RobustSAM
1.0.0
Repositorio oficial de RobustSAM: segmente cualquier cosa de forma sólida en imágenes degradadas
Página del proyecto | Papel | Vídeo | Conjunto de datos
Agosto de 2024: puede consultar las tarjetas modelo Hugging Face y la demostración creada por @jadechoghari para facilitar su uso a través de este enlace.
Julio de 2024: ¡Se publican el código de capacitación, los datos y los puntos de control del modelo para diferentes redes troncales de ViT!
Junio de 2024: ¡Se ha publicado el código de inferencia!
Febrero de 2024: ¡RobustSAM fue aceptado en CVPR 2024!
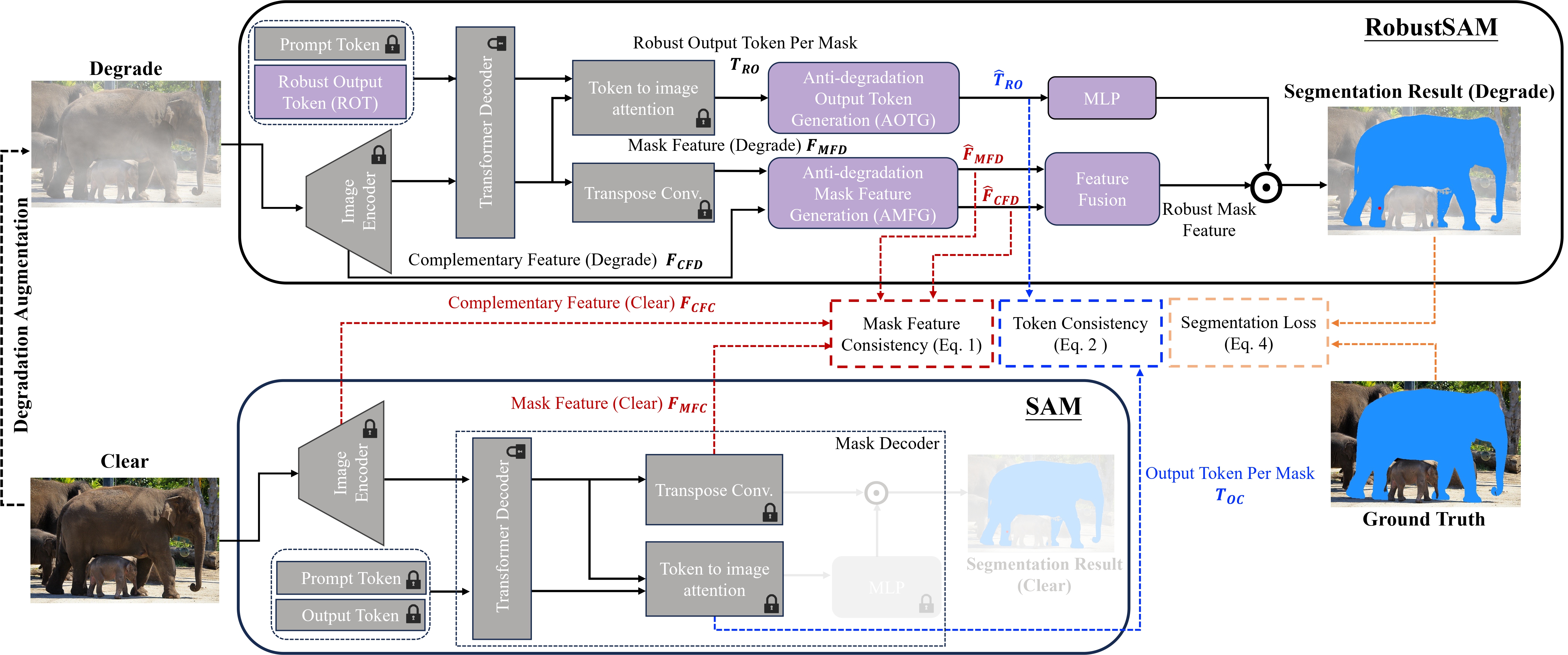
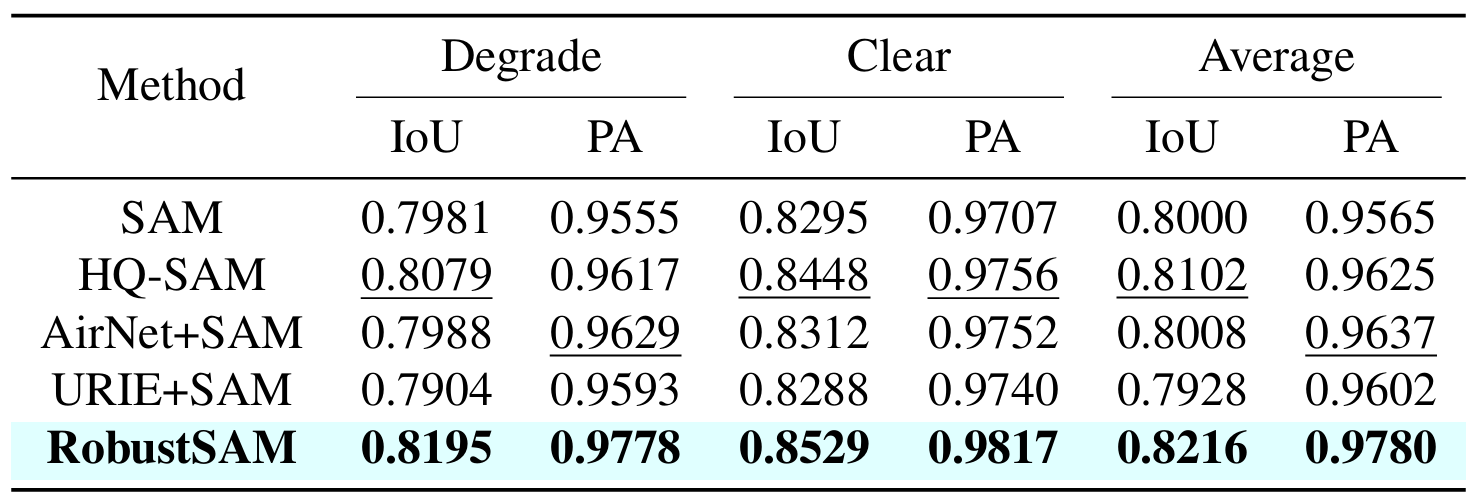
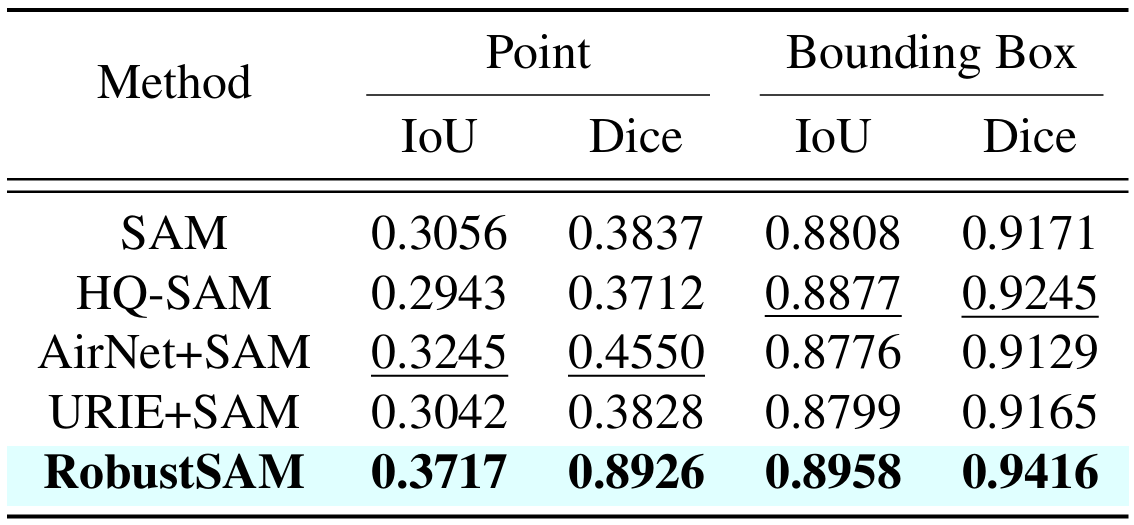
Segment Anything Model (SAM) ha surgido como un enfoque transformador en la segmentación de imágenes, aclamado por sus sólidas capacidades de segmentación de disparo cero y su sistema de indicaciones flexible. No obstante, su rendimiento se ve desafiado por imágenes con calidad degradada. Para abordar esta limitación, proponemos el modelo Robust Segment Anything (RobustSAM), que mejora el rendimiento de SAM en imágenes de baja calidad al tiempo que preserva su rapidez y generalización de disparo cero.
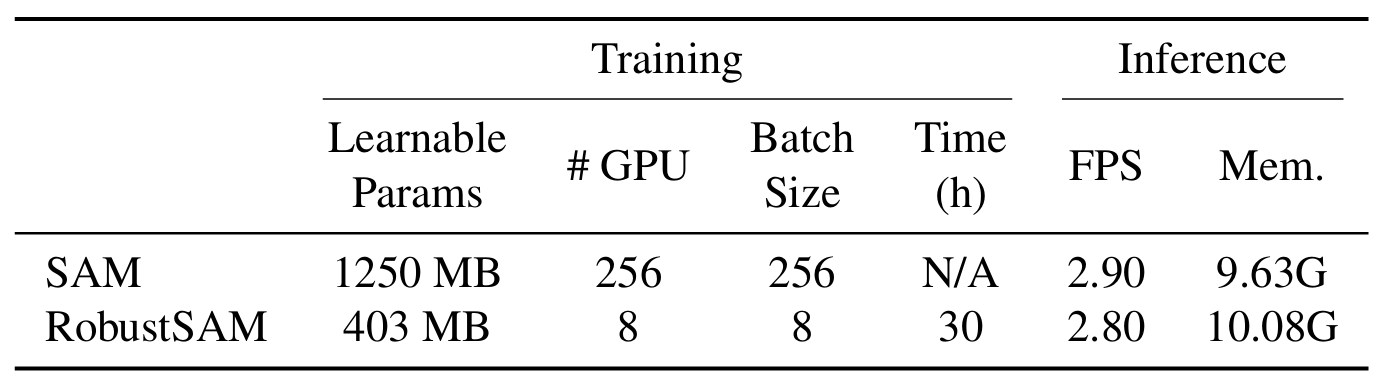
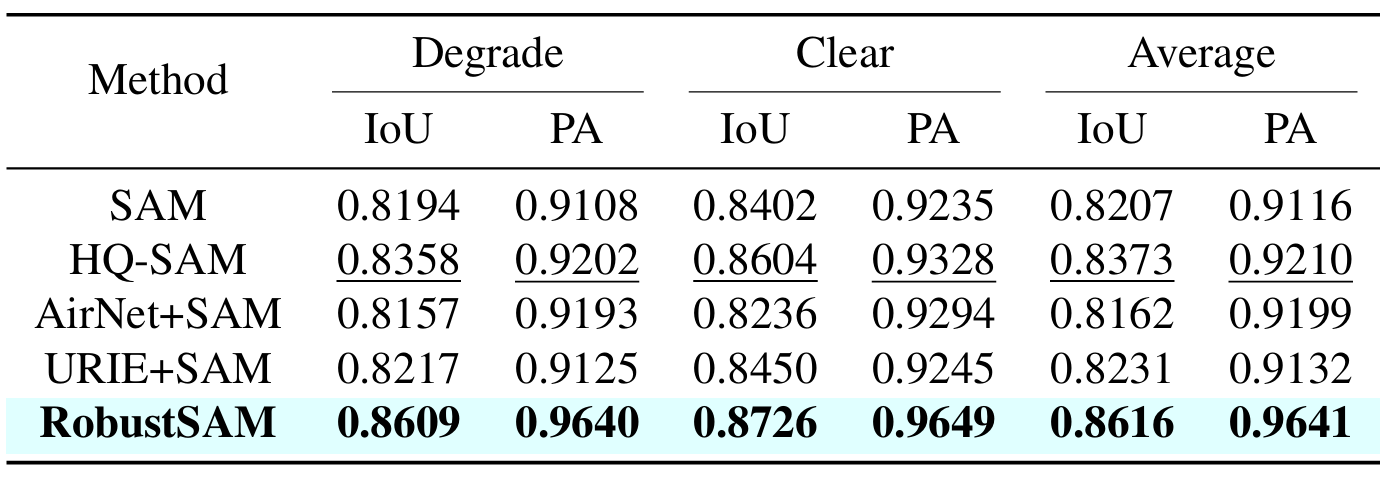
Nuestro método aprovecha el modelo SAM previamente entrenado con incrementos de parámetros y requisitos computacionales solo marginales. Los parámetros adicionales de RobustSAM se pueden optimizar en 30 horas en ocho GPU, lo que demuestra su viabilidad y practicidad para los laboratorios de investigación típicos. También presentamos el conjunto de datos Robust-Seg, una colección de pares de máscaras de imagen de 688K con diferentes degradaciones diseñadas para entrenar y evaluar nuestro modelo de manera óptima. Amplios experimentos en diversas tareas de segmentación y conjuntos de datos confirman el rendimiento superior de RobustSAM, especialmente en condiciones de disparo cero, lo que subraya su potencial para una amplia aplicación en el mundo real. Además, se ha demostrado que nuestro método mejora eficazmente el rendimiento de las tareas posteriores basadas en SAM, como la eliminación de neblina y el desenfoque de una sola imagen.
Crea un entorno conda y actívalo.
conda create --name robustsam python=3.10 -y conda activate robustsam
Clona e ingresa al directorio del repositorio.
git clone https://github.com/robustsam/RobustSAM cd RobustSAM
Utilice el siguiente comando para verificar su versión de CUDA.
nvidia-smi
Reemplace la versión CUDA con la suya en el comando a continuación.
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu[$YOUR_CUDA_VERSION] # For example: pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117 # cu117 = CUDA_version_11.7
Instalar las dependencias restantes
pip install -r requirements.txt
Descargue puntos de control RobustSAM previamente entrenados de diferentes tamaños y colóquelos en el directorio actual.
Punto de control ViT-B RobustSAM
Punto de control ViT-L RobustSAM
Punto de control ViT-H RobustSAM
Cambie el directorio actual al directorio de "datos".
cd data
Descargue el conjunto de datos train, val, test y COCO y LVIS adicionales. (NOTA: Las imágenes en el conjunto de datos train, val y test consisten en imágenes de LVIS, MSRA10K, ThinObject-5k, NDD20, STREETS y FSS-1000)
bash download.sh
Solo se descargaron imágenes claras en el paso anterior. Utilice el siguiente comando para generar las imágenes degradadas correspondientes.
bash gen_data.sh
Si quieres entrenar desde cero, usa el comando a continuación.
python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name [$YOUR_EXP_NAME] --model_size [$MODEL_SIZE] # Example usage: python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name test --model_size l
Si desea entrenar desde un punto de control previamente entrenado, use el comando a continuación.
python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name [$YOUR_EXP_NAME] --model_size [$MODEL_SIZE] --load_model [$CHECKPOINT_PATH] # Example usage: python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name test --model_size l --load_model robustsam_checkpoint_l.pth
python gradio_app.py
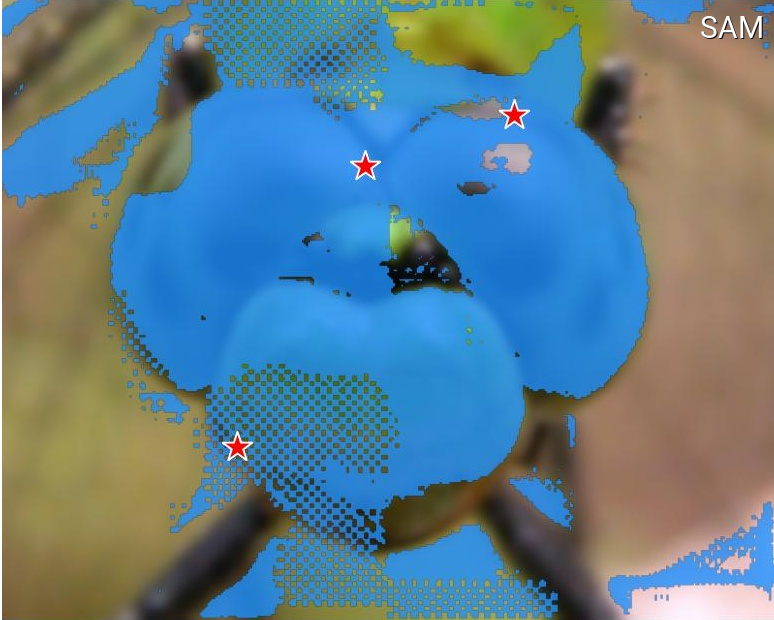
Hemos preparado algunas imágenes en la carpeta demo_images para fines de demostración. Además, hay dos modos de indicaciones disponibles (indicaciones de cuadro y indicaciones de puntos).
Para mensaje de cuadro:
python eval.py --bbox --model_size l
Para solicitar puntos:
python eval.py --model_size l
De forma predeterminada, los resultados de la demostración se guardarán en demo_result/[$PROMPT_TYPE] .
 |  |
 |  |

Si encuentra útil este trabajo, ¡considere citarnos!
@inproceedings{chen2024robustsam, title={RobustSAM: segmente cualquier cosa de forma sólida en imágenes degradadas}, autor={Chen, Wei-Ting y Vong, Yu-Jiet y Kuo, Sy-Yen y Ma, Sizhou y Wang, Jian}, diario= {CVPR}, año={2024}}Agradecemos a los autores de SAM en el que se basa nuestro repositorio.


