lumiere pytorch
0.0.24
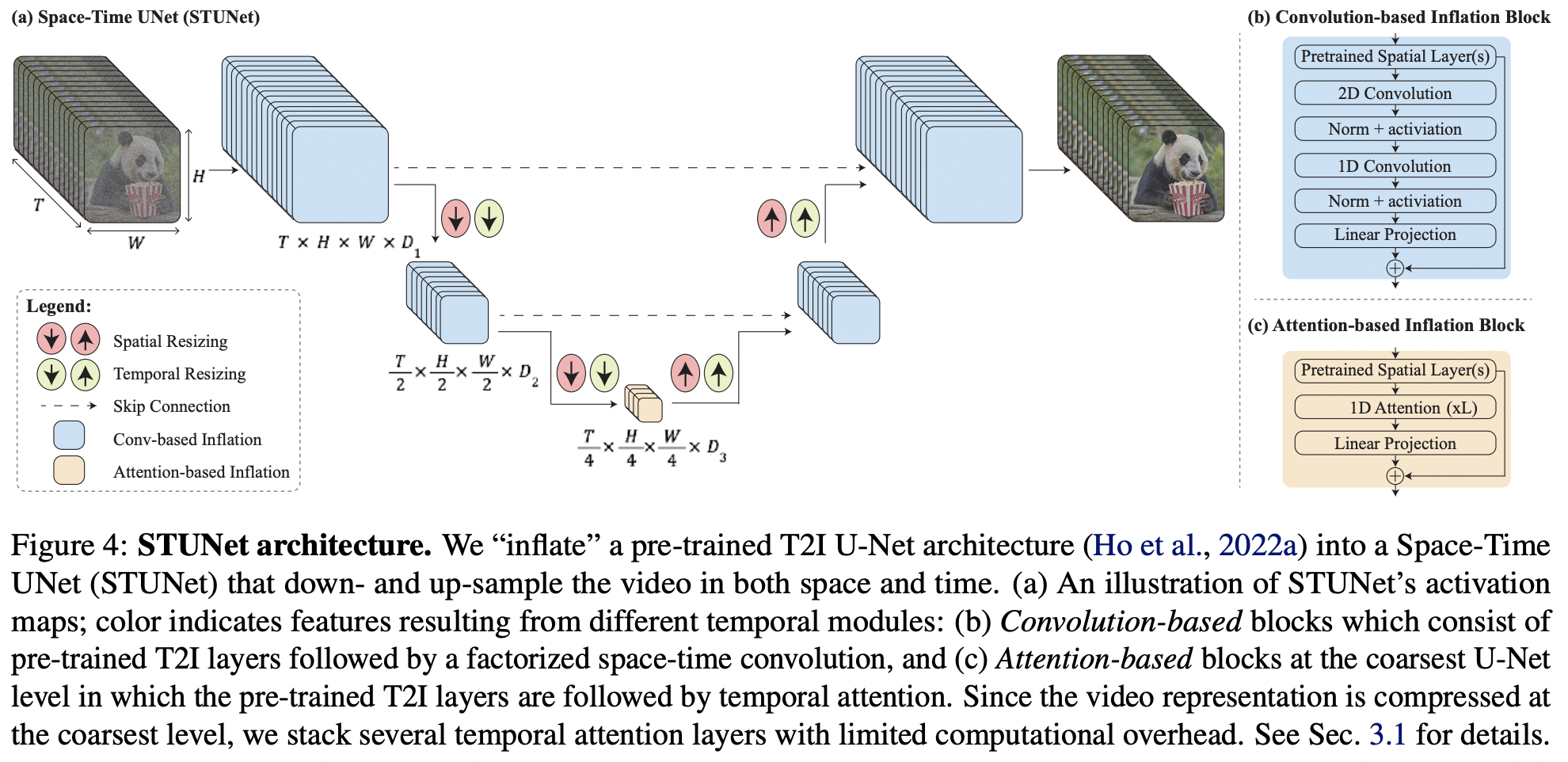
Implementación de Lumiere, generación de texto a video SOTA de Google Deepmind, en Pytorch
Reseña del artículo de Yannic
Dado que este artículo contiene principalmente algunas ideas clave además del modelo de texto a imagen, iremos un paso más allá y extenderemos la nueva Karras U-net a video dentro de este repositorio.
$ pip install lumiere-pytorch import torch
from lumiere_pytorch import MPLumiere
from denoising_diffusion_pytorch import KarrasUnet
karras_unet = KarrasUnet (
image_size = 256 ,
dim = 8 ,
channels = 3 ,
dim_max = 768 ,
)
lumiere = MPLumiere (
karras_unet ,
image_size = 256 ,
unet_time_kwarg = 'time' ,
conv_module_names = [
'downs.1' ,
'ups.1' ,
'downs.2' ,
'ups.2' ,
],
attn_module_names = [
'mids.0'
],
upsample_module_names = [
'ups.2' ,
'ups.1' ,
],
downsample_module_names = [
'downs.1' ,
'downs.2'
]
)
noised_video = torch . randn ( 2 , 3 , 8 , 256 , 256 )
time = torch . ones ( 2 ,)
denoised_video = lumiere ( noised_video , time = time )
assert noised_video . shape == denoised_video . shape agregar todas las capas temporales
exponer sólo parámetros temporales para el aprendizaje, congelar todo lo demás
descubra la mejor manera de lidiar con el acondicionamiento del tiempo después de la reducción de resolución temporal; en lugar de la transformación de pytree al principio, probablemente será necesario conectarse a todos los módulos e inspeccionar los tamaños de los lotes.
manejar módulos intermedios que pueden tener forma de salida como (batch, seq, dim)
siguiendo las conclusiones de Tero Karras, improvisar una variante de los 4 módulos con preservación de magnitud
prueba en imagen-pytorch
Mire la difusión múltiple y vea si se puede convertir en un envoltorio simple.
@inproceedings { BarTal2024LumiereAS ,
title = { Lumiere: A Space-Time Diffusion Model for Video Generation } ,
author = { Omer Bar-Tal and Hila Chefer and Omer Tov and Charles Herrmann and Roni Paiss and Shiran Zada and Ariel Ephrat and Junhwa Hur and Yuanzhen Li and Tomer Michaeli and Oliver Wang and Deqing Sun and Tali Dekel and Inbar Mosseri } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:267095113 }
} @article { Karras2023AnalyzingAI ,
title = { Analyzing and Improving the Training Dynamics of Diffusion Models } ,
author = { Tero Karras and Miika Aittala and Jaakko Lehtinen and Janne Hellsten and Timo Aila and Samuli Laine } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2312.02696 } ,
url = { https://api.semanticscholar.org/CorpusID:265659032 }
}

