awesome mojo
1.0.0

Mojo: un nuevo lenguaje de programación para todos los desarrolladores, científicos de IA/ML e ingenieros de software.
Una lista seleccionada de increíble código Mojo, resolución de problemas, soluciones y, en el futuro, bibliotecas, marcos, software y recursos.
Acumulemos aquí conocimientos tecnológicos muy nuevos y mejores prácticas.
Mojo es un lenguaje de programación que combina la facilidad de uso de Python con las capacidades de rendimiento de C++ y Rust. Además, Mojo permite a los usuarios aprovechar el vasto ecosistema de bibliotecas de Python.
en un breve
Mojo es un nuevo lenguaje de programación que cierra la brecha entre la investigación y la producción al combinar lo mejor de la sintaxis de Python con la programación de sistemas y la metaprogramación.
hello.mojo o hello. ¡La extensión del archivo puede ser un emoji!
Puede leer más sobre por qué Modular hace esto. Por qué Mojo
Lo que queríamos era un modelo de programación innovador y escalable que pudiera apuntar a aceleradores y otros sistemas heterogéneos que son omnipresentes en el campo de la IA. ... Los sistemas de IA aplicados deben abordar todos estos problemas, y decidimos que no había ninguna razón para que no se pudiera hacer con un solo lenguaje. Así nació Mojo.
Pero Python ha hecho muy bien su trabajo =)
No vimos ninguna necesidad de innovar en la sintaxis del lenguaje o en la comunidad. Así que elegimos adoptar el ecosistema Python porque es muy utilizado, el ecosistema de IA lo adora y porque creemos que es un lenguaje realmente agradable.
Mojo significa "un encanto mágico" o "poderes mágicos". Pensamos que este era un nombre apropiado para un lenguaje que aporta poderes mágicos a Python :python:, incluido el desbloqueo de un modelo de programación innovador para aceleradores y otros sistemas heterogéneos omnipresentes en la IA actual.
Guido van Rossum, benévolo dictador vitalicio y Christopher Arthur Lattner, distinguido inventor, creador y conocido líder sobre la pronunciación de Mojo =)
Según la descripción
Quién sabe si estos lenguajes de programación estarán muy contentos, porque Mojo se beneficia de tremendas lecciones aprendidas de otros lenguajes Rust, Swift, Julia, Zig, Nim, etc.
[nuevo]
¡Github ahora detecta automáticamente el código Mojo!
¡Marco HTTP simple y rápido para Mojo! Perfecto para crear servicios web y API simples. Para los mojicianos
Marco de evaluación comparativa de implementaciones de LLama
Traducción automatizada de código de Python a Mojo
Investigación de bases de datos de lenguajes de programación
19 de octubre de 2023 ¡Mojo ya está disponible en Mac! Usar la consola de desarrollador
Chris Lattner: el futuro de la programación y la IA | Podcast #381 de Lex Fridman
Explicación del sistema de tipos Mojo y Python | Chris Lattner y Lex Fridman
¿Mojo puede ejecutar código Python? | Chris Lattner y Lex Fridman
Cambiando del lenguaje de programación Python al Mojo | Chris Lattner y Lex Fridman
Nuevo tema de GitHub mojo-lang. Para que puedas seguirlo.
¿Guido van Rossum sobre Mojo = Python con rendimiento C++/GPU?
Estructura tensorial con algunas operaciones básicas #251
Matriz fn con numpy #267
Actualizaciones sobre cierres parameter y lambda y funciones de orden superior en mojo #244
25 de mayo de 2023, Guido van Rossum (gvanrossum#8415), creador y BDFL emérito de Python, visita el chat público de Discord de Mojo
Esperando un resaltado de sintaxis de Mojo en GitHub
Nuevo lanzamiento de Mojo 2023-05-24
[viejo]
Mojo
brew install hyperfinebrew install macchinapip3 install numpy matplotlib scipybrew install silicon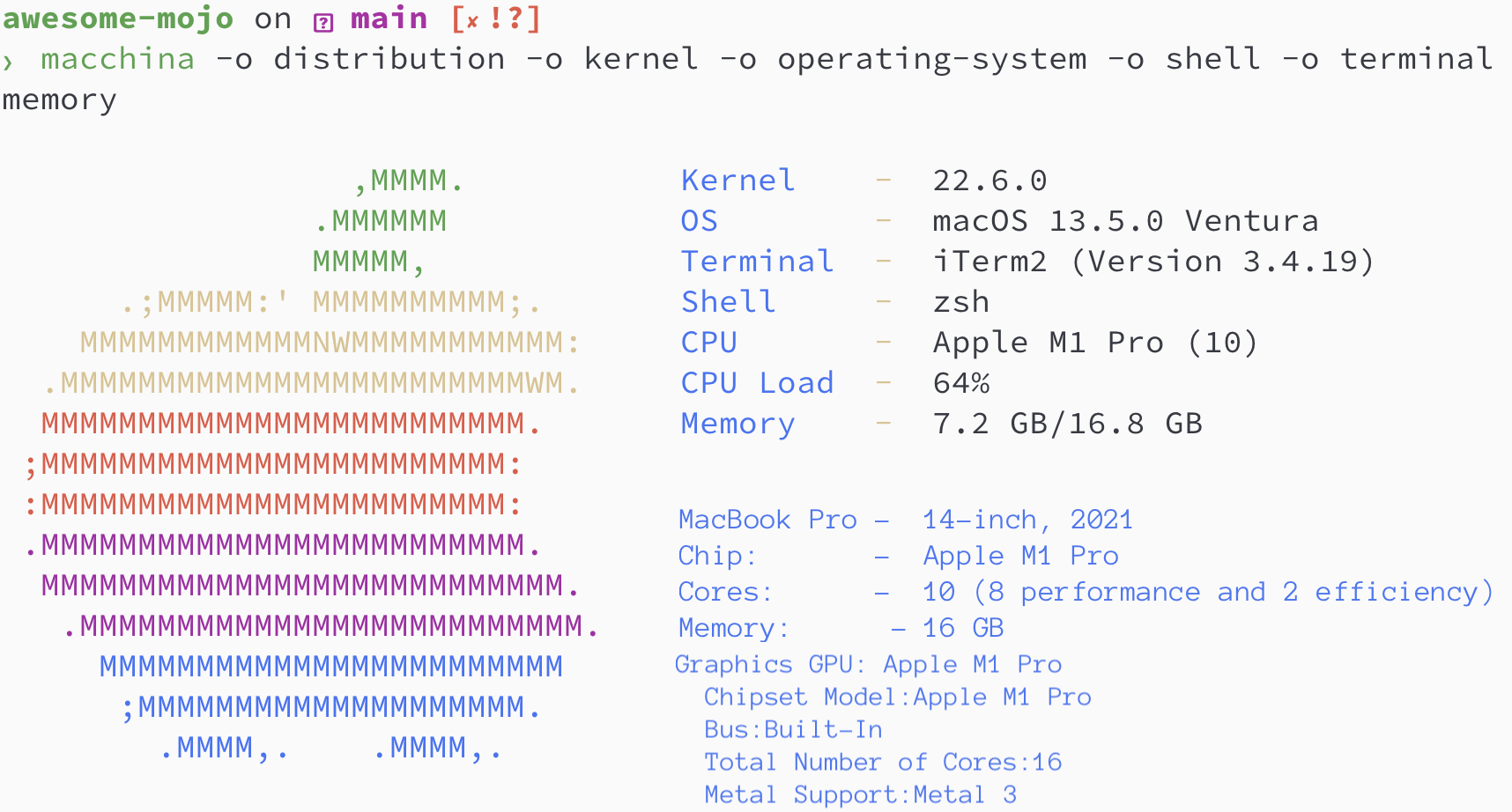
Versiones de Python/Mojo/Codon/Rust
> python3 --version
Python 3.11.6
> mojo --version
mojo 0.4.0 (9e33b013)
> codon --version
0.16.3
> rustc --version
rustc 1.65.0-nightly (9243168fa 2022-08-31)Encontremos la secuencia de Fibonacci donde
norte = 100
def fibonacci_recursion ( n ):
return n if n < 2 else fibonacci_recursion ( n - 1 ) + fibonacci_recursion ( n - 2 )
fibonacci_recursion ( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json python_recursion.json ' python3 benchmarks/fibonacci_sequence/python_recursion.py 'RESULTADO: TIEMPO DE ESPERA, cancelé el cálculo después de 1 m
def fibonacci_iteration ( n ):
a , b = 0 , 1
for _ in range ( n ):
a , b = b , a + b
return a
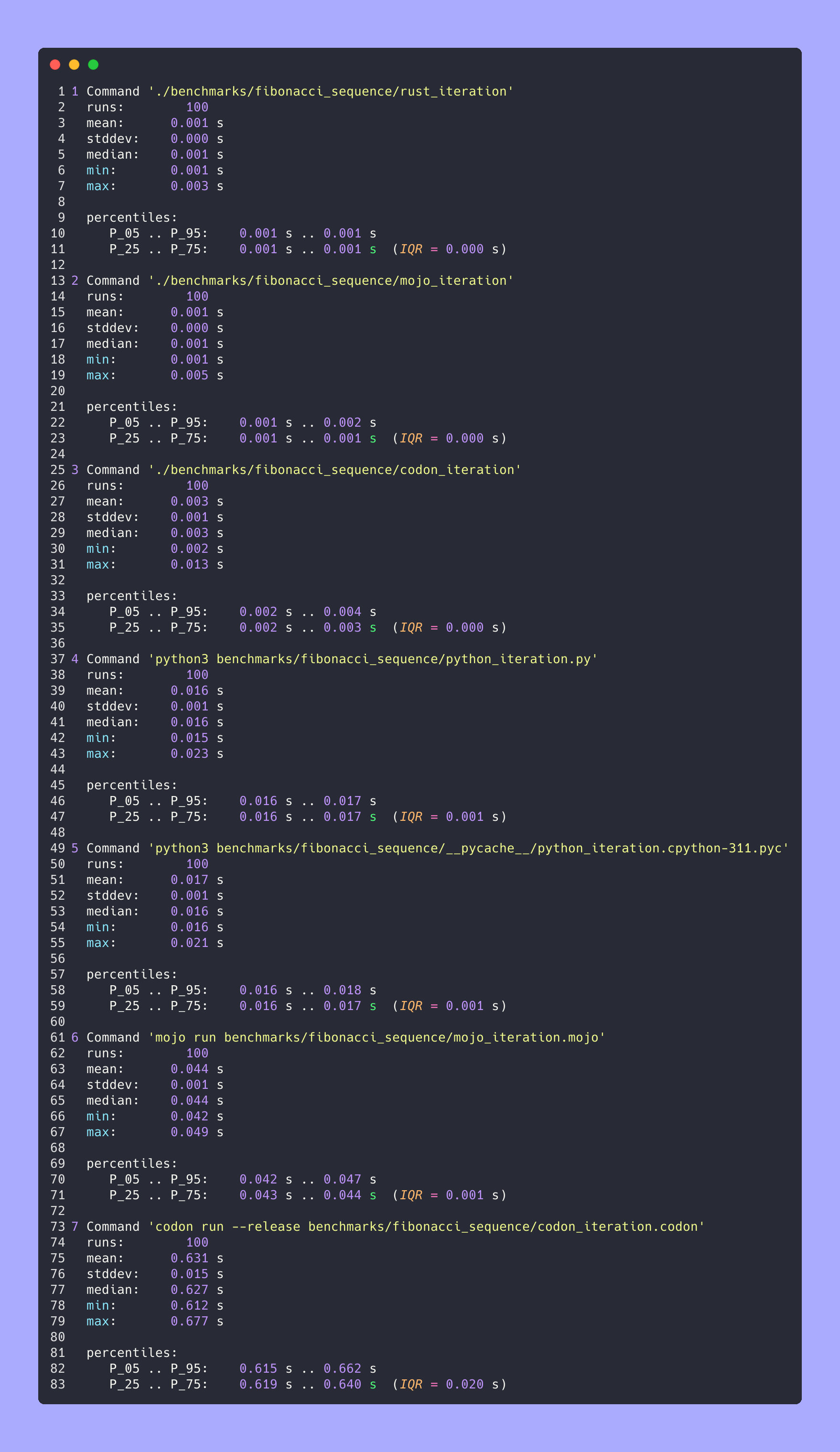
fibonacci_iteration ( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_iteration.json ' python3 benchmarks/fibonacci_sequence/python_iteration.py ' RESULTADO :
Punto de referencia 1: puntos de referencia de python3/fibonacci_sequence/python_iteration.py
Tiempo (media ± σ): 16374,7 µs ± 904,0 µs [Usuario: 11483,5 µs, Sistema: 3680,0 µs]
Rango (mín … máx): 15361,0 µs … 22863,3 µs 100 ejecuciones
python3 -m compileall benchmarks/fibonacci_sequence/python_recursion.py
python3 -m compileall benchmarks/fibonacci_sequence/python_iteration.pyhyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_recursion.cpython-311.json ' python3 benchmarks/fibonacci_sequence/__pycache__/python_recursion.cpython-311.pyc '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_iteration.cpython-311.json ' python3 benchmarks/fibonacci_sequence/__pycache__/python_iteration.cpython-311.pyc ' RESULTADO :
Punto de referencia 1: puntos de referencia de python3/fibonacci_sequence/ pycache /python_iteration.cpython-311.pyc
Tiempo (media ± σ): 16584,6 µs ± 761,5 µs [Usuario: 11451,8 µs, Sistema: 3813,3 µs]
Rango (mín … máx): 15592,0 µs … 20953,2 µs 100 ejecuciones
fn fibonacci_recursion ( n : Int) -> Int:
return n if n < 2 else fibonacci_recursion(n - 1 ) + fibonacci_recursion(n - 2 )
fn main ():
_ = fibonacci_recursion( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_recursion.json ' mojo run benchmarks/fibonacci_sequence/mojo_recursion.mojo 'RESULTADO: TIEMPO DE ESPERA, cancelé el cálculo después de 1 m
fn fibonacci_iteration ( n : Int) -> Int:
var a : Int = 0
var b : Int = 1
for _ in range (n):
a = b
b = a + b
return a
fn main ():
_ = fibonacci_iteration( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_iteration.json ' mojo run benchmarks/fibonacci_sequence/mojo_iteration.mojo ' RESULTADO :
Punto de referencia 1: puntos de referencia de ejecución de mojo/fibonacci_sequence/mojo_iteration.mojo
Tiempo (media ± σ): 43852,7 µs ± 1353,5 µs [Usuario: 38156,0 µs, Sistema: 10407,3 µs]
Rango (mín … máx): 42033,6 µs … 49357,3 µs 100 ejecuciones
mojo build benchmarks/fibonacci_sequence/mojo_recursion.mojo
mojo build benchmarks/fibonacci_sequence/mojo_iteration.mojohyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_recursion.exe.json ' ./benchmarks/fibonacci_sequence/mojo_recursion '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_iteration.exe.json ' ./benchmarks/fibonacci_sequence/mojo_iteration ' RESULTADO :
Punto de referencia 1: ./benchmarks/fibonacci_sequence/mojo_iteration
Tiempo (media ± σ): 934,6 µs ± 468,9 µs [Usuario: 409,8 µs, Sistema: 247,8 µs]
Rango (mín … máx): 552,7 µs … 4522,9 µs 100 ejecuciones
def fibonacci_recursion(n):
return n if n < 2 else fibonacci_recursion(n - 1) + fibonacci_recursion(n - 2)
fibonacci_recursion(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_recursion.json ' codon run --release benchmarks/fibonacci_sequence/codon_recursion.codon 'RESULTADO: TIEMPO DE ESPERA, cancelé el cálculo después de 1 m
def fibonacci_iteration(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a+b
return a
fibonacci_iteration(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_iteration.json ' codon run --release benchmarks/fibonacci_sequence/codon_iteration.codon ' RESULTADO :
Punto de referencia 1: ejecución de codones: puntos de referencia de lanzamiento/fibonacci_sequence/codon_iteration.codon
Tiempo (media ± σ): 628060,1 µs ± 10430,5 µs [Usuario: 584524,3 µs, Sistema: 39358,5 µs]
Rango (mín … máx): 612742,5 µs … 662716,9 µs 100 ejecuciones
codon build --release -exe benchmarks/fibonacci_sequence/codon_recursion.codon
codon build --release -exe benchmarks/fibonacci_sequence/codon_iteration.codonhyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json codon_recursion.exe.json ' ./benchmarks/fibonacci_sequence/codon_recursion '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_iteration.exe.json ' ./benchmarks/fibonacci_sequence/codon_iteration ' RESULTADO :
Punto de referencia 1: ./benchmarks/fibonacci_sequence/codon_iteration
Tiempo (media ± σ): 2732,7 µs ± 1145,5 µs [Usuario: 1466,0 µs, Sistema: 1061,5 µs]
Rango (mín … máx): 2036,6 µs … 13236,3 µs 100 ejecuciones
fn fibonacci_recursive ( n : i64 ) -> i64 {
if n < 2 {
return n ;
}
return fibonacci_recursive ( n - 1 ) + fibonacci_recursive ( n - 2 ) ;
}
fn main ( ) {
let _ = fibonacci_recursive ( 100 ) ;
} rustc -C opt-level=3 benchmarks/fibonacci_sequence/rust_recursion.rs -o benchmarks/fibonacci_sequence/rust_recursion
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/rust_recursion.json ' ./benchmarks/fibonacci_sequence/rust_recursion 'RESULTADO: TIEMPO DE ESPERA, cancelé el cálculo después de 1 m
fn fibonacci_iteration ( n : usize ) -> usize {
let mut a = 1 ;
let mut b = 1 ;
for _ in 1 ..n {
let old = a ;
a = b ;
b += old ;
}
b
}
fn main ( ) {
let _ = fibonacci_iteration ( 100 ) ;
} rustc -C opt-level=3 benchmarks/fibonacci_sequence/rust_iteration.rs -o benchmarks/fibonacci_sequence/rust_iteration
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/rust_iteration.json ' ./benchmarks/fibonacci_sequence/rust_iteration ' RESULTADO :
Punto de referencia 1: ./benchmarks/fibonacci_sequence/rust_iteration
Tiempo (media ± σ): 848,9 µs ± 283,2 µs [Usuario: 371,8 µs, Sistema: 261,4 µs]
Rango (mín … máx): 525,9 µs … 2607,3 µs 100 ejecuciones
# Merge all JSON files into benchmarks.json
python3 benchmarks/hyperfine-scripts/merge_jsons.py benchmarks/fibonacci_sequence/ benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot2.py benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot3.py benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/advanced_statistics.py benchmarks/fibonacci_sequence/benchmarks.json > benchmarks/fibonacci_sequence/benchmarks.json.md
silicon benchmarks/fibonacci_sequence/benchmarks.json.md -l python -o benchmarks/fibonacci_sequence/benchmarks.json.md.pngEstadísticas avanzadas
Juntos
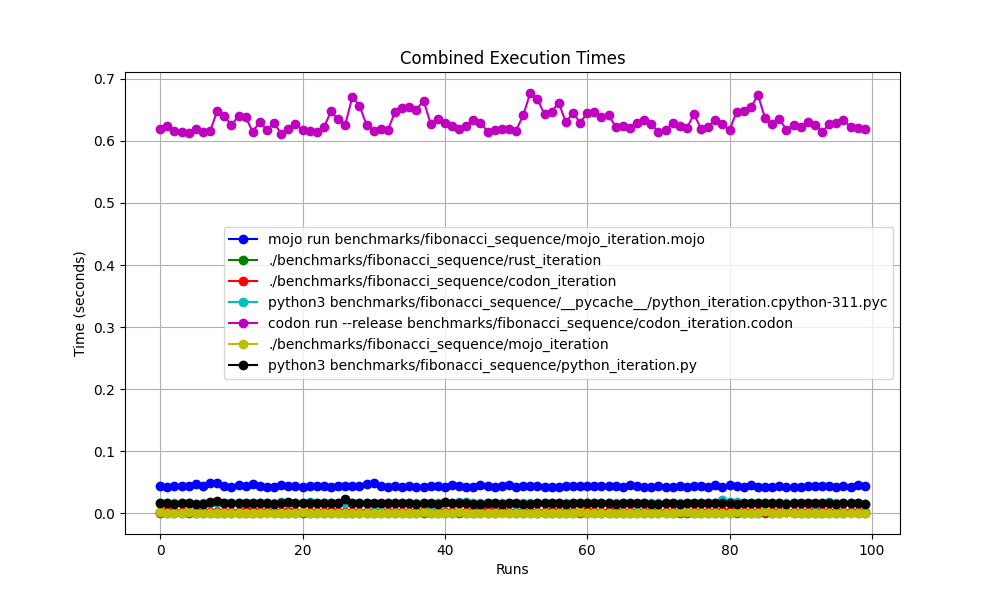
Ampliado
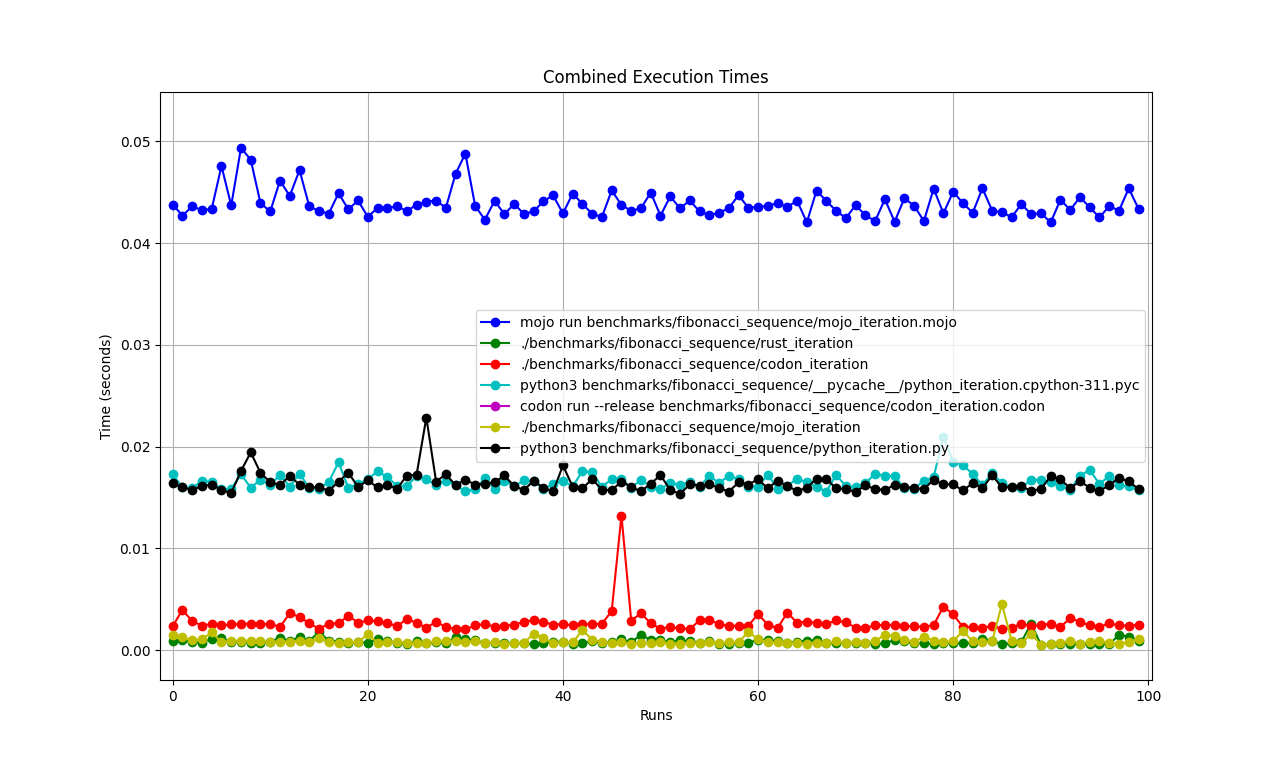
Detallado uno por uno
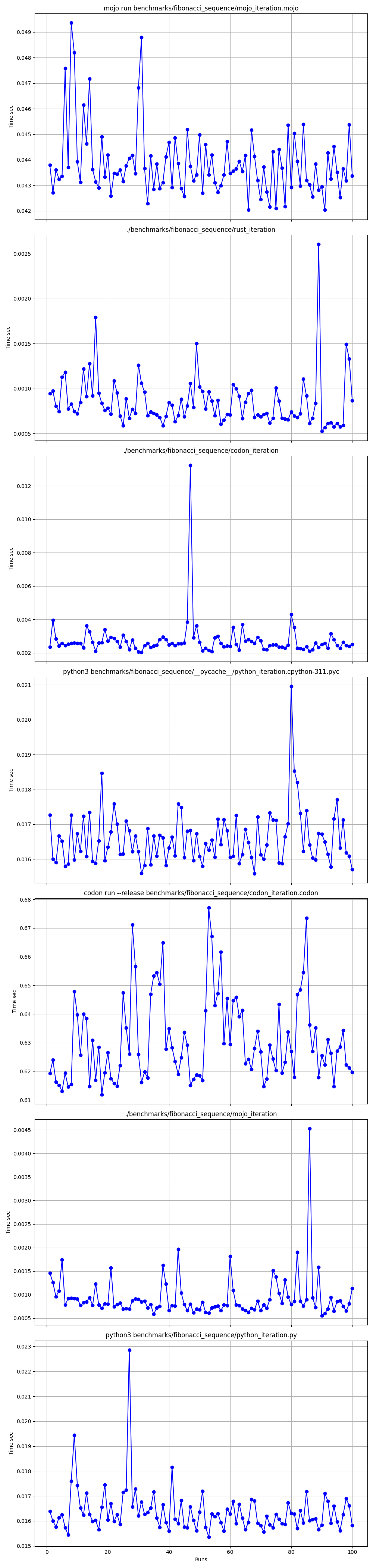
Lugares
Pero aquí hay muchas preguntas:
mojo run tan lento?codon run --release es tan lenta?run más rápido que Mojo/Codon?Entonces, ¡podemos decir que Mojo es tan rápido como Rust en Mac!
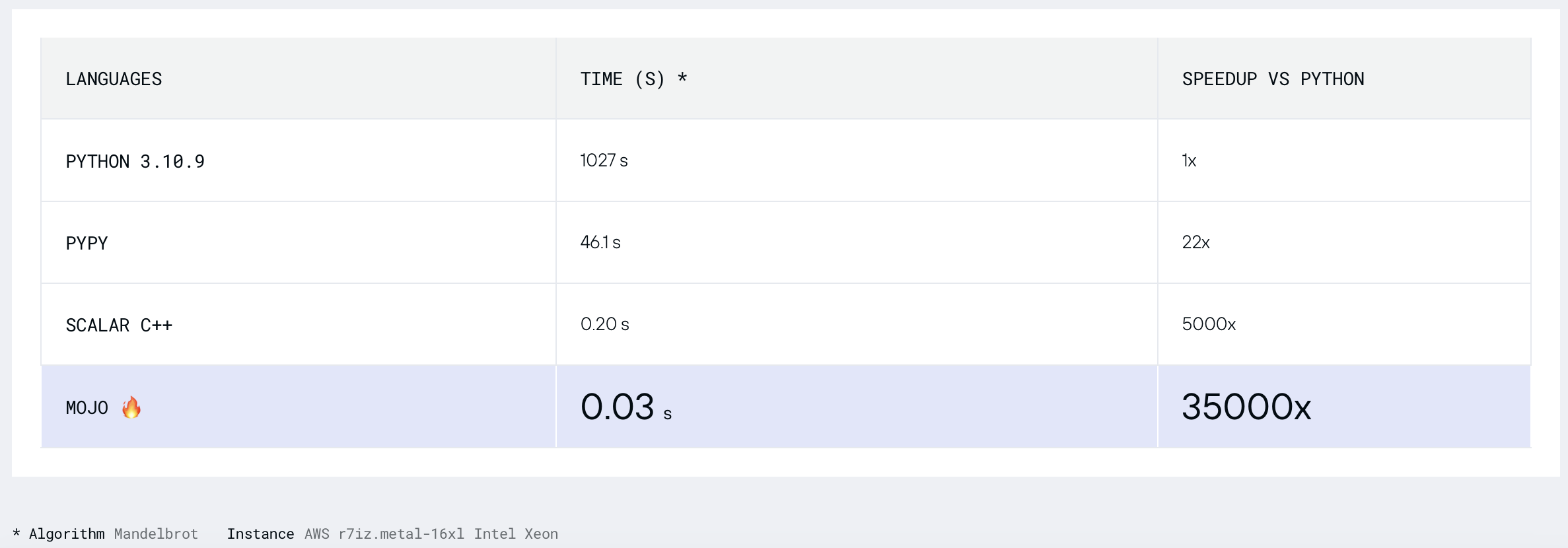
Encontremos el conjunto de Mandelbrot donde
ANCHO = 960
ALTURA = 960
MAX_ITERS = 200
MÍN_X = -2,0
MÁX_X = 0,6
MIN_A = -1,5
MAX_Y = 1,5
def mandelbrot_kernel ( c ):
z = c
for i in range ( MAX_ITERS ):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z . real * z . real + z . imag * z . imag > 4 :
return i
return MAX_ITERS
def compute_mandelbrot ():
t = [[ 0 for _ in range ( WIDTH )] for _ in range ( HEIGHT )] # Pixel matrix
dx = ( MAX_X - MIN_X ) / WIDTH
dy = ( MAX_Y - MIN_Y ) / HEIGHT
for row in range ( HEIGHT ):
for col in range ( WIDTH ):
t [ row ][ col ] = mandelbrot_kernel ( complex ( MIN_X + col * dx , MIN_Y + row * dy ))
return t
compute_mandelbrot ()python3 -m compileall benchmarks/multibrot_set/multibrot.py
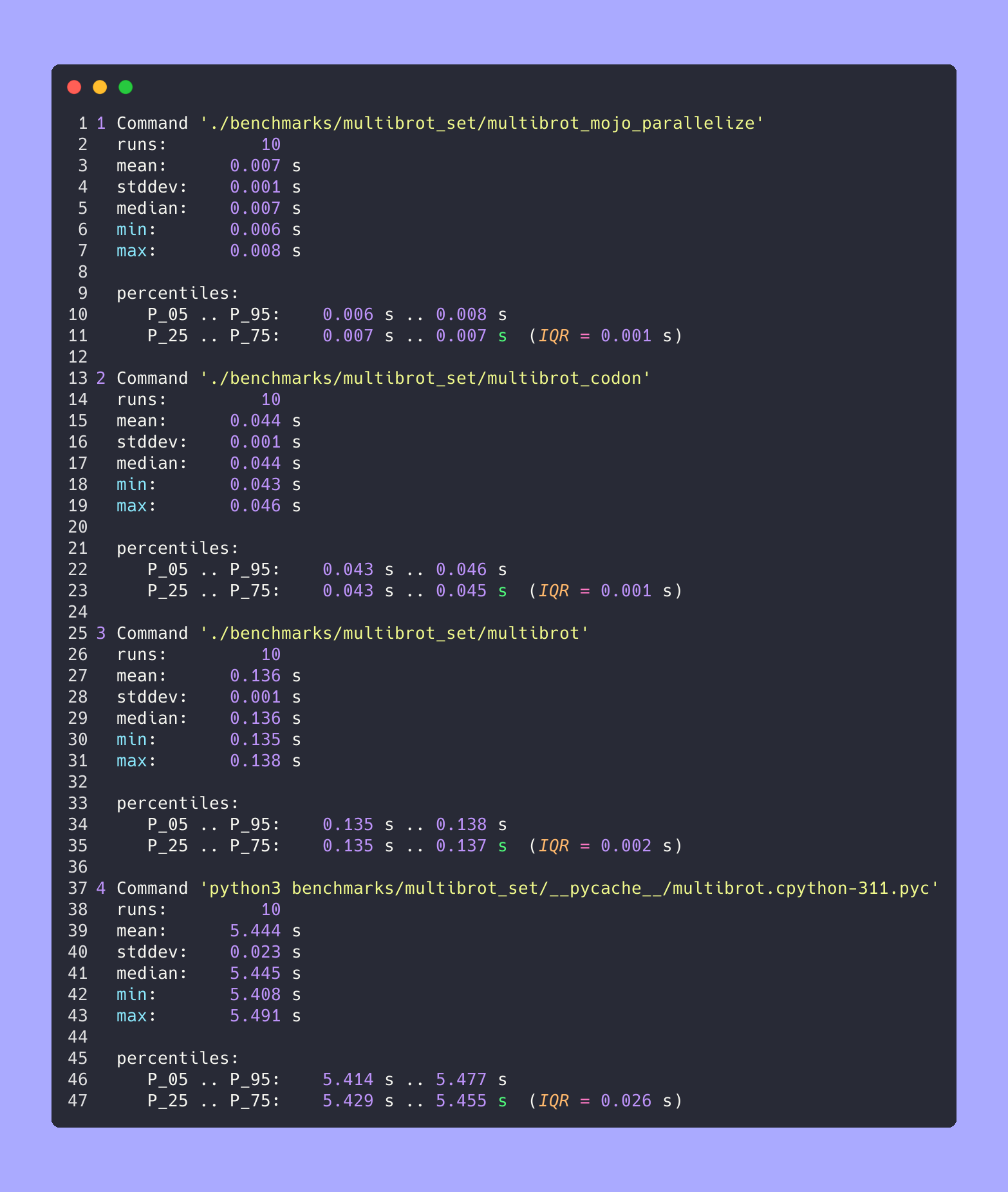
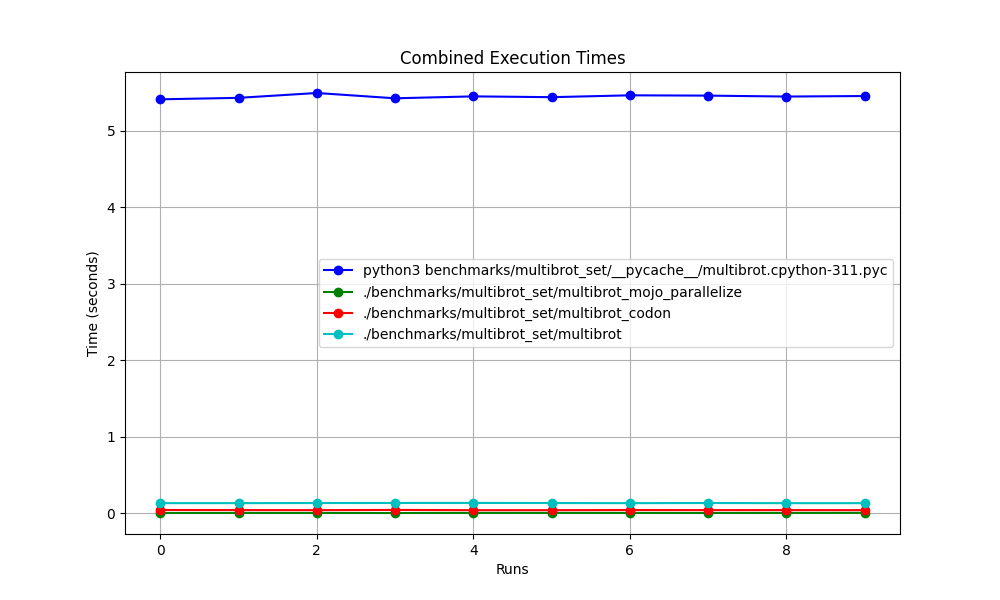
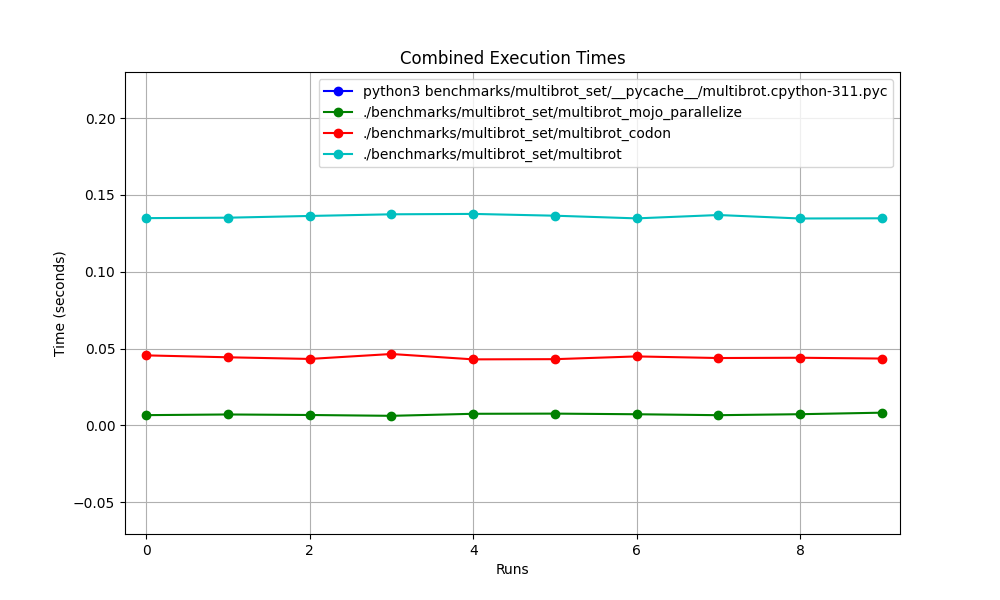
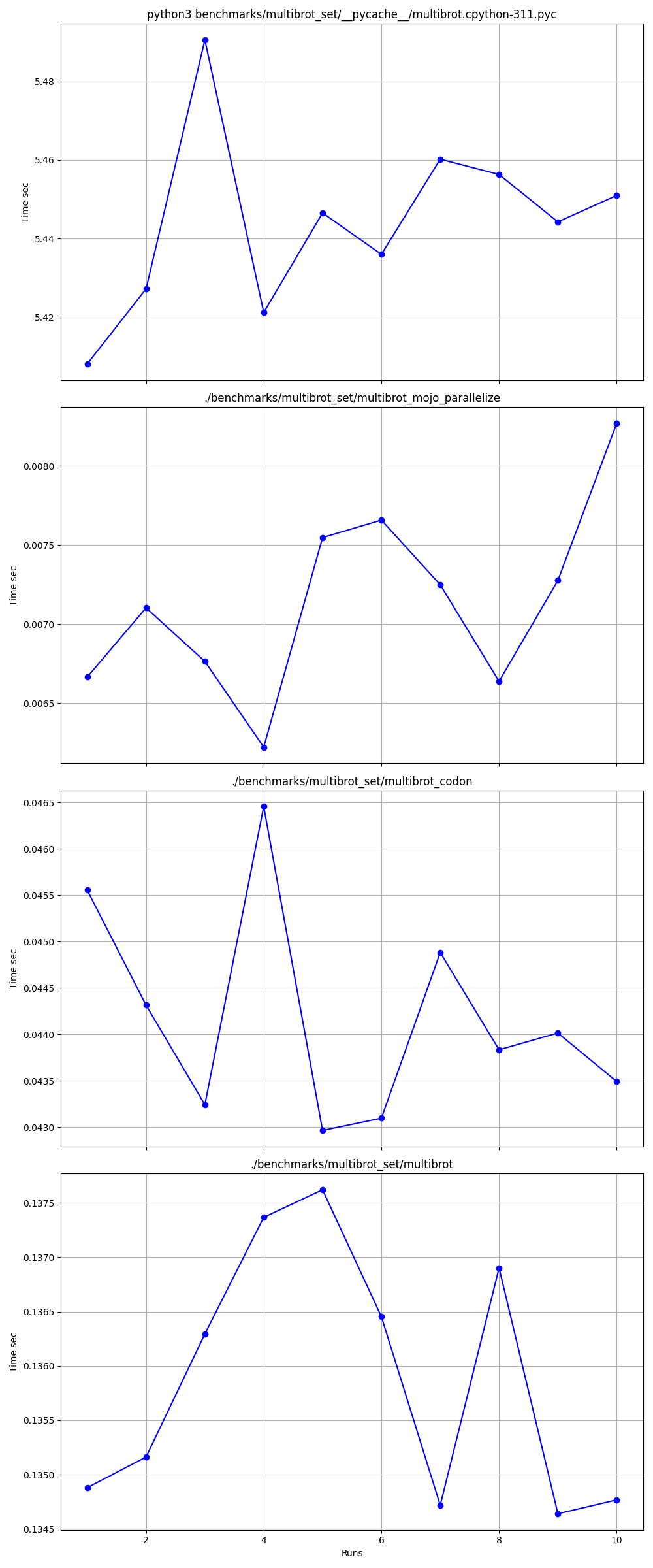
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot.cpython-311.json ' python3 benchmarks/multibrot_set/__pycache__/multibrot.cpython-311.pyc ' RESULTADO :
Punto de referencia 1: puntos de referencia de python3/multibrot_set/ pycache /multibrot.cpython-311.pyc
Tiempo (media ± σ): 5444155,4 µs ± 23059,7 µs [Usuario: 5419790,1 µs, Sistema: 18131,3 µs]
Rango (mín … máximo): 5408155,3 µs … 5490548,4 µs 10 ejecuciones
Versión Mojo sin optimización.
# Compute the number of steps to escape.
def multibrot_kernel ( c : ComplexFloat64) -> Int:
z = c
for i in range ( MAX_ITERS ):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z.squared_norm() > 4 :
return i
return MAX_ITERS
def compute_multibrot () -> Tensor[FloatType]:
# create a matrix. Each element of the matrix corresponds to a pixel
t = Tensor[FloatType]( HEIGHT , WIDTH )
dx = ( MAX_X - MIN_X ) / WIDTH
dy = ( MAX_Y - MIN_Y ) / HEIGHT
y = MIN_Y
for row in range ( HEIGHT ):
x = MIN_X
for col in range ( WIDTH ):
t[Index(row, col)] = multibrot_kernel(ComplexFloat64(x, y))
x += dx
y += dy
return t
_ = compute_multibrot()mojo build benchmarks/multibrot_set/multibrot.mojo
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot.exe.json ' ./benchmarks/multibrot_set/multibrot ' RESULTADO :
Punto de referencia 1: ./benchmarks/multibrot_set/multibrot
Tiempo (media ± σ): 135880,5 µs ± 1175,4 µs [Usuario: 133309,3 µs, Sistema: 1700,1 µs]
Rango (mín … máx): 134639,9 µs … 137621,4 µs 10 ejecuciones
fn mandelbrot_kernel_SIMD [
simd_width : Int
]( c : ComplexSIMD[float_type, simd_width]) -> SIMD [float_type, simd_width]:
""" A vectorized implementation of the inner mandelbrot computation. """
let cx = c.re
let cy = c.im
var x = SIMD [float_type, simd_width]( 0 )
var y = SIMD [float_type, simd_width]( 0 )
var y2 = SIMD [float_type, simd_width]( 0 )
var iters = SIMD [float_type, simd_width]( 0 )
var t : SIMD [DType.bool, simd_width] = True
for i in range ( MAX_ITERS ):
if not t.reduce_or():
break
y2 = y * y
y = x.fma(y + y, cy)
t = x.fma(x, y2) <= 4
x = x.fma(x, cx - y2)
iters = t.select(iters + 1 , iters)
return iters
fn compute_multibrot_parallelized () -> Tensor[float_type]:
let t = Tensor[float_type](height, width)
@parameter
fn worker ( row : Int):
let scale_x = (max_x - min_x) / width
let scale_y = (max_y - min_y) / height
@parameter
fn compute_vector [ simd_width : Int]( col : Int):
""" Each time we operate on a `simd_width` vector of pixels. """
let cx = min_x + (col + iota[float_type, simd_width]()) * scale_x
let cy = min_y + row * scale_y
let c = ComplexSIMD[float_type, simd_width](cx, cy)
t.data().simd_store[simd_width](
row * width + col, mandelbrot_kernel_SIMD[simd_width](c)
)
# Vectorize the call to compute_vector where call gets a chunk of pixels.
vectorize[simd_width, compute_vector](width)
# Parallelized
parallelize[worker](height, height)
return t
def main ():
_ = compute_multibrot_parallelized()mojo build benchmarks/multibrot_set/multibrot_mojo_parallelize.mojo
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_mojo_parallelize.exe.json ' ./benchmarks/multibrot_set/multibrot_mojo_parallelize ' RESULTADO :
Punto de referencia 1: ./benchmarks/multibrot_set/multibrot_mojo_parallelize
Tiempo (media ± σ): 7139,4 µs ± 596,4 µs [Usuario: 36535,2 µs, Sistema: 6670,1 µs]
Rango (mín … máx): 6222,6 µs … 8269,7 µs 10 ejecuciones
def mandelbrot_kernel(c):
z = c
for i in range(MAX_ITERS):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z.real * z.real + z.imag * z.imag > 4:
return i
return MAX_ITERS
def compute_mandelbrot():
t = [[0 for _ in range(WIDTH)] for _ in range(HEIGHT)] # Pixel matrix
dx = (MAX_X - MIN_X) / WIDTH
dy = (MAX_Y - MIN_Y) / HEIGHT
@par(collapse=2)
for row in range(HEIGHT):
for col in range(WIDTH):
t[row][col] = mandelbrot_kernel(complex(MIN_X + col * dx, MIN_Y + row * dy))
return t
compute_mandelbrot()
Para ejecución de prueba o trazado (código descomentado en el archivo)
CODON_PYTHON=/opt/homebrew/opt/[email protected]/Frameworks/Python.framework/Versions/3.11/lib/libpython3.11.dylib codon run --release benchmarks/multibrot_set/multibrot.codonConstruir y ejecutar
codon build --release -exe benchmarks/multibrot_set/multibrot.codon -o benchmarks/multibrot_set/multibrot_codon
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_codon.json ' ./benchmarks/multibrot_set/multibrot_codon ' RESULTADO :
Punto de referencia 1: ./benchmarks/multibrot_set/multibrot_codon
Tiempo (media ± σ): 44184,7 µs ± 1142,0 µs [Usuario: 248773,9 µs, Sistema: 72935,3 µs]
Rango (mín … máx): 42963,8 µs … 46456,2 µs 10 ejecuciones
codon build --release -exe benchmarks/multibrot_set/multibrot_codon_par.codon -o benchmarks/multibrot_set/multibrot_codon_par
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_codon_par.json ' ./benchmarks/multibrot_set/multibrot_codon_par ' # Merge all JSON files into benchmarks.json
python3 benchmarks/hyperfine-scripts/merge_jsons.py benchmarks/multibrot_set/ benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot2.py benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot3.py benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/advanced_statistics.py benchmarks/multibrot_set/benchmarks.json > benchmarks/multibrot_set/benchmarks.json.md
silicon benchmarks/multibrot_set/benchmarks.json.md -l python -o benchmarks/multibrot_set/benchmarks.json.md.pngEstadísticas avanzadas
Juntos
Ampliado
Detallado uno por uno
Lugares
Campo de golf:
Mandelbrot = Multibrot con power = 2
z = z ** power + c # You can change this for different setAlmohada incorporada ImagingEffectMandelbrot
Versión Exaloop Codon de Mandelbrot
Versión modular Mojo de Mandelbrot
Complejo Mojo squared_norm
Matplotlib Mandelbrot
En informática, el algoritmo de búsqueda binaria, también conocido como búsqueda de medio intervalo, búsqueda logarítmica o corte binario, es un algoritmo de búsqueda que encuentra la posición de un valor objetivo dentro de una matriz ordenada.
Hagamos algo de código con Python, Mojo, Swift, V, Julia, Nim, Zig.
Nota: Para las versiones de Python y Mojo , dejo algunas optimizaciones y hago que el código sea similar para medir y comparar.
from typing import List
import timeit
SIZE = 1000000
MAX_ITERS = 100
COLLECTION = tuple ( i for i in range ( SIZE )) # Make it aka at compile-time.
def python_binary_search ( element : int , array : List [ int ]) -> int :
start = 0
stop = len ( array ) - 1
while start <= stop :
index = ( start + stop ) // 2
pivot = array [ index ]
if pivot == element :
return index
elif pivot > element :
stop = index - 1
elif pivot < element :
start = index + 1
return - 1
def test_python_binary_search ():
_ = python_binary_search ( SIZE - 1 , COLLECTION )
print (
"Average execution time of func in sec" ,
timeit . timeit ( lambda : test_python_binary_search (), number = MAX_ITERS ),
) """Implements basic binary search."""
from Benchmark import Benchmark
from Vector import DynamicVector
alias SIZE = 1000000
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
fn mojo_binary_search ( element : Int , array : DynamicVector [ Int ]) - > Int :
var start = 0
var stop = len ( array ) - 1
while start <= stop :
let index = ( start + stop ) // 2
let pivot = array [ index ]
if pivot == element :
return index
elif pivot > element :
stop = index - 1
elif pivot < element :
start = index + 1
return - 1
@ parameter # statement runs at compile-time.
fn get_collection () - > DynamicVector [ Int ]:
var v = DynamicVector [ Int ]( SIZE )
for i in range ( SIZE ):
v . push_back ( i )
return v
fn test_mojo_binary_search () - > F64 :
fn test_closure ():
_ = mojo_binary_search ( SIZE - 1 , get_collection ())
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ test_closure ]()) / 1e9
print (
"Average execution time of func in sec " ,
test_mojo_binary_search (),
)Es la primera búsqueda binaria escrita en la comunidad Mojoby (@ego) y publicada en mojo-chat.
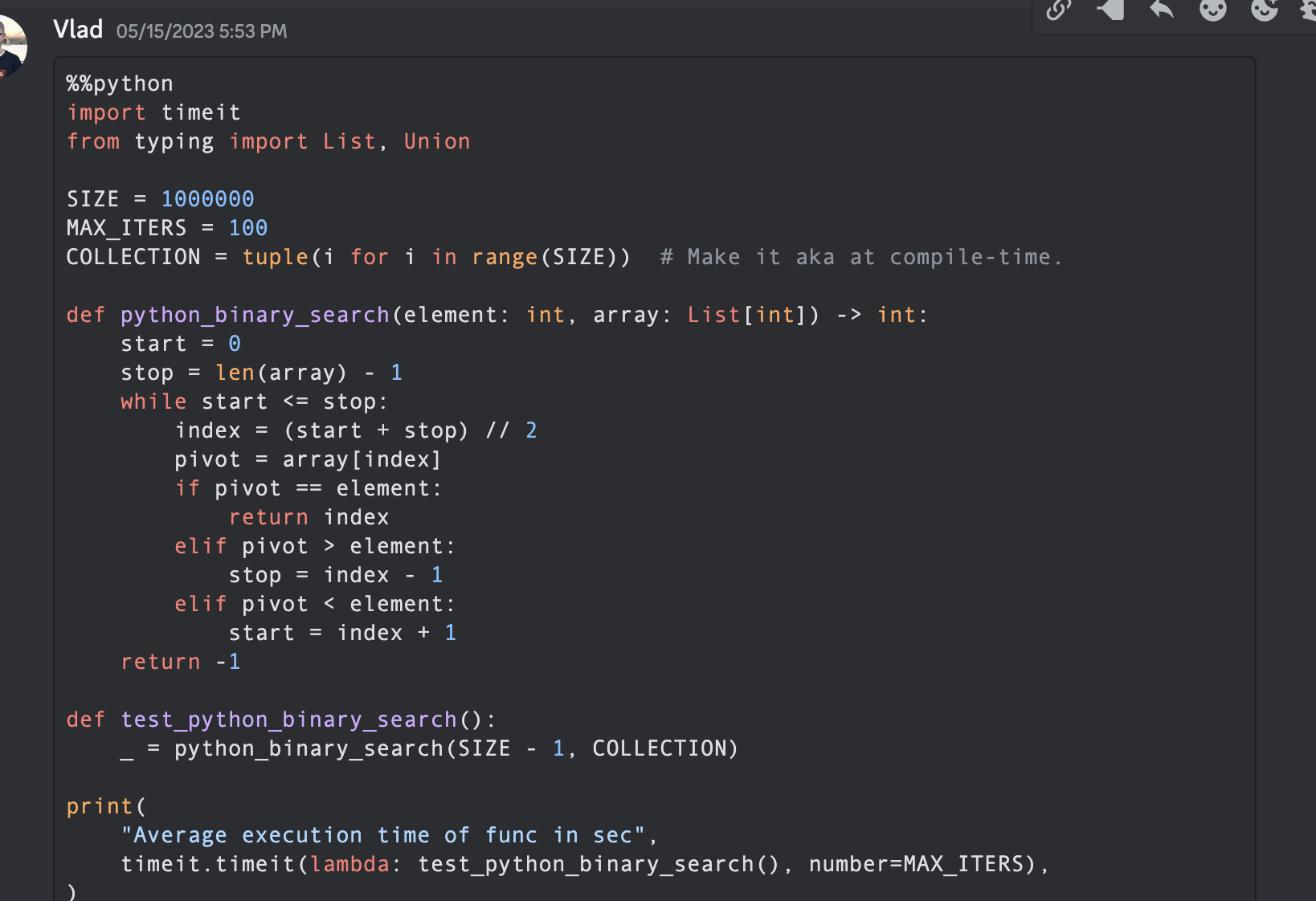
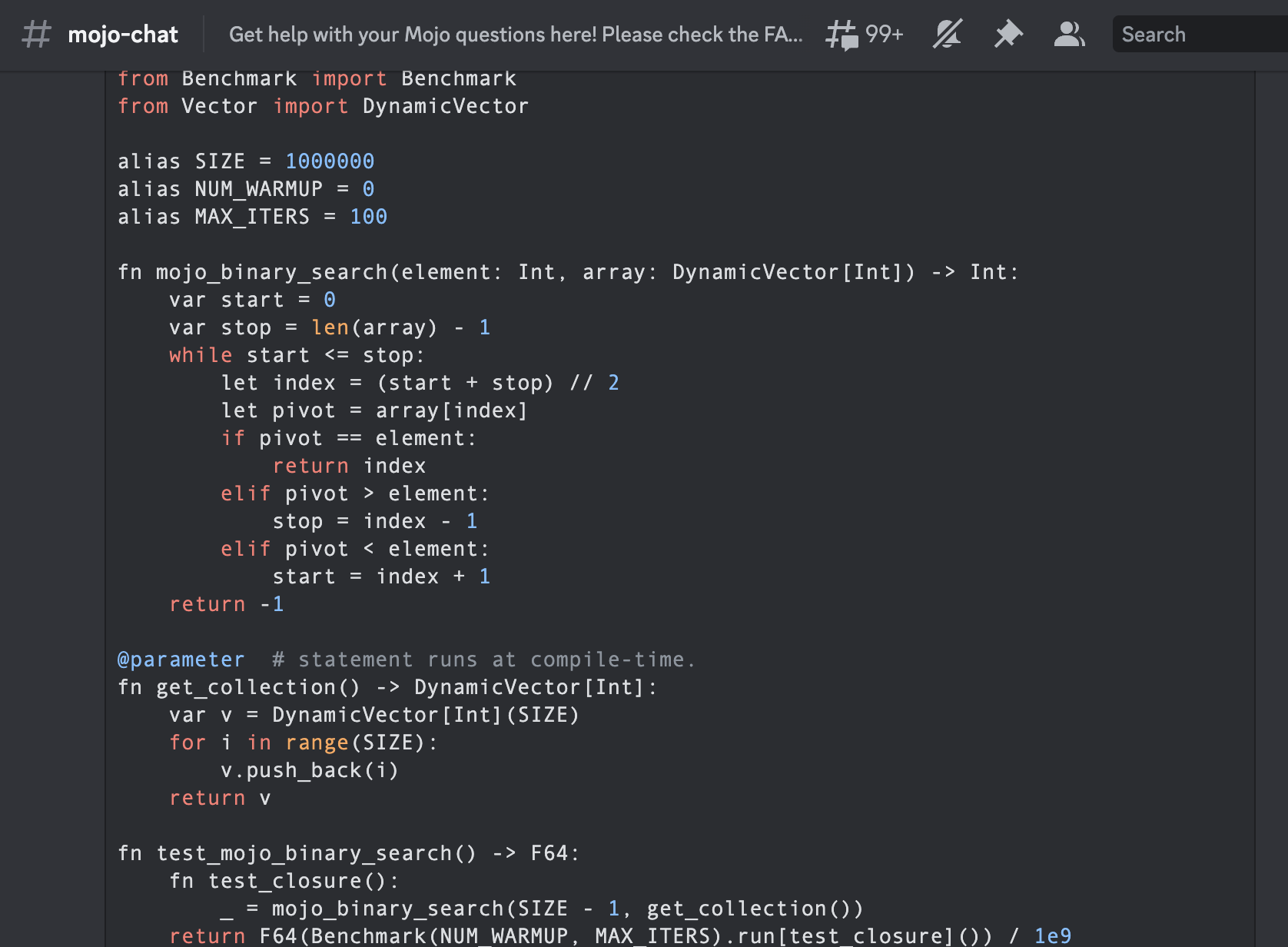
func binarySearch ( items : [ Int ] , elem : Int ) -> Int {
var low = 0
var high = items . count - 1
var mid = 0
while low <= high {
mid = Int ( ( high + low ) / 2 )
if items [ mid ] < elem {
low = mid + 1
} else if items [ mid ] > elem {
high = mid - 1
} else {
return mid
}
}
return - 1
}
let items = [ 1 , 2 , 3 , 4 , 0 ] . sorted ( )
let res = binarySearch ( items : items , elem : 4 )
print ( res ) function binarysearch (lst :: Vector{T} , val :: T ) where T
low = 1
high = length (lst)
while low ≤ high
mid = (low + high) ÷ 2
if lst[mid] > val
high = mid - 1
elseif lst[mid] < val
low = mid + 1
else
return mid
end
end
return 0
end proc binarySearch [T](a: openArray [T], key: T): int =
var b = len (a)
while result < b:
var mid = ( result + b) div 2
if a[mid] < key: result = mid + 1
else : b = mid
if result >= len (a) or a[ result ] != key: result = - 1
let res = @ [ 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 12 , 14 , 16 , 18 , 20 , 22 , 25 , 27 , 30 ]
echo binarySearch (res, 10 ) const std = @import ( "std" );
fn binarySearch ( comptime T : type , arr : [] const T , target : T ) ? usize {
var lo : usize = 0 ;
var hi : usize = arr . len - 1 ;
while ( lo <= hi ) {
var mid : usize = ( lo + hi ) / 2 ;
if ( arr [ mid ] == target ) {
return mid ;
} else if ( arr [ mid ] < target ) {
lo = mid + 1 ;
} else {
hi = mid - 1 ;
}
}
return null ;
} fn binary_search (a [] int , value int ) int {
mut low := 0
mut high := a.len - 1
for low < = high {
mid := (low + high) / 2
if a[mid] > value {
high = mid - 1
} else if a[mid] < value {
low = mid + 1
} else {
return mid
}
}
return - 1
}
fn main () {
search_list := [ 1 , 2 , 3 , 5 , 6 , 7 , 8 , 9 , 10 ]
println ( binary_search (search_list, 9 ))
} fn breadth_first_search_path (graph map [ string ][] string , vertex string , target string ) [] string {
mut path := [] string {}
mut visited := [] string {init: vertex}
mut queue := [][][] string {}
queue << [[vertex], path]
for queue.len > 0 {
mut idx := queue.len - 1
node := queue[idx][ 0 ][ 0 ]
path = queue[idx][ 1 ]
queue. delete (idx)
if node == target {
path << node
return path
}
for child in graph[node] {
mut tmp := path. clone ()
if child ! in visited {
visited << child
tmp << node
queue << [[child], tmp]
}
}
}
return path
}
fn main () {
graph := map {
'A' : [ 'B' , 'C' ]
'B' : [ 'A' , 'D' , 'E' ]
'C' : [ 'A' , 'F' ]
'D' : [ 'B' ]
'E' : [ 'B' , 'F' ]
'F' : [ 'C' , 'E' ]
}
println ( 'Graph: $graph ' )
path := breadth_first_search_path (graph, 'A' , 'F' )
println ( 'The shortest path from node A to node F is: $path ' )
assert path == [ 'A' , 'C' , 'F' ]
} import timeit
SIZE = 100
MAX_ITERS = 100
def _fizz_buzz (): # Make it aka at compile-time.
res = []
for n in range ( 1 , SIZE + 1 ):
if ( n % 3 == 0 ) and ( n % 5 == 0 ):
s = "FizzBuzz"
elif n % 3 == 0 :
s = "Fizz"
elif n % 5 == 0 :
s = "Buzz"
else :
s = str ( n )
res . append ( s )
return res
DATA = _fizz_buzz ()
def fizz_buzz ():
print ( " n " . join ( DATA ))
print (
"Average execution time of Python func in sec" ,
timeit . timeit ( lambda : fizz_buzz (), number = MAX_ITERS ),
)
# Average execution time of Python func in sec 0.005334990004485007 ( import '[java.io OutputStream])
( require '[clojure.java.io :as io])
( def devnull ( io/writer ( OutputStream/nullOutputStream )))
( defmacro timeit [n expr]
`(with-out-str ( time
( dotimes [_# ~( Math/pow 1 n)]
( binding [*out* devnull]
~expr)))))
( defmacro macro-fizz-buzz [n]
`( fn []
( print
~( apply str
( for [i ( range 1 ( inc n))]
( cond
( zero? ( mod i 15 )) " FizzBuzz n "
( zero? ( mod i 5 )) " Buzz n "
( zero? ( mod i 3 )) " Fizz n "
:else ( str i " n " )))))))
( print ( timeit 100 ( macro-fizz-buzz 100 )))
; ; "Elapsed time: 0.175486 msecs"
; ; Average execution time of Clojure func in sec 0.000175486 seconds from String import String
from Benchmark import Benchmark
alias SIZE = 100
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
@ parameter # statement runs at compile-time.
fn _fizz_buzz () - > String :
var res : String = ""
for n in range ( 1 , SIZE + 1 ):
if ( n % 3 == 0 ) and ( n % 5 == 0 ):
res += "FizzBuzz"
elif n % 3 == 0 :
res += "Fizz"
elif n % 5 == 0 :
res += "Buzz"
else :
res += String ( n )
res += " n "
return res
fn fizz_buzz ():
print ( _fizz_buzz ())
fn run_benchmark () - > F64 :
fn _closure ():
_ = fizz_buzz ()
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of func in sec " ,
run_benchmark (),
)
# Average execution time of func in sec 0.000104 Es el primer zumbido de Fizz escrito en Mojo por la comunidad (@Ego).
Usaremos el algoritmo de una referencia muy conocida para el libro de algoritmos Introducción a los algoritmos A3.
Su fama ha llevado al uso común de la abreviatura " CLRS " (Cormen, Leiserson, Rivest, Stein), o, en la primera edición, " CLR " (Cormen, Leiserson, Rivest).
Capítulo 2 "2.3.1 El enfoque de divide y vencerás".
% % python
import timeit
MAX_ITERS = 100
def merge ( A , p , q , r ):
n1 = q - p + 1
n2 = r - q
L = [ None ] * n1
R = [ None ] * n2
for i in range ( n1 ):
L [ i ] = A [ p + i ]
for j in range ( n2 ):
R [ j ] = A [ q + 1 + j ]
i = 0
j = 0
k = p
while i < n1 and j < n2 :
if L [ i ] <= R [ j ]:
A [ k ] = L [ i ]
i += 1
else :
A [ k ] = R [ j ]
j += 1
k += 1
while i < n1 :
A [ k ] = L [ i ]
i += 1
k += 1
while j < n2 :
A [ k ] = R [ j ]
j += 1
k += 1
def merge_sort ( A , p , r ):
if p < r :
q = ( p + r ) // 2
merge_sort ( A , p , q )
merge_sort ( A , q + 1 , r )
merge ( A , p , q , r )
def run_benchmark_merge_sort ():
A = [ 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 ]
merge_sort ( A , 0 , len ( A ) - 1 )
print (
"Average execution time of Python `merge_sort` in sec" ,
timeit . timeit ( lambda : run_benchmark_merge_sort (), number = MAX_ITERS ),
)
# Average execution time of Python `merge_sort` in sec 0.019136679999064654
def run_benchmark_sort ():
A = [ 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 ]
A . sort ()
print (
"Average execution time of Python builtin `sort` in sec" ,
timeit . timeit ( lambda : run_benchmark_sort (), number = MAX_ITERS ),
)
# Average execution time of Python builtin `sort` in sec 0.00019922800129279494 from Benchmark import Benchmark
from Vector import DynamicVector
from StaticTuple import StaticTuple
from Sort import sort
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
fn merge ( inout A : DynamicVector [ Int ], p : Int , q : Int , r : Int ):
let n1 = q - p + 1
let n2 = r - q
var L = DynamicVector [ Int ]( n1 )
var R = DynamicVector [ Int ]( n2 )
for i in range ( n1 ):
L [ i ] = A [ p + i ]
for j in range ( n2 ):
R [ j ] = A [ q + 1 + j ]
var i = 0
var j = 0
var k = p
while i < n1 and j < n2 :
if L [ i ] <= R [ j ]:
A [ k ] = L [ i ]
i += 1
else :
A [ k ] = R [ j ]
j += 1
k += 1
while i < n1 :
A [ k ] = L [ i ]
i += 1
k += 1
while j < n2 :
A [ k ] = R [ j ]
j += 1
k += 1
fn merge_sort ( inout A : DynamicVector [ Int ], p : Int , r : Int ):
if p < r :
let q = ( p + r ) // 2
merge_sort ( A , p , q )
merge_sort ( A , q + 1 , r )
merge ( A , p , q , r )
@ parameter
fn create_vertor () - > DynamicVector [ Int ]:
let st = StaticTuple [ MAX_ITERS , Int ]( 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 )
var v = DynamicVector [ Int ]( st . __len__ ())
for i in range ( st . __len__ ()):
v . push_back ( st [ i ])
return v
fn run_benchmark_merge_sort () - > F64 :
fn _closure ():
var A = create_vertor ()
merge_sort ( A , 0 , len ( A ) - 1 )
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of Mojo `merge_sort` in sec " ,
run_benchmark_merge_sort (),
)
# Average execution time of Mojo `merge_sort` in sec 1.1345999999999999e-05
fn run_benchmark_sort () - > F64 :
fn _closure ():
var A = create_vertor ()
sort ( A )
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of Mojo builtin `sort` in sec " ,
run_benchmark_sort (),
)
# Average execution time of Mojo builtin `sort` in sec 2.988e-06Puedes usarlo como:
# Usage: merge_sort
var A = create_vertor ()
merge_sort ( A , 0 , len ( A ) - 1 )
print ( len ( A ))
print ( A [ 0 ], A [ 99 ]) from Sort import sort es un poco más rápida que nuestra implementación, pero podemos optimizarla en profundidad en el lenguaje y, como es habitual, con algoritmos =) y paradigmas de programación.
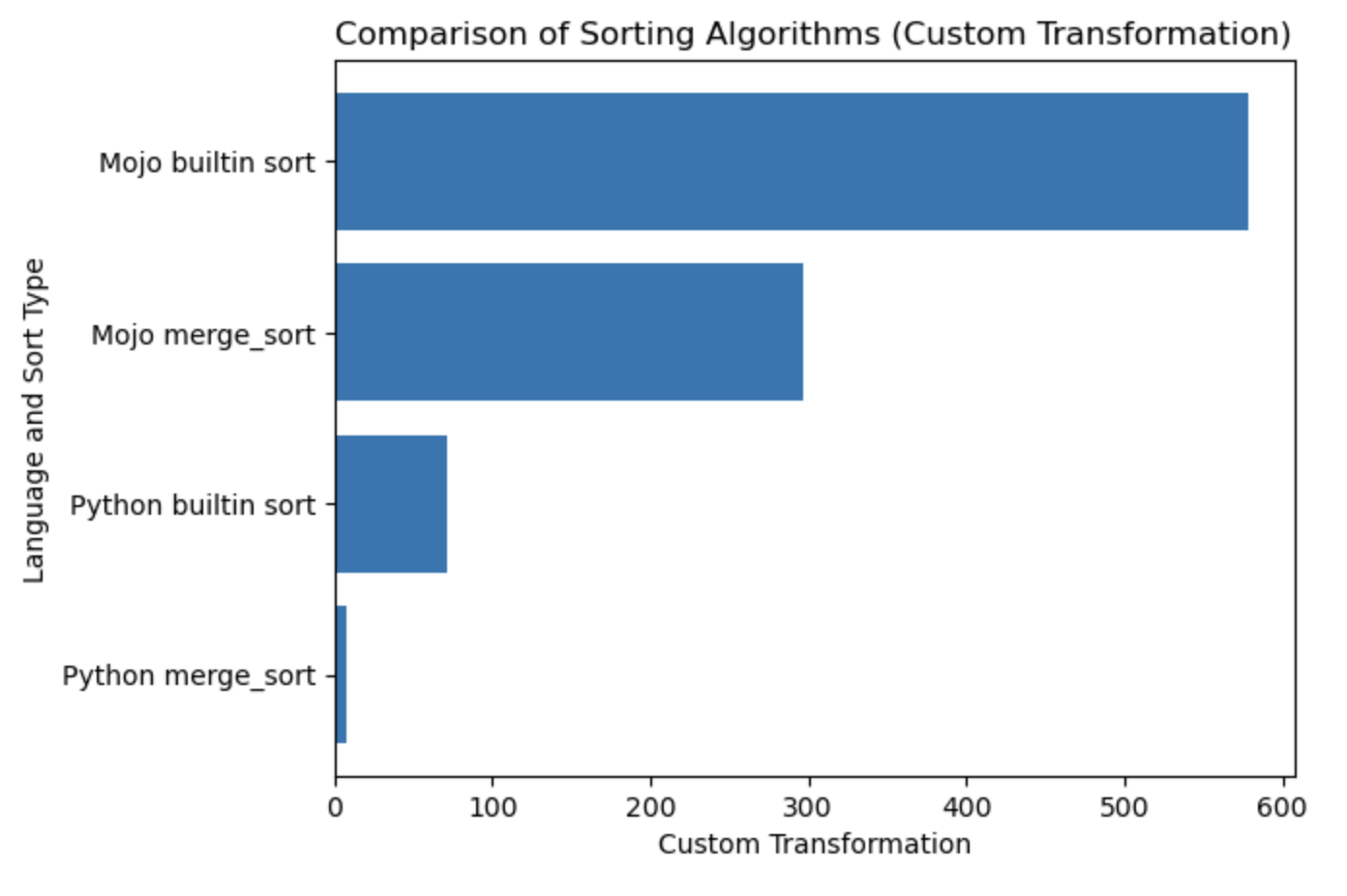
| Lang | segundo |
|---|---|
| merge_sort de Python | 0.019136679 |
| Clasificación incorporada de Python | 0.000199228 |
| Mojo merge_sort | 0.000011346 |
| Clasificación incorporada de Mojo | 0.000002988 |
Construyamos un gráfico para esta tabla.
#%%python
import matplotlib . pyplot as plt
import numpy as np
languages = [ 'Python merge_sort' , 'Python builtin sort' , 'Mojo merge_sort' , 'Mojo builtin sort' ]
seconds = [ 0.019136679 , 0.000199228 , 0.000011346 , 0.000002988 ]
# Apply a custom transformation to the values
transformed_seconds = [ np . sqrt ( 1 / x ) for x in seconds ]
plt . barh ( languages , transformed_seconds )
plt . xlabel ( 'Custom Transformation' )
plt . ylabel ( 'Language and Sort Type' )
plt . title ( 'Comparison of Sorting Algorithms (Custom Transformation)' )
plt . show ()Notas de la trama, más es mejor y más rápido.
Recomiendo encarecidamente comenzar desde aquí HelloMojo y comprender la parametrización de [parámetro] y [expresiones de parámetro] aquí. Como en este ejemplo:
fn concat [ len1 : Int , len2 : Int ]( lhs : MySIMD [ len1 ], rhs : MySIMD [ len2 ]) - > MySIMD [ len1 + len2 ]:
let result = MySIMD [ len1 + len2 ]()
for i in range ( len1 ):
result [ i ] = lhs [ i ]
for j in range ( len2 ):
result [ len1 + j ] = rhs [ j ]
return result
let a = MySIMD [ 2 ]( 1 , 2 )
let x = concat [ 2 , 2 ]( a , a )
x . dump () Tiempo de compilación [Parámetros]: fn concat[len1: Int, len2: Int] .
Tiempo de ejecución (Args) : fn concat(lhs: MySIMD, rhs: MySIMD) .
Parámetros Sintaxis PEP695 entre corchetes [] .
Ahora en Python:
def func ( a : _T , b : _T ) -> _T :
...Ahora en Mojo:
def func [ T ]( a : T , b : T ) -> T :
... Los [parámetros] tienen nombres y tipos como valores normales en un programa Mojo, pero parameters[] se evalúan en tiempo de compilación .
El programa en tiempo de ejecución puede usar el valor de [parámetros] , porque los parámetros se resuelven en tiempo de compilación antes de que el programa en tiempo de ejecución los necesite, pero las expresiones de parámetros en tiempo de compilación pueden no usar valores en tiempo de ejecución.
Self desde PEP673
fn __sub__ ( self , rhs : Self ) - > Self :
let result = MySIMD [ size ]()
for i in range ( size ):
result [ i ] = self [ i ] - rhs [ i ]
return resultEn los documentos puede encontrar campos de palabras, también conocidos como atributos de clase en Python.
Entonces, los llamas con dot .
from DType import DType
let bool_type = DType . bool from DType import DType
DType . si8 from DType import DType
from SIMD import SIMD , SI8
alias MY_SIMD_DType_si8 = SIMD [ DType . si8 , 1 ]
alias MY_SI8 = SI8
print ( MY_SIMD_DType_si8 == MY_SI8 )
# true from DType import DType
from SIMD import SIMD , SI8
from Vector import DynamicVector
from String import String
alias a = DynamicVector [ SIMD [ DType . si8 , 1 ]]
alias b = DynamicVector [ SI8 ]
print ( a == b )
print ( a == String )
print ( b == String )
# all true Entonces, String es solo un alias para algo como DynamicVector[SIMD[DType.si8, 1]] .
VariadicList para desestructurar/desempaquetar/acceder a argumentos from List import VariadicList
fn destructuring_arguments ( * args : Int ):
let my_var_list = VariadicList ( args )
for i in range ( len ( my_var_list )):
print ( "argument" , i , ":" , my_var_list [ i ])
destructuring_arguments ( 1 , 2 , 3 , 4 )Es muy útil para crear colecciones iniciales. Podemos escribir así:
from Vector import DynamicVector
from StaticTuple import StaticTuple
fn create_vertor () - > DynamicVector [ Int ]:
let st = StaticTuple [ 4 , Int ]( 1 , 2 , 3 , 4 )
var v = DynamicVector [ Int ]( st . __len__ ())
for i in range ( st . __len__ ()):
v . push_back ( st [ i ])
return v
v = create_vertor ()
print ( v [ 0 ], v [ 3 ])
# or
from List import VariadicList
fn create_vertor () - > DynamicVector [ Int ]:
let var_list = VariadicList ( 1 , 2 , 3 , 4 )
var v = DynamicVector [ Int ]( len ( var_list ))
for i in range ( len ( var_list )):
v . push_back ( var_list [ i ])
return v
v = create_vertor ()
print ( v [ 0 ], v [ 3 ])Leer más sobre la función def y fn
from String import String
# String concatenation
print ( String ( "'" ) + String ( 1 ) + "' n " )
# Python's join
print ( String ( "|" ). join ( "a" , "b" , "c" ))
# String format
from IO import _printf as print
let x : Int = 1
print ( "'%i' n " , x . value )Para una cadena, puede utilizar el segmento incorporado con formato de segmento de cadena [inicio: fin: paso].
from String import String
let hello_mojo = String ( "Hello Mojo!" )
print ( "Till the end:" , hello_mojo [ 0 ::])
print ( "Before last 2 chars:" , hello_mojo [ 0 : - 2 ])
print ( "From start to the end with step 2:" , hello_mojo [ 0 :: 2 ])
print ( "From start to the before last with step 3:" , hello_mojo [ 0 : - 1 : 3 ])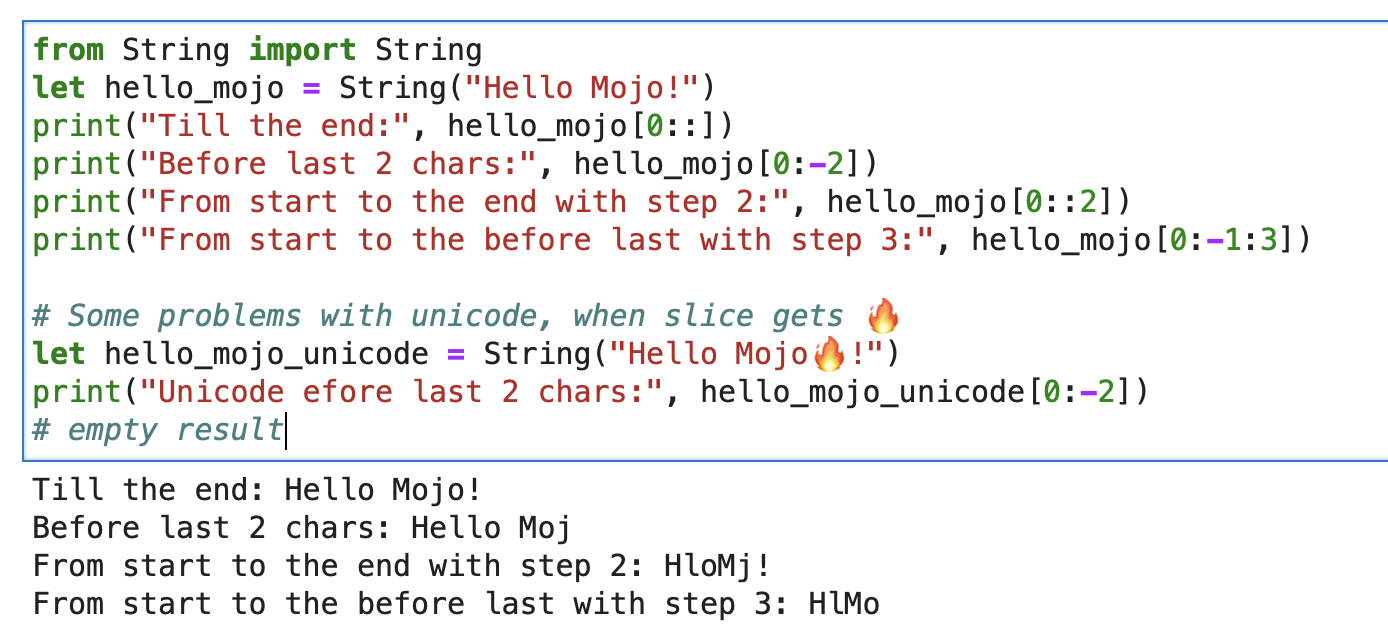
Hay algún problema con Unicode al cortar:
let hello_mojo_unicode = String ( "Hello Mojo!" )
print ( "Unicode efore last 2 chars:" , hello_mojo_unicode [ 0 : - 2 ])
# no result, silentsAquí hay una explicación y algo de discusión.
mbstowcs: convierte una cadena multibyte en una cadena de caracteres anchos
decorador struct también conocido como Python @dataclass . Generará métodos __init__ , __copyinit__ , __moveinit__ automáticamente.
@ value
struct dataclass :
var name : String
var age : Int Tenga en cuenta que el decorador @value solo funciona en tipos cuyos miembros se copyable y/o movable .
Tipos triviales. Este decorador le dice a Mojo que el tipo debe ser copiable __copyinit__ y móvil __moveinit__ . También le dice a Mojo que prefiera pasar el valor en los registros de la CPU. Permite que structs opten por pasar en un register en lugar de pasar por memory .
@ register_passable ( "trivial" )
struct Int :
var value : __mlir_type . `!pop.scalar<index>`Decoradores que proporcionan control total sobre las optimizaciones del compilador . Le indica al compilador que siempre incluya esta función cuando se llama.
@ always_inline
fn foo ( x : Int , y : Int ) - > Int :
return x + y
fn bar ( z : Int ):
let r = foo ( z , z ) # This call will be inlinedSe puede colocar en funciones anidadas que capturan valores de tiempo de ejecución para crear cierres de captura "paramétricos". Permite pasar cierres que capturan valores de tiempo de ejecución como valores de parámetros.
@ always_inline
@ parameter
fn test (): return Algunos ejemplos de casting
s : StringLiteral
let p = DTypePointer [ DType . si8 ]( s . data ()). bitcast [ DType . ui8 ]()
var result = 0
result += (( p . simd_load [ 64 ]( offset ) >> 6 ) != 0b10 ). cast [ DType . ui8 ](). reduce_add (). to_int ()
let rest_p : DTypePointer [ DType . ui8 ] = stack_allocation [ simd_width , UI8 , 1 ]()
from Bit import ctlz
s : String
i : Int
let code = s . buffer . data . load ( i )
let byte_length_code = ctlz ( ~ code ). to_int ()DTypePointer : almacena una dirección con un DType determinado, lo que le permite asignar, cargar y modificar datos con un acceso conveniente a las operaciones SIMD.
from Pointer import DTypePointer
from DType import DType
from Random import rand
from Memory import memset_zero
# `heap`
var my_pointer_on_heap = DTypePointer [ DType . ui8 ]. alloc ( 8 )
memset_zero ( my_pointer_on_heap , 8 )
# `stack or register`
var data = my_pointer_on_heap . simd_load [ 8 ]( 0 )
print ( data )
rand ( my_pointer_on_heap , 4 )
# `data` does not contain a reference to the `heap`, so load the data again
data = my_pointer_on_heap . simd_load [ 8 ]( 0 )
print ( data )
# simd_load and simd_store
var half = my_pointer_on_heap . simd_load [ 4 ]( 0 )
half = half + 1
my_pointer_on_heap . simd_store [ 4 ]( 4 , half )
print ( my_pointer_on_heap . simd_load [ 8 ]( 0 ))
# Pointer move back
my_pointer_on_heap -= 1
print ( my_pointer_on_heap . simd_load [ 8 ]( 0 ))
# Mast free memory
my_pointer_on_heap . free ()La estructura puede minimizar los posibles peligros de los punteros al limitar el alcance.
Excelente artículo en el blog de Mojo Dojo sobre DTypePointer aquí
Además de su ejemplo Matrix Struct y DTypePointer
El puntero almacena una dirección en cualquier register_passable type y asigna n cantidades de ellas al heap .
from Pointer import Pointer
from Memory import memset_zero
from String import String
@ register_passable # for syntaxt like `let coord = p1[0]` and let it be passed through registers.
struct Coord : # memory-only type
var x : UI8
var y : UI8
var p1 = Pointer [ Coord ]. alloc ( 2 )
memset_zero ( p1 , 2 )
var coord = p1 [ 0 ] # is an identifier to memory on the stack or in a register
print ( coord . x )
# Store the value
coord . x = 5
coord . y = 5
print ( coord . x )
# We need to store the data.
p1 . store ( 0 , coord )
print ( p1 [ 0 ]. x )
# Mast free memory
p1 . free ()Artículo completo sobre puntero
Más puntero y estructura de ejemplo
Modular Intrinsics es una especie de backends de ejecución :
Mojo-> Dialectos MLIR -> backends de ejecución con código y arquitecturas de optimización.
MLIR es una infraestructura de compilador que implementa varios pasos de transformación y optimización para diferentes arquitecturas y lenguajes de programación .
MLIR en sí no proporciona directamente funcionalidad para interactuar con llamadas al sistema del sistema operativo.
Que son interfaces de bajo nivel para los servicios del sistema operativo, generalmente se manejan en el nivel del lenguaje de programación de destino o del propio sistema operativo. MLIR está diseñado para ser independiente del idioma y del objetivo, y su objetivo principal es proporcionar una representación intermedia para realizar optimizaciones. Para realizar llamadas al sistema del sistema operativo en MLIR, necesitamos usar un backend específico del objetivo.
Pero con estos execution backends , básicamente, tenemos acceso a las llamadas al sistema del sistema operativo. Y tenemos todo el mundo de C/LLVM/Python bajo el capó.
Echemos un vistazo rápido a la práctica:
from OS import getenv
print ( getenv ( "PATH" ))
print ( getenv ( StringRef ( "PATH" )))
# or like this
from SIMD import SI8
from Intrinsics import external_call
var path1 = external_call [ "getenv" , StringRef ]( StringRef ( "PATH" ))
print ( path1 . data )
var path2 = external_call [ "getenv" , StringRef ]( "PATH" )
print ( path2 . data )
let abs_10 = external_call [ "abs" , SI8 , Int ]( - 10 )
print ( abs_10 ) En este ejemplo simple usamos external_call para obtener la variable de entorno del sistema operativo con un tipo de conversión entre las funciones Mojo y libc. ¡Muy genial, sí!
Tengo muchas ideas sobre este tema y espero ansiosamente la oportunidad de implementarlas pronto. Tomar medidas puede conducir a resultados sorprendentes =)
Hagamos algo interesante: llamemos a libc function gethostname.
La función tiene esta interfaz int gethostname (char *name, size_t size) .
Para eso podemos usar la función auxiliar external_call del módulo Intrinsics o escribir nuestro propio MLIR.
Vamos a codificar:
from Intrinsics import external_call
from SIMD import SIMD , SI8
from DType import DType
from Vector import DynamicVector
from DType import DType
from Pointer import DTypePointer , Pointer
# We can use `from String import String` but for clarification we will use a full form.
# DynamicVector[SIMD[DType.si8, 1]] == DynamicVector[SI8] == String
# Compile time stuff.
alias cArrayOfStrings = DynamicVector [ SIMD [ DType . si8 , 1 ]]
alias capacity = 1024
var c_pointer_to_array_of_strings = DTypePointer [ DType . si8 ]( cArrayOfStrings ( capacity ). data )
var c_int_result = external_call [ "gethostname" , Int , DTypePointer [ DType . si8 ], Int ]( c_pointer_to_array_of_strings , capacity )
let mojo_string_result = String ( c_pointer_to_array_of_strings . address )
print ( "C function gethostname result code:" , c_int_result )
print ( "C function gethostname result value:" , star_hostname ( mojo_string_result ))
@ always_inline
fn star_hostname ( hostname : String ) - > String :
# [Builtin Slice](https://docs.modular.com/mojo/MojoBuiltin/BuiltinSlice.html)
# string slice[start:end:step]
return hostname [ 0 : - 1 : 2 ]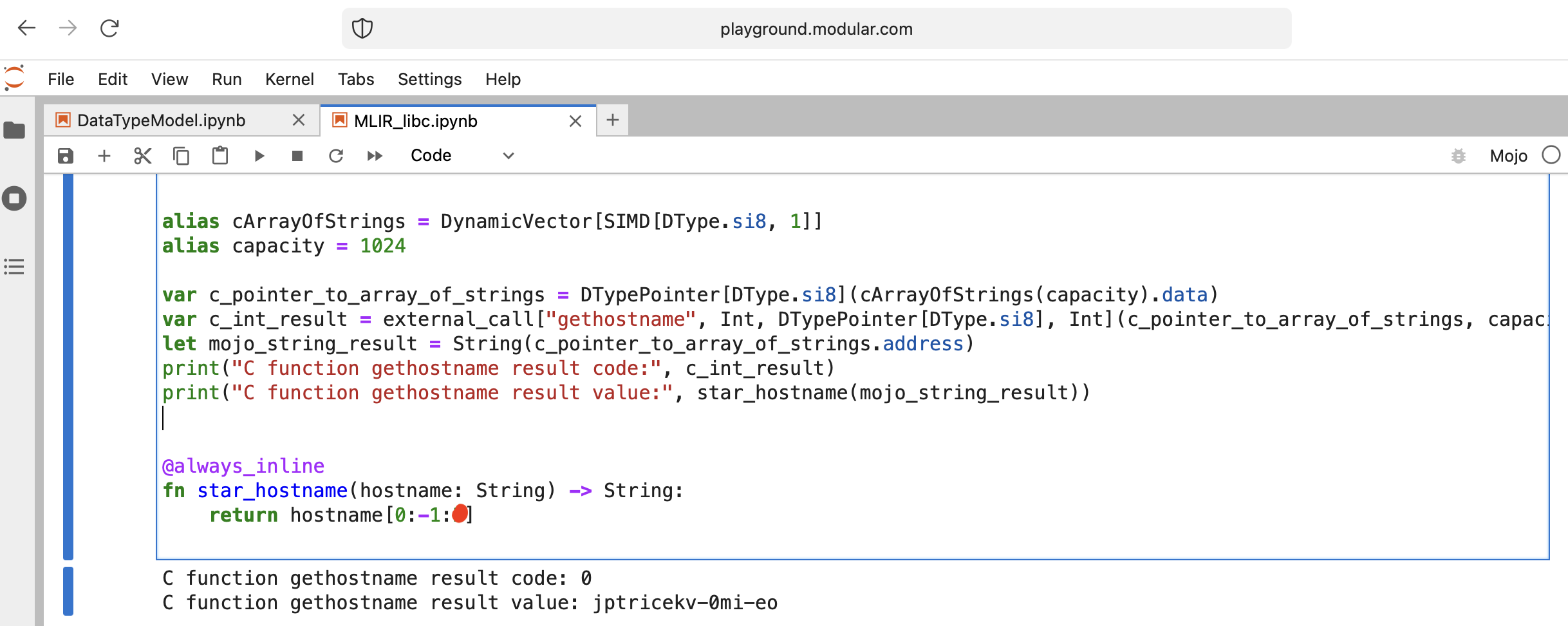
Hagamos algunas cosas para una WEB con Mojo. No tenemos acceso a Internet en Playground.modular.com, pero podemos robar y hacer algunas cosas interesantes como TCP en una máquina.
Escribamos el primer código cliente-servidor TCP en Mojo con PythonInterface
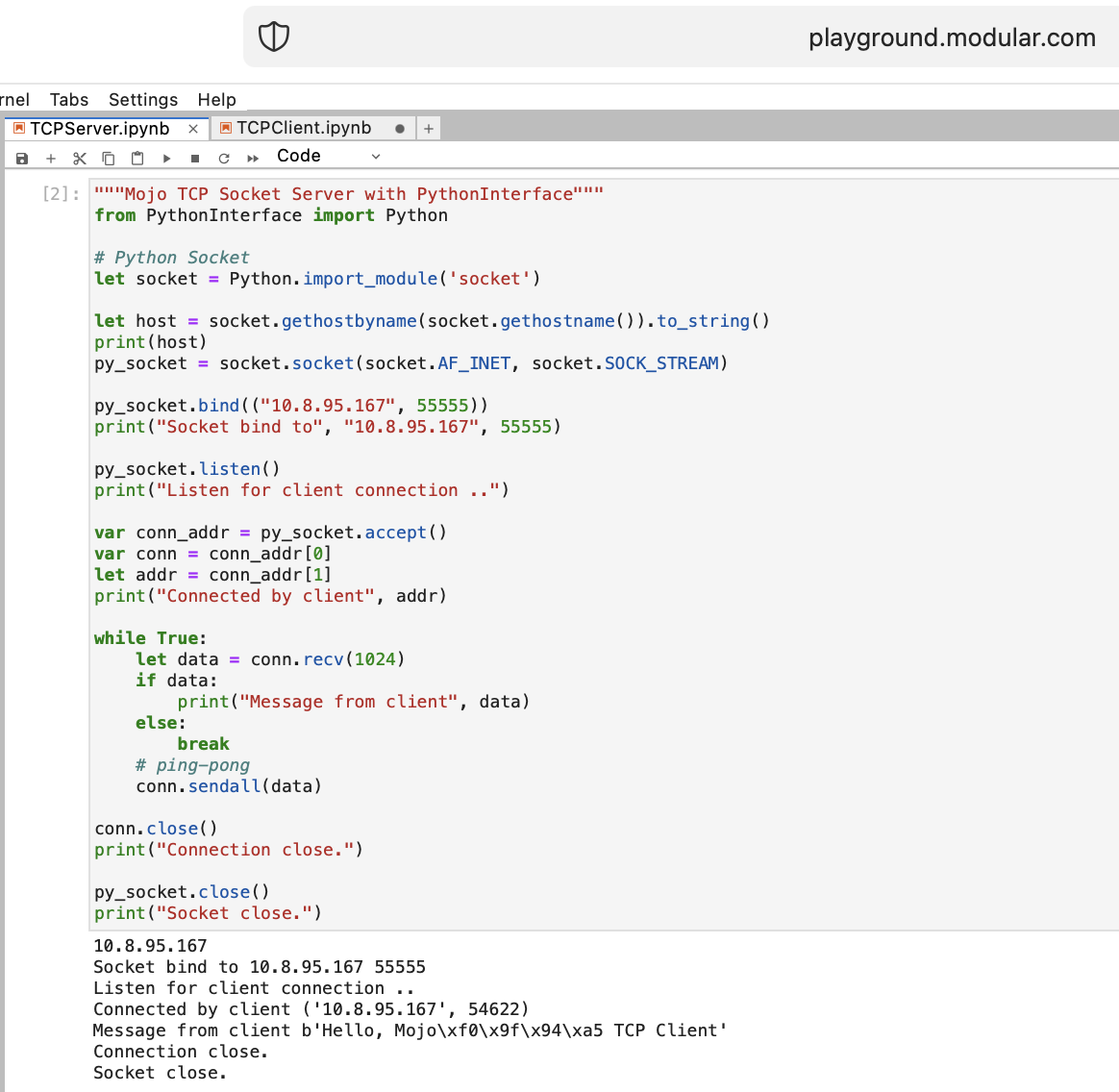
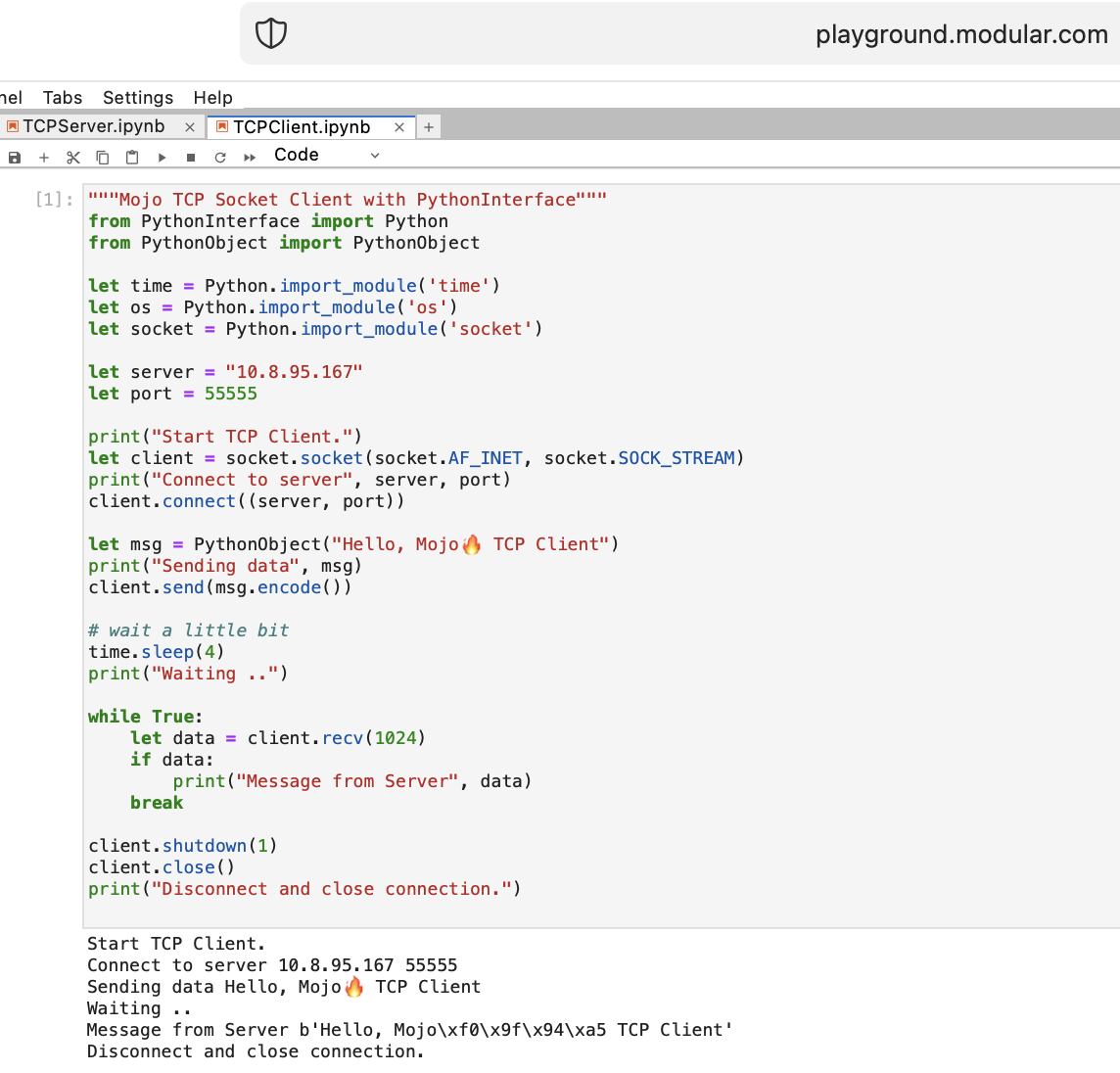
Debe crear dos cuadernos separados y ejecutar TCPSocketServer primero y luego TCPSocketClient .
La versión Python de este código es casi la misma, excepto:
with sintaxislet asignara, b = (1, 2)Después del Servidor TCP en Mojo seguimos adelante =)
Es una locura, ¡pero intentemos ejecutar el servidor web Python moderno FastAPI con Mojo!
Necesitamos cargar el código FastAPI en el área de juegos. Entonces, en su máquina local haga
pip install --target=web fastapi uvicorn
tar -czPf web.tar.gz web y cargue web.tar.gz en el patio de juegos a través de la interfaz web.
Luego necesitamos install , simplemente colocarlo en la carpeta adecuada:
% % python
import os
import site
site_packages_path = site . getsitepackages ()[ 0 ]
# install fastapi
os . system ( f"tar xzf web.tar.gz -C { site_packages_path } " )
os . system ( f"cp -r { site_packages_path } /web/* { site_packages_path } /" )
os . system ( f"ls { site_packages_path } | grep fastapi" )
# clean packages
os . system ( f"rm -rf { site_packages_path } /web" )
os . system ( f"rm web.tar.gz" ) from PythonInterface import Python
# Python fastapi
let fastapi = Python . import_module ( "fastapi" )
let uvicorn = Python . import_module ( "uvicorn" )
var app = fastapi . FastAPI ()
var router = fastapi . APIRouter ()
# tricky part
let py = Python ()
let py_code = """lambda: 'Hello Mojo!'"""
let py_obj = py . evaluate ( py_code )
print ( py_obj )
router . add_api_route ( "/mojo" , py_obj )
app . include_router ( router )
print ( "Start FastAPI WEB Server" )
uvicorn . run ( app )
print ( "Done" ) from PythonInterface import Python
let http_client = Python . import_module ( "http.client" )
let conn = http_client . HTTPConnection ( "localhost" , 8000 )
conn . request ( "GET" , "/mojo" )
let response = conn . getresponse ()
print ( response . status , response . reason , response . read ())Como de costumbre, debe crear dos cuadernos separados y ejecutar FastAPI primero y luego FastAPIClient .
Hay muchas preguntas abiertas, pero básicamente logramos el objetivo.
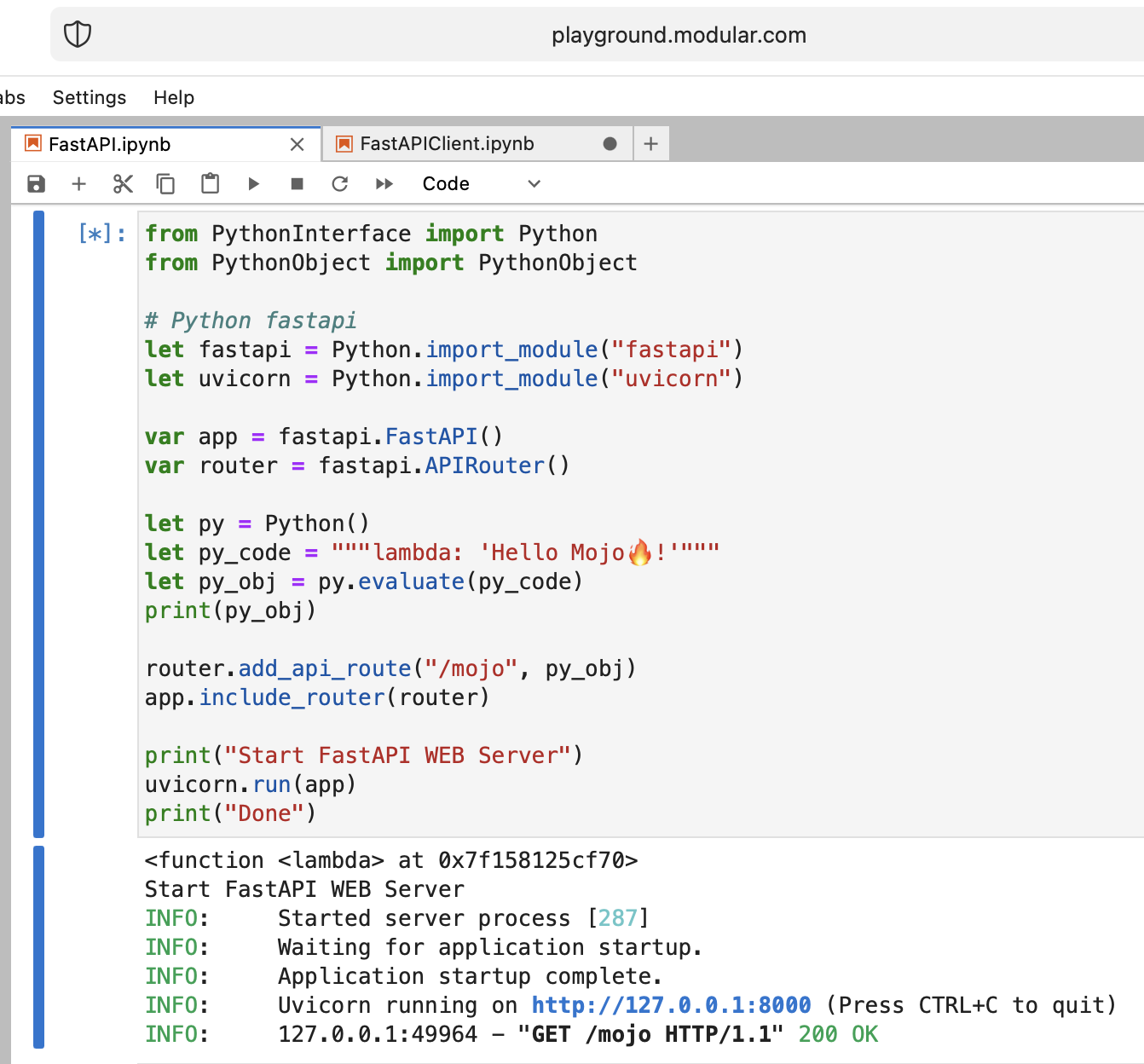
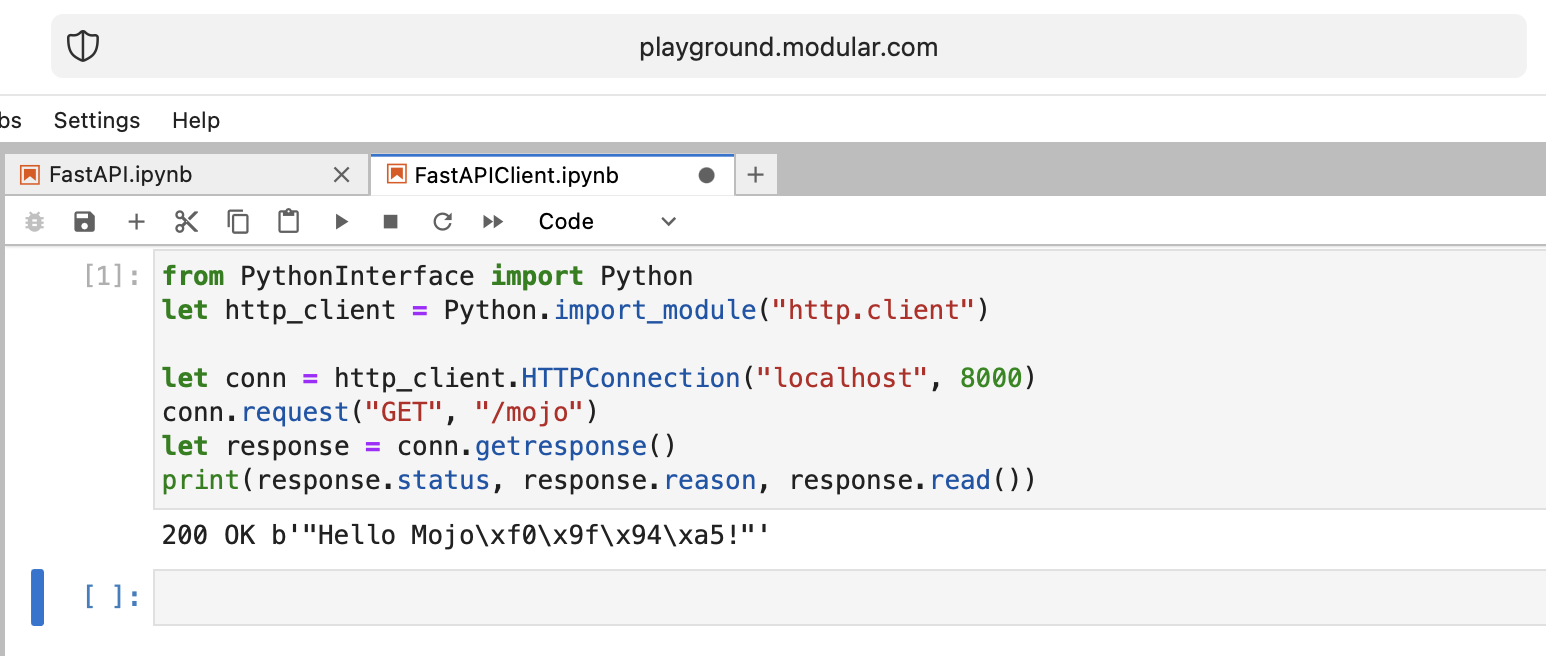
¡Muy bien hecho!
Algunas preguntas abiertas:
from PythonInterface import Python
let pyfn = Python . evaluate ( "lambda x, y: x+y" )
let functools = Python . import_module ( "functools" )
print ( functools . reduce ( pyfn , [ 1 , 2 , 3 , 4 ]))
# How to, without Mojo pyfn.so?
def pyfn ( x , y ):
retyrn x + y¡El futuro parece muy optimista!
Campo de golf:
Punto de referencia Mojo vs Numba por Nick Wogan
Utilidades del tiempo de Samay Kapadia @Zalando
Conexión a su área de juegos mojo desde VSCode o DataSpell
por Maxim Zaks
from String import String
from PythonInterface import Python
let pathlib = Python . import_module ( 'pathlib' )
let txt = pathlib . Path ( 'nfl.csv' ). read_text ()
let s : String = txt . to_string ()implementación de libc
from DType import DType
from Buffer import Buffer
from Pointer import Pointer
from String import String , chr
let hello = "hello"
let pointer = Pointer ( hello . data ())
print ( "variant 1" )
var result = String ()
for i in range ( len ( hello )):
result += chr ( pointer . bitcast [ Int8 ](). offset ( i ). load (). to_int ())
print ( result )
print ( "variant 2" )
print ( StringRef ( hello . data ()))
print ( "variant 3" )
print ( StringRef ( pointer . address ))
print ( "variant 4" )
let pm : Pointer [ __mlir_type . `!pop.scalar<si8>` ] = Pointer ( hello . data ())
print ( StringRef ( pm . address ))
print ( "variant 5" )
print ( String ( pointer . address ))
print ( "variant 6" )
let x = Buffer [ 8 , DType . int8 ]( pointer )
let array = x . simd_load [ 10 ]( 0 )
var result = String ()
for i in range ( len ( array )):
result += chr ( array [ i ]. to_int ())
print ( result )right click el archivo en el explorador y presione Open With > Editorselect all y copy.ipynbGithub lo representa correctamente y luego, si alguien quiere probar el código en su patio de juegos, puede copiar y pegar el código sin formato.
Es mi opinión personal, así que no me juzguéis demasiado duramente.
No puedo decir que Mojo sea un lenguaje de programación fácil de aprender, como Python por ejemplo.
Requiere mucha comprensión, paciencia y experiencia en cualquier otro lenguaje de programación.
Si quieres construir algo que no sea trivial, ¡será difícil pero divertido!
Han pasado 2 semanas desde que me embarqué en este viaje y estoy encantado de compartir que ahora me familiaricé bien con Mojo.
Las complejidades de su estructura y sintaxis han comenzado a desmoronarse ante mis ojos y me siento lleno de una nueva comprensión .
Me enorgullece decir que ahora puedo crear código con confianza en este lenguaje, lo que me permite dar vida a una amplia gama de ideas .
Mojo es un lenguaje de programación de Modular Inc. Por qué Mojo lo discutimos aquí. Acerca de la empresa sabemos menos, pero tiene un nombre muy interesante, Modular , al que se puede hacer referencia:
"En otras palabras: Mojo no es mágico, es modular".
Todo sobre informática, programación, AI/ML. Un muy buen nombre de dominio que describe con precisión el significado de la Empresa.
Hay algunos materiales adicionales sobre la historia de la marca de Modular y cómo ayudar a Modular a humanizar la IA a través de la marca.
Hoy me gustaría contar una historia sobre el problema de Python Enum. Como ingenieros de software, a menudo lo encontramos en una WEB. Supongamos que tenemos este esquema de base de datos (PostgreSQL) con enum de estado:
CREATE TYPE public .status_type AS ENUM (
' FIRST ' ,
' SECOND '
);En un código Python necesitamos nombres y valores como cadenas (supongamos que usamos GraphQL con algún tipo ENUM para nuestra interfaz), y necesitamos mantener su orden y tener la capacidad de comparar estas enumeraciones:
order2.status > order1.status > 'FIRST'
Entonces es un problema para la mayoría de los lenguajes comunes =) pero podemos usar una característica little-known de Python y anular el método de clase enum: __new__ .
MALE -> 1 , FEMALE -> 2 , como lo hace PostgreSQL.len ! import enum
from functools import total_ordering
@ total_ordering
@ enum . unique
class BaseUniqueSortedEnum ( enum . Enum ):
"""Base unique enum class with ordering."""
def __new__ ( cls , * args , ** kwargs ):
obj = object . __new__ ( cls )
obj . index = len ( cls . __members__ ) + 1 # This code line is a piece of advice, an insight and a tip!
return obj
# and then boring Python's magic methods as usual...
def __hash__ ( self ) -> int :
return hash (
f" { self . __module__ } _ { self . __class__ . __name__ } _ { self . name } _ { self . value } "
)
def __eq__ ( self , other ) -> bool :
self . _check_type ( other )
return super (). __eq__ ( other )
def __lt__ ( self , other ) -> bool :
self . _check_type ( other )
return self . index < other . index
def _check_type ( self , other ) -> None :
if type ( self ) != type ( other ):
raise TypeError ( f"Different types of Enum: { self } != { other } " )
class Dog ( BaseUniqueSortedEnum ):
# THIS ORDER MATTERS!
BLOODHOUND = "BLOODHOUND"
WEIMARANER = "WEIMARANER"
SAME = "SAME"
class Cat ( BaseUniqueSortedEnum )
# THIS ORDER MATTERS!
BRITISH = "BRITISH"
SCOTTISH = "SCOTTISH"
SAME = "SAME"
# and some tests
assert Dog . BLOODHOUND < Dog . WEIMARANER
assert Dog . BLOODHOUND <= Dog . WEIMARANER
assert Dog . BLOODHOUND != Dog . WEIMARANER
assert Dog . BLOODHOUND == Dog . BLOODHOUND
assert Dog . WEIMARANER == Dog . WEIMARANER
assert Dog . WEIMARANER > Dog . BLOODHOUND
assert Dog . WEIMARANER >= Dog . BLOODHOUND
assert Cat . BRITISH < Cat . SCOTTISH
assert Cat . BRITISH <= Cat . SCOTTISH
assert Cat . BRITISH != Cat . SCOTTISH
assert Cat . BRITISH == Cat . BRITISH
assert Cat . SCOTTISH == Cat . SCOTTISH
assert Cat . SCOTTISH > Cat . BRITISH
assert Cat . SCOTTISH >= Cat . BRITISH
assert hash ( Dog . BLOODHOUND ) == hash ( Dog . BLOODHOUND )
assert hash ( Dog . WEIMARANER ) == hash ( Dog . WEIMARANER )
assert hash ( Dog . BLOODHOUND ) != hash ( Dog . WEIMARANER )
assert hash ( Dog . SAME ) != hash ( Cat . SAME )
# raise TypeError
Dog . SAME <= Cat . SAME
Dog . SAME < Cat . SAME
Dog . SAME > Cat . SAME
Dog . SAME >= Cat . SAME
Dog . SAME != Cat . SAME El final de la historia. ¡Y use esta información Python ENUM para su buena codificación!


