tab transformer pytorch
0.4.1
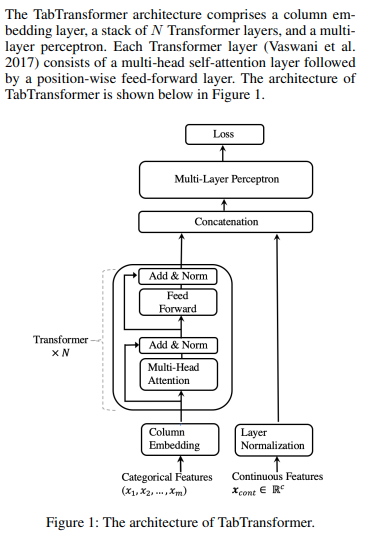
Implementación de Tab Transformer, red de atención para datos tabulares, en Pytorch. Esta arquitectura simple estuvo a un pelo del rendimiento de GBDT.
Actualización: Amazon AI afirma haber vencido a GBDT con Atención en un conjunto de datos tabulares del mundo real (prediciendo el costo de envío).
$ pip install tab-transformer-pytorch import torch
import torch . nn as nn
from tab_transformer_pytorch import TabTransformer
cont_mean_std = torch . randn ( 10 , 2 )
model = TabTransformer (
categories = ( 10 , 5 , 6 , 5 , 8 ), # tuple containing the number of unique values within each category
num_continuous = 10 , # number of continuous values
dim = 32 , # dimension, paper set at 32
dim_out = 1 , # binary prediction, but could be anything
depth = 6 , # depth, paper recommended 6
heads = 8 , # heads, paper recommends 8
attn_dropout = 0.1 , # post-attention dropout
ff_dropout = 0.1 , # feed forward dropout
mlp_hidden_mults = ( 4 , 2 ), # relative multiples of each hidden dimension of the last mlp to logits
mlp_act = nn . ReLU (), # activation for final mlp, defaults to relu, but could be anything else (selu etc)
continuous_mean_std = cont_mean_std # (optional) - normalize the continuous values before layer norm
)
x_categ = torch . randint ( 0 , 5 , ( 1 , 5 )) # category values, from 0 - max number of categories, in the order as passed into the constructor above
x_cont = torch . randn ( 1 , 10 ) # assume continuous values are already normalized individually
pred = model ( x_categ , x_cont ) # (1, 1) 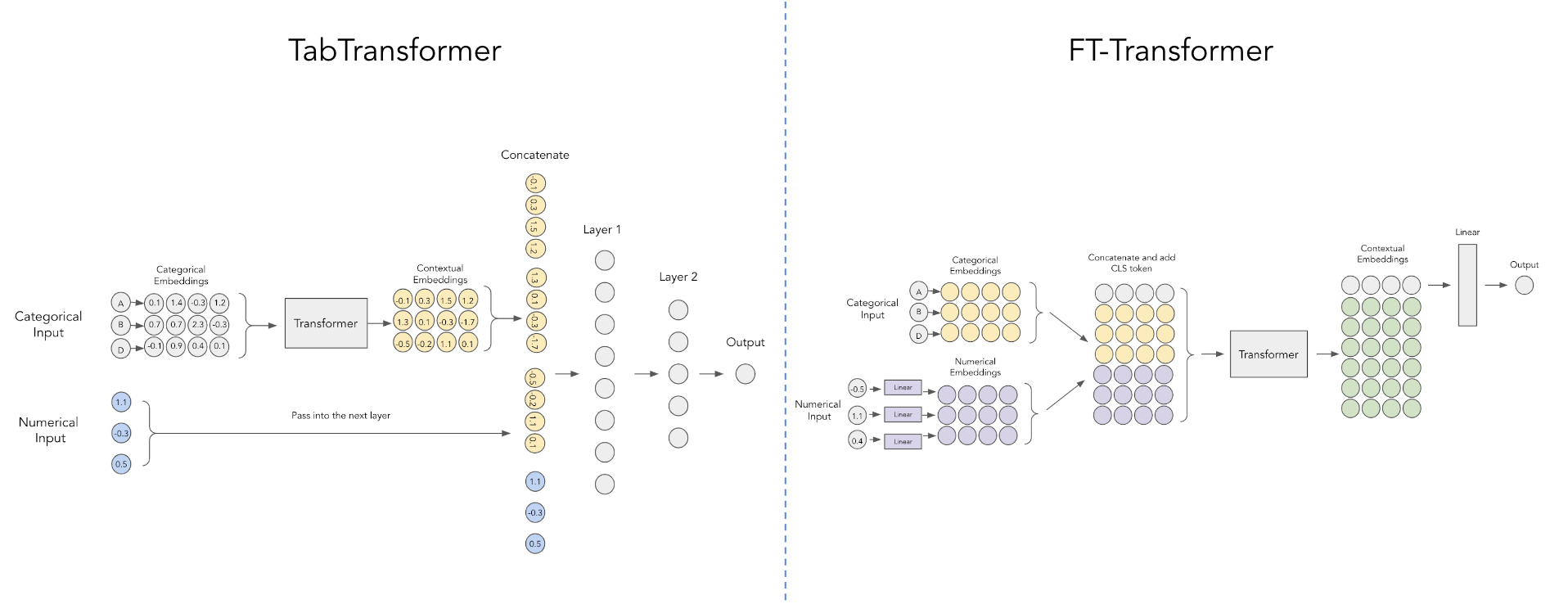
Este artículo de Yandex mejora Tab Transformer mediante el uso de un esquema más simple para incrustar los valores numéricos continuos como se muestra en el diagrama anterior, cortesía de esta publicación de Reddit.
Incluido en este repositorio solo para una comparación conveniente con Tab Transformer
import torch
from tab_transformer_pytorch import FTTransformer
model = FTTransformer (
categories = ( 10 , 5 , 6 , 5 , 8 ), # tuple containing the number of unique values within each category
num_continuous = 10 , # number of continuous values
dim = 32 , # dimension, paper set at 32
dim_out = 1 , # binary prediction, but could be anything
depth = 6 , # depth, paper recommended 6
heads = 8 , # heads, paper recommends 8
attn_dropout = 0.1 , # post-attention dropout
ff_dropout = 0.1 # feed forward dropout
)
x_categ = torch . randint ( 0 , 5 , ( 1 , 5 )) # category values, from 0 - max number of categories, in the order as passed into the constructor above
x_numer = torch . randn ( 1 , 10 ) # numerical value
pred = model ( x_categ , x_numer ) # (1, 1) Para someterse al tipo de capacitación no supervisada que se describe en el documento, primero puede convertir los tokens de sus categorías a los identificadores únicos apropiados y luego usar Electra en model.transformer .
@misc { huang2020tabtransformer ,
title = { TabTransformer: Tabular Data Modeling Using Contextual Embeddings } ,
author = { Xin Huang and Ashish Khetan and Milan Cvitkovic and Zohar Karnin } ,
year = { 2020 } ,
eprint = { 2012.06678 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @article { Gorishniy2021RevisitingDL ,
title = { Revisiting Deep Learning Models for Tabular Data } ,
author = { Yu. V. Gorishniy and Ivan Rubachev and Valentin Khrulkov and Artem Babenko } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2106.11959 }
} @article { Zhu2024HyperConnections ,
title = { Hyper-Connections } ,
author = { Defa Zhu and Hongzhi Huang and Zihao Huang and Yutao Zeng and Yunyao Mao and Banggu Wu and Qiyang Min and Xun Zhou } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2409.19606 } ,
url = { https://api.semanticscholar.org/CorpusID:272987528 }
}

