404 Base de conocimientos no encontrada
Última actualización: 28/06/2020
Recién agregado la semana pasada:
- [Embalaje y publicación de proyectos Python](# herramientas)
Tabla de contenido:
- conceptos básicos de informática
- Conceptos básicos de la teoría de la computación
- red informática
- Sistema operativo
- Estructuras de datos y algoritmos
- base de datos
- Conceptos básicos de criptografía
- Conceptos básicos de tecnología informática.
- idioma
- marco
- herramienta
- tecnología
- investigación subyacente
- Seguridad
- tecnología de seguridad
- lagunas
- seguridad web
- Pruebas de penetración
- Auditoría de código
- Seguridad de datos
- Seguridad en la nube
- herramientas de seguridad
- Escaneo de vulnerabilidades
- investigación de seguridad
- Detección APT
- Muestras maliciosas
- equipo rojo
- WAF
- Detección de URL maliciosas
- Lucha contra el tráfico de máquinas
- Detección de anomalías
- Cifras y Seguridad
- IA y seguridad
- Construcción de seguridad empresarial.
- Desarrollo seguro
- Pruebas de seguridad
- productos de seguridad
- Operación segura
- Gestión de seguridad
- Piensa seguro
- arquitectura de seguridad
- Enfrentamiento rojo y azul
- seguridad intranet
- Seguridad de datos
- Nueva tecnología y nueva seguridad
- Descripción general
- nativo de la nube
- informática confiable
- DevSecOps
- desarrollo seguro
- desarrollo personal
- Desarrollo de la industria
- datos
- sistema de datos
- Análisis de datos y operaciones.
- Análisis de datos de seguridad
- algoritmo
- AI
- sistema algorítmico
- conocimiento basico
- aprendizaje automático
- aprendizaje profundo
- aprendizaje por refuerzo
- Áreas de aplicación
- Desarrollo de la industria
- Calidad integral
- Profesión
- planificación de carrera
- pensamiento
- comunicar
- administrar
- pensar
- Cosas a tener en cuenta
- apéndice
- Personal técnico nacional destacado.
- Excelentes sitios de tecnología extranjera.
- abandonado
conceptos básicos de informática
Conceptos básicos de la teoría de la computación
Sistema operativo
- [¡¡¡¡El examen de ingreso de posgrado en informática 408 es el más completo de toda la red!!!!!] Sistema operativo de computadora Kingly
- Interrupciones y excepciones
- ¿Cómo entender la paginación y segmentación de la gestión de memoria en el sistema operativo de forma sencilla?
Granularidad, unidades lógicas de información y unidades físicas de información, longitudes indeterminadas y deterministas, direcciones bidimensionales y direcciones unidimensionales, información completa y asignación discreta de memoria. - Resumen del estado del kernel y del usuario del sistema operativo
- Recopilación de preguntas comunes de entrevistas: sistema operativo (imprescindible para todo desarrollador)
red informática
- Recopilación de preguntas comunes de entrevistas: red informática (imprescindible para todo desarrollador)
La diferencia entre TCP y UDP, protocolo de enlace de tres vías y onda de cuatro vías de TCP, el proceso después de que el navegador ingresa la URL, el tipo de solicitud del protocolo HTTP, la diferencia entre GET y POST, protocolo de resolución de direcciones ARP - Un proceso completo de solicitud de página de proceso de solicitud del navegador (navegador, HTTP) para el proceso de solicitud de respuesta incluye una serie de procesos como el protocolo de enlace de tres vías TCP, como la resolución de nombres de dominio, el inicio del protocolo de enlace de tres vías TCP, el inicio de la solicitud HTTP y el servidor respondiendo a la solicitud HTTP. y el navegador obtiene el código HTML y el navegador analiza el código HTML y solicita los recursos en el código HTML. El navegador representa la página y la presenta al usuario.
- ¿Qué significa exactamente la confiabilidad de TCP? - Respuesta de CYS - Zhihu
La confiabilidad de TCP se refiere a proporcionar servicios de transmisión de datos confiables en la capa de transporte basados en la capa IP no confiable. Esto significa principalmente que los datos no se dañarán ni se perderán, y todos los datos se transmitirán en el orden en que se enviaron. Se utilizan los siguientes mecanismos para lograr una transmisión confiable de TCP: suma de verificación (para verificar si los datos están dañados), temporizador (retransmisión si el paquete se pierde), número de secuencia (usado para detectar paquetes perdidos y paquetes redundantes), confirmación (información del receptor al remitente que un paquete se recibió correctamente y se esperaba el siguiente), acuse de recibo negativo (el receptor notifica al remitente que un paquete no se recibió correctamente), ventanas y canalización (utilizadas para aumentar el rendimiento del canal).
Estructuras de datos y algoritmos
- Algoritmo 3: la clasificación rápida más utilizada
ordenar y ordenar rápidamente La idea de la clasificación rápida es cavar agujeros y completar números + dividir y conquistar. - Una pregunta de la entrevista de Tencent: Mi taza es increíble (lo aprendí)
Método de resolución de problemas 1: método de bisección; método de resolución de problemas 2: método de intervalo de búsqueda segmentado; método de resolución de problemas 3: método basado en ecuaciones matemáticas; método de resolución de problemas 4: método de programación dinámica (aprendido), descrito por la fórmula: W(n, k) = 1 + min{max(W(n -1, x -1), W(n, k - x))}, x in {2, 3, ……,k} (n es un número de copa, k es el número de pisos) - Cómo escribir preguntas de algoritmos de forma eficaz
Las preguntas sobre LeetCode se dividen aproximadamente en tres tipos: examinar estructuras de datos: como listas vinculadas, pilas, colas, tablas hash, gráficos, intentos, árboles binarios, etc. examinar algoritmos básicos: como profundidad primero, amplitud primero, binario; búsqueda, recursividad, etc.; examinar ideas algorítmicas básicas: recursividad, divide y vencerás, búsqueda de retroceso, programación codiciosa y dinámica. - Una breve discusión sobre qué es el algoritmo de divide y vencerás (aprendido)
Problema de permutación completa, problema de clasificación por fusión, problema de clasificación rápida y problema de la Torre de Hanoi bajo la idea de dividir y conquistar. - 2018.08 En la entrevista de trabajo, el k-ésimo número más grande en la matriz desordenada, la mediana en la matriz desordenada: puntero de clasificación rápida, O (N).
- [Explicación en video] Problema número 1 de LeetCode: la suma de dos números
- Estrategias para agarrar sobres rojos en las reuniones anuales
Conceptos básicos de criptografía
- Explicación detallada de las ventajas y desventajas del cifrado simétrico y el cifrado asimétrico. El cifrado simétrico también se denomina cifrado de clave única. Los algoritmos incluyen: AES, RC4, 3DES. Es rápido y se puede utilizar cuando es necesario cifrar una gran cantidad de datos. La cantidad de cálculo es pequeña y la eficiencia es alta. Si se revela la clave secreta de una de las partes, todo el cifrado no será seguro. Cifrado asimétrico, los algoritmos incluyen RSA, DSA/DSS, lento y altamente seguro. Los algoritmos hash incluyen MD5, SHA1 y SHA256. Tres tipos de algoritmos son la base de la comunicación HTTPS .
base de datos
- Entrevista de Tencent: ¿Cuáles son las razones por las que una declaración SQL se ejecuta lentamente?
Aprendizaje complementario : motor de base de datos (InnoDB admite procesamiento de transacciones y claves externas, pero es más lento, ISAM y MyISAM usan poco espacio y memoria e insertan datos rápidamente), codificación de base de datos ( character_set_client、character_set_connection、character_set_database、character_set_results、character_set_server、character_set_system ), base de datos índice (índice de clave principal, índice agrupado e índice no agrupado) y otros puntos de conocimiento básico.
Las razones por las que una instrucción SQL se ejecuta lentamente se dividen en dos categorías: 1) Normal en la mayoría de los casos, ocasionalmente muy lenta: (1) La base de datos está actualizando páginas sucias, como rehacer Cuando el registro está lleno, es necesario sincronizarlo con el disco; (2) Se encuentran bloqueos durante la ejecución, como bloqueos de tabla y bloqueos de fila; 2) Siempre es lento: (1) No se utiliza el índice: por ejemplo; , el campo no tiene índice; debido a que el índice no se puede utilizar debido a cálculos y operaciones de funciones (2) Se seleccionó el índice incorrecto en la base de datos. Compare el número de filas escaneadas del índice agrupado con el índice de clave principal; la búsqueda directa de la tabla completa Es posible que el problema de muestreo se juzgue incorrectamente y no se realice una exploración completa de la tabla. - Esta es probablemente la solución de optimización de SQL más completa.
Conceptos básicos de tecnología informática.
idioma
- Un análisis en profundidad de los decoradores de Python en un artículo de 10.000 palabras
- Iteradores y generadores de Python3
Pitón : Los iteradores tienen dos métodos básicos: iter() y next(). Los objetos iterables como cadenas, tuplas y listas se pueden usar para crear iteradores (esto se debe a que estas clases implementan la función __iter__() internamente. Después de llamar a iter(). , se convierte en una list_iterator objeto, encontrará que se ha agregado el método __next__() . Todos los objetos que implementan __iter__ y __next__ son iteradores). El iterador es un objeto con estado. Registrará la posición de la iteración actual. obtener los elementos correctos durante la siguiente iteración. __iter__ devuelve el iterador en sí __next__ devuelve el siguiente valor en el contenedor. Generador: una función que usa rendimiento se llama generador. Cuando se llama a una función generadora, se devuelve un objeto iterador. El generador puede considerarse como un iterador. - iterador de tecnología python black, generador, decorador
- ¿Cuánto sabes sobre las funciones avanzadas de Python? comparemos
Python : función anónima lambda, la función es realizar alguna expresión u operación simple sin definir completamente la función; la función Map es una función incorporada de Python que puede aplicar funciones a elementos en varias estructuras de datos. Función incorporada de filtro Similar a la función. Función de mapa, pero solo devuelve elementos para los cuales la función aplicada devuelve True; el módulo Itertools es una colección de herramientas para procesar iteradores, que son un tipo de datos que se pueden usar en declaraciones de bucle. La función Generador es una función similar a un iterador; . - ¿Por qué utilizar el lenguaje Go? ¿Cuáles son las ventajas del lenguaje Go?
Go : Las ventajas de go y los usos de go. Las principales ventajas de go incluyen: lenguaje estático, concurrencia múltiple, multiplataforma, compilación directa en código de máquina, biblioteca estándar enriquecida, etc. Los principales usos de go incluyen programación de servidores, programación de redes, sistemas distribuidos, bases de datos en memoria y plataformas en la nube. - Serie de práctica de ginebra: introducción a Golang e instalación ambiental
Go : instalación del entorno de Go, el significado de cada carpeta después de instalar el entorno; espacio de trabajo de Go, el significado de cada carpeta en el espacio de trabajo. - Ruby-on-Rails - ¿Cuál es la diferencia entre Ruby y JRuby?
Ruby : Ruby es un lenguaje de programación. El intérprete de Ruby al que generalmente nos referimos es CRuby. CRuby se ejecuta en el entorno del intérprete de lenguaje C local. JRuby es un intérprete de Ruby implementado en Java puro.
marco
- Gin: introducción y uso del marco web Golang de alto rendimiento
Gin : es un marco de aplicación web escrito en Go. - ¿Cuál es la diferencia entre Spring Boot y Spring MVC?
Primavera -> Primavera MVC -> Arranque de primavera.
herramienta
- Comparación entre chispa y tormenta
Herramientas de tecnología de big data: tipo de computación : compare desde los aspectos del modelo de computación en tiempo real, latencia de computación en tiempo real, rendimiento, mecanismo de transacción, robustez/tolerancia a fallas, ajuste dinámico del paralelismo, etc. Spark streaming es un modelo casi en tiempo real. Recopila datos dentro de un período de tiempo y los procesa como un RDD. El retraso del cálculo en tiempo real es de segundo nivel y tiene un alto rendimiento. Admite mecanismos de transacción, pero no es lo suficientemente completo. Tiene una robustez promedio y no admite dinámicas. Ajuste el grado de paralelismo; Storm es un modelo puramente en tiempo real. Recibe y procesa un dato en tiempo real, y el rendimiento es pequeño. admite un mecanismo de transacción completo, es muy robusto y admite el ajuste dinámico del grado de paralelismo. Escenarios de aplicación : Storm se puede utilizar en escenarios donde el tiempo real puro no puede tolerar retrasos de más de 1 segundo para funciones informáticas en tiempo real que requieren mecanismos de transacción confiables y mecanismos de confiabilidad, es decir, el procesamiento de datos es completamente preciso, Storm también puede; considerar: Si también necesita ajustar dinámicamente el paralelismo de los programas informáticos en tiempo real durante los períodos pico y bajo para maximizar la utilización de recursos, también puede considerar Storm si el proyecto es puramente informático en tiempo real; para ejecutar consultas interactivas SQL en el medio, etc. Para otras operaciones, usar Storm es una mejor opción. Por otro lado, si no necesita mecanismos de transacción confiables en tiempo real puro o un ajuste dinámico del paralelismo, puede considerar la transmisión por chispa. La mayor ventaja de la transmisión por chispa es que está en la pila de tecnología ecológica de Spark. perspectiva macro del proyecto, si no solo se requiere tiempo real La informática también requiere procesamiento por lotes fuera de línea y consultas interactivas, y en el cálculo en tiempo real, también implicará procesamiento por lotes de alta latencia, consultas interactivas y otras funciones. use Spark Core para desarrollar procesamiento por lotes fuera de línea y Spark SQL para desarrollar consultas interactivas. Streaming desarrolla computación en tiempo real, se integra perfectamente y proporciona alta escalabilidad al sistema. Esta característica mejora enormemente las ventajas de Spark Streaming. Los dos marcos son buenos en diferentes escenarios de segmentación. - Tutorial de introducción a Ziyu Big Data Spark (versión Python) (más importante)
- ¿Cuáles son las diferencias y conexiones entre los sistemas de recolección de troncos Flume y Kafka? ¿Cuándo se usan respectivamente y cuándo se pueden combinar?
Herramientas de tecnología de big data - tipo middleware : Kafka puede entenderse como middleware, sistema de caché o base de datos, su función principal es mantener la estabilidad. Flume puede entenderse como la recopilación activa de datos de registro. En comparación con Kafka, es difícil promover la interfaz de modificación de aplicaciones en línea para escribir datos en Kafka. - ¿Cuáles son las ventajas y desventajas entre logstash y flume y para qué escenarios son adecuados?
Herramientas de tecnología de big data: tipo de agente : según los requisitos, tanto logstash como flume existen como agentes. Logstash tiene más complementos y mejores productos de soporte, como elasticsearch, pero el lenguaje de desarrollo de logstash es ruby y el entorno operativo es. JRuby además, los datos transmitidos pueden perderse; hay un mecanismo dentro de Flume para garantizar que una cierta cantidad de datos se transmita sin pérdida. El lenguaje de desarrollo de Flume es Java, que es fácil de desarrollar. que la jvm ocupa mucha memoria. - Lista de teclas de acceso directo de Mac
MAC : teclas de acceso directo básicas: capturas de pantalla, en aplicaciones, procesamiento de texto, en buscador, en navegadores, teclas de acceso directo para inicio y apagado de MAC. - Hojas de comandos de Git de uso común
Git : Almacén remoto-"Almacén local->Área de preparación-"Espacio de trabajo, git add., git commit -m mensaje, git push. - git-lfs
Git-lfs : herramienta de extensión de carga de archivos grandes de git. - paquete pcap de análisis estadístico tshark
- [Embalaje y publicación de proyectos Python](# herramientas)
Nota : 1. setup.py: long_description y long_description_content_type (tenga en cuenta los problemas de representación de los formatos md y rst). 2. manifest.in frente a gitignore. 3. Léame.primero frente a Léame.md. 4. .pypirc frente a gitconfig. 5. Subir python setup.py bdist_wheel.
tecnología
- Decodificación y xss ( hay un
\u72 en el texto original "después de la codificación de entidad html" debería ser:
Secuencia de decodificación de tecnología del navegador : La decodificación del navegador implica principalmente dos partes: motor de renderizado y analizador js. Orden de decodificación: la decodificación se realiza en cualquier entorno. El orden de decodificación es: la codificación correspondiente al entorno más externo se decodifica primero. Por ejemplo: en <a href=javascript:alert(1)>click</a> alert(1) está en el entorno html->url->js. 1. Haga clic en utiliza la codificación Unicode e, que no se puede decodificar en entornos html o URL. Solo se puede decodificar en el carácter e en el entorno js, por lo que no aparecerá ninguna ventana emergente.
2. Haga clic en utiliza codificación de URL. Antes de ejecutar js, la URL decodifica %65, de modo que cuando se inicie el motor js, verá la alerta completa(1).
3. Haga clic en la decodificación de entidad html para ejecutarla primero.
4. Haga clic en En el proceso de decodificación de URL, JavaScript no se considerará un pseudoprotocolo y se producirán errores.
5. Haga clic en htmlparser para ejecutarlo antes que el analizador de JavaScript, por lo que el proceso de análisis consiste en decodificar primero los caracteres de htmlencode y luego ejecutar el evento de JavaScript.
El orden de decodificación del navegador es la base para omitir XSS . - La relación entre dockerfile y docker-compose
Tecnología Docker : la relación entre archivos y carpetas. - ¿Cuál es la diferencia entre dockerfile y docker-compose?
Tecnología Docker : Docker-compose sirve para orquestar contenedores. - ¿Qué es una máquina bastión?
Tecnología de host bastión : define una entrada para acceder al clúster y facilita el control y monitoreo de permisos. - ¿Desde qué aspectos hay que analizar la viabilidad de un producto?
Análisis de viabilidad : La viabilidad del producto se divide en: viabilidad técnica, viabilidad económica y viabilidad social. Entre ellas, me centro en la viabilidad técnica. La viabilidad técnica se mide principalmente a partir de la comparación de funciones de la competencia, riesgos técnicos y métodos para evitarlos, facilidad de uso y umbral de usuario, dependencia del entorno del producto, etc. - ¿Qué roles juegan Nginx y Gunicorn en el servidor?
Servidor de aplicaciones : escenario de implementación de Nginx: equilibrio de carga (los marcos como tornado solo admiten un solo núcleo, por lo que la implementación multiproceso requiere equilibrio de carga inverso. gunicorn en sí es multiproceso y no lo necesita), soporte de archivos estáticos, presión anti-concurrencia , control de acceso adicional. - Wikipedia: Kerberos
Kerberos : Descripción básica, contenido del protocolo y proceso específico de Kerberos. - La relación entre dockerfile y docker-compose
Tecnología Docker : la relación entre archivos y carpetas. - ¿Cuál es la diferencia entre dockerfile y docker-compose?
Tecnología Docker : Docker-compose sirve para orquestar contenedores. - ¿Qué es una máquina bastión?
Tecnología de host bastión : define una entrada para acceder al clúster y facilita el control y monitoreo de permisos. - ¿Desde qué aspectos hay que analizar la viabilidad de un producto?
Análisis de viabilidad : La viabilidad del producto se divide en: viabilidad técnica, viabilidad económica y viabilidad social. Entre ellas, me centro en la viabilidad técnica. La viabilidad técnica se mide principalmente a partir de la comparación de funciones de la competencia, riesgos técnicos y métodos para evitarlos, facilidad de uso y umbral de usuario, dependencia del entorno del producto, etc. - ¿Qué roles juegan Nginx y Gunicorn en el servidor?
Servidor de aplicaciones : escenario de implementación de Nginx: equilibrio de carga (los marcos como tornado solo admiten un solo núcleo, por lo que la implementación multiproceso requiere equilibrio de carga inverso. gunicorn en sí es multiproceso y no lo necesita), soporte de archivos estáticos, presión anti-concurrencia , control de acceso adicional. - Wikipedia: Kerberos
Kerberos : Descripción básica, contenido del protocolo y proceso específico de Kerberos. - ¿Qué es la arquitectura de microservicios**?
- ¿Qué es la malla de servicio (malla de servicio)?
Arquitectura de microservicios : Por qué: ¿Por qué utilizar una malla de servicios? Bajo la arquitectura tradicional de aplicaciones web de tres niveles MVC, la comunicación entre servicios no es complicada y se puede administrar dentro de la aplicación. Sin embargo, en los sitios web complejos a gran escala de hoy, las aplicaciones individuales se descomponen en numerosos microservicios. complejo. Qué: La malla de servicios es la capa de infraestructura para la comunicación entre servicios. Se puede comparar con TCP/IP entre aplicaciones o microservicios. Es responsable de las llamadas de red, la limitación de corriente, la interrupción de circuitos y el monitoreo entre servicios. Características de Service Mesh: capa intermedia para comunicación entre aplicaciones, proxy de red liviano, independiente de la aplicación, reintentos/tiempos de espera desacoplados de la aplicación, monitoreo, seguimiento y descubrimiento de servicios. Actualmente, el software de código abierto más popular es Istio y Linkerd, los cuales pueden integrarse en el entorno Cloud Native kubernetes. - El actualizador falla si no se ejecuta como administrador, incluso en una instalación de usuario
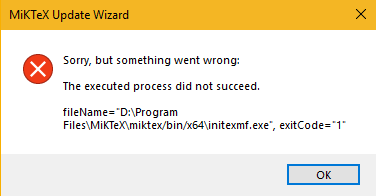
LaTeX : MiKTeX (problema de registro y problema de derechos de administrador) + TeXnicCenter (no se puede generar un problema de pdf, establezca la ruta de ejecución de Adobe en Build en AcroRd32.exe genuino) + Adobe Acrobat Reader DC, y luego use la versión descifrada de Adobe Acrobat DC para convertir a otros formatos. - Principio HTTPS y proceso de interacción.
HTTPS : HTTPS requiere un protocolo de enlace entre el navegador y el sitio web antes de transmitir datos. Durante el proceso de protocolo de enlace, se confirmará la información de la contraseña utilizada por ambas partes para cifrar los datos transmitidos. Obtenga la clave pública -> El navegador genera una clave secreta aleatoria (simétrica) -> Utilice la clave pública para cifrar la clave secreta simétrica -> Enviar la clave secreta simétrica cifrada -> comunicación de texto cifrado cifrada por la clave secreta simétrica. Todo el proceso de comunicación HTTPS utiliza cifrado simétrico, cifrado asimétrico y algoritmos HASH . - Política del mismo origen del navegador
Tecnología del navegador : La política del mismo origen es la función de seguridad principal y más básica del navegador. La política del mismo origen se define como: protocolo/host/puerto. - Nueve principios de implementación entre dominios (versión completa)
Tecnología de navegador : soluciones de solicitud entre dominios: JSONP (vulnerabilidades que dependen de etiquetas de script sin restricciones entre dominios), CORS (compartición de recursos entre dominios), postMessage, websocket, proxy de middleware de nodo, proxy inverso de nginx, windows.name+iframe , ubicación.hash+iframe, documento.dominio+iframe.
CORS admite todo tipo de solicitudes HTTP y es la solución fundamental para solicitudes HTTP entre dominios. JSONP solo admite solicitudes GET. La ventaja es que admite navegadores antiguos y puede solicitar datos de sitios web que no admiten CORS. Ya sea el proxy de middleware de Node o el proxy inverso de nginx , la razón principal es no imponer restricciones al servidor a través de la política del mismo origen. En el trabajo diario, las soluciones entre dominios más utilizadas son CORS y el proxy inverso nginx. - ¿Cómo utilizar el entorno virtual Python en Jupyter Notebook?
Anaconda : instalar complementos, conda instalar nb_conda - Dado que existen solicitudes HTTP, ¿por qué utilizar llamadas RPC? - La respuesta del hermano Yi.
RPC : Restful VS RPC. RPC incluye: proxy inverso, serialización y deserialización, comunicación (HTTP, TCP, UDP), manejo de excepciones.
investigación subyacente
Un breve análisis del proceso de la biblioteca de solicitudes de Python.
Python solicita la implementación de la biblioteca : socket->httplib->urllib->urllib3->requests. El proceso de llamada interno de request.get: request.get->requests()->Session.request->Session.send->adapter.send->HTTPConnectionPool(urllib3)->HTTPConnection(httplib).
1、socket:是TCP/IP最直接的实现,实现端到端的网络传输
2、httplib:基于socket库,是最基础最底层的http库,主要将数据按照http协议组织,然后创建socket连接,将封装的数据发往服务端
3、urllib:基于httplib库,主要对url的解析和编码做进一步处理
4、urllib3:基于httplib库,相较于urllib更高级的地方在于用PoolManager实现了socket连接复用和线程安全,提高了效率
5、requests:基于urllib3库,比urllib3更高级的是实现了Session对象,用Session对象保存一些数据状态,进一步提高了效率
Análisis de los principios de XGBoost y su implementación subyacente (aprendido)
XGBoost : Comprender desde la perspectiva de la puntuación del árbol (función objetivo: función de pérdida (expansión de segundo orden) + término regular), la estructura del árbol (decisión dividida (clasificación previa)).
Comprensión profunda del algoritmo de optimización del histograma Lightgbm
Lightgbm : en comparación con la clasificación previa, lgb utiliza un histograma para manejar la división de nodos y encontrar el punto de división óptimo. Idea de algoritmo: convierta los valores de las características en valores de bin por adelantado antes del entrenamiento, es decir, cree una función por partes para el valor de cada característica y divida los valores de todas las muestras de esta característica en un segmento determinado (bin) Y, finalmente, los valores de las características se convierten de valores continuos a valores discretos. Los histogramas también se pueden utilizar para la aceleración diferencial. La complejidad de calcular el histograma se basa en la cantidad de cubos.
Análisis del código fuente de preprocesamiento de texto de Keras
Keras - preprocesamiento de texto : 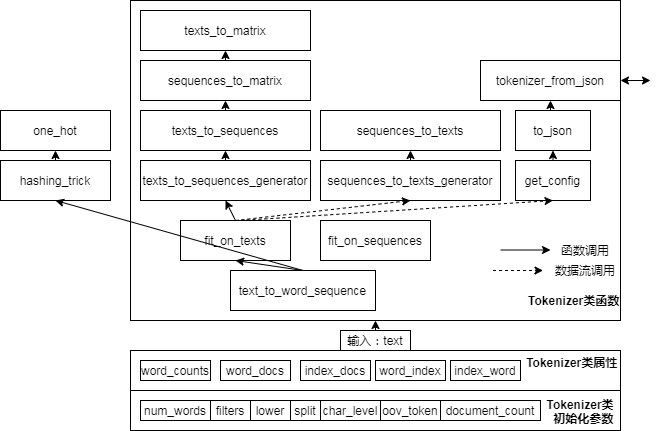
Análisis del código fuente de preprocesamiento de secuencia de Keras
Palabra2Vec
- Comprender el modelo Skip-Gram de Word2Vec
- Implementación del modelo Skip-Gram basado en TensorFlow: artículo de Tian Yusu
- Tutorial de Word2Vec: el modelo Skip-Gram
- Tutorial de Word2Vec, parte 2: muestreo negativo
- Tutorial de incrustación de palabras de Word2Vec en Python y TensorFlow
- análisis del código fuente de word2vec_basic tensorlflow
- Un tutorial de Word2Vec Keras
- keras_word2vec@aventuras-en-ml-code
Seguridad
tecnología de seguridad
lagunas
- Compilación de la carga útil de la biblioteca de vulnerabilidades de Wuyun y el complemento auxiliar Burp
- boy-hack/wooyun-carga útil
- La perspectiva de un investigador sobre la investigación de la vulnerabilidad en la década de 2010
Investigación de vulnerabilidades: estado actual y tendencias de la investigación de vulnerabilidades en los últimos 10 años : 1. En la era posterior a la PC, la integridad del flujo de control se ha convertido en un nuevo mecanismo de protección básico para la seguridad del sistema. 2. Sorprendentes características de seguridad del hardware y vulnerabilidades de seguridad del hardware. 3. Vino nuevo en botellas viejas: el diseño seguro de los dispositivos móviles permite adelantar en las curvas. 4. La batalla por las entradas a la red se está intensificando. Las entradas a la red incluyen: navegadores, coprocesadores WiFi, bandas base, Bluetooth, enrutadores, dispositivos de mensajería instantánea, software social, clientes de correo electrónico, PC y servidores tradicionales. 5. Aún es necesario mejorar la minería y explotación automatizadas de vulnerabilidades.
seguridad web
- Un artículo para brindarle una comprensión profunda de las vulnerabilidades: vulnerabilidades XXE
Vulnerabilidad XXE : El principio de XXE: llamar a entidades externas, la utilización de XXE: usar entidades generales, entidades paramétricas, entidades externas, entidades internas para leer archivos, detección de puerto y host de intranet, RCE de intranet (se requiere el soporte de la extensión esperada en PHP) ) - Técnicas de inyección sin comas de MySQL
Ataques de inyección : inyección SQL, inyección XML (un lenguaje de marcado que representa estructuralmente datos a través de etiquetas), inyección de código (clase de evaluación), inyección CRLF (rn). Inyección de MySQL: use comentarios para omitir espacios, use paréntesis para omitir espacios, use símbolos como %20 %0a para reemplazar espacios en la consulta de unión, use unión para omitir el filtrado de comas, select id,ip from client_ip where 1>2 union select * from ( (select user())a JOIN (select version())b ); Utilice select case when(条件) then 代码1 else 代码2 end para omitir el filtrado de comas, insert into client_ip (ip) values ('ip'+(select case when (substring((select user()) from 1 for 1)='e') then sleep(3) else 0 end)); - [CRLF Utilización de vulnerabilidades de inyección y análisis de ejemplos]([https://wooyun.js.org/drops/CRLF%20Injection%E6%BC%8F%E6%B4%9E%E7%9A%84%E5% 88%A9%E7%94%A8%E4%B8%8E%E5%AE%9E%E4%BE%8B%E5%88%86%E6%9E%90.html](https://wooyun.js .org/drops/CRLF Utilización de vulnerabilidades de inyección y análisis de ejemplo.html))
CRLF es la abreviatura de "retorno de carro + avance de línea" (rn). El encabezado HTTP y el cuerpo HTTP están separados por dos CRLF. La inyección CRLF también se denomina división de respuesta HTTP o HRS para abreviar. X-XSS-Protection:0 desactiva la estrategia de protección del navegador para el filtrado XSS reflejado. - Explotación de vulnerabilidad SSRF y combate getshell (seleccionado)
- Resumen de varios métodos para evitar el filtrado (restricciones de IP) en vulnerabilidades SSRF
SSRF : use salto 302 (xip.io, dirección corta, servicio autoescrito); enlace de DNS (evitando las restricciones de IP; cambie la forma en que se escribe la dirección IP; use el problema de analizar la URL: http://[email protected]/ a través de varios protocolos no HTTP - Resumen de los métodos de derivación de la SSRF
SSRF : use @; use una dirección corta; use el nombre de dominio especial xip.io; use la resolución DNS (establezca un registro en el nombre de dominio; use el período de uso); - ThinkPHP 5.0.0 ~ 5.0.23 Análisis de vulnerabilidad RCE
- Un breve análisis de la codificación de caracteres y la inyección SQL en la auditoría de caja blanca (excelente, aprendido)
Ataque de inyección basado en codificación de caracteres : un carácter chino codificado con gbk ocupa 2 bytes y un carácter chino codificado con utf-8 ocupa 3 bytes. La inyección amplia de bytes aprovecha las características de mysql. Cuando mysql usa la codificación gbk, pensará que dos caracteres son un carácter chino (bajo gbk, el código ascii anterior debe ser mayor que 128 para alcanzar el rango de caracteres chinos; la codificación rango de valores de gb2312: bit alto 0xA1-0xF7 , bit bajo 0xA1-0xFE y 0x5c , no está en el rango de bits bajos, por lo que 0x5c no es la codificación en gb2312, por lo que no se consumirá esta idea a todas las codificaciones de varios bytes, siempre que el rango de bits bajos contenga la codificación de 0x5c . se puede realizar una inyección de bytes amplia). Plan de defensa uno: mysql_set_charset+mysql_real_escape_string , teniendo en cuenta el conjunto de caracteres actual de la conexión. Plan de defensa dos: Establecer character_set_client en binary (binario), SET character_set_connection=gbk, character_set_results=gbk,character_set_client=binary . Cuando nuestro MySQL recibe los datos del cliente, pensará que su codificación es character_set_client , y luego la cambiará a la codificación de character_set_connection , y luego ingresará la tabla y el campo específicos, y luego los convertirá a la codificación correspondiente al campo. Luego, cuando se generen los resultados de la consulta, se convertirán de la codificación de tabla y campo a la codificación character_set_results y se devolverán al cliente. Por lo tanto, si configuramos character_set_client en binary , no habrá ningún problema de byte ancho o multibyte. Todos los datos se transfieren en formato binario, lo que puede evitar efectivamente la inyección de caracteres anchos. También pueden ocurrir problemas al llamar a iconv después de la defensa. Cuando se usa iconv para convertir utf-8 a gbk, el método de utilización es錦' , porque su codificación utf-8 es 0xe98ca6 y su codificación gbk es 0xe55c , que finalmente se convierte en %e5%5c%5c%27 , dos %5c son ' son un número impar, ' escapará del límite. ¿Por qué no錦' utilizar este método? De acuerdo con las reglas de codificación utf-8, (0x0000005c) no aparecerá en la codificación utf-8, por lo que se informará un error. - Problemas de seguridad causados por las sesiones de clientes.
- Una visión de DAST, SAST e IAST en un artículo: una breve discusión sobre la comparación de tecnologías de prueba de seguridad de aplicaciones web (aprendida)
- Hablar sobre SAST/IDAST/IAST
- Introducción a los métodos de conexión PHP y cómo atacar PHP-FPM
- Una solicitud GET para obtener la bandera——Resumen final de PUBG (WEB 2) de XCTF 2018
Pruebas de penetración
- Un conjunto de preguntas prácticas de entrevista de trabajo sobre pruebas de penetración Funciones de ejecución de código:
eval、preg_replace+/e、assert、call_user_func、call_user_func_array、create_function Funciones de ejecución de comandos: system、exec、shell_exec、passthru、pcntl_exec、popen、proc_open etiqueta excepto el atributo onerror; Además, ¿hay alguna otra forma de obtener la ruta del administrador? src especifica un archivo de script remoto para obtener el referente. - Un conjunto de preguntas prácticas para una entrevista de trabajo sobre pruebas de penetración, ¿lo conoces?
- Mi experiencia en entrevistas, pruebas de penetración.
Auditoría de código
- Auditoría de código Java: avance capa por capa
Seguridad de datos
- NO.27 Charla sobre seguridad de datos Tecnología y era de big data, los datos son el activo principal de muchas empresas . Los límites de seguridad tradicionales están borrosos, debemos asumir que nuestros límites han sido traspasados y, al mismo tiempo, tener una defensa en profundidad; capacidades para proteger la seguridad de la información. Por lo tanto, al tiempo que fortalecemos los métodos de seguridad tradicionales, debemos centrar la seguridad directamente en los datos en sí. Esto es lo que hace la seguridad de los datos. Antes de hacer esto, hay una premisa: debemos saber que la seguridad todavía sirve al negocio (en la mayoría de los casos de seguridad empresarial, negocio > seguridad), por lo que se deben sopesar la seguridad y la usabilidad. Actualmente, las medidas comúnmente utilizadas por las empresas incluyen principalmente: clasificación de datos, gestión del ciclo de vida de los datos, desensibilización y cifrado de datos, y prevención de fuga de datos.
- Construcción del sistema de seguridad de datos empresariales de Internet.
Seguridad en la nube
- Seguridad en la nube, ¿qué es exactamente?
Hay tres direcciones principales de investigación en seguridad en la nube: seguridad informática en la nube, nubeización de la infraestructura de seguridad y servicios de seguridad en la nube. La colaboración en la seguridad de los datos también se menciona en las tendencias de desarrollo futuro de la seguridad en la nube, lo que indica que no importa cuál sea el escenario, los datos son el foco de la seguridad. Los servicios de seguridad en la nube pueden verse como Chefs Cooking (PPT de CDXY), computación en la nube (energía), algoritmos (herramientas), datos (materias primas), ingenieros (chefs), qué tipo de arroz se puede hacer (servicios de seguridad que se pueden proporcionó) ) - El futuro de la seguridad en la nube (artículo en profundidad)
Ideas de escritura : Tendencias del mercado de seguridad en la nube -"Productos de seguridad en la nube convencionales (productos de seguridad de plataforma en la nube y productos de seguridad de seguridad en la nube de terceros CWPP, CSPM, CASB) -" La combinación de seguridad en la nube y SD -wan -"nativo de la nube (DevOps, continuo entrega, microservicios, contenedores) Seguridad.
otro
- Información de seguridad: laboratorios empresariales, comunidades de seguridad, equipos de seguridad, herramientas de seguridad, etc.
herramientas de seguridad
Exploración de vulnerabilidad
- Escaneo de vulnerabilidad utilizando el modo XRAY proxy
investigación de seguridad
Detección apta
- Detección APT basada en el aprendizaje automático
Modelo de detección APT : este documento propone un modelo de detección APT al detectar múltiples enlaces en el ciclo de vida APT, correlacionar los eventos de alarma en cada enlace y usar el aprendizaje automático para entrenar el modelo de detección. Es ligeramente similar a mi idea. El propósito de esto es describir completamente el conjunto de eventos de seguridad en un escenario Apt, reducir la tasa de falsos positivos, mejorar la precisión y evitar los problemas de negativos perdidos y falsos positivos causados por la detección tradicional de un solo enlace APT. Sin embargo, también hay algunos problemas en este artículo, como la falta de fuentes de datos APT.
Muestras maliciosas
- Use el aprendizaje automático para detectar el tráfico externo malicioso HTTP (excelente)
Detección de tráfico externo HTTP malicioso : Idea general : 1. Recopilación de datos , ejecutar muestras maliciosas en la caja de arena, recopilar tráfico malicioso, distinguir manualmente el tráfico malicioso del tráfico blanco y luego clasificar el tráfico malicioso en familias en función de la inteligencia de amenazas. 2. Análisis de datos (ingeniería de características): para la similitud del tráfico externo malicioso de la misma familia, puede considerar usar un algoritmo de agrupación para agrupar el tráfico de la misma familia en una categoría, extraer sus puntos en común, formar una plantilla y luego Use la plantilla para detectar el tráfico desconocido. 3. Algoritmo: Fase de entrenamiento : Extraer tráfico de conexión externa HTTP ---> Extraer Campos de encabezado de solicitud ---> Generalización ---> Cálculo de similitud ( ponderación específica del campo en el encabezado de solicitud y luego calcular la similitud ) ---> jerárquico Clustering ---> Generar plantilla de tráfico externo malicioso (la unión de este campo en el clúster se usa como el valor de este campo en la plantilla). Etapa de detección : Tráfico externo HTTP desconocido ---> Campos de encabezado de solicitud de extracción ---> Generalización ---> coincidir con plantillas maliciosas ---> Determinar si la similitud excede el umbral (determinación del umbral) - Construcción de la plataforma de análisis automatizado de malware de cuco
- Entorno de análisis de malware del cuco
- Jugando con cuco
Cuco Sandbox: Encontré muchas trampas en el proceso de construcción del entorno de análisis de muestras maliciosas de Cuco. PY a la carpeta de inicio; En el host físico, Windows 10 está instalado con VMware, VMware está instalado con Ubuntu16, Ubuntu16 se instala con VirtualBox y Cuckoo Server, y VirtualBox se instala con Windows7 como agente. - Resumen de recursos de análisis de muestras maliciosas
Lucha contra el tráfico de máquinas
- Informe Bad Bot 2018
Traffic de la máquina de combate : la confrontación de seguridad ha promovido la evolución de los métodos de ataque y ha entrado en la etapa de confrontación automatizada. El tráfico de la máquina se genera, mientras que los rastreadores maliciosos y otros rastreadores maliciosos imitan las solicitudes de usuarios normales para generar el tráfico de máquinas maliciosas. sin cabeza. navegador, más avanzados pueden simular movimientos y clics del mouse. El tráfico de la máquina se puede distinguir en función del entorno de red (ISP de Amazon, centros de datos, proveedores de alojamiento global), las herramientas utilizadas (los navegadores del tráfico de máquinas les gusta disfrazarse de Chrome, Firefox, Internet Explorer, Safari) y si imitan humanos interacciones, como trayectorias y clics del mouse. Una vez que detectan nuestros intentos de detenerlos, los APB de tráfico de máquinas maliciosas avanzadas se vuelven persistentes y adaptables, realizando transformaciones multimodales. Defensa: Comprenda nuestras operaciones y objetivos enemigos. Suprima el UA/navegador; intentos de inicio de sesión fallidos;
Detección de URL maliciosa
- Detección de URL maliciosas
Después de leer algoritmos de seguridad nacionales y materiales de análisis de datos de seguridad hasta el final, comenzaron a centrar su atención en países extranjeros y rastrear el proceso de desarrollo de las aplicaciones de aprendizaje automático extranjero en el campo de la seguridad de la red. Tomando la detección de URL como ejemplo, se pueden derivar muchos escenarios aplicables, incluida la detección de páginas web maliciosas, actividades de comunicación maliciosa y software web malicioso. - Más allá de las listas negras: aprendiendo a detectar sitios web maliciosos de URL sospechosas
Use la detección de URL maliciosa como método complementario para la detección de páginas web maliciosas. Datos: Muestras de URL en blanco y negro de código abierto, sin características especiales: características léxicas y características basadas en el host, características promedio, análisis y comparación de características de cada subcategoría, modelos promedio: regresión logística, SVM, Bayes Naive, Bayes, No hay características, análisis y comparación de cada subcategoría Este modelo no tiene características; Después de todo, era un artículo escrito hace diez años. - Identificación de URL sospechosas: una aplicación de aprendizaje en línea a gran escala
- Explotación de la covarianza de características en el aprendizaje en línea de alta dimensión
equipo rojo
- Práctica y pensamiento del equipo rojo de 0 a 1 (aprendido)
Definición del equipo rojo ---> El objetivo del equipo rojo (aprender y usar TTP de atacantes reales conocidos para atacar, evaluar la efectividad de las capacidades de defensa existentes, identificar debilidades en el sistema de defensa y proponer contramedidas específicas, usar ataques simulados reales y efectivos para evaluar el impacto comercial potencial causado por problemas de seguridad) ---> quién necesita equipo rojo ---> Cómo funciona el equipo rojo (composición básica: reserva de conocimiento, infraestructura, capacidades de investigación técnica; proceso de trabajo: simulación de ataque de etapa completa, ataque escenificado simulación; Cuantificación y evaluación del equipo (cobertura de TTP conocidos, tasa de detección/tiempo de detección/etapa de detección, tasa de bloqueo/tiempo de bloqueo/etapa de bloqueo) ---> El crecimiento y mejora del equipo rojo (capacitación en el entorno de simulación, análisis de vulnerabilidad e investigación técnica, comunicación externa y compartiendo) - Resumen de la organización ATT y CK APT TTPS
- Resumen de tecnología de ataque de plataforma completa ATT & CK
- Resumen de los informes de análisis de la organización real APT
WAF
- Discusión técnica |
- Use la transferencia fragmentada para derrotar a todos los WAFS
- Bustar WAF desde el nivel de protocolo HTTP y el nivel de base de datos
- Cuatro niveles de ataque de WAF e investigación de defensa: Bypass WAF
- Algún conocimiento sobre WAF
Detección de anomalías
- N Métodos de detección de anomalías (erudito)
Una de las dificultades en la detección de anomalías es la falta de la verdad del suelo. Desde series de tiempo (promedio móvil, año tras año y mes a mes, STL+GESD), estadísticas (distancia de Mahalanobis, Placa de caja), ángulo de distancia (KNN), método lineal (descomposición de matriz y reducción de dimensionalidad PCA), distribución (Entropía relativa KL detecta anomalías de ángulos como divergencia, prueba de chi-cuadrado), árboles, gráficos, secuencias de comportamiento y modelos supervisados (que pueden combinar automáticamente más características, como GBDT). - Algoritmo de detección de anomalías de aprendizaje automático (1): bosque de aislamiento
- Algoritmo de detección de anomalías de aprendizaje automático (2): factor atípico local
- Algoritmo de detección de anomalías de aprendizaje automático (3): análisis de componentes principales
- ¿Qué es una máquina vectorial de soporte de una clase (una clase SVM)?
- Aislamiento de algoritmo de detección de anomalías
- Minería de anomalía, bosque de aislamiento
- Primer intento de detección de anomalías
- Monitoreo inteligente de anomalías de datos de series de tiempo impulsadas por el aprendizaje automático
- Excepciones de minería en registros de operación y mantenimiento masivos
- Identificación de preprocesamiento de datos-fuera
- Un estudio preliminar sobre la aplicación de la detección anormal y el aprendizaje supervisado en la detección de anomalías
- ¿Cuáles son los algoritmos comunes de "detección de anomalías" en la minería de datos? - Respuesta ajustada - Zhihu
1. Introducir algoritmos y experimentos de detección de anomalías no supervisadas; 1.1) Estadísticas y modelos de probabilidad: distribución de hipótesis y pruebas de hipótesis, undimensional y multidimensional, independencia de características y correlación de características, distancia euclidiana y distancia de Mahalanobis; La distancia euclidiana y la distancia de Mahalanobis, PCA y PCA suave y SVM de una clase; 1.2) Verifique la conexión entre algoritmos desde el límite de decisión del gráfico de resultados experimentales. 2.1) La comparación de los efectos de detección de modelos, el bosque de aislamiento y KNN funcionan de manera estable y otros modelos basados en la medición de la distancia se ven muy afectados por las dimensiones de los datos. 3.1) El volumen de datos y las dimensiones de datos también tienen un impacto en la sobrecarga de algoritmos. El aislamiento es más adecuado para espacios de alta dimensión. 4.1) Los resultados experimentales traen ideas para la selección del modelo de detección de anomalías: KNN y MCD para conjuntos de datos pequeños y medianos son relativamente estables, y el bosque de aislamiento para conjuntos de datos medianos y grandes es estable y la eficiencia del modelo a menudo se opone, como Como PCA y MCD; 4.2) Para un nuevo problema de detección de anomalías, puede seguir los siguientes pasos para analizar: A. Comprender los datos, la distribución de datos y la distribución de anomalías, y seleccionar un modelo basado en supuestos; , si es así, debe ser desperdiciado; Algoritmo de selección de puntos; Las características de las anomalías a menudo están cambiando. Las reglas manuales siguen siendo muy útiles, no intente reemplazar las reglas existentes con estrategias de datos en un solo paso. - Peuring |
- Aislamiento de detección de anomalías Bosque y visualización
- Detección de anomalías con pronóstico de series de tiempo
Figuras y seguridad
- Figura/Louvain/DGA La charla aleatoria El gráfico lleva información topológica, y la información topológica puede considerarse como una dimensión característica. El punto clave del algoritmo de Louvain es el peso de los bordes del gráfico, que requiere un estudio especial en ataques específicos y escenarios de defensa. de IP que han visitado los nombres de dominio A y B al mismo tiempo. Master CDXY implementó esta lógica usando SQL.
- Algoritmo de descubrimiento de la comunidad-A Estudio preliminar sobre el algoritmo de desarrollo rápido (Louvian)
- Un análisis DGA DGA DGA Odyssey DGA conducido
- Graph Computing ha aprendido sobre la implementación de la seguridad básica: la implementación de gráficos en detección de intrusos, respuesta a la intrusión, inteligencia de amenazas y UEBA. Detección de intrusión: la dirección de desarrollo de la detección de intrusos empresariales y el historial de desarrollo de las capacidades de análisis de datos. Respuesta a la intrusión: Problemas resueltos durante el proceso (integridad y riqueza de los registros, análisis de correlación de datos masivos y ventanas de mucho tiempo, construcción en tiempo real y consulta de gráficos, interacción y visualización). UEBA: El desarrollo de la confianza nativa de la nube y la confianza cero -"segura por defecto -" obteniendo credenciales para servicios de confianza, "cadena de suministro" ataques -"detección de intrusiones basadas en la autenticación -" Análisis de comportamiento y perfiles de comportamiento. Resumen: Problemas comerciales -> Problemas de datos.
AI y seguridad
- Compilación de materiales de aprendizaje para escenarios de seguridad, algoritmos de seguridad basados en IA y análisis de datos de seguridad
- Hacia la privacidad y la seguridad de los sistemas de aprendizaje profundo: una encuesta
Superficie de ataque de seguridad de la IA : en términos de datos y modelos en la fase de entrenamiento y la fase de prueba, los ataques incluyen envenenamiento por datos y muestras adversas, extracción de modelo e inversión del modelo, etc. - Detección inteligente de amenazas: plataforma de detección de aprendizaje automático SOC basada en chispas
Construcción de seguridad empresarial
Desarrollo seguro
- Construcción de la plataforma de detección automatizada de escaneo de seguridad (caja negra web)
- Llevarlo a leer el análisis del código fuente de Kunpeng del artefacto
Pruebas de seguridad
- Planificar para establecer un sistema de control de riesgos y advertencia temprana
Control de riesgo de seguridad empresarial : detecte rápidamente las anomalías y defina con precisión los riesgos. Descubra fragmentos y entidades anormales a través de cambios en los indicadores de núcleo, y descubra todas las entidades bajo el clúster anormal a través de métodos de agrupación; - El viaje de cambiar de seguridad tradicional al campo del control de riesgos y discutir las tendencias en la industria negra y la industria de control de riesgos
Control de riesgo comercial : la lucha en el campo del control de riesgos se está volviendo cada vez más feroz. . - Preparación de la entrevista del ingeniero modelo de control de riesgos-Capítulo técnico
- Práctica del modelo de control de riesgos: competencia de algoritmo de control de riesgos "Magic Mirror Cup"
- Método de identificación del usuario de control de riesgos
- Github: Sladesha
- Múltiples algoritmos identifican usuarios anormales como el relleno de credenciales y el fraude de cupón
- Experimento de comunicación encubierta del túnel DNS intenta reproducir la detección del modo de pensamiento de vectorización de características
- HIDS para la construcción de seguridad empresarial
- Asegurar la seguridad de IDC: diseño de arquitectura de clúster HIDS distribuido
- Agentes de código abierto de Dianrong Hids --- Un sistema de ocultaciones ligeras
- Construcción de seguridad empresarial: algunas ideas sobre el diseño del sistema HIDS basado en agentes
Sistema de detección de intrusos de detección de intrusos : vale la pena aprender la práctica sistemática de Meituan. A partir de la descripción de la demanda, el gerente de producto presenta la demanda -> analiza la demanda, resume las características de que la arquitectura del producto debe cumplir con -> dificultades técnicas, analiza los desafíos técnicos encontrados -> Diseño de arquitectura y selección de tecnología -> Hids Cluster HIDS Diagrama de arquitectura -> Selección de lenguaje de programación-> Implementación del producto. - Método de detección de túnel ICMP e implementación basada en el análisis estadístico
productos de seguridad
- Recoja algunos excelentes proyectos de seguridad de código abierto para ayudar a los profesionales de seguridad de la parte A a construir capacidades de seguridad empresarial (aprendidas) productos de seguridad de código abierto : incluyendo gestión de activos, desarrollo de seguridad, auditoría automatizada de código, operación y mantenimiento de seguridad, host de bastión, HID y análisis de tráfico de red , Honeypot, WAF, disco de nube empresarial, sistema de sitios web de phishing, monitoreo de GitHub, control de riesgos, gestión de vulnerabilidades, SIEM/SOC.
Operación segura
- Lo que entiendo sobre las operaciones de seguridad
Las empresas pagan la producción, no el conocimiento . Las operaciones de seguridad están orientadas a la resolución de problemas. Responsabilidades principales y requisitos de habilidad para las operaciones de seguridad, I + D, operación y antecedentes de mantenimiento; - Hablemos sobre el por qué de operaciones seguras : se visualizan los riesgos de seguridad y la apariencia está expuesta;
El que y cómo de operaciones seguras: confiscar las principales contradicciones y contradicciones secundarias y hacer todo lo posible para resolverlas.
Gestión de seguridad
- El lanzamiento del árbol de habilidades de construcción de seguridad empresarial V1.0 incluye seis partes: descripción, concepto de seguridad, gobernanza de seguridad, habilidades generales, habilidades profesionales y recursos de alta calidad.
Piensa seguro
- Hable sobre la dirección de desarrollo de la seguridad empresarial de Internet
Dirección de desarrollo de seguridad empresarial : desde el menos profundo hasta el más profundo, se divide en cuatro objetivos: 1. Impulsado por eliminar las vulnerabilidades, el primer objetivo es hacer que cada línea de código escrita por los ingenieros sea segura de esto, SDL nació, y SDL nació. Investigación técnica y tecnología derivadas. 2. SDL no puede ser 100% seguro, por lo que el segundo objetivo es permitir que todos los ataques conocidos y desconocidos se descubran por primera vez, y rápidamente se alertan y rastreen. Desafíos: datos masivos y requisitos complejos: potencia de súper informática y modelos tridimensionales. 3. El tercer objetivo es hacer de la seguridad la competitividad central de la empresa y profundizar en las características de cada producto para guiar mejor los hábitos de uso de Internet de los usuarios. 4. El último objetivo es poder observar cambios en toda la tendencia de seguridad de Internet y proporcionar una advertencia temprana de riesgos en el futuro. Al hacer seguridad en una empresa de Internet, debe tener imaginación y prestar mucha atención al desarrollo de otros campos técnicos. Hacer que este es un gran plan. - Promoción de la defensa a través de la ofensiva: pensamientos sobre la construcción de un ejército azul corporativo
- Ciso Blitz de Zhao Yan |
Objetos de alcance (negocios de la empresa, desafíos y necesidades de seguridad (defensa en profundidad, propia seguridad de la cadena de suministro, capacitación de seguridad de terceros)) ---> establecimiento de objetivos (configuración de demanda actual y desarrollo futuro) ---> Desafíos (en todo el equipo Pila (estructura de conocimiento y habilidades correspondientes al negocio principal), capacidades de ingeniería, capacidades de gestión) ---> descomposición Sistema de seguridad (Seguridad Construcción Sandbox en campos generales: seguridad de I + D, seguridad de TI, seguridad de infraestructura, seguridad de datos, seguridad terminal, seguridad empresarial, privacidad y cumplimiento de la seguridad) ---> Implementación y respuesta (Marco de gobierno de seguridad, evaluación comparativa de la industria (implementación real La capacidad, la demostración no cuenta como esta habilidad), investigación de seguridad). En general, es una visión técnica de pila completa (esforzarse por aumentar desde el nivel de habilidades hasta el nivel de visión técnica) + capacidades de gestión de seguridad.
arquitectura de seguridad
- Arquitectura de seguridad de red |
Enfrentamiento rojo y azul
- [Confrontación roja y azul] Construcción del equipo de seguridad del Ejército Azul para grandes empresas de Internet (aprendidas)
El por qué de confrontación roja y azul : prueba el sistema de protección de la empresa;
¿Qué es la confrontación roja?
El cómo de la confrontación roja-azul : simular apt ---> El equipo azul necesita desarrollar una base de conocimiento sistemática y la biblioteca de técnicas de ataque de armas ---> ATT && CK Matrix Framework.
Desafíos en la confrontación roja-azul con la eficiencia/beneficio de los costos de ataque;
El futuro de la confrontación roja-azul : la plataforma de penetración automatizada/plataforma de penetración de múltiples niveles; - Construyendo confrontación azul roja en la era de la seguridad del ciberespacio (hay artículos relacionados con la confrontación azul roja en el apéndice)
El combate real es el único criterio para probar las capacidades de protección de seguridad . Las pruebas de penetración son adecuadas para la etapa inicial de la construcción del sistema de seguridad empresarial o la etapa de agotamiento, y la confrontación roja-azul es una versión mejorada de las pruebas de penetración. Sistema de construcción de seguridad . /Peeping y otros campos desde una perspectiva de seguridad del ciberespacio .
Seguridad de intranet
- Simulación de ataque de seguridad de intranet y práctica de la regla de detección de anomalías
La idea de la escritura : recopilación de información externa -> Bonos del límite -> Recopilación de información, Escalación de privilegios -> Mantenimiento de privilegios -> Recopilación de información, extracción de credenciales -> Movimiento lateral -> Robo de datos -> Trazos de limpieza.
Seguridad de datos
- Tencent Security inicia el "Mapa de capacidad de seguridad de datos de nivel empresarial"
Ideas de escritura : El mapa de capacidad de seguridad de datos incluye seis aspectos principales: gestión de activos de datos y capacidades de control, capacidades de operación de seguridad de datos, gestión de seguridad empresarial de datos y capacidades de control, soporte de datos Gestión de seguridad ambiental y capacidades de control, operación de datos y mantenimiento Gestión de seguridad y control de control y control capacidades y capacidades de percepción de seguridad de datos.
Nueva tecnología y nueva seguridad
Descripción general
- Modernización de la aplicación y cambio de seguridad en la transformación digital
Ideas de escritura : Nueva infraestructura -> Transformación digital -> La informatización tradicional enfrenta desafíos -> Modernización de aplicaciones impulsadas por negocios -> nativo de la nube, contenedorización, devops, microservicios de aplicación, orquestación y otras nuevas tecnologías -> Arquitectura de modernización de aplicaciones -> Seguridad endógena (todos (todos -Cepciones ruidosas, confiabilidad, intervención de seguridad de procesamiento completo y operación segura de la red en la nube).
nativo de la nube
- Interpretación del proxy nativo de la nube MOSN Tecnología de secuestro transparente |
La idea de escritura : Mesh de servicio-> istio-> plano de datos-> proxy de red-> mosn-> secuestro de tráfico eficiente y transparente. Problema: adquisición del tráfico. Resolución de problemas: adaptación del entorno, gestión de configuración, rendimiento del plano de datos. - Observación de la tendencia de detección de intrusos nativas de nubes
La idea de escribir : diversificación de activos, fragmentación de servicios, reventón de middleware, seguridad de infraestructura por defecto -> detección de intrusos "orientada al negocio", el análisis de comportamiento se convertirá en la capacidad central. - Wang Renfei (Avfisher): equipo rojo para la nube (ofensiva y defensa de la nube) (Mark)
informática confiable
- Zhang OU: Práctica de red de confianza de banca digital
Ideas de escritura : El tema esencial es: defensa en profundidad a nivel de red. Por qué hacerlo (desafío) -> Ideas y planes para la implementación -> Desafíos y pensamientos en el proceso . - He Yi: El camino a la práctica de la arquitectura de seguridad de cero confianza
Punto central : El núcleo de cero confianza es el establecimiento de cadenas de confianza, como los usuarios + dispositivos + aplicaciones, verificación dinámica segura y continua, y reducir la superficie de ataque. Trabajo realizado: puerta de enlace de red, puerta de enlace de host, puerta de enlace de aplicación, Soc .
DevSecOps
- "La seguridad requiere la participación de cada ingeniero" -devsecops filosofía y pensamiento (Mark)
desarrollo seguro
desarrollo personal
entrevista
- Entrevistas de seguridad, pasantías, etc.
Entrevistas : Didi, Baidu (2), 360 (2), Alibaba (6), Tencent (3), Bilibili, Huawei, Tonghuashun, Mogujie. En términos generales, los grandes son tan fuertes que la mayoría de sus opciones son el departamento de seguridad de la fiesta A. Entendía: después de leer las entrevistas y preguntas que se hacen los grandes, es realmente diverso, incluida la orientación del contenedor, la orientación de seguridad de datos, la orientación de la operación de seguridad, etc., que tiene algún valor de referencia, pero debido a que las direcciones son diferentes, por lo que usted No se puede copiar rígidamente. - Resumen de entrevistas con seguridad de seguridad para reclutamiento de primavera 2018
- TENCENT 2016 Pasantía Reclutamiento Explicación detallada de las respuestas a las preguntas de prueba por escrito de Security Post
Prueba escrita : Diseñe una solución de autenticación web segura: front-end: código de verificación + csrf_token + generar números aleatorios basados en el cifrado de la marca de tiempo; , puerto, protocolo); - Entrevistas para puestos de tecnología de seguridad en grandes empresas
Entrevista : Conceptos básicos de la tecnología de seguridad ---> Detalles del proyecto (profundidad de conocimiento, abrumador al entrevistador en áreas de especialización, evitando que el entrevistador haga preguntas en profundidad) ---> Cómo lidiar con preguntas desafiantes (conocimiento e industria cognitiva La capacidad generalmente no se desvía del campo de la experiencia y requiere lectura y pensamiento diarios) ---> la capacidad cognitiva en profundidad de la industria y la planificación profesional - ¿Cuál es la situación actual de las referencias internas para los pasantes de Alibaba en 2019? - Respuesta de Zuo Zuo Vera - Zhihu (Learn)
- Diez caras de Ali, siete caras de los titulares, ¿crees que he entrado en Ali?
Entrevista : Versión de Java de Excelente Experiencia de entrevista, un imprescindible para Java. - Libro de espadas y enemistades: Alibaba y yo (demasiado fuerte)
- Preguntas de la entrevista de reclutamiento de seguridad (aprendida)
Ideas de escritura : Pruebas de penetración (dirección web), investigación y desarrollo de seguridad (dirección de Java), operaciones de seguridad (dirección de auditoría de cumplimiento), arquitectura de seguridad (dirección de gestión de seguridad)
Aprendizaje complementario : CRLF, las diferencias, ventajas y desventajas del cifrado simétrico y cifrado asimétrico, proceso de interacción HTTPS, política de origen, solicitudes de dominio cruzado. - ¿Cómo es un buen currículum para un reclutamiento seguro?
- Reclutamiento de seguridad: situación actual de la industria de seguridad
- Cualidades esenciales de los profesionales de la seguridad para el reclutamiento de seguridad
Idea de escritura: calidad básica = habilidad básica (autodenominado + aprendizaje independiente) + habilidad profesional (ataque de penetración y defensa + desarrollo de software). Cualidades avanzadas = inteligencia (IQ + inteligencia emocional) + valentía y optimismo + introspección . - El proceso de entrevista para el reclutamiento seguro ahora es perezoso, y costará más compensarlo más tarde.
- Un ingeniero de seguridad 2019
Ideas de escritura : Old Track y New Journey - "Explorador de la industria o seguidor -" Intercambio transparente de la información de la industria - "Agregue un poco de sal a la vida".
desarrollo profesional
- Autocultivo de investigadores de seguridad
- Autocultivo de investigadores de seguridad (continuación)
- Discusión sobre la dirección de desarrollo del personal de seguridad
Ruta de desarrollo de seguridad de la parte A : Tipo de tecnología de núcleo duro ---> Laboratorios de Dachang e Investigación de Seguridad Publicaciones de tecnología de núcleo no difícil ---> Construcción de seguridad de la empresa en Internet Rojo y azul, operaciones técnicas, gestión de seguridad - La importancia de la existencia de profesionales de seguridad
Desarrollo personal : el objetivo es ayudar a la productividad avanzada a resolver problemas de seguridad. El problema de seguridad es un problema de confianza (apoyo fiduciario, apoyo de origen), una ciencia que estudia la confrontación (confrontación entre personas) y un problema de probabilidad (arquitectura de seguridad). La seguridad es una ciencia aplicada. , incluida la inteligencia de la máquina y la tecnología blockchain. - Varias identidades del equipo de seguridad en la empresa
Desarrollo del equipo : como servidor y colaborador, el equipo de seguridad debe utilizar capacidades de seguridad profesionales para proporcionar ideas y soluciones a un tipo de problemas de seguridad y resolverlos para evitar que ocurran problemas de seguridad varias veces.
Desarrollo de la industria
paisaje de seguridad
- 最新统计2005-2017年国内科研单位在国际安全顶级会议中发表文章量统计
- 从内容产出看安全领域变化
技术格局:企鹅等互联网巨头开始进行流量封锁,对安全从业人员影响很大,爬不到数据,api又有限,只能上升到app hook了;技术上安全分析、数据挖掘、威胁情报的比重越来越重, AI已经不仅仅是噱头了,智能安全势不可挡;安全的职业发展方面,越来越多大佬们开始转型业务安全、数据安全。 - 网络安全行业竞争格局浅析
市场格局:基础安全防护(传统安全防护能力),中级安全防护(海量数据建模与分析能力),高级安全防护(云端威胁情报与分析能力),中高级安全防护市场广阔。此外,全文在多处凸显了人工智能技术,智能安全开始迈入开悟之坡了吗? !半数以上的人看好智能安全,也有人不看好智能安全,未来会怎么样,让我们拭目以待! - ZoomEye 网络空间测绘——委内瑞拉停电事件对其网络关键基础设施和重要信息系统影响
- 2020安全工作展望
Logic of writing : Major events in 2019 : HW action changes safety from implicit to explicit, low frequency to high frequency, exposes problems, and promotes management to pay attention to safety. This is the background; Classification Protection 2.0 safety compliance is becoming more stringent . 2019大变化:领导重视了;实战化了。 2020甲方安全关注技术点:安全运营(覆盖率和正常率等指标、是否有验证思路:能否在一定时间内主动发现安全措施失效)和安全资产管理(CMDB、主机上数据、流量、扫描、人工添加)。 2020关注“人”的需求。 2020展望行业:甲方安全团队组织架构会发生剧烈变化,安全团队能否承受变化;甲乙两方相处之道;安全黑天鹅事件越来越多。
productos de seguridad
- C端安全产品的未来之路
C端安全产品:移动端安全产品是否会像前几天PC端安全产品一样迎来春天?PC时代windows是一家独大的完全开放的平台,这让第三方安全公司能够在平台和用户之间产生价值的空间足够的大,但在移动端,安卓开始封闭,就不好说了。传统安全软件围绕病毒和欺诈,而围绕个人信息安全的C端安全产品有一线生机。 - 下一座圣杯- 2019
API安全:应用安全的发展:2015年预测,数据是新中心,身份是新边界,行为是新控制,情报是新服务。基础设施演进->交付方式的改变。2015年,应用安全领域的WAF产品是良机,由市场决定。新形势与新机遇:微服务、Serverless、边缘计算。市场中的交付方式发生变化。跨细分领域且跨基础设施:API安全横跨应用安全、数据安全和身份安全三大领域。API使用场景广泛,需要产品有全面覆盖多种不同基础设施的能力。
datos
数据体系
- 数据分析师如何搭建数据运营指标体系? - 张溪梦Simon的回答
Core point : Collaboration process empowerment : Implementing the data-driven XX indicator system construction process requires cross-team collaboration. The processes include: demand collection, program planning, data collection, collection program evaluation, data collection and data verification online, and effect evaluation .规划数据指标体系的两个模型:OSM和UJM。 OSM强调业务目标,UJM强调用户旅程。指标分级体系:一二三级指标联动。 - 如何在企业中从0-1建立一个数据/商业分析部门? ( Aprendió )
部门的定位和价值——>里程碑设计——->团队搭建——->构建IT数据——->前期管理。
定位和价值是一个部门立足公司的根本:做报表的部门VS做战略的部门;业务其他公司的定位和公司内其他部门的认可;一定要会放大部门的价值和一定要走高层路线。
设立长期目标并拆解里程碑:公司业务目标--->公司战略--->部门目标--->部门里程碑--->工作计划;设立里程碑的技巧?借势、共赢、取巧、筑基;借老板势,寻找1-2个老板的痛点问题解决;寻找利益相同的部门共建共赢;取巧摘已有的“桃子”;筑基数据链路梳理、数据清洗、系统互联、数据仓库设计、数据集市设计。
基于里程碑进行团队搭建:切忌一步到位;审慎拉帮结派;遇到人才不可错过;学会“画饼”;注意团队文化建设。
构建公司的数据IT能力:搭建基础且通用的数据流框架:应用层、归集层、加工层、分析层、展示层; 同时根据各种数据库选型指标选择对应的数据库存储产品,数据库选型指标比如容量、水平扩展性、查询实时性、查询灵活性、写入速度、事务、数据存储、处理数据规模、列扩展性。在搭建数据框架中需要注意的点是:需要实现公司级别的业务数据架构。基于业务对整个公司的数据进行体系化的梳理,任何的业务变化都会体现在数据之上,实现数据充分体现业务现状的目的。要完成这一步的关键是完成公司级别的主数据管理:明确各项数据的业务含义和口径、明确每个数据的职责单位、打通数据链路,推动数据共享。
引领团队走向胜利:做“排长”而不要做“军长”;让合适的人做合适的事;明确规则,及时兑现。
数据分析与运营
- 数据分析与可视化:谁是安全圈的吃鸡第一人(学到了)
数据分析与可视化:收集数据集--->观察数据集--->社群发现与社区关系--->玩家画像。 - 请分享一下数据分析方面的思路,如何做好数据分析?
核心点:数据分析的问题:业务的数据分析指标体系(点线面体)。数据分析的方法:分类和对比。
安全数据分析
- Data-Knowledge-Action: 企业安全数据分析入门(优秀,学到了)
综述: 1、让模型理解业务,基于业务历史行为建立异常基线,在异常的基础上检测威胁;将运营结果反馈到模型,将误报视作正常行为回流。2、安全运营可运营,降低事件调查成本,自动化信息收集与聚合。3、随着数据的积累,安全数据分析将向基于图结构的高级知识表达方式发展。(这点深表赞同)4、对场景、攻击模式、数据的认识深度,远比选择工具重要。 - Security Data Science Learning Resources
综述:作者的研究点也是安全数据科学,整理了一些学习方法和学习资源。学习方法主要分为三个方面:谷歌学术、Twitter、安全会议。谷歌学术关注知名研究者以及他们新出的文章,关注引用了你关注的文章的文章,Twitter关注细分安全领域的人群,关注安全会议以及会议议程。学习资源:书籍和课程。 - 快速搭建一个轻量级OpenSOC架构的数据分析框架(一)(学到了)
框架:行文思路:由粗变细(由框架到举例子(由框架到场景到实际架构))。OpenSOC介绍(框架组成和工作流程)---》构建轻量级OpenSOC(聚焦具体场景和工具及具体架构)---》搭建步骤(每一步的环境搭建及配置)---》效果展示。 - 先知talk:从数据视角探索安全威胁
- 大数据威胁建模方法论(学到了很多)
- 安全日志维度随想
- 数据安全分析思想探索
- DataCon 2019: 1st place solution of malicious DNS traffic & DGA analysis(学到了)
我的理解:涉及的知识点有:安全场景:DNS安全;数据处理:tshark工具的使用,MaxCompute和SQL的使用,PAI预分析和可视化;特征工程:DNS_type、src_ip维度的特征;异常检测算法:单特征3sigma检测;人工提取特征规则。
第一小题DNS恶意流量的异常检测:个人吸收80%,整理流程无障碍,每步流程中的细节和工具还未完全掌握,比如DNS安全场景了解不全面、tshark的大量数据解析、统计特征的全面提取、SQL语句做特征化;
第二小题DGA的多分类:个人吸收50%,流程搞懂了,但是对一些问题的理解还不到位,比如社区算法 - 基于大数据企业网络威胁发现模型实践
我的理解:问题:多源安全分析设备和服务(威胁数据)的横向和纵向联动。
algoritmo
AI
算法体系
- 机器学习算法集锦:从贝叶斯到深度学习及各自优缺点
算法知识框架:主要从算法的定义、过程、代表性算法、优缺点解释回归、正则化算法、人工神经网络、深度学习||决策树算法、集成算法||支持向量机||降维算法、聚类算法||基于实例的算法||贝叶斯算法||关联规则学习算法||图模型。
个人理解:回归系列主要基于线性回归和逻辑回归衍生,包括回归、正则化算法、人工神经网络、深度学习;树系列主要基于决策树衍生,包括决策树和基于树的集成学习算法;支持向量机属于老牌算法;降维算法和聚类算法主要基于数据的内在结构描述数据;基于实例的算法实际上并没有训练的过程,代表性算法是KNN,基于记忆的学习;贝叶斯算法利用贝叶斯定理计算输出概率;关联规则学习算法能够提取数据中变量之间的关系的最佳解释;图模型是一种概率模型,可以表示随机变量之间的条件依赖结构。 - Categories of algorithms non exhaustive (学到了)
算法知识框架:学到了搭建自己的算法体系。
conocimiento basico
- HTTP DATASET CSIC 2010
Security Data Set-CSIC2010 : A security data set automatically generated based on e-Commerce Web application, including 36,000 normal requests and 25,000 abnormal requests. Abnormal requests include: SQL injection, buffer overflow, information collection, file leakage, CRLF injection, XSS etc . - 分类模型的性能评估——以SAS Logistic 回归为例(3): Lift 和Gain
- 机器学习中非均衡数据集的处理方法?
非均衡数据集:上采样和下采样、正负样本的惩罚权重(scikit-learn的SVM为例:class_weight:{dict,'balanced'})、组合/集成方法(从大样本中抽取多个小样本训练模型再集成)、特征选择(小样本量具有一定规模的时候,选择显著型的特征) - 机器学习算法中GBDT 和XGBOOST 的区别有哪些?
算法比较:GBDT基分类器为CART,XGB的分类器可以是多种基分类器,比如线性分类器,这时候就相当于L1、L2正则项的逻辑回归或线性回归;传统的GBDT在优化时用到的是一阶导数,XGB则对损失函数进行了二阶泰勒公式的展开,精度变高;XGB并行处理(特征粒度的并行,对特征值进行预排序存储为block结构,在进行节点分类的时候,需要计算每个特征的增益,最终选择增益最大的那个特征去做分类,那么各个特征的增益计算就可以开多线程进行),相对于GBM速度飞跃;剪枝时,当新增分类带来负增益时,GBM会停止分裂,而XGB一直分类到指定的最大深度,然后进行后全局剪枝;从最优化的角度来看,GBDT采用的是数值优化的思维,用的最速下降法去求解Loss function的最优解,其中用CART决策树去拟合负梯度,用牛顿法求步长,而XGB用的是解析的思维,对Loss function展开到二阶近似,求得解析解,用解析解作为Gain来建立决策树,使得Loss function最优。 - SVM和logistic回归分别在什么情况下使用?
算法使用场景-SVM和逻辑回归使用场景:需要根据特征数量和训练样本数量来确定。如果特征数相对于训练样本数已经够大了,使用线性模型就能取得不错的效果,不需要过于复杂的模型,则使用LR或线性核函数的SVM。 If the training samples are large enough and the number of features is small, better prediction performance can be obtained through SVM with complex kernel functions. If the samples do not reach millions, SVM with complex kernel functions will not cause the operation to be too slow .如果训练样本特别大,使用复杂核函数的SVM已经会导致运算过慢了,因此应该考虑引入更多特征,然后使用线性SVM或者LR来构造模型。 - gbdt的残差为什么用负梯度代替?
- 欧氏距离与马氏距离
- 机器学习算法常用指标总结
- 分类模型评估之ROC-AUC曲线和PRC曲线
aprendizaje automático
- 平均数编码:针对高基数定性特征(类别特征)的数据预处理/特征工程
- Mean Encoding
- kaggle编码categorical feature总结
- Python target encoding for categorical features
- Mean (likelihood) encodings: a comprehensive study
- 如何在Kaggle 首战中进入前10%
- kaggle竞赛总结
- 分享一波关于做Kaggle比赛,Jdata,天池的经验,看完我这篇就够了
- 为什么在实际的kaggle比赛中,GBDT和Random Forest效果非常好?
有监督学习-树系列算法:单模型,gradient boosting machine和deep learning是首选。gbm不需要复杂的特征工程,不需要太多时间去调参数,dl则需要比较多的时间去调网络结构。从overfit角度理解,两者都有overfit甚至perfect fit的能力,overfit能力越强,可塑性越强,然后我们要解决的问题就是如果把模型训练的“恰好”,比如gbm里有early_stopping功能。线性回归模型就缺乏overfit能力,如果实际数据符合线性模型的关系,那可以得到很好的结果,如果不符合的话,就需要做特征工程,可特征工程又是一个比较主观的过程。树的优势,非参数模型,gbm的overfit能力强。而random forest的perfact fit能力很差,这是因为rf的树是独立训练的,没有相互协作,虽然是非参数型模型,但是浪费了这个先天优势。 - 【总结】树类算法认知总结
有监督学习-树类算法:分类树和回归树的区别;避免决策树过拟合的方法;随机森林怎么应用到分类和回归问题上;kaggle上为啥GBDT比RF更优;RF、GBDT、XGBoost的认知(原理、优缺点、区别、特性)。 - LightGBM
- LightGBM算法总结
- 『我爱机器学习』集成学习(四)LightGBM
- 如何玩转LightGBM(官方slides讲解)
有监督学习-LightGBM-个人理解: LightGBM几大特性及原理:直方图分割及直方图差加速(直方图两大改进:直方图复杂度=O(#feature×#data),GOSS降低样本数,EFB降低特征数)-》效率和内存提升。Leaf-wise with max depth limitation取代Level-wise-》准确率提升。支持原生类别特征。并行计算:数据并行(水平划分数据)、特征并行(垂直划分数据)、PV-Tree投票并行(本质上是数据并行)。 - 快速弄懂机器学习里的集成算法:原理、框架与实战
- 时间序列数据的聚类有什么好方法?
无监督学习-时间序列问题:传统的机器学习数据分析领域:提取特征,使用聚类算法聚集;在自然语言处理领域:为了寻找相似的新闻或是把相似的文本信息聚集到一起,可以使用word2vec把自然语言处理成向量特征,然后使用KMeans等机器学习算法来作聚类;另一种做法是使用Jaccard相似度来计算两个文本内容之间的相似性,然后使用层次聚类的方法来作聚类。常见的聚类算法:基于距离的机器学习聚类算法(KMeans)、基于相似性的机器学习聚类算法(层次聚类)。对时间序列数据进行聚类的方法:时间序列的特征构造、时间序列的相似度方法。如果使用深度学习的话,要么就提供大量的标签数据;要么就只能使用一些无监督的编码器的方法。 - 凝聚式层次聚类算法的初步理解
无监督学习-层次聚类:算法步骤:计算邻近度矩阵--->(合并最接近的两个簇--->更新邻近度矩阵)(repeat),直到达到仅剩一个簇或达到终止条件。 - 推荐算法入门(1)相似度计算方法大全
无监督学习-层次聚类-相似性计算:曼哈顿距离、欧式距离、切比雪夫距离、余弦相似度、皮尔逊相关系数、Jaccard系数。
aprendizaje profundo
CPU环境搭建
- tensorflow issues#22512
Nature of the problem : Error: ImportError: DLL load failed, reason: missing dependencies, solution: pip install --index-url https://pypi.douban.com/simple tensorflow==2.0.0, dependencies will be installed automatically .
GPU环境搭建
- Tensorflow和Keras 常见问题(持续更新~)(坑点)
- Tested build configurations(版本对应速查表)
- windows tensorflow-gpu的安装(靠谱)
- windows下安装配置cudn和cudnn
问题本质:总的来说,是英伟达显卡驱动版本、cuda、cudnn和tensorflow-gpu之间版本的对应问题。最好装tensorflow-gpu==1.14.0,tensorflow-gpu==2.0需要cuda==10.0,10.2会报错,tensorflow-gpu==2.0不支持。 - win10搭建tensorflow-gpu环境
问题本质:CUDA的各种环境变量添加。
深度学习基础知识
- 深度学习中的batch的大小对学习效果有何影响?
- Batch Normalization原理与实战(还没完全看懂)
神经网络基本部件
- 如何计算感受野(Receptive Field)——原理感受野:卷积层越深,感受野越大,计算公式为(N-1)_RF = f(N_RF, stride, kernel) = (N_RF - 1) * stride + kernel,思路为倒推法。
- 如何理解空洞卷积(dilated convolution)谭旭的回答空洞卷积:池化层减小图像尺寸同时增大感受野,空洞卷积的优点是不做pooling损失信息的情况下,增大感受野。3层3*3的传统卷积叠加起来,stride为1的话,只能达到(kernel_size-1)layer+1=7的感受野,和层数layer成线性关系,而空洞卷积的感受野是指数级的增长,计算公式为(2^layer-1)(kernel_size-1)+kernel_size=15。
- 空洞卷积(dilated convolution)感受野计算
- 空洞卷积(dilated Convolution)
- 直观理解神经网络最后一层全连接+Softmax(便于理解)
全连接层:可以理解为对特征的加权求和。
神经网络基本结构
- 一组图文,读懂深度学习中的卷积网络到底怎么回事?
卷积神经网络:卷积层参数:内核大小(卷积视野3乘3)、步幅(下采样2)、padding(填充)、输入和输出通道。卷积类型:引入扩张率参数的扩张卷积、转置卷积、可分离卷积。 - 卷积神经网络(CNN)模型结构
- 总结卷积神经网络发展历程- 没头脑的文章(很全面)
- 三次简化一张图:一招理解LSTM/GRU门控机制(很清晰)
循环神经网络:文中电路图的形式好理解。RNN:输入状态、隐藏状态。LSTM:输入状态、隐藏状态、细胞状态、3个门。GRU:输入状态、隐藏状态、2个门。LSTM和GRU通过设计门控机制缓解RNN梯度传播问题。 - gcn
- GRAPH CONVOLUTIONAL NETWORKS
图神经网络:相较于CNN,区别是图卷积算子计算公式。 - keras-attention-mechanism
神经网络应用
- [AI识人]OpenPose:实时多人2D姿态估计| 附视频测试及源码链接
- 使用生成对抗网络(GAN)生成DGA
- GAN_for_DGA
- 详解如何使用Keras实现Wassertein GAN
- Wasserstein GAN in Keras
- WassersteinGAN
- keras-acgan
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题- 综述和实践
NLP :传统的高维稀疏->现在的低维稠密。注意事项:类目不均衡、理解数据(badcase)、fine-tuning(只用word2vec训练的词向量作为特征表示,可能会损失很大效果,预训练+微调)、一定要用dropout、避免训练震荡、超参调节、未必一定要softmax loss、模型不是最重要的、关注迭代质量(为什么?结论?下一步?)
aprendizaje por refuerzo
- 深度强化学习的弱点和局限
- 关于强化学习的局限的一些思考
强化学习的局限性:采样效率很差、很难设计一个合适的奖励函数。
Áreas de aplicación
- 全球最全?的安全数据网站(有时间得好好整理一下)
- 初探机器学习检测PHP Webshell
- 基于机器学习的Webshell 发现技术探索
- 网络安全即将迎来机器对抗时代?
智能安全-智能攻击:国外已经在研究利用机器学习打造更智能的攻击工具,比如深度强化学习,就是深度学习和强化学习的结合,可以感知环境,做出最优决策,可能被应用到漏洞扫描器里,使扫描器能够自动化地入侵目标。
个人理解:国外已有案例Deep Exploit就是利用深度强化学习结合metasploit进行自动化地渗透测试,国内还没有看到过相关公开案例。由于学习门槛高、安全本身攻击场景需要精细化操作、弱智能化机器学习导致的机器学习和安全场景结合深度不够等一系列的问题,已有的机器学习+安全的大多数研究主要集中在安全防护方面,机器学习+攻击方面的研究较少且局限,但是我相信这个场景很有潜力,或许以后就成为蓝方的攻击利器。 - 人工智能反欺诈三部曲之:设备指纹
智能安全-业务安全-设备指纹:ip、cookie、设备ID ;主动式设备指纹:使用JS或SDK从客户端抓取各种各样的设备属性值,然后组合,通过hash算法得到设备ID;优点:Web内或者App内准确率高。缺点:主动式设备指纹在Web与App之间、不同的浏览器之间,会生成不同的设备ID,无法实现跨Web和App,不同浏览器之间的设备关联;由于依赖客户端代码,指纹在反欺诈的场景中对抗性较弱。被动式设备指纹:从数据报文中提取设备OS、协议栈和网络状态的特征集,并结合机器学习算法识别终端设备。优点:弥补了主动式设备指纹的缺点。缺点:占用处理资源多;响应时延比主动式长。 - 风险大脑支付风险识别初赛经验分享【谋杀电冰箱-凤凰还未涅槃】
智能安全-业务安全-风控:个人理解见:https://github.com/404notf0und/Risk-Operation-Detection/blob/master/atec.ipynb。 - 机器学习在互联网巨头公司实践
入侵检测:机器学习和统计建模的主要区别:机器学习主要依赖数据和算法,统计建模依赖建模者对数据特征的了解。两者的优缺点:机器学习:打标数据难获取,如果采用非监督学习,则性能不足以运维;机器学习结果不可解释。所以现在机器学习在做入侵检测的时候,一般都要限定一个特定的场景。统计建模:数据预处理阶段移除正常数据的干扰(重点关注查全率,强调过正常数据的过滤能力,尽可能筛除正常数据),构建能够识别恶意可疑行为的攻击模型(重点关注precision,强调模型对异常攻击模式判断的准确性,攻击链模型),缺点是泛化能力不足、在入侵检测一些场景中,模型易被干扰。我们的最终目的:大数据场景下安全分析可运维。 - Web安全检测中机器学习的经验之谈
Web安全:从文本分类的角度解决Web安全检测的问题。数据样本的多样性,短文本分类,词向量,句向量,文本向量。文本分类+多维度特征。与传统方法做对比得出更好的检测方式:传统方法+机器学习:传统waf/正则规则给数据打标;传统方法先进行过滤。 - 词嵌入来龙去脉(学到了)
PNL :DeepNLP的核心关键:语言表示--->NLP词的表示方法类型:词的独热表示和词的分布式表示(这类方法都基于分布假说:词的语义由上下文决定,方法核心是上下文的表示以及上下文与目标词之间的关系的建模)--->NLP语言模型:统计语言模型--->词的分布式表示:基于矩阵的分布表示、基于聚类的分布表示、基于神经网络的分布表示,词嵌入--->词嵌入(word embedding是神经网络训练语言模型的副产品)--->神经网络语言模型与word2vec。 - 深入浅出讲解语言模型
NLP :NLP统计语言模型:定义(计算一个句子的概率的模型,也就是判断一句话是否是人话的概率)、马尔科夫假设(随便一个词出现的概率只与它前面出现的有限的一个或几个词有关)、N元模型(一元语言模型unigram、二元语言模型bigram)。 - 有谁可以解释下word embedding? - YJango的回答- 知乎
NLP :单词表达:one hot representation、distributed representation。Word embedding:以神经网络分析one hot representation和distributed representation作为例子,证明用distributed representation表达一个单词是比较好的。word embedding就是神经网络分析distributed representation所显示的效果,降低训练所需的数据量,就是要从数据中自动学习出输入空间到distributed representation空间的映射f(相当于加入了先验知识,相同的东西不需要分别用不同的数据进行学习)。训练方法:如何自动寻找到映射f,将one hot representation转变成distributed representation呢?思想:单词意思需要放在特定的上下文中去理解,例子:这个可爱的泰迪舔了我的脸和这个可爱的京巴舔了我的脸,用输入单词x 作为中心单词去预测其他单词z 出现在其周边的可能性(至此我才明白为什么说词嵌入是神经网络训练语言模型的副产品这句话)。用输入单词作为中心单词去预测周边单词的方式叫skip-gram,用输入单词作为周边单词去预测中心单词的方式叫CBOW。 - Chars2vec: character-based language model for handling real world texts with spelling errors and…
- Character Level Embeddings
- 使用TextCNN模型探究恶意软件检测问题
恶意软件检测:改进分为两个方面:调参和结构。调参:Embedding层的inputLen、output_dim,EarlyStopping,样本比例参数class_weight,卷积层和全连接层的正则化参数l2,适配硬件(GPU、TPU)的batch_size。结构:增加了全局池化层。
学到了:一个trick,通过训练集和评价指标logloss计算测试集的各标签数量,以此调整训练阶段的参数class_weight,还可以事先达到“对答案”的效果。和一个T大大佬在datacon域名安全检测比赛中使用的trick如出一辙。 - 基于海量url数据识别视频类网页
CV-行文思路:问题:视频类网页识别。解决方式:url粗筛->视频网页规则粗筛->视频网页截屏及CNN识别。
行业发展
- 认知智能再突破,阿里18 篇论文入选AI 顶会KDD
认知智能:计算智能->感知智能->认知智能。快速计算、记忆、存储->识别处理语言、图像、视频->实现思考、理解、推理和解释。认知智能的三大关键技术:知识图谱是底料、图神经网络是推理工具、用户交互是目的。 - 未来3~5 年内,哪个方向的机器学习人才最紧缺? - 王喆的回答
要点简记:站在机器学习“工程体系”之上,综合考虑“模型结构”,“工程限制”,“问题目标”的算法“工程师”。我的理解:红利的迁移,模型结构单点创新带来的收益->体系结构协同带来的收益。 阿里技术副总裁贾扬清:我对人工智能的一点浅见
AI发展:神经网络和深度学习的成功与局限,成功原因是大数据和高性能计算,局限原因是结构化的理解和小数据上的有效学习算法。 AI这个方向会怎么走?传统的深度学习应用,比如图像、语音等,应该如何输出产品和价值?而不仅仅是停留在安防这个层面,要深入到更广阔的领域。除了语音和图像之外,如何解决更多问题?而不仅仅是停留在解决语音图像等几个领域内的问题。
综合素质
- 算法工程师必须要知道的面试技能雷达图(学到了)
个人发展-必备技术素质:算法工程师必备技术素质拆分:知识、工具、逻辑、业务。 On the basis of meeting the minimum requirements, algorithm engineers have relatively comprehensive capabilities in these four aspects, including both "algorithm" and "engineering", while big data engineers focus on "tools" and researchers focus on "knowledge" and "logic" .
针对安全业务的算法工程师就是安全算法工程师。为了便于理解,举个例子,如果用XGBoost解决某个安全问题,那么可以由浅入深理解,把知识、工具、逻辑、业务四个方面串起来:
1.GBDT的原理(知识)
2.决策树节点分裂时是如何选择特征的? (Conocimiento)
3.写出Gini Index和Information Gain的公式并举例说明(知识)
4.分类树和回归树的区别是什么(知识)
5.与Random Forest对比,理解什么是模型的偏差和方差(知识)
6.XGBoost的参数调优有哪些经验(工具)
7.XGBoost的正则化和并行化分别是如何实现的(工具)
8.为什么解决这个安全问题会出现严重的过拟合问题(业务)
9.如果选用一种其他模型替代XGBoost或改进XGBoost你会怎么做? ¿Por qué? (业务、逻辑、知识)。
以上,就是以“知识”为切入点,不仅深度理解了“知识”,也深度理解了“工具”、“逻辑”、“业务”。
- [校招经验] BAT机器学习算法实习面试记录(学到了)
个人发展-面试经验:根据面试常遇到的问题再深入理解机器学习,储备自己的算法知识库。 - 机器学习如何才能避免「只是调参数」? (Aprendió)
个人发展-职业发展:机器学习工程师分为三种:应用型(能力:保持算法全栈,即数据、建模、业务、运维、后端,重点在建模能力,流程是遇到一个指定的业务场景应该迅速知道用什么数据做特征,用什么模型,这个模型在工程上的时效性和鲁棒性,最终会不会产生业务风险等一整套链路。预期目标:锻炼得到很强的业务敏感性,快速验证提出的需求)、造轮子型(多读顶会跟上时代节奏,且拥有超强的功能能力,打造ML框架,提供给应用型机器学习工程师使用)、研究型(AI Lab,读论文+试验性复现)。 Personal development: Develop business and engineering capabilities. The growth plan for the next few years is still the full-stack algorithm route. I will be independent in technology and bring KPIs in business. I will be promoted quickly + lead the team in the future .同时保持阅读习惯,多学习新知识。 - 做机器学习算法工程师是什么样的工作体验?
个人发展-工作体验:业务理解、数据清洗和特征工程、持续学习(增强解决方案的判断力)、编程能力、常用工具(XGB、TensorFlow、ScikitLearn、Pandas(表格类数据或时间序列数据)、Spark、SQL、FbProphet(时间序列)) - 大三实习面经(学到了)
- 如果你是面试官,你怎么去判断一个面试者的深度学习水平?
个人发展-心得体会:深度学习擅长处理具有局部相关性的问题和数据,在图像、语音、自然语言处理方面效果显著,因为图像是由像素构成,语音是由音位构成,语言是由单词构成,都有局部相关性,可以构造高级特征。 - 面试官如何判断面试者的机器学习水平? - 微调的回答- 知乎
个人发展-心得体会:考虑方法优点和局限性,培养独立思考的能力;正确判断机器学习对业务的影响力;学会分情况讨论(比如深度学习相对于机器学习而言);学习机器学习不能停留在“知道”的层次,要从原理级学习,甚至可以从源码级学习,知其然知其所以然,要做安全圈机器学习最6的。 - 两年美团算法大佬的个人总结与学习建议
个人发展-心得体会:算法的基本认识(知识)、过硬的代码能力(工具)、数据处理和分析能力(业务和逻辑)、模型的积累和迁移能力(业务和逻辑)、产品能力、软实力。
Profesión
planificación de carrera
pensamiento
- 如何解决思维混乱、讲话没条理的情况? (Aprendió)
结构化思维->讲话有条理。 - 哪些思维方式是你刻意训练过的? (Aprendió)
结构化思维
金字塔思维:结论先行,以上统下,归类分组,逻辑递进。
金字塔结构:纵向延伸,横向分类。
如何得出金字塔结论:归纳法,演绎推理法。实际生活中,不是每时每刻都有相关的模型套用和演绎法的,这时候就用归纳法,自下而上进行梳理,得出结论,比如头脑风暴把闪过的碎片想法全部写下来,再抽象与分类,最后得出结论。 - 厉害的人是怎么分析问题的? (Aprendió)
Define the problem/describe the problem: The essence of the problem is the gap between reality and expectations ; clarify the expected value B', accurately locate the current situation B, and use the gap B--->B' to accurately describe the problema.
分析问题/解决问题:不能从现状B出发,找寻一条B--->B'的路径,要透过现象看本质。方法A,现实B,期望B',变量C。校准期望B',重构方法A,消除变量C。
comunicar
administrar
- “我是技术总监,你干嘛总问我技术细节?”
(快速发展期、平稳期、衰退期等业务发展时期作为时间轴)(中高层管理者)(需要掌握)(应用场景、技术基础、技术栈中的技术细节)。技术基础要扎实,技术栈了解程度深(对技术原理和细节清楚),应用场景不能浮于表面。总的来说就是一句话:技术细节与技术深度。 - 阿里巴巴高级算法专家威视:组建技术团队的一些思考(学到了)
行文思路:团队的定位(定位(能力、业务、服务)、壁垒(以不变应万变沉淀风险管控知识作为壁垒)和价值(提供不同层次的服务形式))-》团队的能力(连接、生产、传播、服务)-》组织与个人的关系-》招人-》用人-》对内管理模式(找对前进的方向、绩效的考核(3个维度:业务结果、能力进步、技术影响力))
学到了:建设技术体系解决某一类问题,而不是某个技术点去解决某一个问题。 - 26岁当上数据总监,分享第一次做Leader的心得
团队管理方面的基本功和方法论:定策略、建团队、立规矩、拿结果。
定策略:要明确公司高层的真实目的;对自己的团队了如指掌;管理者专精的行业知识和经验。
建团队:避免嫉贤妒能、职场近亲、玻璃心。
立规矩:立规矩守规矩。
拿结果:注意吃相。
管理中常见的误区:做管理后放弃原来专业(要关注行业发展方向和前沿技术);过度管理(要自循环的稳定成熟团队);过度追求团队稳定(衡量团队稳定的核心标准不是人员的稳定,而是团队的效率和产出是否能够有持续稳定的增长) - 什么特质的员工容易成为管理者
公司内部晋升管理者:天时:企业/行业所处的阶段;地利:部门/业务所处的阶段;人和:人际关系+自身能力。
跳槽成为管理者:大公司跳槽到小公司,寻找职业突破,弊端是跳出去容易跳回来难;成为行业内有影响力的人物,被大公司挖角。大部分人都是第一种情况,在大公司的同学要多一点耐心,通过努力在公司内晋升,因为曲线救国式的跳槽已经没有市场了。 - 技术部门Leader是不是一定要技术大牛担任?
核心点:Manager vs Tech Leader、方法论、软技能、赋能成员、综合。
pensar
- 好的研究想法从哪里来
研究的本质是对未知领域的探索,是对开放问题的答案的追寻。“好”的定义-》区分好与不好的能力-》全面了解所在研究方向的历史和现状-》实践法/类比法/组合法。这就好比是机器学习的训练和测试阶段,训练:全面了解所在研究方向的历史和现状,判断不同时期的研究工作的好与不好。测试:实践法/类比法/组合法出的idea,判断自己的研究工作好与不好。 - 科研论文如何想到不错的idea?
模块化学习、交叉、布局可预期的趋势。 - 人在年轻的时候,最核心的能力是什么?
核心点:达到以前从未达到的高度:基本的事情做到极致、专注、坚持长久做一件事、延迟满足、认清自己+了解环境->准确定位、
Cosas a tener en cuenta
- 领域点-线-面体系:点:自己focus的领域;线:上游和下游;面:大领域。不要过度focus在自己工作的领域,要有全局化的眼光,特别是自己的上游和下游。
- 日常学习点-线-面体系:点:自己focus的安全数据分析领域;线:安全/数据分析;面:全局安全内容/行业发展/职业规划。 Study a small field for at least one hour every day; read intensively for at least half an hour every day/at least one quality article on security/data analysis/industry development/career planning; browse a large number of incremental articles/stock articles cada día.保持学习与思考的敏感性。
apéndice
国外优质技术站点
- https://resources.distilnetworks.com
站点概况:专注于机器流量对抗与缓解。 - http://www.covert.io
技术栈:Jason Trost,专注于安全研究、大数据、云计算、机器学习,即安全数据科学。 - http://cyberdatascientist.com
站点概括:专注于安全数据科学,提供网络安全、统计学和AI等学习资料,并提供14个安全数据集,包括:垃圾邮件、恶意网站、恶意软件、Botnet等。没有secrepo.com提供的资料全面。 - https://towardsdatascience.com
站点概括:专注于数据科学。
国内优秀技术人
- michael282694
技术栈:数据分析挖掘产品开发、爬虫、Java、Python。 - LittleHann
技术栈:我也不知道该怎么描述,Han师傅会的太多了,C++、Java、Python、PHP、Web安全、系统安全,不过目前好像做算法多一些。 - FeeiCN
技术栈:专注自动化漏洞发现和入侵检测防御。 - xiaojunjie
技术栈:专注于代码审计、CTF。 - 云雷
技术栈:阿里云存储技术专家,专注于日志分析与业务,日志计算驱动业务增长。 - yami
技术栈:主要研究Web安全、机器学习,喜欢Python和Go。一直偷学师傅的博客。 - cdxy
技术栈:早先主要做Web安全,CTF,代码审计,现在主要做安全研究与数据分析,初步估算技术领先我1~2年,师傅别学了。 - csuldw
技术栈:专注于机器学习、数据挖掘、人工智能。 - molunerfinn
技术栈:专注于前端,北邮大佬,和404notfound同级。 - 刘建平Pinard
技术栈:机器学习、深度学习、强化学习、自然语言处理、数学统计学、大数据挖掘,相关tutorial非常棒。
abandonado
- Efficient and Flexible Discovery of PHP Vulnerability译文
- Efficient and Flexible Discovery of PHP Application Vulnerabilities原文
- The Code Analysis Platform "Octopus"
- A Code Intelligence System:The Octopus Platform


