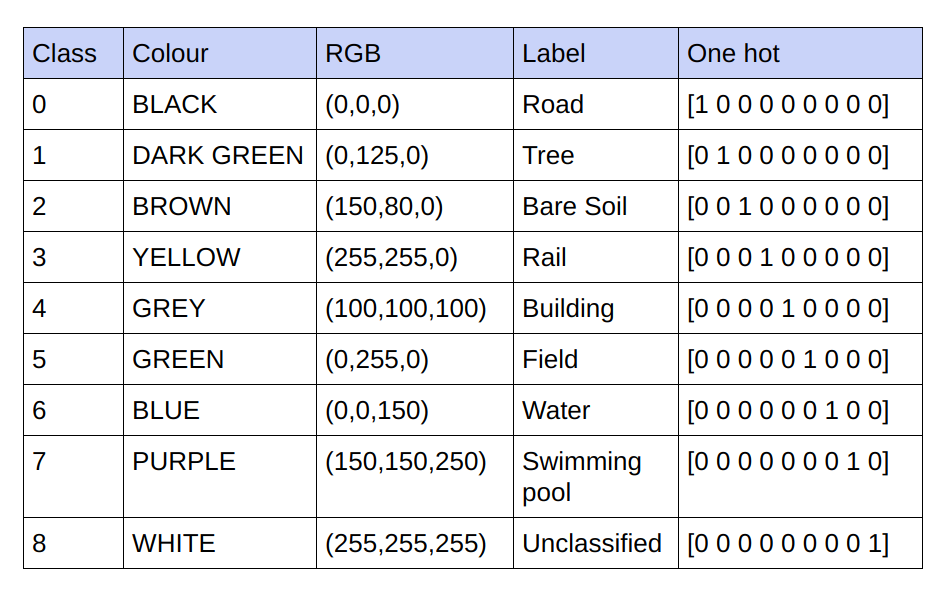
Realización de cada canal en la verdad fundamental codificada como clase.

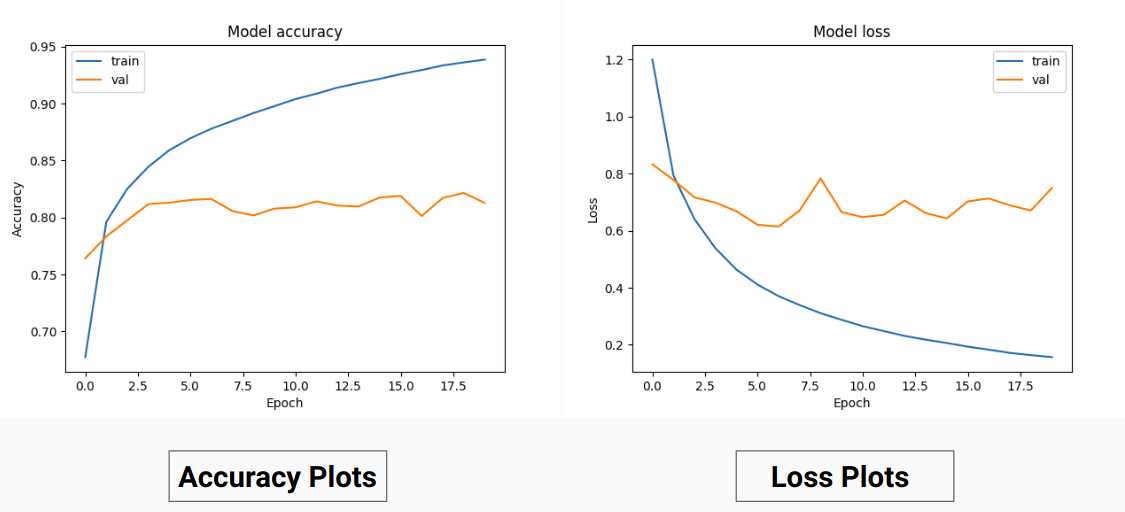
Entonces, en lugar de entrenar con los valores RGB de la verdad fundamental, los hemos convertido en valores únicos de diferentes clases. Este enfoque nos produjo una precisión de validación del 85 % y una precisión de entrenamiento del 92 % en comparación con una precisión de validación del 71 % y una precisión de entrenamiento del 65 % cuando usábamos los valores de verdad del terreno RGB para el entrenamiento.
Esto podría deberse a la disminución de la varianza y la media de la verdad fundamental de los datos de entrenamiento, ya que actúa como una técnica de normalización eficaz. El mejor rendimiento de esta técnica de entrenamiento también se debe a que el modelo proporciona una salida con 9 mapas de características, cada mapa indica una clase, es decir, esta técnica de entrenamiento actúa como si el modelo estuviera entrenado en cada una de las 9 clases por separado hasta cierto punto ( pero aquí definitivamente la predicción en un canal que corresponde a una clase particular depende de otros) .
Nuestros resultados en PSPNet para clasificación de imágenes satelitales:
Precisión de entrenamiento: 49 % Precisión de validación: 60 %
Razones:
U-Net:
U-Net modificado:
Para el entrenamiento y la validación hemos utilizado las 14 imágenes '.tif' en la carpeta Inter-IIT-CSRE/The-Eye-in-the-Sky-dataset .
Para el entrenamiento hemos utilizado las primeras 13 imágenes del conjunto de datos y para la validación, se utiliza la 14ª imagen .
Cada imagen de satélite en la carpeta sat contiene 4 canales, a saber, R (Banda 1), G (Banda 2), B (Banda 3) y NIR (Banda 4).
Las imágenes reales del terreno en el directorio gt son imágenes RGB y representan 8 clases: carreteras, edificios, árboles, césped, suelo desnudo, agua, ferrocarriles y piscinas.
La razón por la que hemos considerado solo una imagen (imagen 14) como conjunto de validación es porque es una de las imágenes más pequeñas del conjunto de datos y no queremos dejar menos datos para el entrenamiento, ya que el conjunto de datos es bastante pequeño. El conjunto de validación (imagen 14) que hemos considerado no tiene 3 clases (suelo desnudo, carril, encuesta de natación) que tengan precisiones de entrenamiento bastante altas. La precisión de la validación habría sido mejor si hubiéramos considerado una imagen con todas las clases (ninguna imagen en el conjunto de datos contiene todas las clases, falta al menos una clase en todas las imágenes).
El cultivo a zancadas:
Para tener suficientes datos de entrenamiento a partir de las imágenes de alta definición dadas, es necesario recortar para entrenar el clasificador que tiene alrededor de 31 millones de parámetros de nuestra implementación de U-Net. En el tamaño de recorte de 64x64 encontramos una infrarrepresentación de las clases individuales y se pierde la geometría y continuidad de los objetos, disminuyendo el campo de visión de las convoluciones.
Usando una ventana de recorte de 128x128 píxeles con un paso de 32, se obtuvieron 15887 entrenamientos y 414 imágenes de validación.
Dimensiones de la imagen:
Antes de recortar, las dimensiones de las imágenes de entrenamiento se convierten en múltiplos de zancadas para mayor comodidad durante el recorte.
Para los casos en los que el no. de cultivos no es el múltiplo de las dimensiones de la imagen que inicialmente probamos con relleno cero, nos dimos cuenta de que agregar relleno agregará artefactos no deseados en forma de píxeles negros en las imágenes de entrenamiento y prueba, lo que conducirá al entrenamiento con datos falsos y límites de imagen.
Alternativamente, hemos cambiado correctamente las dimensiones de la imagen agregando píxeles adicionales en el lado derecho y en la parte inferior de la imagen. Así que rellenamos la diferencia desde la parte más izquierda de la imagen hasta el extremo derecho del déficit y de manera similar para la parte superior e inferior de la imagen.
Ejemplo de entrenamiento 1: Imagen '2.tif' de datos de entrenamiento
Ejemplo de entrenamiento 2: Imagen '4.tif' de datos de entrenamiento
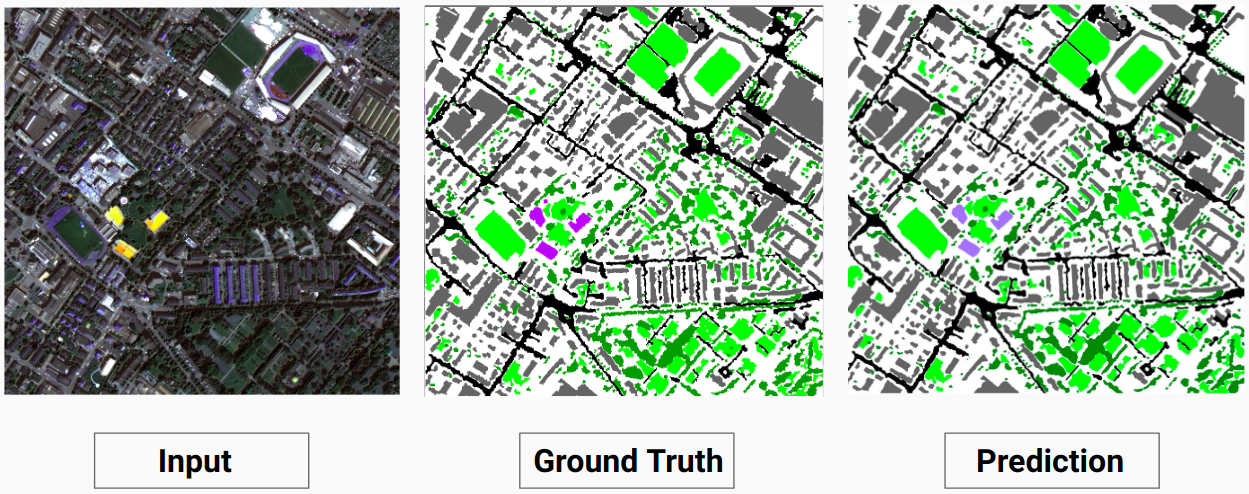
Ejemplo de validación: imagen '14.tif' del conjunto de datos

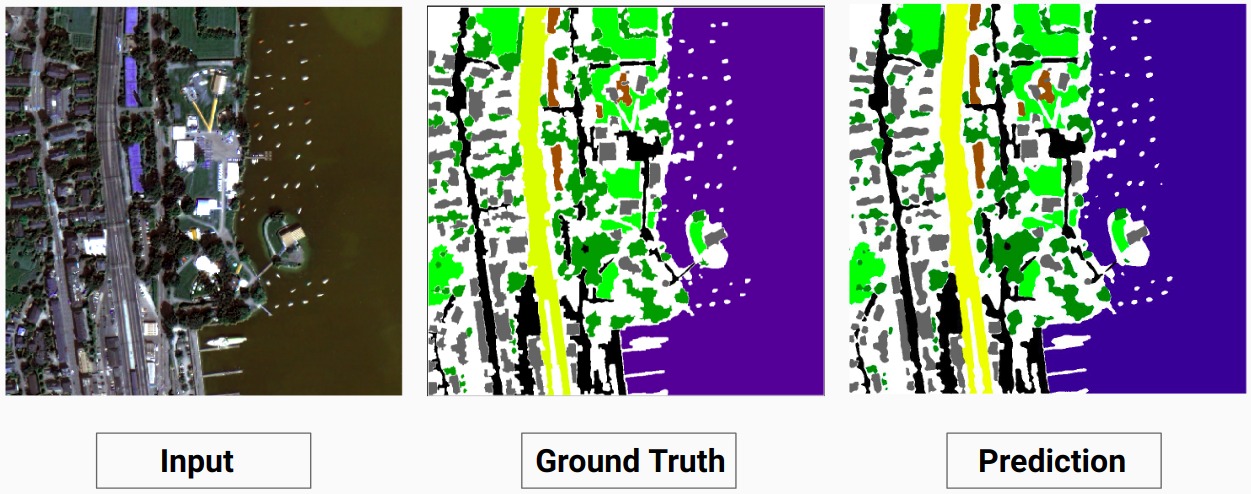
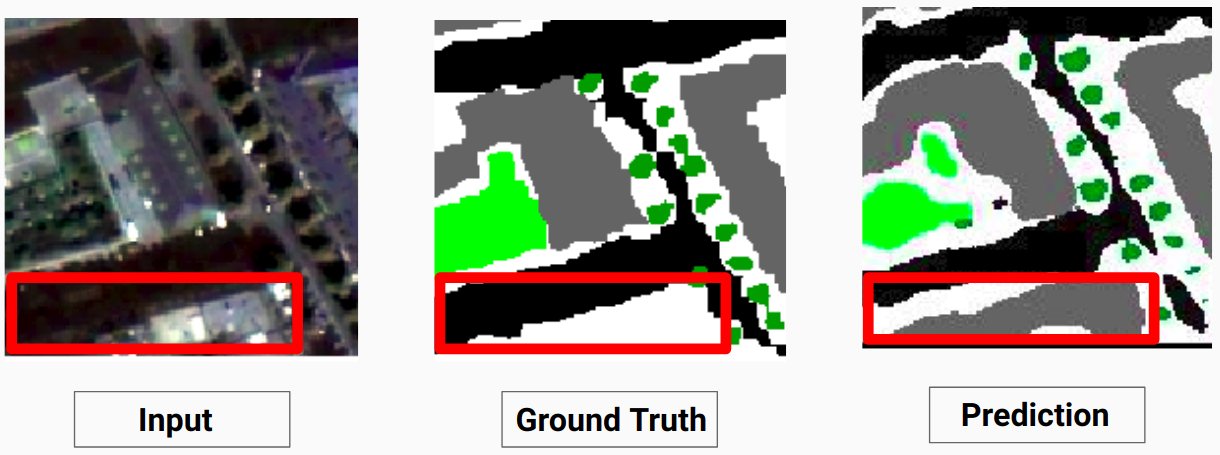
Nuestro modelo es capaz de predecir algunas clases que un anotador humano no pudo. El anotador humano etiqueta las clases no identificables en las imágenes como píxeles blancos. Nuestro modelo es capaz de predecir algunos de estos píxeles blancos correctamente como alguna clase, pero esto provocó una disminución en la precisión general ya que el modelo considera los píxeles blancos como una clase separada.
Aquí el modelo es capaz de predecir los píxeles blancos como un edificio, lo cual es correcto y se puede ver claramente en la imagen de entrada.
Consulte Comparison_Test.pdf para comparar las imágenes de prueba y los resultados previstos por el modelo.
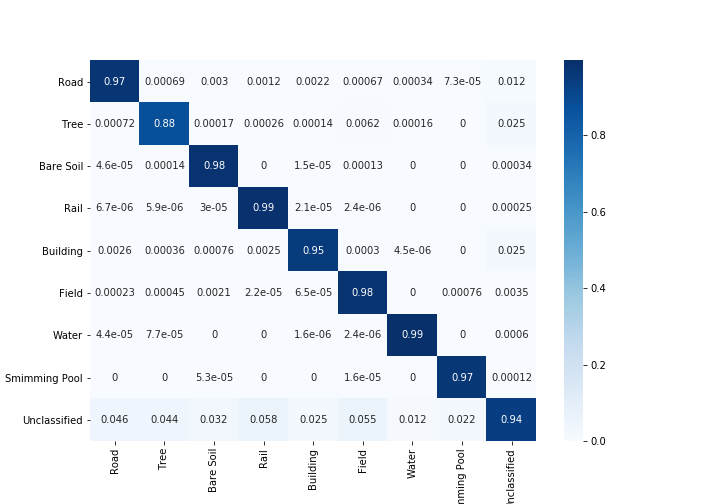
Coeficientes Kappa con y sin considerar los píxeles no clasificados
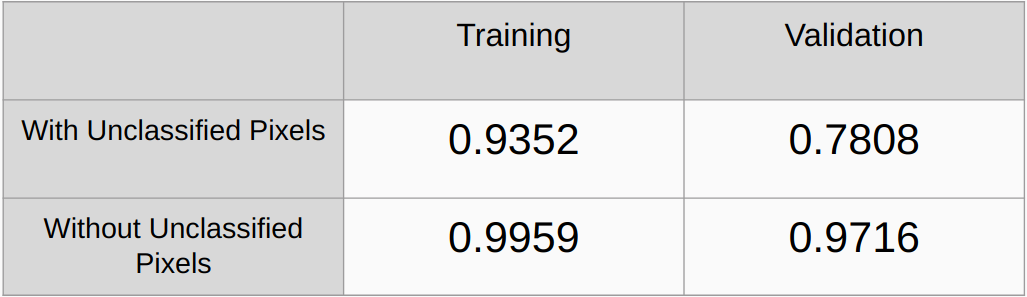
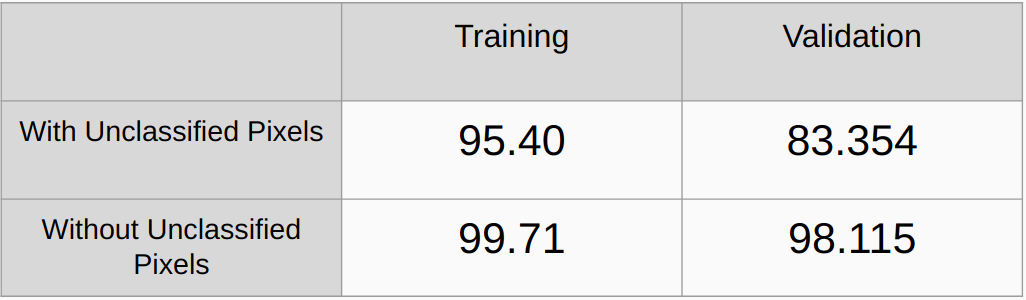
Precisión general con y sin considerar los píxeles no clasificados
Es necesario agregar métodos de regularización como regularización L2 y abandono y verificar el rendimiento.
Implemente un algoritmo para detectar automáticamente todos los valores RGB únicos en las verdades básicas y codifíquelos en caliente en lugar de encontrar manualmente los valores RGB.
[1] U-Net: Redes convolucionales para la segmentación de imágenes biomédicas, Olaf Ronneberger, Philipp Fischer y Thomas Brox
[2] Red de análisis de escenas piramidales, Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, Jiaya Jia
[3] Guía de 2017 para la segmentación semántica con aprendizaje profundo, Sasank Chilamkurthy


