perfusion pytorch
0.1.23
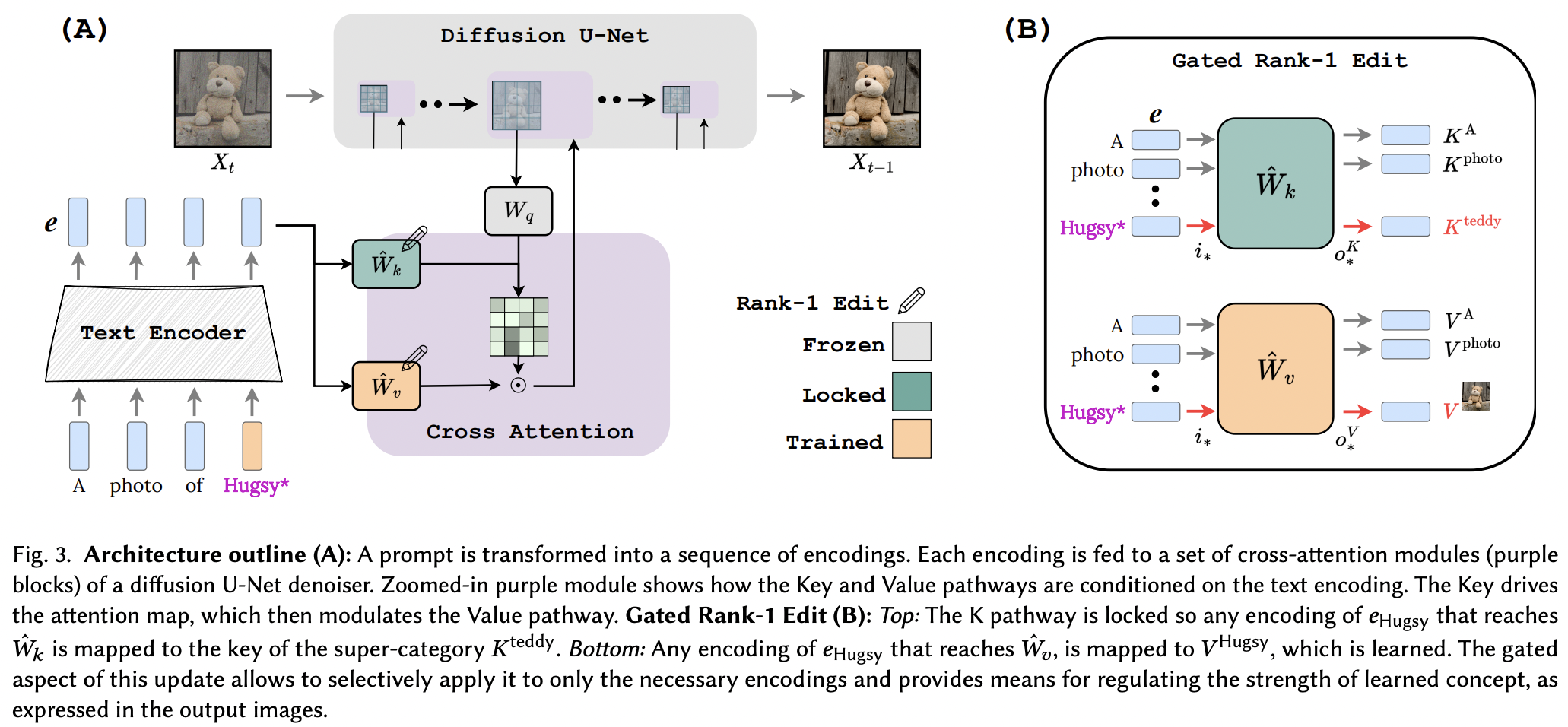
Implementación de edición de rango uno con llave. página del proyecto
El punto fuerte de este documento son los parámetros adicionales extremadamente bajos por concepto agregado, hasta 100 kb.
Parece que aplicaron con éxito la técnica de edición de rango 1 de un artículo de edición de memoria para LLM, con algunas mejoras. También identificaron que las claves determinan el "dónde" del nuevo concepto, mientras que los valores determinan el "qué", y proponen un bloqueo de clave local/global a un concepto de superclase (mientras aprenden los valores).
Para los investigadores, si este artículo es correcto, las herramientas de este repositorio deberían funcionar para cualquier otra red de texto a <insert modality> que utilice condicionamiento de atención cruzada. solo un pensamiento
StabilityAI por el generoso patrocinio, así como a mis otros patrocinadores.
Yoad Tewel por las múltiples revisiones de código y correos electrónicos aclaratorios
¡Brad Vidler por precalcular la matriz de covarianza para el CLIP utilizado en Stable Diffusion 1.5!
Todos los mantenedores de OpenClip, por sus modelos de texto-imagen de aprendizaje contrastivo de código abierto SOTA.
$ pip install perfusion-pytorch import torch
from torch import nn
from perfusion_pytorch import Rank1EditModule
to_keys = nn . Linear ( 768 , 320 , bias = False )
to_values = nn . Linear ( 768 , 320 , bias = False )
wrapped_to_keys = Rank1EditModule (
to_keys ,
is_key_proj = True
)
wrapped_to_values = Rank1EditModule (
to_values
)
text_enc = torch . randn ( 4 , 77 , 768 ) # regular input
text_enc_with_superclass = torch . randn ( 4 , 77 , 768 ) # init_input in algorithm 1, for key-locking
concept_indices = torch . randint ( 0 , 77 , ( 4 ,)) # index where the concept or superclass concept token is in the sequence
key_pad_mask = torch . ones ( 4 , 77 ). bool ()
keys = wrapped_to_keys (
text_enc ,
concept_indices = concept_indices ,
text_enc_with_superclass = text_enc_with_superclass ,
)
values = wrapped_to_values (
text_enc ,
concept_indices = concept_indices ,
text_enc_with_superclass = text_enc_with_superclass ,
)
# after much training ...
wrapped_to_keys . eval ()
wrapped_to_values . eval ()
keys = wrapped_to_keys ( text_enc )
values = wrapped_to_values ( text_enc ) El repositorio también contiene un EmbeddingWrapper que facilita el entrenamiento en un nuevo concepto (y la eventual inferencia con múltiples conceptos).
import torch
from torch import nn
from perfusion_pytorch import EmbeddingWrapper
embed = nn . Embedding ( 49408 , 512 ) # open clip embedding, somewhere in the module tree of stable diffusion
# wrap it, and will automatically create a new concept for learning, based on the superclass embed string
wrapped_embed = EmbeddingWrapper (
embed ,
superclass_string = 'dog'
)
# now just pass in your prompts with the superclass id
embeds_with_new_concept , embeds_with_superclass , embed_mask , concept_indices = wrapped_embed ([
'a portrait of dog' ,
'dog running through a green field' ,
'a man walking his dog'
]) # (3, 77, 512), (3, 77, 512), (3, 77), (3,)
# now pass both embeds through clip text transformer
# the embed_mask needs to be passed to the cross attention as key padding mask Si puede identificar la instancia CLIP dentro de la instancia de difusión estable, también puede pasarla directamente a OpenClipEmbedWrapper para obtener todo lo que necesita para las capas de atención cruzada.
ex.
from perfusion_pytorch import OpenClipEmbedWrapper
texts = [
'a portrait of dog' ,
'dog running through a green field' ,
'a man walking his dog'
]
wrapped_clip_with_new_concept = OpenClipEmbedWrapper (
stable_diffusion . path . to . clip ,
superclass_string = 'dog'
)
text_enc , superclass_enc , mask , indices = wrapped_clip_with_new_concept ( texts )
# (3, 77, 512), (3, 77, 512), (3, 77), (3,) conéctese con SD 1.5, comenzando con dreambooth-sd de xiao
muestre un ejemplo en el archivo Léame para realizar inferencias con múltiples conceptos
inferir automáticamente dónde están las claves y la proyección de valores si no se especifica para la función make_key_value_proj_rank1_edit_modules_
El contenedor de incrustación debe encargarse de sustituirlo por el ID del token de superclase y devolver la incrustación por la superclase.
revisar múltiples conceptos - gracias a Yoad
Ofrecer una función que conecta la atención cruzada.
manejar múltiples conceptos en un solo mensaje en la inferencia: suma del término sigmoideo + resultados
Ofrecer una manera de combinar conceptos aprendidos por separado de múltiples Rank1EditModule en uno solo para inferencia.
Rank1EditModule s agregar el concepto de enmascaramiento de disparo cero propuesto en el artículo
cuidar la función que toma el conjunto de datos y el codificador de texto y precalcula la matriz de covarianza necesaria para la actualización de rango 1
en lugar de que el investigador se preocupe por las diferentes tasas de aprendizaje, ofrezca el truco del gradiente fraccionario de otro artículo (para aprender el concepto de incrustación)
@article { Tewel2023KeyLockedRO ,
title = { Key-Locked Rank One Editing for Text-to-Image Personalization } ,
author = { Yoad Tewel and Rinon Gal and Gal Chechik and Yuval Atzmon } ,
journal = { ACM SIGGRAPH 2023 Conference Proceedings } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:258436985 }
} @inproceedings { Meng2022LocatingAE ,
title = { Locating and Editing Factual Associations in GPT } ,
author = { Kevin Meng and David Bau and Alex Andonian and Yonatan Belinkov } ,
booktitle = { Neural Information Processing Systems } ,
year = { 2022 } ,
url = { https://api.semanticscholar.org/CorpusID:255825985 }
}

