PALM E
0.0.4

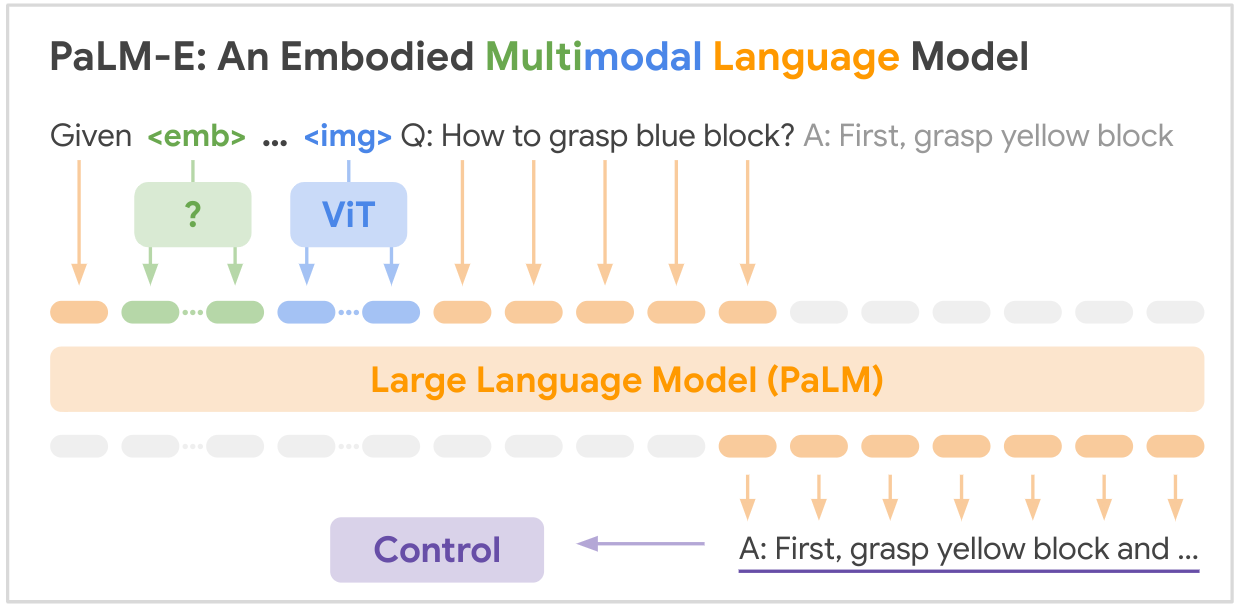
Esta es la implementación de código abierto del modelo básico multimodal SOTA "PALM-E: An Embodied Multimodal Language Model" de Google. PALM-E es un único modelo multimodal incorporado de gran tamaño, que puede abordar una variedad de tareas de razonamiento incorporado, desde una variedad de modalidades de observación, en múltiples realizaciones y, además, muestra una transferencia positiva: el modelo se beneficia de una capacitación conjunta diversa en los dominios del lenguaje, la visión y el lenguaje visual a escala de Internet.
ENLACE DEL PAPEL: PaLM-E: un modelo de lenguaje multimodal incorporado
pip install palme import torch
from palme . model import PalmE
#usage
img = torch . randn ( 1 , 3 , 256 , 256 )
caption = torch . randint ( 0 , 20000 , ( 1 , 1024 ))
model = PalmE ()
output = model ( img , caption )
print ( output . shape ) # (1, 1024, 20000)
A continuación se muestra una tabla resumen de los conjuntos de datos clave mencionados en el artículo:
| Conjunto de datos | Tareas | Tamaño | Enlace |
|---|---|---|---|
| APISONAR | Planificación de manipulación robótica, VQA. | 96.000 escenas | Conjunto de datos personalizado |
| Tabla de idiomas | Planificación de manipulación robótica. | Conjunto de datos personalizado | Enlace |
| Manipulación Móvil | Planificación robótica de navegación y manipulación, VQA. | 2912 secuencias | Basado en el conjunto de datos SayCan |
| WebLI | Recuperación de texto de imagen | 66 millones de pares de imagen-título | Enlace |
| VQAv2 | Respuesta visual a preguntas | 1,1 millones de preguntas sobre imágenes de COCO | Enlace |
| OK-VQA | Respuesta visual a preguntas que requieren conocimientos externos. | 14.031 preguntas sobre imágenes COCO | Enlace |
| PALMA DE COCO | Subtítulos de imagen | Imágenes de 330K con subtítulos | Enlace |
| Wikipedia | Corpus de texto | N / A | Enlace |
Los conjuntos de datos clave de robótica se recopilaron específicamente para este trabajo, mientras que los conjuntos de datos de lenguaje de visión más grandes (WebLI, VQAv2, OK-VQA, COCO) son puntos de referencia estándar en ese campo. Los conjuntos de datos van desde decenas de miles de ejemplos para los dominios de la robótica hasta decenas de millones para los datos de visión y lenguaje a escala de Internet.
¡Se necesita tu brillantez! Únase a nosotros y juntos hagamos que PALM-E sea aún más impresionante:
? Correcciones, ? mejoras, documentos o ideas: ¡todos son bienvenidos! Demos forma al futuro de la IA, de la mano.
@article{driess2023palme,
title={PALM-E: An Embodied Multimodal Language Model},
author={Driess, Danny and Xia, Fei and Sajjadi, Mehdi S. M. and Lynch, Corey and Chowdhery, Aakanksha and Ichter, Brian and Wahid, Ayzaan and Tompson, Jonathan and Vuong, Quan and Yu, Tianhe and Huang, Wenlong and Chebotar, Yevgen and Sermanet, Pierre and Duckworth, Daniel and Levine, Sergey and Vanhoucke, Vincent and Hausman, Karol and Toussaint, Marc and Greff, Klaus and Zeng, Andy and Mordatch, Igor and Florence, Pete},
journal={arXiv preprint arXiv:2303.03378},
year={2023},
url={https://doi.org/10.48550/arXiv.2303.03378}
}

