byol pytorch
0.8.2
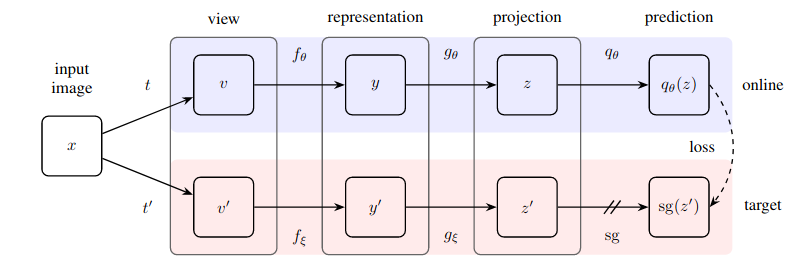
Implementación práctica de un método sorprendentemente simple para el aprendizaje autosupervisado que logra un nuevo estado del arte (superando a SimCLR) sin aprendizaje contrastivo y sin tener que designar pares negativos.
Este repositorio ofrece un módulo que permite envolver fácilmente cualquier red neuronal basada en imágenes (red residual, discriminadora, red de políticas) para comenzar a beneficiarse inmediatamente de los datos de imágenes sin etiquetar.
Actualización 1: ahora hay nueva evidencia de que la normalización por lotes es clave para que esta técnica funcione bien
Actualización 2: un nuevo documento reemplazó con éxito la norma de lote con la norma de grupo + estandarización de peso, refutando que se necesitan estadísticas de lote para que BYOL funcione
Actualización 3: Finalmente, tenemos un análisis de por qué esto funciona.
La excelente explicación de Yannic Kilcher.
Ahora evita que tu organización tenga que pagar por las etiquetas :)
$ pip install byol-pytorchSimplemente conecte su red neuronal, especificando (1) las dimensiones de la imagen, así como (2) el nombre (o índice) de la capa oculta, cuya salida se utiliza como representación latente utilizada para el entrenamiento autosupervisado.
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of target encoder
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )Eso es todo. Después de mucha capacitación, la red residual ahora debería funcionar mejor en sus tareas supervisadas posteriores.
Un nuevo artículo de Kaiming sugiere que BYOL ni siquiera necesita que el codificador de destino sea un promedio móvil exponencial del codificador en línea. He decidido incorporar esta opción para que puedas usar fácilmente esa variante para el entrenamiento, simplemente configurando el indicador use_momentum en False . Ya no necesitarás invocar update_moving_average si sigues esta ruta como se muestra en el siguiente ejemplo.
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
use_momentum = False # turn off momentum in the target encoder
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )Si bien los hiperparámetros ya se han configurado según lo que el documento considera óptimo, puede cambiarlos con argumentos de palabras clave adicionales para la clase contenedora base.
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
projection_size = 256 , # the projection size
projection_hidden_size = 4096 , # the hidden dimension of the MLP for both the projection and prediction
moving_average_decay = 0.99 # the moving average decay factor for the target encoder, already set at what paper recommends
) De forma predeterminada, esta biblioteca utilizará los aumentos del documento SimCLR (que también se usa en el documento BYOL). Sin embargo, si desea especificar su propio canal de aumento, simplemente puede pasar su propia función de aumento personalizada con la palabra clave augment_fn .
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn
)En el artículo, parecen asegurar que uno de los aumentos tiene una mayor probabilidad de desenfoque gaussiano que el otro. También puedes ajustar esto al deleite de tu corazón.
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
augment_fn2 = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip (),
kornia . filters . GaussianBlur2d (( 3 , 3 ), ( 1.5 , 1.5 ))
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn ,
augment_fn2 = augment_fn2 ,
) Para recuperar las incrustaciones o las proyecciones, simplemente debe pasar un indicador return_embeddings = True a la instancia del alumno BYOL .
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
imgs = torch . randn ( 2 , 3 , 256 , 256 )
projection , embedding = learner ( imgs , return_embedding = True ) El repositorio ahora ofrece capacitación distribuida con ? Huggingface Acelerar. Sólo tienes que pasar tu propio Dataset al BYOLTrainer importado.
Primero establezca la configuración para la capacitación distribuida invocando la CLI de aceleración
$ accelerate config Luego, elabora tu script de entrenamiento como se muestra a continuación, por ejemplo en ./train.py
from torchvision import models
from byol_pytorch import (
BYOL ,
BYOLTrainer ,
MockDataset
)
resnet = models . resnet50 ( pretrained = True )
dataset = MockDataset ( 256 , 10000 )
trainer = BYOLTrainer (
resnet ,
dataset = dataset ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
learning_rate = 3e-4 ,
num_train_steps = 100_000 ,
batch_size = 16 ,
checkpoint_every = 1000 # improved model will be saved periodically to ./checkpoints folder
)
trainer ()Luego use la CLI de aceleración nuevamente para iniciar el script.
$ accelerate launch ./train.pySi su tarea posterior implica segmentación, consulte el siguiente repositorio, que extiende BYOL al aprendizaje a nivel de "píxeles".
https://github.com/lucidrains/pixel-level-contrastive-learning
@misc { grill2020bootstrap ,
title = { Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning } ,
author = { Jean-Bastien Grill and Florian Strub and Florent Altché and Corentin Tallec and Pierre H. Richemond and Elena Buchatskaya and Carl Doersch and Bernardo Avila Pires and Zhaohan Daniel Guo and Mohammad Gheshlaghi Azar and Bilal Piot and Koray Kavukcuoglu and Rémi Munos and Michal Valko } ,
year = { 2020 } ,
eprint = { 2006.07733 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { chen2020exploring ,
title = { Exploring Simple Siamese Representation Learning } ,
author = { Xinlei Chen and Kaiming He } ,
year = { 2020 } ,
eprint = { 2011.10566 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

