toyCarIRL
1.0.0
El aprendizaje por refuerzo (RL) es la forma más básica e intuitiva de aprendizaje por prueba y error, es la forma en que aprenden la mayoría de los organismos vivos con algún tipo de capacidad de pensamiento. A menudo denominado aprendizaje por exploración, es la forma en que un bebé humano recién nacido aprende a dar sus primeros pasos, es decir, tomando acciones aleatorias inicialmente y luego descubriendo lentamente las acciones que conducen al movimiento de caminar hacia adelante.
Tenga en cuenta que esta publicación supone una buena comprensión del marco de aprendizaje por refuerzo; familiarícese con RL durante las semanas 5 y 6 de este increíble curso en línea AI_Berkeley.
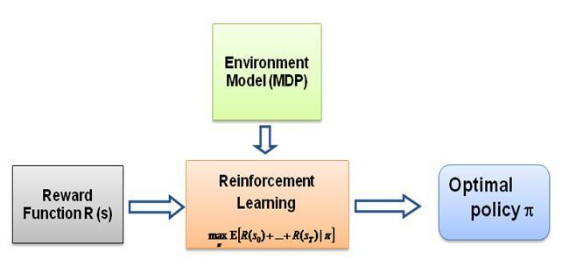
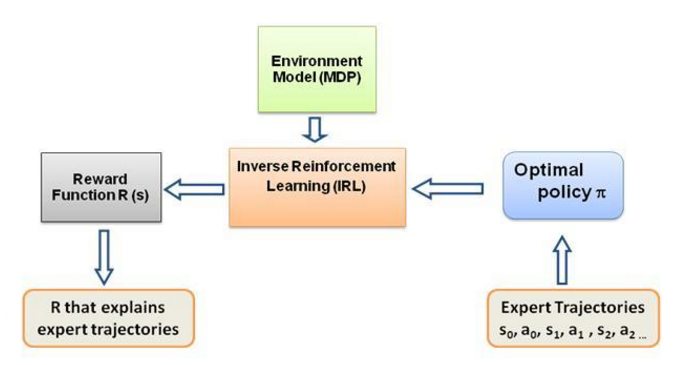
Ahora bien, la pregunta que me sigo haciendo es cuál es la fuerza impulsora de este tipo de aprendizaje, qué obliga al agente a aprender un comportamiento particular en la forma en que lo hace. Al aprender más sobre RL, me encontré con la idea de recompensas : básicamente, el agente intenta elegir sus acciones de tal manera que se maximicen las recompensas que obtiene de ese comportamiento en particular. Ahora bien, para hacer que el agente realice diferentes comportamientos, es la estructura de recompensa la que se debe modificar/explotar. Pero supongamos que sólo tenemos el conocimiento del comportamiento del experto con nosotros, entonces ¿cómo estimamos la estructura de recompensa dado un comportamiento particular en el entorno? Bueno, este es el problema mismo del aprendizaje por refuerzo inverso (IRL) , donde, dada la política experta óptima (en realidad se supone que es óptima), deseamos determinar la estructura de recompensa subyacente.
Nuevamente, esta no es una publicación de Introducción al aprendizaje por refuerzo inverso, más bien es un tutorial sobre cómo usar/codificar el marco de aprendizaje por refuerzo inverso para su propio problema, pero IRL se encuentra en el centro del mismo, y es esencial conocerlo. primero. IRL ha sido ampliamente estudiado en el pasado y se han desarrollado algoritmos para ello; consulte los artículos Ng y Russell, 2000, y Abbeel y Ng, 2004 para obtener más información.
Esta publicación adapta el algoritmo de Abbeel y Ng, 2004 para resolver el problema IRL.
La idea aquí es programar un agente simple en un mundo 2D lleno de obstáculos para copiar/clonar diferentes comportamientos en el entorno, los comportamientos se ingresan con la ayuda de trayectorias expertas dadas manualmente por un humano/experto en computadora. Esta forma de aprendizaje a partir de demostraciones de expertos se llama aprendizaje por aprendizaje en la literatura científica; en su núcleo se encuentra el aprendizaje por refuerzo inverso, y simplemente estamos tratando de descubrir las diferentes funciones de recompensa para estos diferentes comportamientos.
En general, sí, son lo mismo, lo que significa aprender de la demostración (LfD). Ambos métodos aprenden de la demostración, pero aprenden cosas diferentes:
El aprendizaje mediante aprendizaje mediante el aprendizaje por refuerzo inverso intentará inferir el objetivo del profesor . En otras palabras, aprenderá una función de recompensa a partir de la observación, que luego podrá utilizarse en el aprendizaje por refuerzo. Si descubre que el objetivo es clavar un clavo con un martillo, ignorará los parpadeos y rasguños del profesor, ya que son irrelevantes para el objetivo.
El aprendizaje por imitación (también conocido como clonación conductual) intentará copiar directamente al profesor . Esto se puede lograr únicamente mediante el aprendizaje supervisado. La IA intentará copiar cada acción, incluso acciones irrelevantes como parpadear o rascarse, por ejemplo, o incluso errores. También puedes usar RL aquí, pero solo si tienes una función de recompensa.
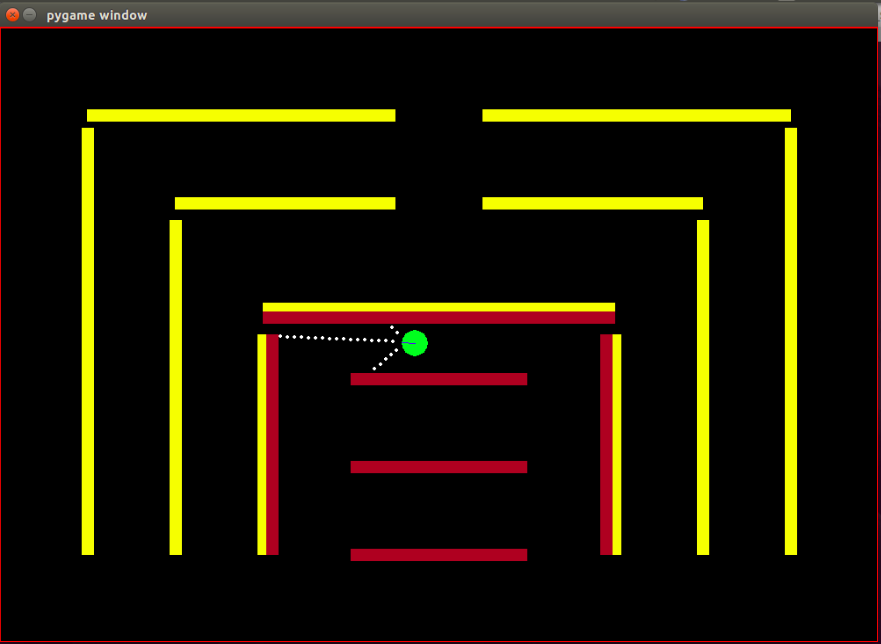
Agente: el agente es un pequeño círculo verde con su dirección de rumbo indicada por una línea azul.
Sensores: el agente está equipado con 3 sensores de distancia y color, y esta es la única información que tiene el agente sobre el medio ambiente.
Espacio de estados: el estado del agente consta de 8 características observables:
Tenga en cuenta que la normalización se realiza para garantizar que cada valor de característica observable esté en el rango [0,1], que es una condición necesaria en las recompensas para que el algoritmo IRL converja.
Recompensas: la recompensa después de cada cuadro se calcula como una combinación lineal ponderada de los valores de las características observadas en ese cuadro respectivo. Aquí, la recompensa r_t en el t-ésimo cuadro se calcula mediante el producto escalar del vector de peso w con el vector de valores de características en el t-ésimo cuadro, es decir, el vector de estado phi_t. Tal que r_t = w^T x phi_t.
Acciones disponibles: con cada nuevo cuadro, el agente automáticamente da un paso hacia adelante , las acciones disponibles pueden girar al agente hacia la izquierda , hacia la derecha o no hacer nada que sea un simple paso hacia adelante. Tenga en cuenta que las acciones de giro también incluyen el movimiento hacia adelante. no es una rotación en el lugar.
Obstáculos: el entorno está formado por paredes rígidas, deliberadamente coloreadas en diferentes colores. El agente tiene capacidades de detección de colores que le ayudan a distinguir entre los tipos de obstáculos. El entorno está diseñado de esta manera para facilitar las pruebas del algoritmo IRL.
La posición inicial (estado) del bot es fija, ya que según el algoritmo IRL es necesario que el estado inicial sea el mismo para todas las iteraciones.
Tenga en cuenta que Matt Harvey adoptó completamente el algoritmo RL de esta publicación con cambios menores, por lo que tiene mucho sentido hablar sobre los cambios que he realizado, además, incluso si el lector se siente cómodo con RL, recomiendo encarecidamente echarle un vistazo. esa publicación para comprender cómo se está llevando a cabo el aprendizaje por refuerzo.
El entorno cambia significativamente, y el agente adquiere la capacidad no solo de detectar la distancia de los 3 sensores sino también de detectar el color de los obstáculos, lo que le permite distinguir entre los obstáculos. Además, el agente ahora es más pequeño y sus puntos sensores ahora están más cerca para obtener más resolución y mejor rendimiento. Los obstáculos tuvieron que volverse estáticos por ahora, para simplificar el proceso de prueba del algoritmo IRL, esto muy bien puede conducir a un sobreajuste de los datos, pero eso no me preocupa en este momento. Como se analizó anteriormente, el conjunto de observación o el estado del agente se incrementó de 3 a 8, con la inclusión de la función de colisión en el estado del agente. La estructura de recompensa ha cambiado completamente, la recompensa ahora es una combinación lineal ponderada de estas 8 características, el agente ya no recibe una recompensa de -500 al chocar contra obstáculos, sino que el valor de la característica por chocar es +1 y no chocar es 0 y Corresponde al algoritmo decidir qué peso se debe asignar a esta característica en función del comportamiento del experto.
Como se indica en el blog de Matt, el objetivo aquí no es solo enseñar al agente de RL a evitar obstáculos, es decir, por qué asumir algo sobre la estructura de recompensa, dejar que el algoritmo de las demostraciones de expertos decida completamente la estructura de recompensa y ver qué comportamiento ¡Se logra una configuración particular de recompensas!
Las características o funciones básicas phi_i que son básicamente observables en el estado. Las características del problema actual se analizan anteriormente en la sección de espacio de estados. Definimos phi(s_t) como la suma de todas las expectativas de características phi_i tal que:
Recompensas r_t: combinación lineal de estos valores de características observados en cada estado s_t.
Expectativas de características mu(pi) de una política pi es la suma de los valores de características descontados phi(s_t).
Las expectativas de características de una política son independientes de las ponderaciones, solo dependen de los estados visitados durante la ejecución (según la política) y del factor de descuento gamma, un número entre 0 y 1 (por ejemplo, 0,9 en nuestro caso). Para obtener las expectativas de características de una póliza tenemos que ejecutar la política en tiempo real con el agente y registrar los estados visitados y los valores de características obtenidos.
Las expectativas de las características de la política del experto o las expectativas de las características del experto mu(pi_E) se obtienen mediante las acciones que se toman de acuerdo con el comportamiento del experto. Básicamente, ejecutamos esta política y obtenemos las expectativas de funciones como lo hacemos con cualquier otra política. Las expectativas de las características del experto se le dan al algoritmo IRL para encontrar los pesos de modo que la función de recompensa correspondiente a los pesos se asemeje a la función de recompensa subyacente que el experto está tratando de maximizar (en el lenguaje RL habitual).
Expectativas de características de política aleatoria : ejecute una política aleatoria y utilice las expectativas de características obtenidas para inicializar IRL.
Mantener una lista de las expectativas de las características de la política que obtenemos después de cada iteración.
Al principio solo tenemos pi^1 -> las expectativas de la característica de política aleatoria.
Encuentre el primer conjunto de pesos de w^1 mediante optimización convexa; el problema es similar a un clasificador SVM que intenta dar una etiqueta +1 a la característica experta esperada. y -1 etiqueta para todas las demás características de la póliza esperadas.-
tal que,
Condición de terminación:
Ahora, una vez que obtenemos los pesos después de una iteración de optimización, es decir, una vez que obtenemos una nueva función de recompensa, tenemos que aprender la política a la que da lugar esta función de recompensa. Esto es lo mismo que decir encontrar una política que intente maximizar esta función de recompensa obtenida. Para encontrar esta nueva política, tenemos que entrenar el algoritmo de aprendizaje por refuerzo con esta nueva función de recompensa y entrenarlo hasta que los valores Q converjan, para obtener una estimación adecuada de la política.
Después de haber aprendido una nueva política, tenemos que probarla en línea para obtener las expectativas de funciones correspondientes a esta nueva política. Luego agregamos estas nuevas expectativas de características a nuestra lista de expectativas de características y continuamos con la siguiente iteración del algoritmo IRL hasta la convergencia.
Intentemos ahora dominar el código. Encuentre el código completo en este repositorio de git. Hay principalmente 3 archivos de los que debes preocuparte:
manualControl.py : para obtener las expectativas de funciones del experto moviendo manualmente al agente. Ejecute "python3 manualControl.py", espere a que se cargue la interfaz gráfica de usuario y luego use las teclas de flecha para comenzar a moverse. Déle el comportamiento que desea que copie (tenga en cuenta que el comportamiento que espera que copie debe ser razonable con el espacio de estado dado). Un buen truco sería asumir el lugar del agente y pensar si podrá distinguir el comportamiento dado únicamente en el espacio de estado actual. Consulte el archivo fuente para obtener más detalles.
toy_car_IRL.py : el archivo principal, aquí es donde reside el código IRL. Echemos un vistazo al código paso a paso.
{% esencia 51542f27e97eac1559a00f06b757df1a %}
Importe dependencias y defina los parámetros importantes, cambie el COMPORTAMIENTO según sea necesario. MARCOS son el número de fotogramas que desea que ejecute el algoritmo RL. 100K está bien y toma alrededor de 2 horas.
{% esencia 49b602b9a3090773d492310175bb2e3f %}
Cree la clase irlAgent fácil de usar, que incorpora los comportamientos aleatorios y expertos, y los demás parámetros importantes como se muestra.
{% esencia bc17c06a07ea3b915827e89f3c13a2ae %}
La función getRLAgentFE utiliza IRL_helper del alumno de refuerzo para entrenar un nuevo modelo y obtener expectativas de características reproduciendo ese modelo durante 2000 iteraciones. Básicamente, devuelve las expectativas de características para cada conjunto de pesos (W) que obtiene.
{% esencia ce0ef99adc652c7469f1bc4303a3af41 %}
Actualizar el diccionario en el que guardamos nuestras políticas obtenidas y sus respectivos valores t. Donde t = (weights.tanspose)x(experto-nuevaPolítica).
{% esencia be55a5d44e5b1ff13dfa68cc96f6b1b1 %}
La implementación del algoritmo IRL principal, que se analiza anteriormente. {% esencia 9faee18596467ee33ac5d91fd0cb675f %}
La optimización convexa para actualizar las ponderaciones al recibir una nueva política, básicamente asigna una etiqueta +1 a la política experta y una etiqueta -1 a todas las demás políticas y optimiza las ponderaciones bajo las restricciones mencionadas. Para saber más sobre esta optimización visite el sitio
{% esencia 30cf6c59b9915054f3cf6d278f8f8a11 %}
Cree un irlAgent y pase los parámetros deseados, seleccione entre el tipo de comportamiento experto para el que desea aprender los pesos y luego ejecute la función OptimumWeightFinder(). Tenga en cuenta que ya obtuve las expectativas de características para los comportamientos rojo, amarillo y marrón. Después de que finalice el algoritmo, obtendrá una lista de pesos en 'pesos-rojo/amarillo/marrón.txt', con el respectivo COMPORTAMIENTO seleccionado. Ahora, para seleccionar el mejor comportamiento posible de todos los pesos obtenidos, reproduzca los modelos guardados en el directorio save-models_BEHAVIOR/evaluatedPolicies/, los modelos se guardan en el siguiente formato 'saved-models_'+ BEHAVIOR +'/evaluatedPolicies/'+ número de iteración+ '-164-150-100-50000-100000' + '.h5' . Básicamente obtendrás diferentes pesos para diferentes iteraciones, primero reproduce los modelos para descubrir cuál funciona mejor, luego anota el número de iteración de ese modelo, los pesos obtenidos correspondientes a este número de iteración son los pesos que te acercan más al experto. comportamiento.
Y luego hay archivos que probablemente no necesites actualizar/modificar, al menos para el contenido de esta publicación:
Después de alrededor de 10 a 15 iteraciones, el algoritmo converge en los 4 comportamientos diferentes elegidos, obtuve los siguientes resultados:
| Pesos | me encanta el amarillo | Me encanta el marrón | me encanta el rojo | me encanta chocar |
|---|---|---|---|---|
| w1 (distancia del sensor izquierdo) | -0.0880 | -0.2627 | 0.2816 | -0.5892 |
| w2 (distancia del sensor medio) | -0.0624 | 0.0363 | -0.5547 | -0.3672 |
| w3 (distancia del sensor derecho) | 0.0914 | 0.0931 | -0.2297 | -0.4660 |
| w4 (color negro) | -0.0114 | 0.0046 | 0.6824 | -0.0299 |
| w5 (color amarillo) | 0.6690 | -0.1829 | -0.3025 | -0.1528 |
| w6 (color marrón) | -0.0771 | 0.6987 | 0.0004 | -0.0368 |
| w7 (color rojo) | -0.6650 | -0.5922 | 0.0525 | -0.5239 |
| w8 (accidente) | -0.2897 | -0.2201 | -0.0075 | 0.0256 |
Se asigna un valor negativo alto al peso que pertenece a la característica de choque en los primeros tres comportamientos, porque estos 3 comportamientos expertos no quieren que el agente choque con obstáculos. Mientras que el peso de la misma característica en el último comportamiento, es decir, el robot Nasty, es positivo, ya que el comportamiento experto aboga por los golpes.
Aparentemente, los pesos para las características de color son respectivos al comportamiento experto, altos cuando se desea ese color; de lo contrario, un valor bastante bajo/negativo para obtener un comportamiento distintivo.
Las ponderaciones de las características de distancia son muy ambiguas (contraintuitivas) y es muy difícil encontrar algún patrón significativo en las ponderaciones. Lo único que deseo señalar es que incluso es posible distinguir comportamientos en el sentido de las agujas del reloj y en el sentido contrario a las agujas del reloj en la configuración actual; las características de distancia llevarán esta información.
Tenga en cuenta que es muy importante pensar primero si usted, como ser humano, podrá distinguir entre los comportamientos dados con la disponibilidad del conjunto de estados actual (las observaciones) al diseñar la estructura del problema. De lo contrario, podría estar obligando al algoritmo a encontrar pesos diferentes sin proporcionarle la información necesaria por completo.
Si realmente desea ingresar a IRL, le recomendaría que intente enseñarle al agente un nuevo comportamiento (es posible que tenga que modificar el entorno para eso, ya que los posibles comportamientos distintos para el conjunto de estados actual ya han sido explotados, bueno). al menos según yo).
Instale las dependencias de Pygame con:
sudo apt install mercurial libfreetype6-dev libsdl-dev libsdl-image1.2-dev libsdl-ttf2.0-dev libsmpeg-dev libportmidi-dev libavformat-dev libsdl-mixer1.2-dev libswscale-dev libjpeg-dev
Luego instale Pygame:
pip3 install hg+http://bitbucket.org/pygame/pygame
Este es el motor de física utilizado por la simulación. Acaba de pasar por una reescritura bastante significativa (v5), por lo que debe obtener la versión v4 anterior. v4 está escrito para Python 2, por lo que hay un par de pasos adicionales.
Regrese a su inicio o descargas y obtenga Pymunk 4:
wget https://github.com/viblo/pymunk/archive/pymunk-4.0.0.tar.gz
Descomprimirlo:
tar zxvf pymunk-4.0.0.tar.gz
Actualización de Python 2 a 3:
cd pymunk-pymukn-4.0.0/pymunk
2to3 -w *.py
Instálalo:
cd .. python3 setup.py install
Ahora regrese a donde clonó reinforcement-learning-car y asegúrese de que todo funcionó con un python3 learning.py . Si ves que aparece una pantalla con un pequeño punto volando alrededor de la pantalla, ¡estás listo para comenzar!
Primero, necesitas entrenar un modelo. Esto guardará los pesos en la carpeta saved-models . Es posible que necesites crear esta carpeta antes de ejecutar . Puedes entrenar el modelo ejecutando:
python3 learning.py
Puede llevar entre una hora y 36 horas entrenar un modelo, según la complejidad de la red y el tamaño de la muestra. Sin embargo, arrojará pesos cada 25.000 fotogramas, por lo que podrás pasar al siguiente paso en mucho menos tiempo.
Edite el archivo playing.py para cambiar el nombre de la ruta del modelo que desea cargar. Lo siento, sé que debería ser un argumento de línea de comando.
Luego, ¡observa cómo el coche sortea los obstáculos!
python3 playing.py
Eso es todo lo que hay que hacer.


