Mega pytorch
0.1.0
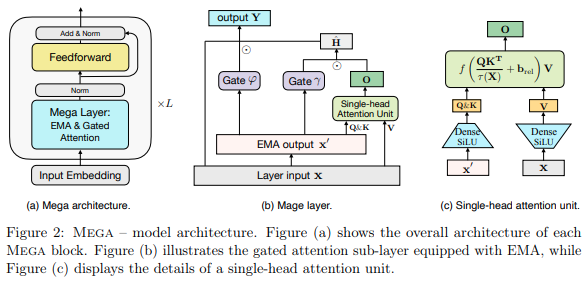
Implementación de la capa Mega, la capa de Atención de un solo cabezal con EMA de múltiples cabezales que existe en la arquitectura que actualmente tiene SOTA en Long Range Arena, superando a S4 en Pathfinder-X y todas las demás tareas excepto el audio.
$ pip install mega-pytorchLa Mega Capa con combinación de atención y EMA aprendida
import torch
from mega_pytorch import MegaLayer
layer = MegaLayer (
dim = 128 , # model dimensions
ema_heads = 16 , # number of EMA heads
attn_dim_qk = 64 , # dimension of queries / keys in attention
attn_dim_value = 256 , # dimension of values in attention
laplacian_attn_fn = False , # whether to use softmax (false) or laplacian attention activation fn (true)
)
x = torch . randn ( 1 , 1024 , 128 ) # (batch, seq, dim)
out = layer ( x ) # (1, 1024, 128)Full Mega (con Layernorm por ahora)
import torch
from mega_pytorch import Mega
mega = Mega (
num_tokens = 256 , # number of tokens
dim = 128 , # model dimensions
depth = 6 , # depth
ema_heads = 16 , # number of EMA heads
attn_dim_qk = 64 , # dimension of queries / keys in attention
attn_dim_value = 256 , # dimensino of values in attention
laplacian_attn_fn = True , # whether to use softmax (false) or laplacian attention activation fn (true)
)
x = torch . randint ( 0 , 256 , ( 1 , 1024 ))
logits = mega ( x ) # (1, 1024, 256) @inproceedings { Ma2022MegaMA ,
title = { Mega: Moving Average Equipped Gated Attention } ,
author = { Xuezhe Ma and Chunting Zhou and Xiang Kong and Junxian He and Liangke Gui and Graham Neubig and Jonathan May and Luke Zettlemoyer } ,
year = { 2022 }
}

