algebraic nnhw
1.0.0
Este repositorio contiene el código fuente para arquitecturas de hardware de aprendizaje automático que requieren casi la mitad de la cantidad de unidades multiplicadoras para lograr el mismo rendimiento, mediante la ejecución de algoritmos internos alternativos que intercambian casi la mitad de las multiplicaciones por adiciones económicas de bajo ancho de bits, sin dejar de producir resultados idénticos. como el producto interior convencional. Esto aumenta el rendimiento teórico y los límites de eficiencia informática de los aceleradores de ML. Consulte la siguiente publicación de revista para obtener todos los detalles:
TE Pogue y N. Nicolici, "Arquitecturas y algoritmos rápidos de producto interno para aceleradores de redes neuronales profundas", en IEEE Transactions on Computers, vol. 73, núm. 2, págs. 495-509, febrero de 2024, doi: 10.1109/TC.2023.3334140.
URL del artículo: https://ieeexplore.ieee.org/document/10323219
Versión de acceso abierto: https://arxiv.org/abs/2311.12224
Resumen: Introducimos un nuevo algoritmo llamado Free-pipeline Fast Inner Product (FFIP) y su arquitectura de hardware que mejora un algoritmo rápido de producto interno (FIP) poco explorado y propuesto por Winograd en 1968. A diferencia de los algoritmos de filtrado mínimo no relacionados de Winograd para capas convolucionales, FIP es aplicable a todas las capas del modelo de aprendizaje automático (ML) que se pueden descomponer principalmente en la multiplicación de matrices, incluidas las capas completamente conectadas, convolucionales, recurrentes y de atención/transformador. Implementamos FIP por primera vez en un acelerador de ML y luego presentamos nuestro algoritmo FFIP y nuestra arquitectura generalizada que mejoran inherentemente la frecuencia de reloj de FIP y, como consecuencia, el rendimiento por un costo de hardware similar. Finalmente, contribuimos con optimizaciones específicas de ML para los algoritmos y arquitecturas FIP y FFIP. Mostramos que FFIP se puede incorporar sin problemas a los aceleradores de ML de matriz sistólica de punto fijo tradicionales para lograr el mismo rendimiento con la mitad del número de unidades de acumulación múltiple (MAC), o puede duplicar el tamaño máximo de matriz sistólica que puede caber en dispositivos con un presupuesto fijo de hardware. Nuestra implementación de FFIP para modelos de aprendizaje automático no dispersos con entradas de punto fijo de 8 a 16 bits logra un mayor rendimiento y eficiencia informática que las mejores soluciones anteriores de su clase en el mismo tipo de plataforma informática.
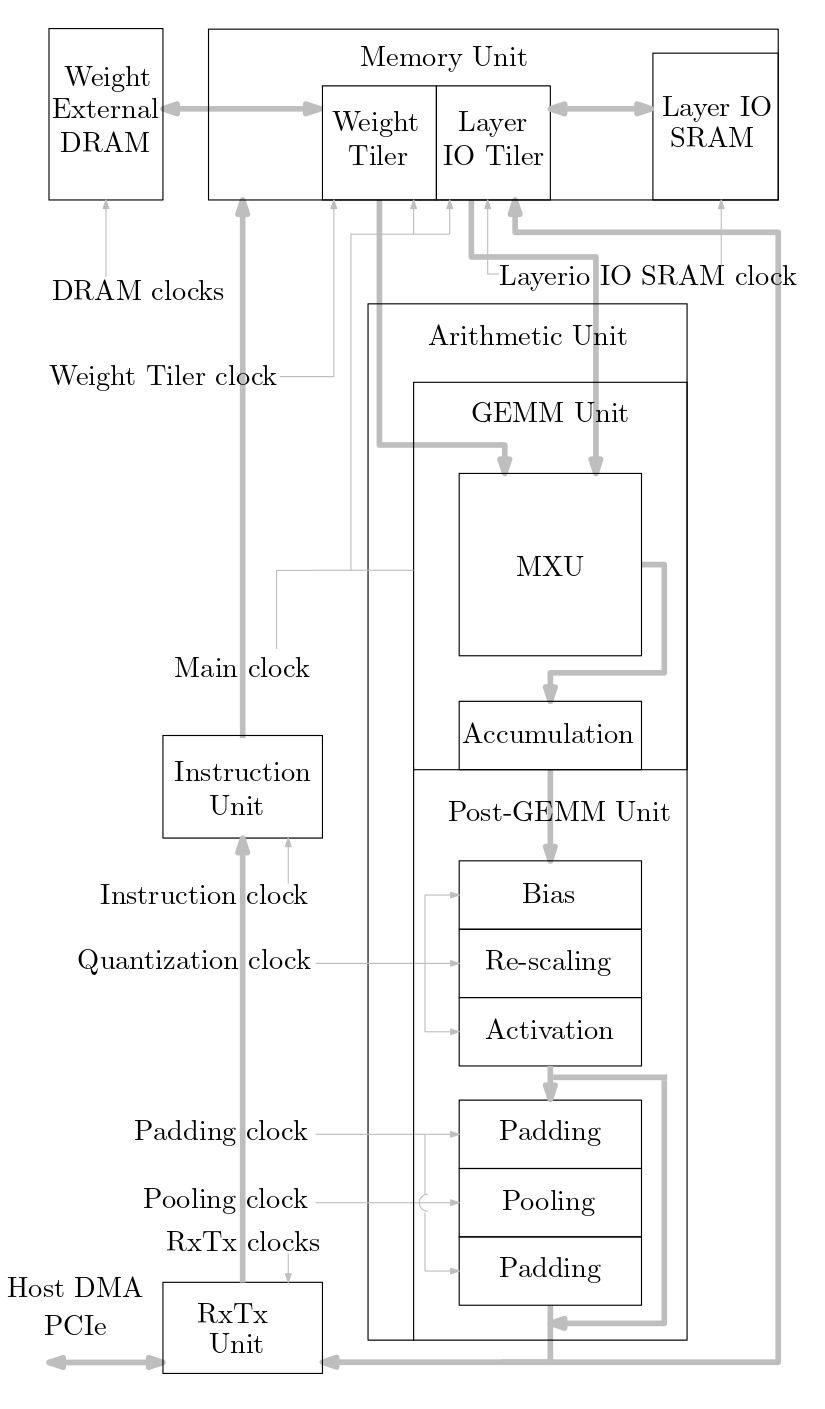
El siguiente diagrama muestra una descripción general del sistema acelerador de ML implementado en este código fuente:
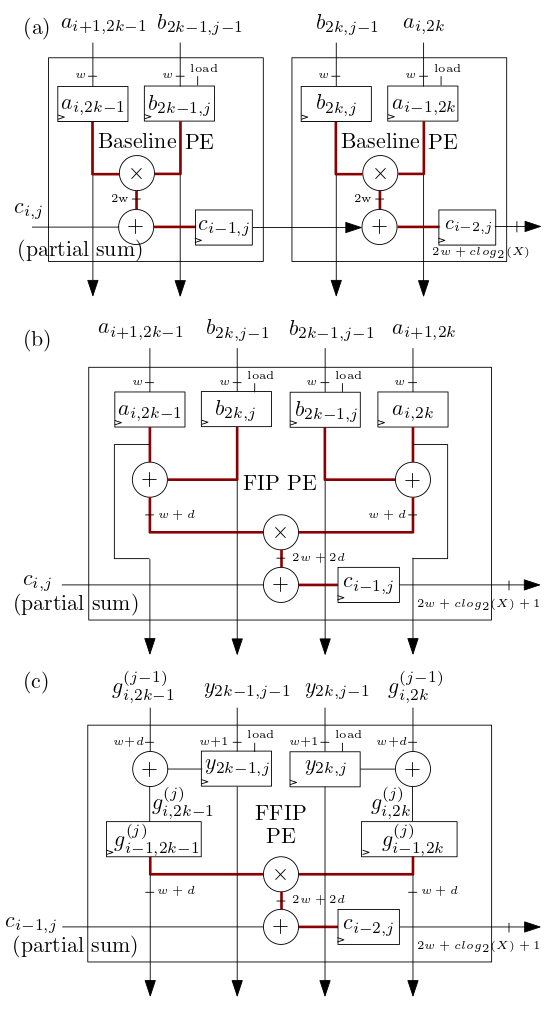
Los elementos de procesamiento (PE) de matriz sistólica/MXU FIP y FFIP que se muestran a continuación en (b) y (c) implementan los algoritmos de producto interno FIP y FFIP y cada uno proporciona individualmente la misma potencia computacional efectiva que los dos PE de referencia que se muestran en ( a) combinados que implementan el producto interno de referencia como en los aceleradores ML de matriz sistólica anteriores:
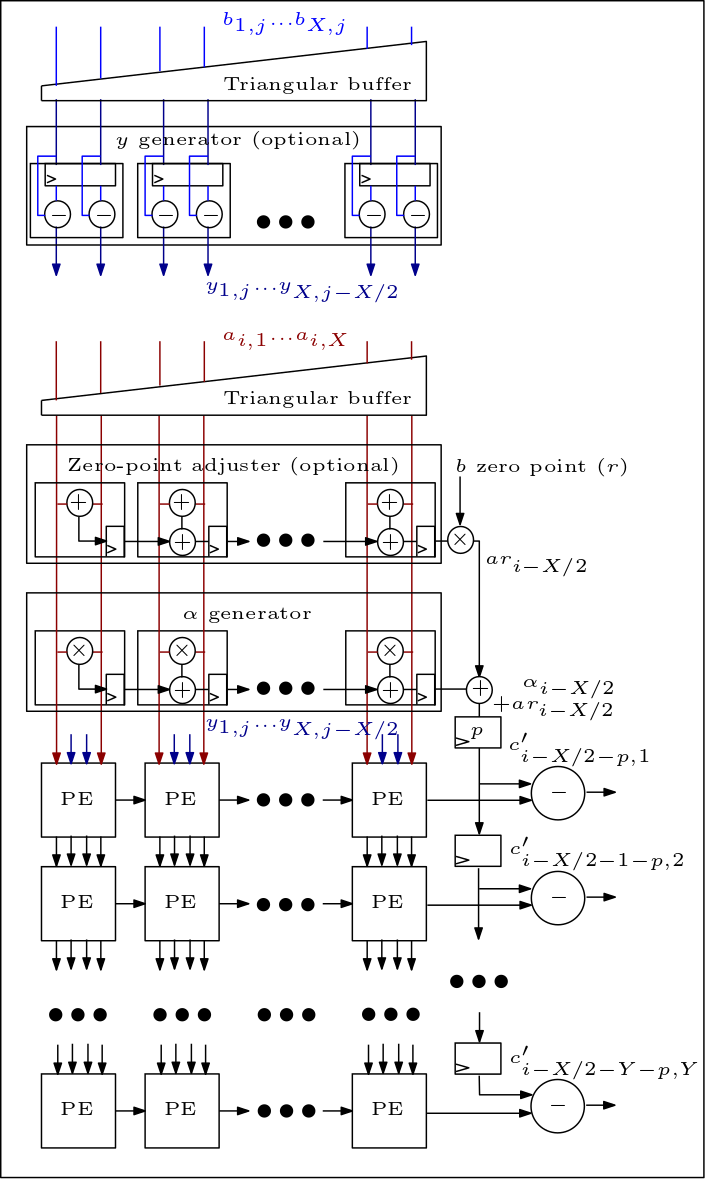
El siguiente es un diagrama de la matriz MXU/sistólica y muestra cómo se conectan los PE:
La organización del código fuente es la siguiente:
Los archivos rtl/top/define.svh y rtl/top/pkg.sv contienen una serie de parámetros configurables como FIP_METHOD en define.svh que define el tipo de matriz sistólica (línea de base, FIP o FFIP), SZI y SZJ que definen la altura/ancho de la matriz sistólica, y LAYERIO_WIDTH/WEIGHT_WIDTH que definen los anchos de bits de entrada.
El directorio rtl/arith incluye mxu.sv y mac_array.sv que contienen el RTL para las arquitecturas de matriz sistólica de línea base, FIP y FFIP (según el valor del parámetro FIP_METHOD).


