linformer pytorch
version
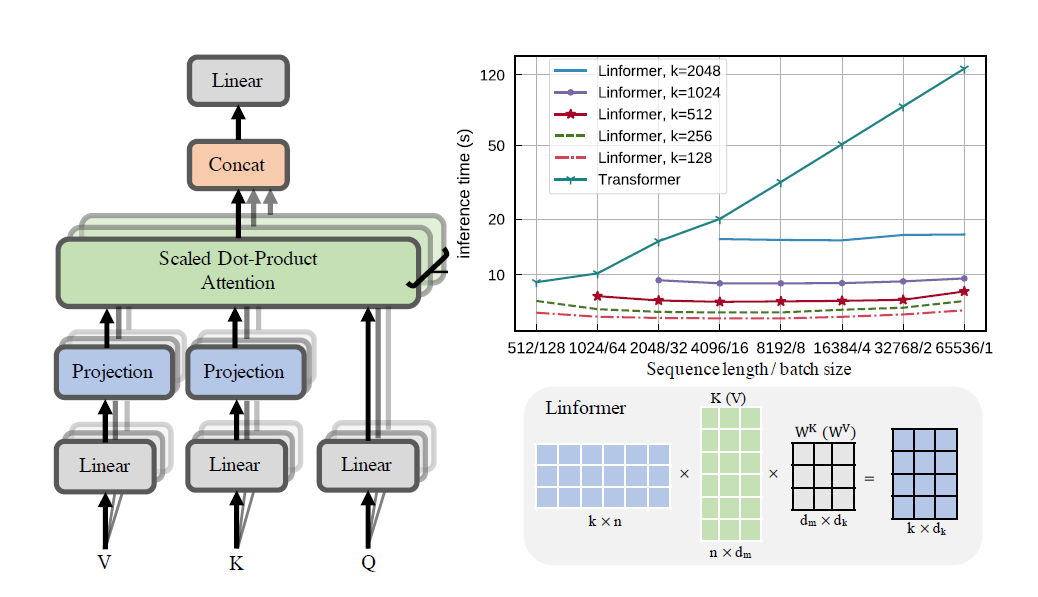
Una implementación práctica del documento Linformer. Esta es una atención con solo complejidad lineal en n, lo que permite atender longitudes de secuencia muy largas (1 mil+) en hardware moderno.
Este repositorio es un transformador de estilo Atención es todo lo que necesita, completo con un módulo codificador y decodificador. La novedad aquí es que ahora se pueden hacer lineales las cabezas de atención. Vea cómo usarlo a continuación.
Esto está en proceso de validación en wikitext-2. Actualmente, funciona al mismo nivel que otros mecanismos de atención escasa, como el transformador Sinkhorn, pero aún están por encontrar los mejores hiperparámetros.
También es posible la visualización de las cabezas. Para ver más información, consulte la sección Visualización a continuación.
No soy el autor del artículo.
1,23 millones de fichas
pip install linformer-pytorch
Alternativamente,
git clone https://github.com/tatp22/linformer-pytorch.git
cd linformer-pytorch
Modelo de lenguaje Linformer
from linformer_pytorch import LinformerLM
import torch
model = LinformerLM (
num_tokens = 10000 , # Number of tokens in the LM
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
use_pos_emb = True , # Whether or not to use positional embeddings
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
emb_dim = 128 , # If you want the embedding dimension to be different than the channels for the Linformer
causal = False , # If you want this to be a causal Linformer, where the upper right of the P_bar matrix is masked out.
method = "learnable" , # The method of how to perform the projection. Supported methods are 'convolution', 'learnable', and 'no_params'
ff_intermediate = None , # See the section below for more information
). cuda ()
x = torch . randint ( 1 , 10000 ,( 1 , 512 )). cuda ()
y = model ( x )
print ( y ) # (1, 512, 10000) Autoatención de Linformer, pilas de MHAttention y FeedForward
from linformer_pytorch import Linformer
import torch
model = Linformer (
input_size = 262144 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
). cuda ()
x = torch . randn ( 1 , 262144 , 64 ). cuda ()
y = model ( x )
print ( y ) # (1, 262144, 64)Atención Linformer Multihead
from linformer_pytorch import MHAttention
import torch
model = MHAttention (
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim = 8 , # Dim of each attn head
dim_k = 128 , # What to sample the input length down to
nhead = 8 , # Number of heads
dropout = 0 , # Dropout for each of the heads
activation = "gelu" , # Activation after attention has been concat'd
checkpoint_level = "C2" , # If C2, checkpoint each of the heads
parameter_sharing = "layerwise" , # What level of parameter sharing to do
E_proj , F_proj , # The E and F projection matrices
full_attention = False , # Use full attention instead
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x )
print ( y ) # (1, 512, 64)El cabezal de atención lineal, la novedad del papel
from linformer_pytorch import LinearAttentionHead
import torch
model = LinearAttentionHead (
dim = 64 , # Dim 2 of the input
dropout = 0.1 , # Dropout of the P matrix
E_proj , F_proj , # The E and F layers
full_attention = False , # Use Full Attention instead
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x , x , x )
print ( y ) # (1, 512, 64)Un módulo codificador/decodificador.
Nota: Para secuencias causales, se puede activar el indicador causal=True en LinformerLM para enmascarar la parte superior derecha de la matriz de atención (n,k) .
import torch
from linformer_pytorch import LinformerLM
encoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
k_reduce_by_layer = 1 ,
return_emb = True ,
)
decoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
decoder_mode = True ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
x_mask = torch . ones_like ( x ). bool ()
y_mask = torch . ones_like ( y ). bool ()
enc_output = encoder ( x , input_mask = x_mask )
print ( enc_output . shape ) # (1, 512, 128)
dec_output = decoder ( y , embeddings = enc_output , input_mask = y_mask , embeddings_mask = x_mask )
print ( dec_output . shape ) # (1, 512, 10000) Se puede realizar una forma sencilla de obtener las matrices E y F llamando a la función get_EF . Por ejemplo, para un n de 1000 y un k de 100 :
from linfromer_pytorch import get_EF
import torch
E = get_EF ( 1000 , 100 ) Con el indicador method , se puede configurar el método con el que el linformer realiza la reducción de resolución. Actualmente, se admiten tres métodos:
learnable : este método de reducción de resolución crea un módulo n,k nn.Linear que se puede aprender.convolution : este método de reducción de resolución crea una convolución 1d, con longitud de zancada y tamaño de núcleo n/k .no_params : Esto crea una matriz fija n,k con valores de N(0,1/k)En el futuro, es posible que incluya la agrupación o algo más. Pero por ahora estas son las opciones que existen.
Como un intento de introducir aún más ahorro de memoria, se ha introducido el concepto de niveles de puntos de control. Los tres niveles de puntos de control actuales son C0 , C1 y C2 . Al subir los niveles de los puntos de control, se sacrifica la velocidad para ahorrar memoria. Es decir, el nivel de punto de control C0 es el más rápido, pero ocupa la mayor cantidad de espacio en la GPU, mientras que C2 es el más lento, pero ocupa el menor espacio en la GPU. El detalle de cada nivel de punto de control es el siguiente:
C0 : Sin puntos de control. Los modelos se ejecutan manteniendo todas las cabezas de atención y las capas ff en la memoria de la GPU.C1 : controle la atención de cada MultiHead, así como de cada capa ff. Con esto, aumentar depth debería tener un impacto mínimo en la memoria.C2 : junto con las optimizaciones en el nivel C1 , controle cada cabeza en cada capa de atención de múltiples cabezas. Con esto, aumentar nhead debería tener un impacto menor en la memoria. Sin embargo, concatenar las cabezas con torch.cat todavía consume mucha memoria y, con suerte, esto se optimizará en el futuro.Aún se desconocen los detalles de rendimiento, pero existe la opción para los usuarios que quieran probar.
Otro intento de introducir ahorros de memoria en el artículo fue compartir parámetros entre proyecciones. Esto se menciona en la sección 4 del artículo; en particular, hubo 4 tipos diferentes de intercambio de parámetros que los autores discutieron y todos se implementaron en este repositorio. La primera opción ocupa la mayor parte de la memoria y cada opción adicional reduce los requisitos de memoria necesarios.
none : No se comparten parámetros. Para cada cabeza y para cada capa, se calcula una nueva E y una nueva matriz F para cada cabeza en cada capa.headwise : Cada capa tiene una matriz E y F única. Todas las cabezas de la capa comparten esta matriz.kv : Cada capa tiene una matriz de proyección única P y E = F = P para cada capa. Todas las cabezas comparten esta matriz de proyección P .layerwise : hay una matriz de proyección P , y cada cabeza en cada capa usa E = F = P Como se inició en el artículo, esto significa que para una red de 12 capas y 12 cabezales, habría 288 , 24 , 12 y 1 matrices de proyección diferentes, respectivamente.
Tenga en cuenta que con la opción k_reduce_by_layer , la opción layerwise no será efectiva, ya que utilizará la dimensión de k para la primera capa. Por lo tanto, si el valor de k_reduce_by_layer es mayor que 0 , lo más probable es que no se deba utilizar la opción de compartir layerwise .
Además, tenga en cuenta que, según los autores, en la figura 3, este intercambio de parámetros realmente no afecta demasiado el resultado final. Por lo tanto, puede ser mejor continuar con el uso compartido layerwise para todo, pero existe la opción para que los usuarios lo prueben.
Un pequeño problema con la implementación actual de Linformer es que la longitud de su secuencia debe coincidir con el indicador input_size del modelo. El Padder rellena el tamaño de entrada de modo que el tensor pueda introducirse en la red. Un ejemplo:
from linformer_pytorch import Linformer , Padder
import torch
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_d = 32 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 6 ,
depth = 3 ,
checkpoint_level = "C1" ,
)
model = Padder ( model )
x = torch . randn ( 1 , 500 , 16 ) # This does not match the input size!
y = model ( x )
print ( y ) # (1, 500, 16) 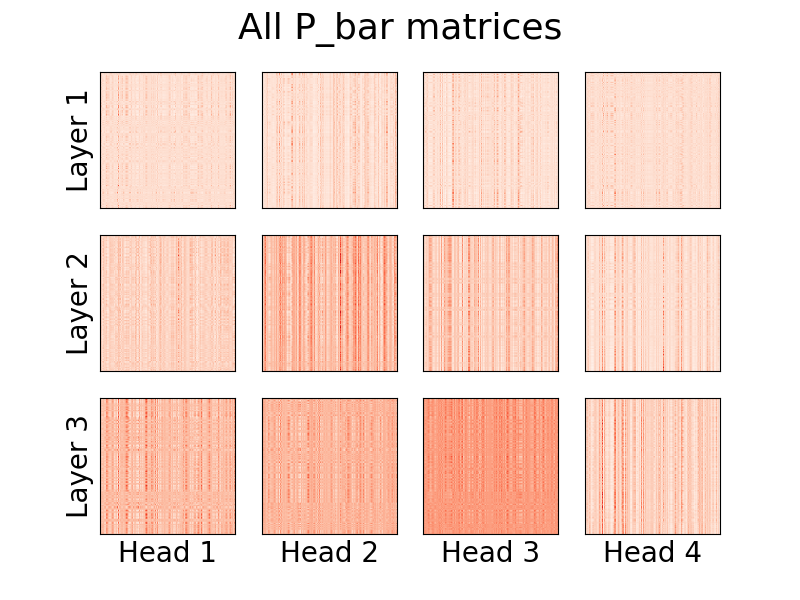
¡A partir de la versión 0.8.0 , ahora se pueden visualizar las cabezas de atención del linformer! Para ver esto en acción, simplemente importe la clase Visualizer y ejecute la función plot_all_heads() para ver una imagen de todas las cabezas de atención en cada nivel, de tamaño (n,k). Asegúrese de especificar visualize=True en el pase hacia adelante, ya que esto guarda la matriz P_bar para que la clase Visualizer pueda visualizar correctamente la cabeza.
A continuación se puede encontrar un ejemplo funcional del código, y el mismo código se puede encontrar en ./examples/example_vis.py :
import torch
from linformer_pytorch import Linformer , Visualizer
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_k = 128 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
checkpoint_level = "C0" ,
parameter_sharing = "layerwise" ,
k_reduce_by_layer = 1 ,
)
# One can load the model weights here
x = torch . randn ( 1 , 512 , 16 ) # What input you want to visualize
y = model ( x , visualize = True )
vis = Visualizer ( model )
vis . plot_all_heads ( title = "All P_bar matrices" , # Change the title if you'd like
show = True , # Show the picture
save_file = "./heads.png" , # If not None, save the picture to a file
figsize = ( 8 , 6 ), # How big the figure should be
n_limit = None # If not None, limit how much from the `n` dimension to show
)Puede encontrar una explicación detallada de lo que significan estas cabezas en el n.° 15.
De manera similar al Reformer, intentaré crear un módulo codificador/decodificador para simplificar la capacitación. Esto funciona como 2 clases LinformerLM . Los parámetros se pueden ajustar individualmente para cada uno, teniendo el codificador el prefijo enc_ para todos los hiperparámetros y el decodificador teniendo el prefijo dec_ de manera similar. Hasta el momento lo que se implementa es:
import torch
from linformer_pytorch import LinformerEncDec
encdec = LinformerEncDec (
enc_num_tokens = 10000 ,
enc_input_size = 512 ,
enc_channels = 16 ,
dec_num_tokens = 10000 ,
dec_input_size = 512 ,
dec_channels = 16 ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
output = encdec ( x , y )Estoy planeando tener una manera de generar una secuencia de texto para esto.
ff_intermediate Ahora, la dimensión del modelo puede ser diferente en las capas intermedias. Este cambio se aplica al módulo ff y solo en el codificador. Ahora, si el indicador ff_intermediate no es Ninguno, las capas se verán así:
channels -> ff_dim -> ff_intermediate (For layer 1)
ff_intermediate -> ff_dim -> ff_intermediate (For layers 2 to depth-1)
ff_intermediate -> ff_dim -> channels (For layer depth)
A diferencia de
channels -> ff_dim -> channels (For all layers)
input_size y dim_k , respectivamente.apex deberían funcionar con esto; sin embargo, en la práctica, no se ha probado.input_size , k= dim_k y d= dim_d . LinformerEncDec Esta es la primera vez que reproduzco el resultado de un artículo, por lo que algunas cosas pueden estar mal. Si ve un problema, abra un problema e intentaré solucionarlo.
Gracias a lucidrains, cuyos otros repositorios de escasa atención me ayudaron a diseñar este Linformer Repo.
@misc { wang2020linformer ,
title = { Linformer: Self-Attention with Linear Complexity } ,
author = { Sinong Wang and Belinda Z. Li and Madian Khabsa and Han Fang and Hao Ma } ,
year = { 2020 } ,
eprint = { 2006.04768 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @inproceedings { vaswani2017attention ,
title = { Attention is all you need } ,
author = { Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, {L}ukasz and Polosukhin, Illia } ,
booktitle = { Advances in neural information processing systems } ,
pages = { 5998--6008 } ,
year = { 2017 }
}"Escucha con atención..."


