gigagan pytorch
0.2.20

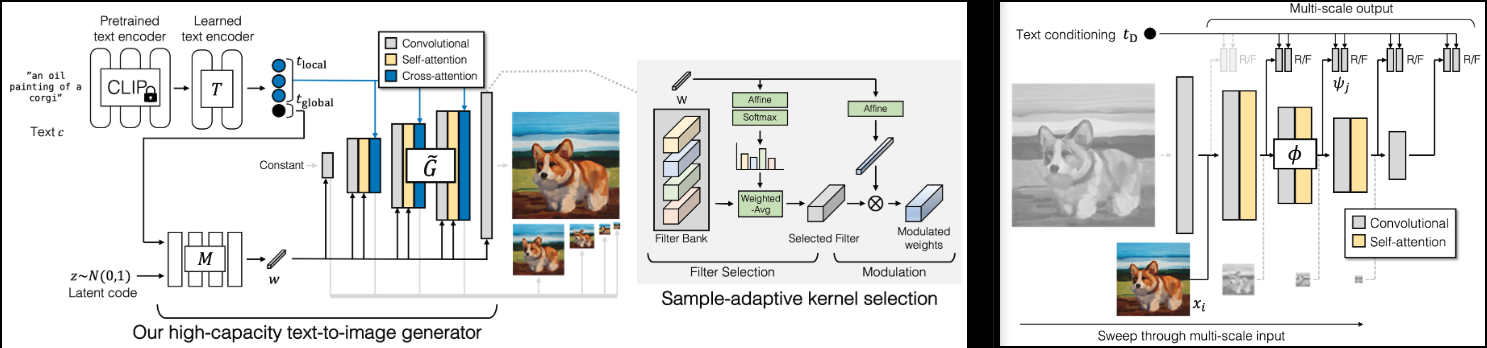
Implementación de GigaGAN (página del proyecto), nueva SOTA GAN de Adobe.
También agregaré algunos hallazgos de gan liviano, para una convergencia más rápida (excitación de capa de salto) y una mejor estabilidad (pérdida auxiliar de reconstrucción en el discriminador)
También contendrá el código para los muestreadores de 1k - 4k, que considero lo más destacado de este documento.
Únase si está interesado en ayudar con la replicación con la comunidad LAION.
EstabilidadAI y ? Huggingface por el generoso patrocinio, así como a mis otros patrocinadores, por brindarme la independencia para abrir la inteligencia artificial de código abierto.
? Huggingface por su biblioteca acelerada
Todos los mantenedores de OpenClip, por sus modelos de texto-imagen de aprendizaje contrastivo de código abierto SOTA.
Xavier por la muy útil revisión del código y por las discusiones sobre cómo se debe construir la invariancia de escala en el discriminador.
@CerebralSeed para solicitar el código de muestreo inicial tanto para el generador como para el upsampler.
¡Kerth por la revisión del código y por señalar algunas discrepancias con el documento!
$ pip install gigagan-pytorchGAN incondicional simple, para empezar
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
generator = dict (
dim_capacity = 8 ,
style_network = dict (
dim = 64 ,
depth = 4
),
image_size = 256 ,
dim_max = 512 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
amp = True
). cuda ()
# dataset
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
# you must then set the dataloader for the GAN before training
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
images = gan . generate ( batch_size = 4 ) # (4, 3, 256, 256)Para Unet Upsampler incondicional
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
train_upsampler = True , # set this to True
generator = dict (
style_network = dict (
dim = 64 ,
depth = 4
),
dim = 32 ,
image_size = 256 ,
input_image_size = 64 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
multiscale_input_resolutions = ( 128 ,),
unconditional = True
),
amp = True
). cuda ()
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
lowres = torch . randn ( 1 , 3 , 64 , 64 ). cuda ()
images = gan . generate ( lowres ) # (1, 3, 256, 256) G -generadorMSG - Generador multiescalaD - DiscriminadorMSD - Discriminador multiescalaGP - Penalización de gradienteSSL : reconstrucción auxiliar en discriminador (de GAN ligero)VD - Discriminador asistido por visiónVG - Generador asistido por visiónCL - Pérdida contrastiva del generadorMAL - Pérdida consciente coincidente Una ejecución saludable tendría G , MSG , D , MSD con valores que oscilan entre 0 y 10 y, por lo general, se mantienen bastante constantes. Si en algún momento después de 1k pasos de entrenamiento estos valores persisten en tres dígitos, eso significaría que algo anda mal. Está bien que los valores del generador y del discriminador caigan ocasionalmente en valores negativos, pero deberían volver a subir al rango superior.
GP y SSL deben llevarse a 0 . En ocasiones, GP puede aumentar; Me gusta imaginarlo como las redes experimentando una epifanía.
¿La clase GigaGAN ahora está equipada con? Acelerador. Puede realizar fácilmente un entrenamiento con múltiples GPU en dos pasos utilizando su CLI accelerate
En el directorio raíz del proyecto, donde está el script de entrenamiento, ejecute
$ accelerate configLuego, en el mismo directorio
$ accelerate launch train . py asegúrese de que pueda ser entrenado incondicionalmente
lea los documentos relevantes y elimine las 3 pérdidas auxiliares
muestreador unet
Obtenga una revisión del código para las entradas y salidas de múltiples escalas, ya que el documento era un poco vago.
agregar arquitectura de red de muestreo superior
hacer trabajo incondicional tanto para el generador base como para el upsampler
hacer que el entrenamiento condicionado por texto funcione tanto para la base como para el muestreador superior
hacer que el reconocimiento sea más eficiente mediante parches de muestreo aleatorios
asegúrese de que el generador y el discriminador también puedan aceptar codificaciones de texto CLIP precodificadas
hacer una revisión de las pérdidas auxiliares
agregue algunos aumentos diferenciables, técnica probada de los viejos tiempos de GAN
mover todas las proyecciones de modulación a la clase conv2d adaptativa
añadir acelerar
El clip debe ser opcional para todos los módulos y administrado por GigaGAN , con texto -> incrustaciones de texto procesadas una vez.
agregue la capacidad de seleccionar un subconjunto aleatorio de una dimensión multiescala, para mayor eficiencia
puerto a través de CLI desde ligero | stylegan2-pytorch
conectar el conjunto de datos de laion para imagen-texto
@misc { https://doi.org/10.48550/arxiv.2303.05511 ,
url = { https://arxiv.org/abs/2303.05511 } ,
author = { Kang, Minguk and Zhu, Jun-Yan and Zhang, Richard and Park, Jaesik and Shechtman, Eli and Paris, Sylvain and Park, Taesung } ,
title = { Scaling up GANs for Text-to-Image Synthesis } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { arXiv.org perpetual, non-exclusive license }
} @article { Liu2021TowardsFA ,
title = { Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis } ,
author = { Bingchen Liu and Yizhe Zhu and Kunpeng Song and A. Elgammal } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2101.04775 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Karras2020ada ,
title = { Training Generative Adversarial Networks with Limited Data } ,
author = { Tero Karras and Miika Aittala and Janne Hellsten and Samuli Laine and Jaakko Lehtinen and Timo Aila } ,
booktitle = { Proc. NeurIPS } ,
year = { 2020 }
} @article { Xu2024VideoGigaGANTD ,
title = { VideoGigaGAN: Towards Detail-rich Video Super-Resolution } ,
author = { Yiran Xu and Taesung Park and Richard Zhang and Yang Zhou and Eli Shechtman and Feng Liu and Jia-Bin Huang and Difan Liu } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2404.12388 } ,
url = { https://api.semanticscholar.org/CorpusID:269214195 }
}

