intelligent trading bot
1.0.0
___ _ _ _ _ _ _____ _ _ ____ _
|_ _|_ __ | |_ ___| | (_) __ _ ___ _ __ | |_ |_ _| __ __ _ __| (_)_ __ __ _ | __ ) ___ | |_
| || '_ | __/ _ | | |/ _` |/ _ '_ | __| | || '__/ _` |/ _` | | '_ / _` | | _ / _ | __|
| || | | | || __/ | | | (_| | __/ | | | |_ | || | | (_| | (_| | | | | | (_| | | |_) | (_) | |_
|___|_| |_|_____|_|_|_|__, |___|_| |_|__| |_||_| __,_|__,_|_|_| |_|__, | |____/ ___/ __|
|___/ |___/
₿ Ξ ₳ ₮ ✕ ◎ ● Ð Ł Ƀ Ⱥ ∞ ξ ◈ ꜩ ɱ ε ɨ Ɓ Μ Đ ⓩ Ο Ӿ Ɍ ȿ
? ¿Señales comerciales inteligentes ? https://t.me/intelligent_trading_signals
El proyecto tiene como objetivo desarrollar un robot comercial inteligente para el comercio automatizado de criptomonedas utilizando ingeniería de funciones y algoritmos de aprendizaje automático (ML) de última generación. El proyecto proporciona las siguientes funcionalidades principales:
El servicio de señalización se ejecuta en la nube y envía sus señales a este canal de Telegram:
? ¿Señales comerciales inteligentes ? https://t.me/intelligent_trading_signals
Todos pueden suscribirse al canal para tener una idea de las señales que genera este bot.
Actualmente, el bot está configurado usando los siguientes parámetros:
Hay períodos de silencio en los que la puntuación es inferior al umbral y no se envían notificaciones al canal. Si la puntuación es mayor que el umbral, cada minuto se envía una notificación que se parece a
₿24.518??? Puntuación: -0,26
El primer número es el último precio de cierre. La puntuación -0,26 significa que es muy probable que el precio sea más bajo que el precio de cierre actual.
Si la puntuación supera algún umbral especificado en el modelo, se genera una señal de compra o venta, lo que significa que es un buen momento para realizar una operación. Estas notificaciones tienen el siguiente aspecto:
? COMPRAR: ₿ 24.033 Puntuación: +0,34
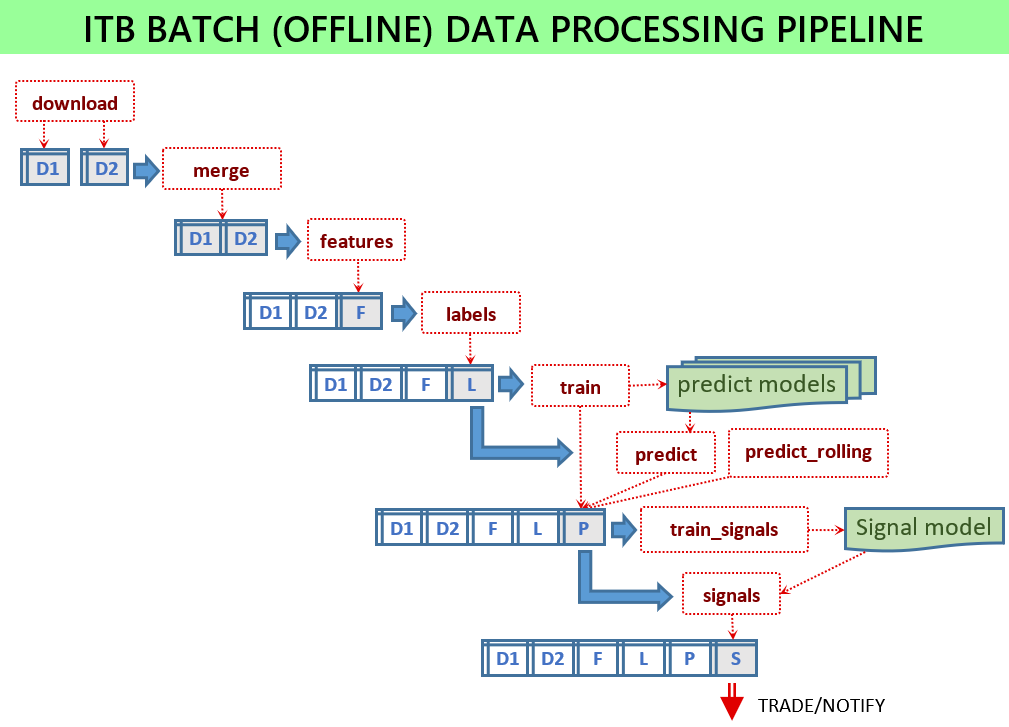
Para que el servicio de señalización funcione, se deben entrenar varios modelos de ML y los archivos de modelo deben estar disponibles para el servicio. Todos los scripts se ejecutan en modo por lotes cargando algunos datos de entrada y almacenando algunos archivos de salida. Los scripts por lotes se encuentran en el módulo scripts .
Si todo está configurado, se deben ejecutar los siguientes scripts:
python -m scripts.download_binance -c config.jsonpython -m scripts.merge -c config.jsonpython -m scripts.features -c config.jsonpython -m scripts.labels -c config.jsonpython -m scripts.train -c config.jsonpython -m scripts.signals -c config.jsonpython -m scripts.train_signals -c config.json Sin un archivo de configuración, los scripts utilizarán los parámetros predeterminados, lo cual es útil para fines de prueba y no está destinado a mostrar un buen rendimiento. Utilice archivos de configuración de muestra que se proporcionan para cada versión, como config-sample-v0.6.0.jsonc .
El parámetro de configuración principal para ambos scripts es una lista de fuentes en data_sources . Una entrada en esta lista especifica una fuente de datos, así como column_prefix utilizado para distinguir columnas con el mismo nombre de diferentes fuentes.
Descargue los datos históricos más recientes: python -m scripts.download_binance -c config.json
Fusione varios conjuntos de datos históricos en un solo conjunto de datos: python -m scripts.merge -c config.json
Este script está diseñado para calcular funciones derivadas:
python -m scripts.features -c config.json La lista de funciones que se generarán se configura a través de la lista feature_sets en el archivo de configuración. La forma en que se generan las funciones la define el generador de funciones, cada uno de los cuales tiene algunos parámetros especificados en su sección de configuración.
talib se basa en la biblioteca de análisis técnico TA-lib. Aquí un ejemplo de su configuración "config": {"columns": ["close"], "functions": ["SMA"], "windows": [5, 10, 15]}itbstats implementa funciones que se pueden encontrar en tsfresh como scipy_skew , scipy_kurtosis , lsbm (golpe más largo por debajo de la media), fmax (primera ubicación del máximo), mean , std , area , slope . Estos son los parámetros típicos: "config": {"columns": ["close"], "functions": ["skew", "fmax"], "windows": [5, 10, 15]}itblib implementado en ITB, pero la mayoría de sus funciones se pueden generar (mucho más rápido) a través de talibtsfresh genera funciones desde la biblioteca tsfresh Este script es similar a la generación de funciones porque agrega nuevas columnas al archivo de entrada. Sin embargo, estas columnas describen algo que queremos predecir y lo que no se sabe al ejecutar en modo online. Por ejemplo, podría ser un aumento de precio en el futuro:
python -m scripts.labels -c config.json La lista de etiquetas que se generarán se configura a través de la lista label_sets en la configuración. Un conjunto de etiquetas apunta a la función que genera columnas adicionales. Su configuración es muy similar a las configuraciones de funciones.
highlow devuelve True si el precio es superior al umbral especificado dentro de algún horizonte futuro.highlow2 Calcula aumentos (disminuciones) futuros con la condición de que no haya disminuciones (aumentos) significativos antes de eso. Aquí está su configuración típica "config": {"columns": ["close", "high", "low"], "function": "high", "thresholds": [1.0, 1.5, 2.0], "tolerance": 0.2, "horizon": 10080, "names": ["first_high_10", "first_high_15", "first_high_20"]}topbot obsoletotopbot2 Calcula los valores máximo y mínimo (etiquetados como Verdadero). Se garantiza que cada máximo (mínimo) etiquetado estará rodeado de mínimos (máximos) inferiores (superiores) al nivel especificado. La diferencia mínima requerida entre mínimos y máximos adyacentes se especifica mediante parámetros level . El parámetro de tolerancia permite incluir también puntos cercanos al máximo/mínimo. Aquí hay una configuración típica: "config": {"columns": "close", "function": "bot", "level": 0.02, "tolerances": [0.1, 0.2], "names": ["bot2_1", "bot2_2"]} Este script utiliza las etiquetas y características de entrada especificadas para entrenar varios modelos de ML:
python -m scripts.train -c config.jsonprediction-metrics.txt con las puntuaciones de predicción para todos los modelos.Configuración:
model_store.pytrain_featureslabelsalgorithms El objetivo de este paso es agregar las puntuaciones de predicción generadas por diferentes algoritmos para diferentes etiquetas. El resultado es una puntuación que se supone que será consumida por las reglas de señales en el siguiente paso. Los parámetros de agregación se especifican en la sección score_aggregation . buy_labels y sell_labels especifican puntuaciones de predicción de entrada procesadas por el procedimiento de agregación. window es el número de pasos previos utilizados para la agregación continua y combine es una forma de combinar dos tipos de puntuación (compra y etiquetas) en una puntuación de salida.
La puntuación generada por el procedimiento de agregación es un número y el objetivo de las reglas de señales es tomar decisiones comerciales: comprar, vender o no hacer nada. Los parámetros de las reglas de señales se describen en trade_model .
Este script simula operaciones utilizando muchos parámetros de señal de compra-venta y luego elige los parámetros de señal de mejor rendimiento:
python -m scripts.train_signals -c config.jsonEste script inicia un servicio que ejecuta periódicamente una misma tarea: cargar los datos más recientes, generar funciones, hacer predicciones, generar señales, notificar a los suscriptores:
python -m service.server -c config.jsonHay dos problemas:
python -m scripts.predict_rolling -c config.jsonpython -m scripts.train_signals -c config.jsonLos parámetros de configuración se especifican en dos archivos:
service.App.py en el campo config de la clase App-c config.jsom argumento para los servicios y scripts. Los valores de este archivo de configuración sobrescribirán los de App.config cuando este archivo se cargue en un script o servicio. Estos son algunos de los campos más importantes (tanto en App.py como config.json ):
data_folder : ubicación de los archivos de datos que solo se necesitan para secuencias de comandos sin conexión por lotessymbol es un par comercial como BTCUSDTlabels Lista de nombres de columnas que se tratan como etiquetas. Si define una nueva etiqueta utilizada para entrenamiento y luego para predicción, deberá especificar su nombre aquí.algorithms Lista de nombres de algoritmos utilizados para el entrenamientotrain_features Lista de todos los nombres de columnas utilizadas como funciones de entrada para entrenamiento y predicción.buy_labels y sell_labels Listas de columnas previstas utilizadas para señalestrade_model Parámetros del señalizador (principalmente algunos umbrales)trader es una sección para los parámetros del comerciante. Actualmente, no se ha probado exhaustivamente.collector Esta sección de parámetros está destinada a servicios de recopilación de datos. Hay dos tipos de servicios de recopilación de datos: sincrónico con solicitudes regulares al proveedor de datos y servicio de transmisión asincrónica que se suscribe al proveedor de datos y recibe notificaciones tan pronto como haya nuevos datos disponibles. Están funcionando, pero no se han probado ni integrado exhaustivamente en el servicio principal. El patrón de uso principal actual se basa en actualizaciones manuales de datos por lotes, generación de funciones y entrenamiento de modelos. Una razón para tener estos servicios de recopilación de datos es 1) tener actualizaciones más rápidas 2) tener datos que no están disponibles en una API normal como el libro de pedidos (existen algunas funciones que utilizan estos datos pero no están integradas en el flujo de trabajo principal).Consulte los archivos de configuración de muestra y los comentarios en App.config para obtener más detalles.
Cada minuto, el señalizador realiza los siguientes pasos para hacer una predicción sobre si es probable que el precio aumente o disminuya:
Notas:
Iniciando el servicio: python3 -m service.server -c config.json
El comerciante está funcionando, pero no está completamente depurado y, en particular, no se ha probado su estabilidad y confiabilidad. Por tanto, debe considerarse un prototipo con funcionalidad básica. Actualmente está integrado con Signaler, pero en un mejor diseño debería ser un servicio separado.
Prueba retrospectiva
Integraciones externas


