MambaTransformer
1.0.0

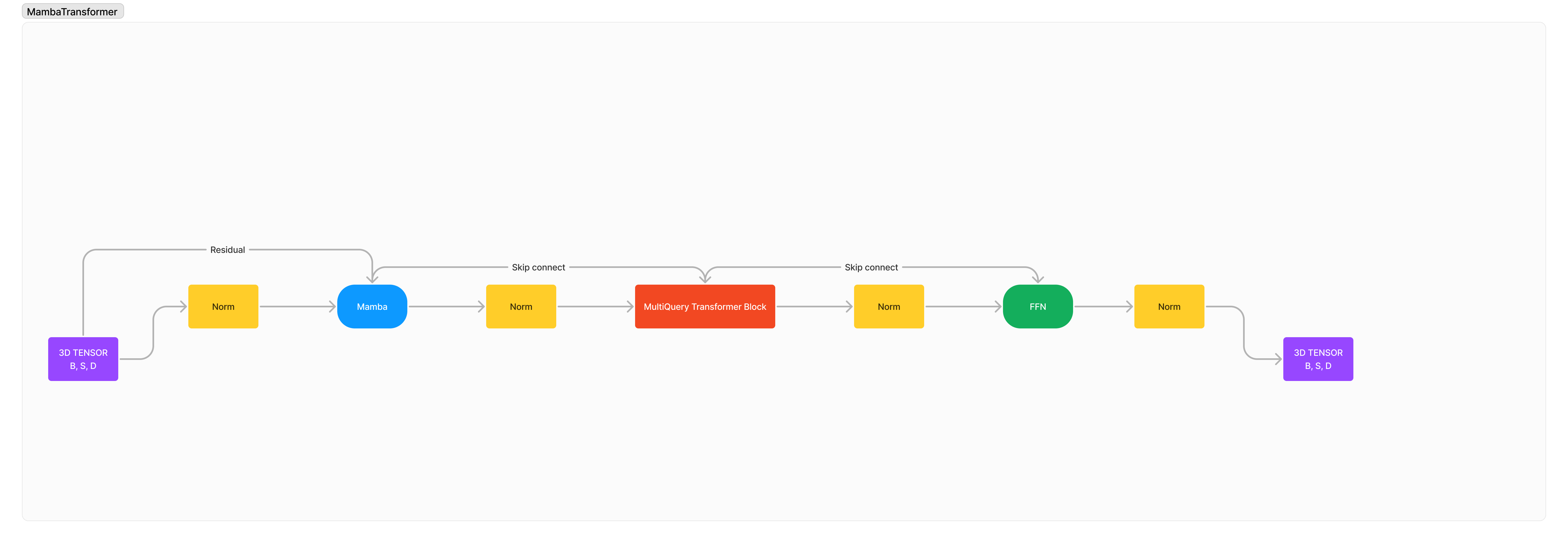
Integración de Mamba/SSM con Transformer para un contexto largo mejorado y modelado de secuencias de alta calidad.
Esta es una arquitectura 100% novedosa que he diseñado para combinar las fortalezas y debilidades de los SSM y la Atención para una arquitectura avanzada completamente nueva con el propósito de superar nuestros viejos límites. Velocidad de procesamiento más rápida, contextos más largos, menor perplejidad ante secuencias largas, razonamiento mejorado y superior sin dejar de ser pequeño y compacto.
La arquitectura es esencialmente: x -> norm -> mamba -> norm -> transformer -> norm -> ffn -> norm -> out .
Agregué muchas normalizaciones porque creo que, de forma predeterminada, la estabilidad del entrenamiento se degradaría gravemente debido a la integración de dos arquitecturas extrañas entre sí.
pip3 install mambatransformer
import torch
from mamba_transformer import MambaTransformer
# Generate a random tensor of shape (1, 10) with values between 0 and 99
x = torch . randint ( 0 , 100 , ( 1 , 10 ))
# Create an instance of the MambaTransformer model
model = MambaTransformer (
num_tokens = 100 , # Number of tokens in the input sequence
dim = 512 , # Dimension of the model
heads = 8 , # Number of attention heads
depth = 4 , # Number of transformer layers
dim_head = 64 , # Dimension of each attention head
d_state = 512 , # Dimension of the state
dropout = 0.1 , # Dropout rate
ff_mult = 4 , # Multiplier for the feed-forward layer dimension
return_embeddings = False , # Whether to return the embeddings,
transformer_depth = 2 , # Number of transformer blocks
mamba_depth = 10 , # Number of Mamba blocks,
use_linear_attn = True , # Whether to use linear attention
)
# Pass the input tensor through the model and print the output shape
out = model ( x )
print ( out . shape )
# After many training
model . eval ()
# Would you like to train this model? Zeta Corporation offers unmatchable GPU clusters at unbeatable prices, let's partner!
# Tokenizer
model . generate ( text )
MIT


