antialiased cnns
v0.3
Hacer que las redes convolucionales vuelvan a ser invariantes
Ricardo Zhang. En ICML, 2019.
Ejecute pip install antialiased-cnns
import antialiased_cnns
model = antialiased_cnns . resnet50 ( pretrained = True ) Si ya tiene un modelo y desea suavizar el alias y continuar entrenando, copie sus pesos anteriores:
import torchvision . models as models
old_model = models . resnet50 ( pretrained = True ) # old (aliased) model
antialiased_cnns . copy_params_buffers ( old_model , model ) # copy the weights overSi desea modificar su propio modelo, utilice la capa BlurPool. Más información sobre los modelos proporcionados y cómo usar BlurPool se encuentra a continuación.
C = 10 # example feature channel size
blurpool = antialiased_cnns . BlurPool ( C , stride = 2 ) # BlurPool layer; use to downsample a feature map
ex_tens = torch . Tensor ( 1 , C , 128 , 128 )
print ( blurpool ( ex_tens ). shape ) # 1xCx64x64 tensorActualizaciones
pip install antialiased-cnns y cargar modelos con el indicador pretrained=True .BlurPoolPip instala este paquete
pip install antialiased-cnnsO clonar este repositorio e instalar los requisitos (en particular, PyTorch)
https://github.com/adobe/antialiased-cnns.git
cd antialiased-cnns
pip install -r requirements.txtLo siguiente carga un modelo antialiased previamente entrenado, quizás como columna vertebral de su aplicación.
import antialiased_cnns
model = antialiased_cnns . resnet50 ( pretrained = True , filter_size = 4 ) También proporcionamos ponderaciones para AlexNet antialiased, VGG16(bn) , Resnet18,34,50,101 , Densenet121 y MobileNetv2 (consulte example_usage.py).
El módulo antialiased_cnns contiene la clase BlurPool , que realiza desenfoque+submuestreo. Ejecute pip install antialiased-cnns o copie el subdirectorio antialiased_cnns .
Metodología La metodología es simple: primero evalúe con el paso 1 y luego use nuestra capa BlurPool para realizar una reducción de resolución suavizada. Realice los siguientes cambios arquitectónicos.
import antialiased_cnns
# MaxPool --> MaxBlurPool
baseline = nn . MaxPool2d ( kernel_size = 2 , stride = 2 )
antialiased = [ nn . MaxPool2d ( kernel_size = 2 , stride = 1 ),
antialiased_cnns . BlurPool ( C , stride = 2 )]
# Conv --> ConvBlurPool
baseline = [ nn . Conv2d ( Cin , C , kernel_size = 3 , stride = 2 , padding = 1 ),
nn . ReLU ( inplace = True )]
antialiased = [ nn . Conv2d ( Cin , C , kernel_size = 3 , stride = 1 , padding = 1 ),
nn . ReLU ( inplace = True ),
antialiased_cnns . BlurPool ( C , stride = 2 )]
# AvgPool --> BlurPool
baseline = nn . AvgPool2d ( kernel_size = 2 , stride = 2 )
antialiased = antialiased_cnns . BlurPool ( C , stride = 2 ) Suponemos que el tensor entrante tiene canales C Calcular una capa en el paso 1 en lugar del paso 2 agrega memoria y tiempo de ejecución. Como tal, normalmente omitimos el antialiasing en la resolución más alta (al principio de la red) para evitar grandes aumentos.
Agregue antialiasing y luego continúe entrenando. Si ya entrenó un modelo y luego agregó antialiasing, puede realizar ajustes desde ese modelo antiguo:
antialiased_cnns . copy_params_buffers ( old_model , antialiased_model )Si esto no funciona, puedes simplemente copiar los parámetros (y no los buffers). Agregar antialiasing no agrega ningún parámetro, por lo que las listas de parámetros son idénticas. (Agrega búferes, por lo que se utiliza alguna heurística para hacer coincidir los búferes, lo que puede generar un error).
antialiased_cnns . copy_params ( old_model , antialiased_model )Observamos mejoras tanto en la precisión (con qué frecuencia la imagen se clasifica correctamente) como en la coherencia (con qué frecuencia dos cambios de la misma imagen se clasifican de la misma manera).
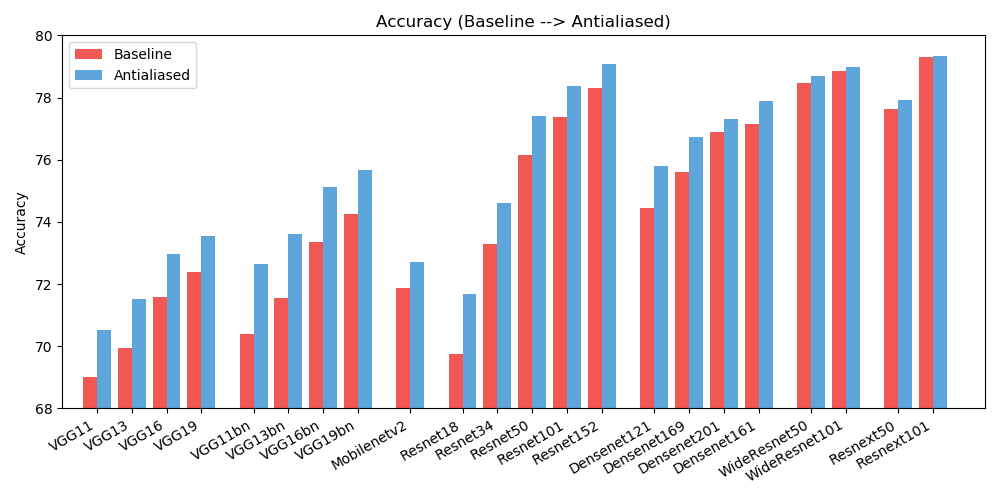
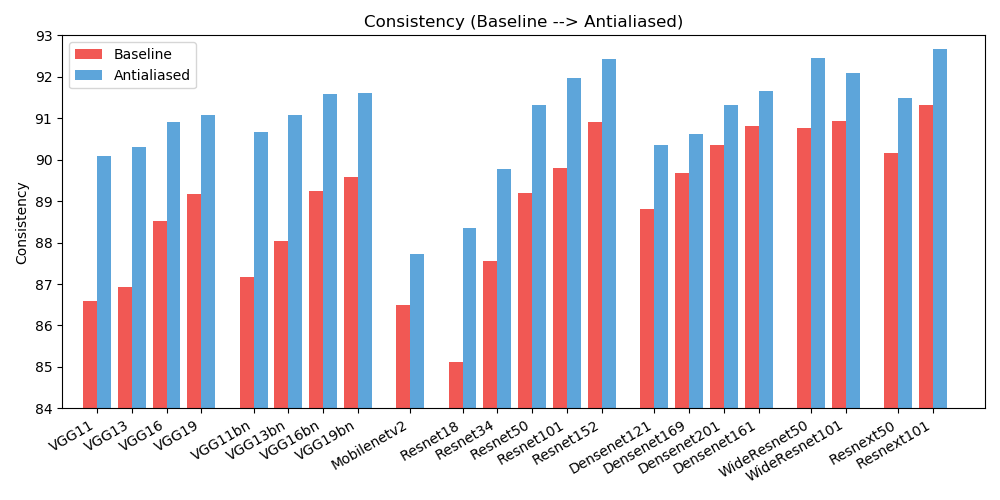
| EXACTITUD | Base | Antialias | Delta |
|---|---|---|---|
| alexnet | 56,55 | 56,94 | +0.39 |
| vgg11 | 69.02 | 70,51 | +1.49 |
| vgg13 | 69,93 | 71,52 | +1.59 |
| vgg16 | 71,59 | 72,96 | +1.37 |
| vgg19 | 72,38 | 73,54 | +1.16 |
| vgg11_bn | 70,38 | 72,63 | +2.25 |
| vgg13_bn | 71,55 | 73,61 | +2.06 |
| vgg16_bn | 73,36 | 75.13 | +1.77 |
| vgg19_bn | 74,24 | 75,68 | +1.44 |
| resnet18 | 69,74 | 71,67 | +1.93 |
| resnet34 | 73,30 | 74,60 | +1.30 |
| resnet50 | 76,16 | 77,41 | +1.25 |
| resnet101 | 77,37 | 78,38 | +1.01 |
| resnet152 | 78,31 | 79.07 | +0.76 |
| resnext50_32x4d | 77,62 | 77,93 | +0.31 |
| resnext101_32x8d | 79,31 | 79,33 | +0.02 |
| ancho_resnet50_2 | 78,47 | 78,70 | +0.23 |
| ancho_resnet101_2 | 78,85 | 78,99 | +0.14 |
| densanet121 | 74,43 | 75,79 | +1.36 |
| densanet169 | 75,60 | 76,73 | +1.13 |
| densanet201 | 76,90 | 77,31 | +0.41 |
| densanet161 | 77.14 | 77,88 | +0.74 |
| móvilnet_v2 | 71,88 | 72,72 | +0.84 |
| CONSISTENCIA | Base | Antialias | Delta |
|---|---|---|---|
| alexnet | 78,18 | 83.31 | +5.13 |
| vgg11 | 86,58 | 90.09 | +3.51 |
| vgg13 | 86,92 | 90.31 | +3.39 |
| vgg16 | 88,52 | 90,91 | +2.39 |
| vgg19 | 89,17 | 91.08 | +1.91 |
| vgg11_bn | 87,16 | 90,67 | +3.51 |
| vgg13_bn | 88.03 | 91.09 | +3.06 |
| vgg16_bn | 89,24 | 91,58 | +2.34 |
| vgg19_bn | 89,59 | 91,60 | +2.01 |
| resnet18 | 85.11 | 88,36 | +3.25 |
| resnet34 | 87,56 | 89,77 | +2.21 |
| resnet50 | 89.20 | 91,32 | +2.12 |
| resnet101 | 89,81 | 91,97 | +2.16 |
| resnet152 | 90,92 | 92,42 | +1.50 |
| resnext50_32x4d | 90.17 | 91,48 | +1.31 |
| resnext101_32x8d | 91,33 | 92,67 | +1.34 |
| ancho_resnet50_2 | 90,77 | 92,46 | +1.69 |
| ancho_resnet101_2 | 90,93 | 92.10 | +1.17 |
| densanet121 | 88,81 | 90,35 | +1.54 |
| densanet169 | 89,68 | 90,61 | +0.93 |
| densanet201 | 90.36 | 91,32 | +0.96 |
| densanet161 | 90,82 | 91,66 | +0.84 |
| móvilnet_v2 | 86,50 | 87,73 | +1.23 |
Para reducir el desorden, aquí se encuentran resultados ampliados (diferentes tamaños de filtro). ¡Ayuda a mejorar los resultados!
Este trabajo está bajo una licencia Creative Commons Atribución-No Comercial-CompartirIgual 4.0 Internacional.
Todo el material está disponible bajo la licencia Creative Commons BY-NC-SA 4.0 de Adobe Inc. Puede usar, redistribuir y adaptar el material para fines no comerciales , siempre que dé el crédito apropiado citando nuestro artículo e indicando cualquier cambio. que has hecho.
El repositorio se basa en el repositorio de ejemplos de PyTorch y el repositorio de modelos de torchvision. Estos tienen licencia de estilo BSD.
Si encuentra esto útil para su investigación, considere citar este bibtex. Comuníquese con Richard Zhang <rizhang en adobe punto com> si tiene algún comentario o sugerencia.


