q transformer
0.3.0
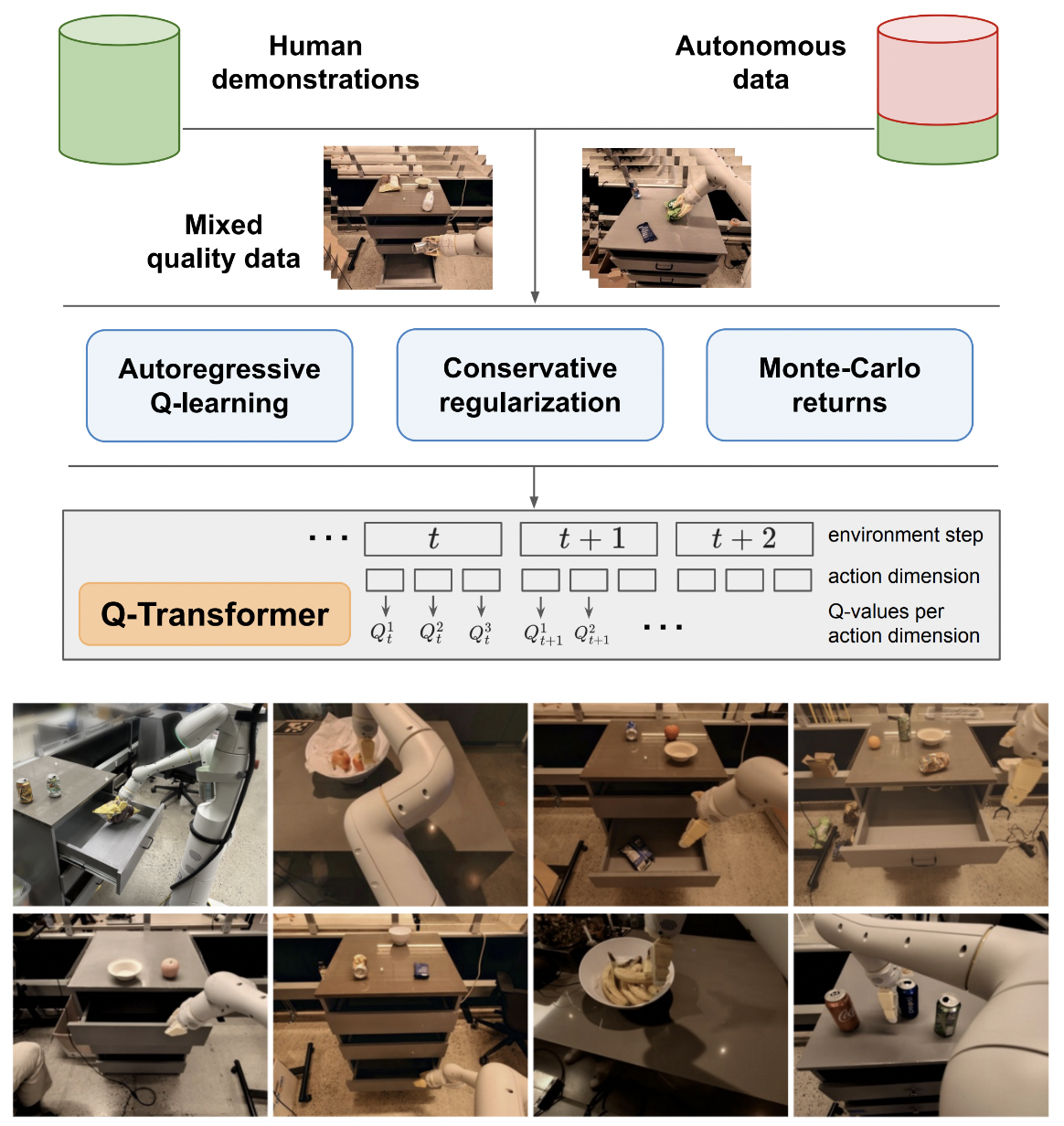
Implementación de Q-Transformer, aprendizaje por refuerzo fuera de línea escalable mediante funciones Q autorregresivas, de Google Deepmind
Mantendré la lógica del Q-learning en una sola acción solo para una comparación final con el Q-learning autorregresivo propuesto en múltiples acciones. También para servir como educación para mí y el público.
La formulación autorregresiva de Q-learning ha sido reproducida por Kotb et al.
$ pip install q-transformer import torch
from q_transformer import (
QRoboticTransformer ,
QLearner ,
Agent ,
ReplayMemoryDataset
)
# the attention model
model = QRoboticTransformer (
vit = dict (
num_classes = 1000 ,
dim_conv_stem = 64 ,
dim = 64 ,
dim_head = 64 ,
depth = ( 2 , 2 , 5 , 2 ),
window_size = 7 ,
mbconv_expansion_rate = 4 ,
mbconv_shrinkage_rate = 0.25 ,
dropout = 0.1
),
num_actions = 8 ,
action_bins = 256 ,
depth = 1 ,
heads = 8 ,
dim_head = 64 ,
cond_drop_prob = 0.2 ,
dueling = True
)
# you need to supply your own environment, by overriding BaseEnvironment
from q_transformer . mocks import MockEnvironment
env = MockEnvironment (
state_shape = ( 3 , 6 , 224 , 224 ),
text_embed_shape = ( 768 ,)
)
# env.init() should return instructions and initial state: Tuple[str, Tensor[*state_shape]]
# env(actions) should return rewards, next state, and done flag: Tuple[Tensor[()], Tensor[*state_shape], Tensor[()]]
# agent is a class that allows the q-model to interact with the environment to generate a replay memory dataset for learning
agent = Agent (
model ,
environment = env ,
num_episodes = 1000 ,
max_num_steps_per_episode = 100 ,
)
agent ()
# Q learning on the replay memory dataset on the model
q_learner = QLearner (
model ,
dataset = ReplayMemoryDataset (),
num_train_steps = 10000 ,
learning_rate = 3e-4 ,
batch_size = 4 ,
grad_accum_every = 16 ,
)
q_learner ()
# after much learning
# your robot should be better at selecting optimal actions
video = torch . randn ( 2 , 3 , 6 , 224 , 224 )
instructions = [
'bring me that apple sitting on the table' ,
'please pass the butter'
]
actions = model . get_optimal_actions ( video , instructions )Primer camino hacia el apoyo a una acción única
ofrecer una variante de maxvit sin normas por lotes, como se hace en el modelo meteorológico SOTA metnet3
agregar arquitectura de duelo profundo opcional
agregar aprendizaje Q de n pasos
construir la regularización conservadora
desarrollar la propuesta principal en papel (acciones discretas autorregresivas hasta la última acción, recompensa otorgada solo por la última)
improvisar la variante del cabezal decodificador, en lugar de concatenar acciones previas en la etapa de fotogramas + tokens aprendidos. en otras palabras, utilice el codificador-decodificador clásico
rehacer maxvit con incrustaciones rotativas axiales + puerta sigmoidea para no atender nada. habilite la atención flash para maxvit con este cambio
Cree una clase de creación de conjuntos de datos simple, tomando en cuenta el entorno y el modelo y devolviendo una carpeta que pueda ser aceptada por un ReplayDataset
ReplayDataset que lleva en la carpeta manejar múltiples instrucciones correctamente
mostrar un ejemplo simple de un extremo a otro, en el mismo estilo que todos los demás repositorios
no manejar instrucciones, aprovechar el acondicionador nulo en la biblioteca CFG
caché kv para decodificación de acciones
para la exploración, permita aleatorizar finamente un subconjunto de acciones, y no todas las acciones a la vez
Consulte a algunos expertos en RL y averigüe si hay nuevos avances para resolver el sesgo delirante.
descubrir si uno puede entrenar con órdenes de acciones aleatorias: el orden podría enviarse como un condicionamiento que se concatena o se suma antes de las capas de atención
función de búsqueda de haz simple para acciones óptimas
improvisar atención cruzada a acciones pasadas y estados de paso de tiempo, estilo transformador-xl (con abandono de memoria estructurada)
vea si la idea principal de este artículo es aplicable a los modelos de lenguaje aquí
@inproceedings { qtransformer ,
title = { Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions } ,
authors = { Yevgen Chebotar and Quan Vuong and Alex Irpan and Karol Hausman and Fei Xia and Yao Lu and Aviral Kumar and Tianhe Yu and Alexander Herzog and Karl Pertsch and Keerthana Gopalakrishnan and Julian Ibarz and Ofir Nachum and Sumedh Sontakke and Grecia Salazar and Huong T Tran and Jodilyn Peralta and Clayton Tan and Deeksha Manjunath and Jaspiar Singht and Brianna Zitkovich and Tomas Jackson and Kanishka Rao and Chelsea Finn and Sergey Levine } ,
booktitle = { 7th Annual Conference on Robot Learning } ,
year = { 2023 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Kumar2023MaintainingPI ,
title = { Maintaining Plasticity in Continual Learning via Regenerative Regularization } ,
author = { Saurabh Kumar and Henrik Marklund and Benjamin Van Roy } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:261076021 }
}

