El repositorio consiste en un VQ-VAE implementado en Pytorch y capacitado en el conjunto de datos MNIST.
VQ-VAE siga el mismo concepto básico que detrás de los autoenvocadores variacionales (VAE). VQ-VAE utiliza incrustaciones latentes discretas para codificadores automáticos variacionales , es decir, cada dimensión de Z (vector latente) es un entero discreto, en lugar de la distribución normal continua generalmente utilizada mientras codifica las entradas.
Los VAE consisten en 3 partes:
Bueno, puede preguntar sobre las diferencias que vq-Vaes traen a la mesa. Vamos a enumerarlos:
Muchos objetos importantes del mundo real son discretos. Por ejemplo, en imágenes podríamos tener categorías como "gato", "automóvil", etc., y podría no tener sentido interpolar entre estas categorías. Las representaciones discretas también son más fáciles de modelar.
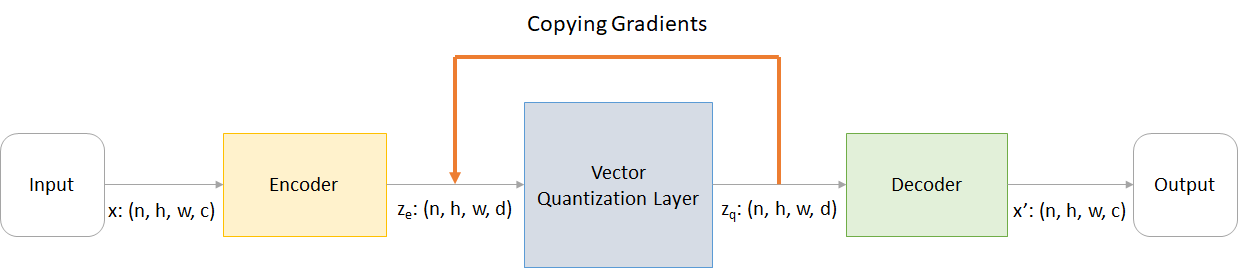
dónde:
n : tamaño por lotesh : Altura de la imagenw : Ancho de imagenc : Número de canales en la imagen de entradad : Número de canales en el estado oculto Aquí hay una breve descripción del funcionamiento de una red VQ-VAE:
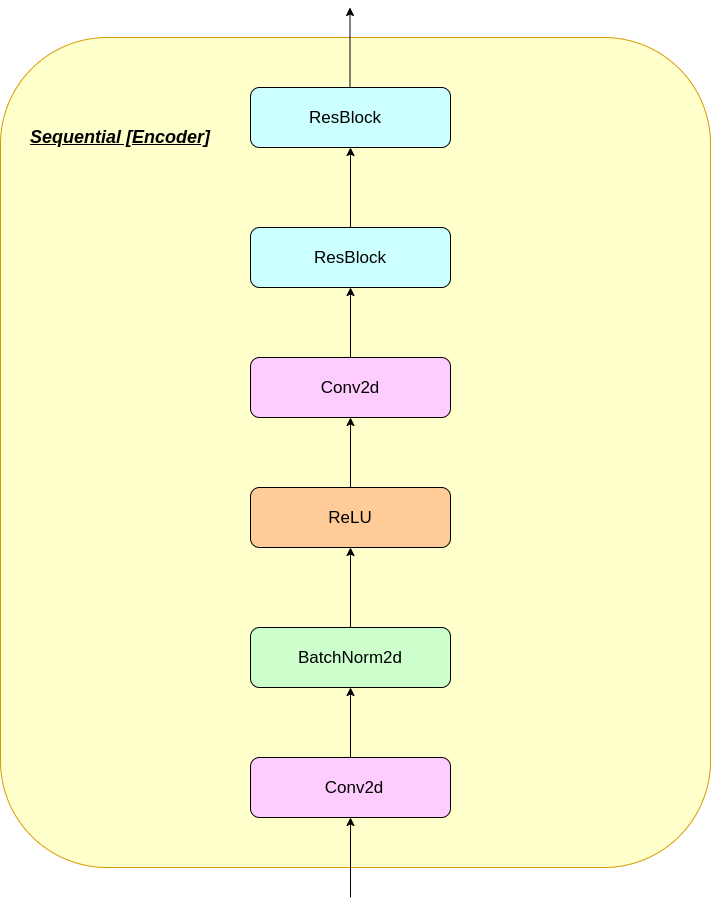
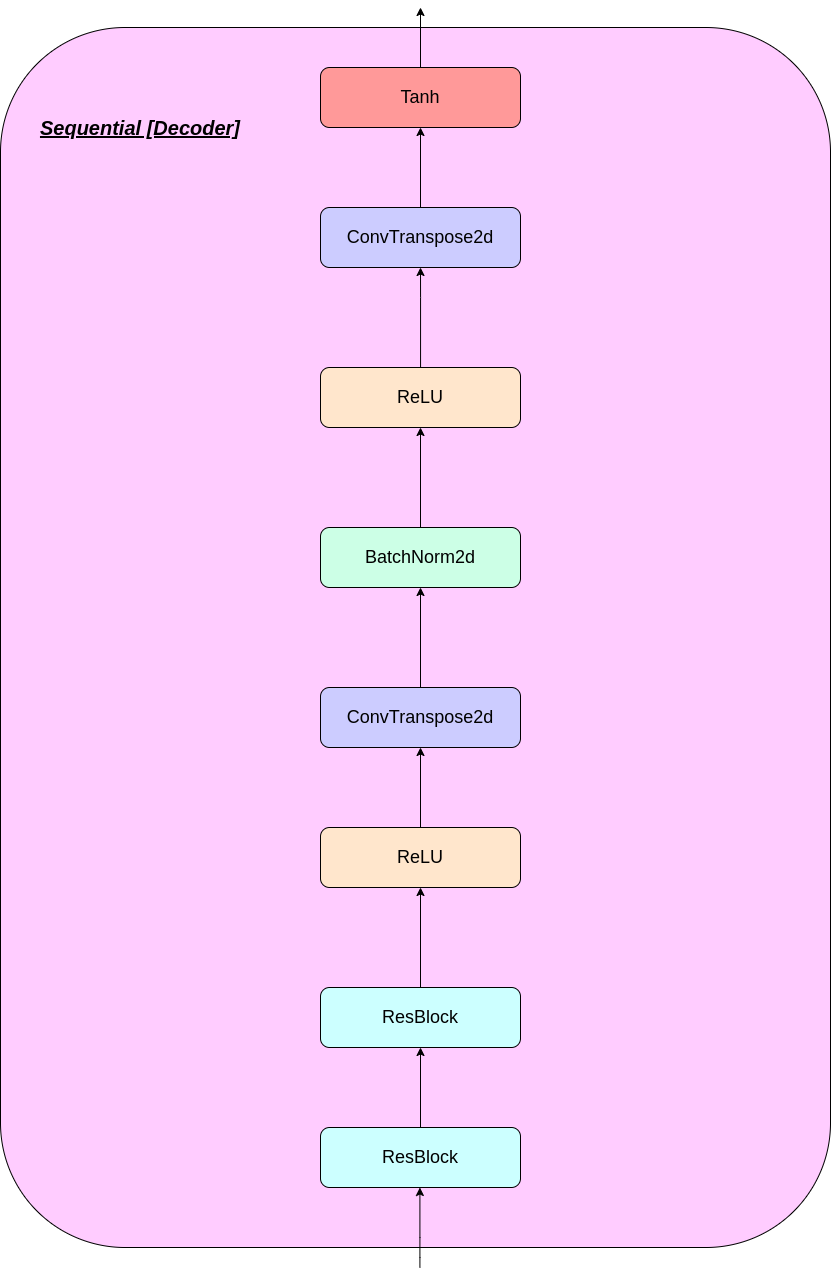
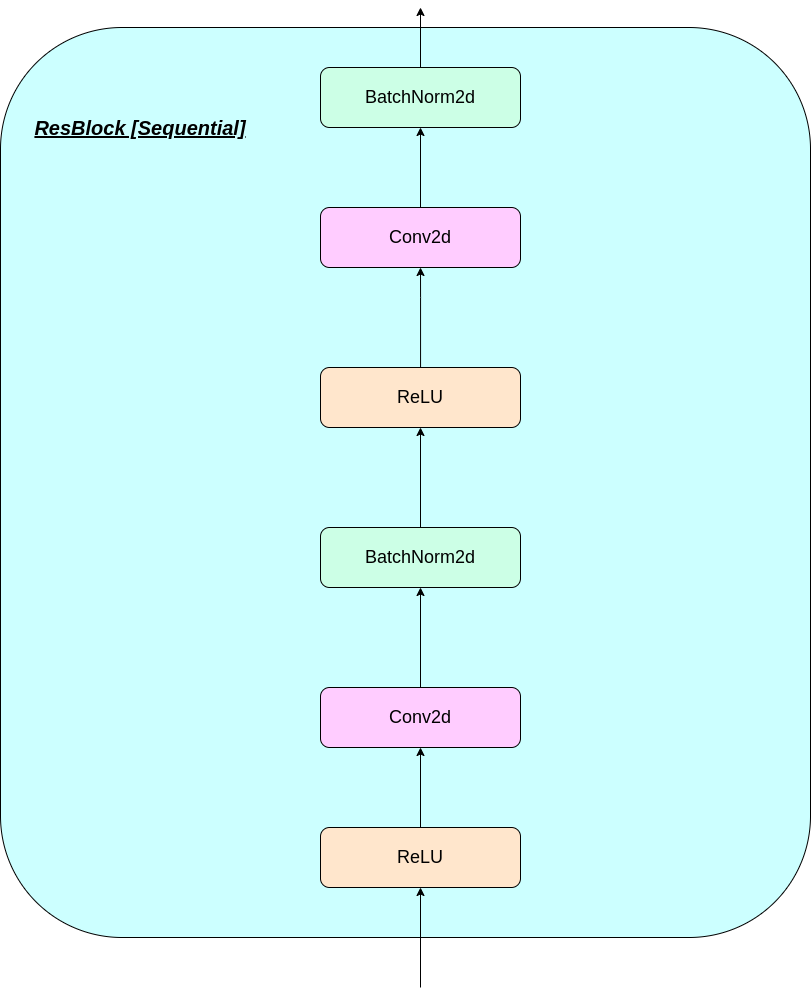
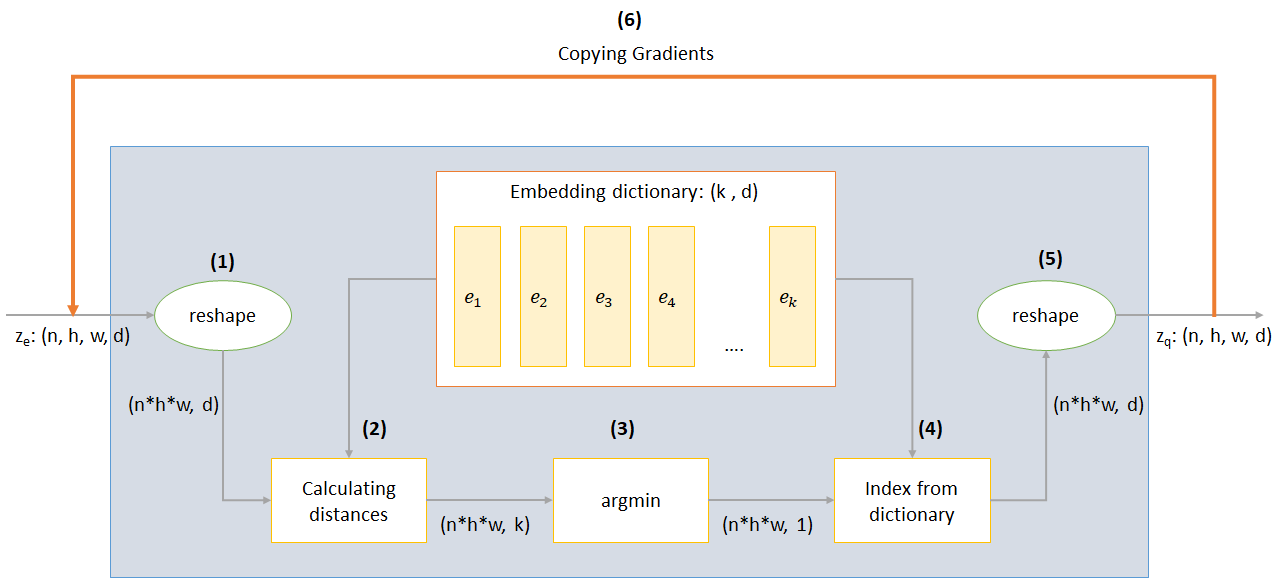
El funcionamiento de la capa VQ se puede explicar en seis pasos como se numera en la figura:
VQ-VAE utiliza 3 pérdidas para calcular la pérdida total durante el entrenamiento:
Pérdida de reconstrucción: optimiza el decodificador y el codificador como VAE, es decir, la diferencia entre la imagen de entrada y la reconstrucción:
reconstruction_loss = -log( p(x|z_q) )
Pérdida del libro de códigos: debido al hecho de que los gradientes omiten la incrustación, se utiliza un algoritmo de aprendizaje de diccionario que utiliza un error L2 para mover los vectores de incrustación E_I hacia la salida del codificador.
codebook_loss = ‖ sg[z_e(x)]− e ‖^2
(SG representa el operador de gradiente de parada, lo que significa que ningún gradiente fluye a través de lo que se aplique)
Pérdida de compromiso: dado que el volumen del espacio de incrustación es adimensional, puede crecer arbitrariamente si las incrustaciones e_i no entrenan tan rápido como los parámetros del codificador y, por lo tanto, se agrega una pérdida de compromiso para asegurarse de que el codificador se comprometa a una incrustación.
commitment_loss = β‖ z_e(x)− sg[e] ‖^2
(β es un hiperparámetro que controla cuánto queremos sopesar la pérdida de compromiso en comparación con otros componentes)
Puede descargar el repositorio o clonarlo ejecutando lo siguiente en el aviso CMD
https://github.com/praeclarumjj3/VQ-VAE-on-MNIST.git
Puede entrenar el modelo desde cero por el siguiente comando (en Google Colab)
! python3 VQ-VAE.py --output-folder [NAME_OF_OUTPUT_FOLDER] --data-folder [PATH_TO_MNIST_dataset] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --batch-size [BATCH_SIZE] --num_epoch [NUMBER_OF_EPOCHS] --lr [LEARNING_RATE] --beta [VALUE] --num-workers [NUMBER_OF_WORKERS]
output-folder - Nombre de la carpeta de datosdata-folder : nombre de la carpeta de datosdevice : configure el dispositivo (CPU o CUDA, predeterminado: CPU)hidden-size : tamaño de los vectores latentes (predeterminado: 40)k - Número de vectores latentes (predeterminado: 512)batch-size - Tamaño de lote (predeterminado: 128)num-epochs - Número de épocas (predeterminado: 10)lr - Tasa de aprendizaje para Adam Optimizer (predeterminado: 2E -4)beta : contribución de la pérdida de compromiso, entre 0.1 y 2.0 (predeterminado: 1.0)num-workers - Número de trabajadores para muestreo de trayectorias (predeterminado: cpu_count () - 1) El programa descarga automáticamente el conjunto de datos MNIST y lo guarda en la carpeta PATH_TO_MNIST_dataset (necesita crear esta carpeta). Esto solo sucede una vez.
También crea una carpeta logs y models de carpeta y dentro de ellos crea una carpeta con el nombre pasado por usted para guardar registros y modelar puntos de control dentro de ella respectivamente.
Para generar nuevas imágenes de Z muestreadas al azar desde una unidad Gaussian Ejecute el siguiente comando (en Google Colab):
! python3 generate.py --model [SAVED_MODEL_FILENAME] --input [MNIST_or_random] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --filename [SAVING_NAME]
model : nombre de archivo que contiene el modeloinput - Mnist o Randomdevice : configure el dispositivo (CPU o CUDA, predeterminado: CPU)hidden-size : tamaño de los vectores latentes (predeterminado: 40)k - Número de vectores latentes (predeterminado: 512)filename : nombre con el que se guardará el archivo Genera una cuadrícula de 10*10 de imágenes que se guardan en una carpeta llamada generatedImages .
Puede usar un modelo previamente capacitado descargándolo desde el enlace en model.txt .
El repositorio contiene los siguientes archivos
modules.py : contiene los diferentes módulos utilizados para hacer nuestro modeloVQ-VAE.py : contiene las funciones y el código para capacitar a nuestro modelo VQ-VAEvector_quantizer.py : las clases de cuantificación vectorial se definen en este archivogenerate-py : genera nuevas imágenes a partir de un modelo previamente capacitadomodel.txt : contiene un enlace a un modelo previamente capacitadoREADME.md - Readme que da una visión general del repositorioreferences.txt : referencias utilizadas al crear este repositorioreadme_images - tiene varias imágenes para el readmeMNIST : contiene el conjunto de datos MNIST con cremallera (aunque se descargará automáticamente si es necesario)Training track for VQ-VAE.txt : contiene los valores de pérdida durante el entrenamiento de nuestro modelo VQ-VAElogs_VQ-VAE : contiene los registros de placa tensor con cremallera para nuestro modelo VQ-VAE (creado automáticamente por el programa)testers.py : contiene algunas funciones para probar nuestros módulos definidosComando para ejecutar TensorBoard (en Google Colab):
%load_ext tensorboard
%tensordboard --logdir [path_to_folder_with_logs]
Imagen de entrenamiento
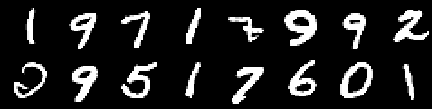
Imagen de 0th Epoch

Imagen de la 2da época
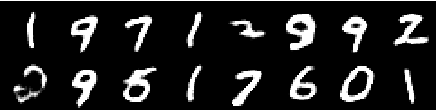
Imagen de la 4ta época
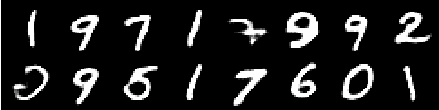
Imagen de la sexta época
Imagen de la octava época
Imagen de la décima época
Las reconstrucciones siguen mejorando y al final casi se parecen a las imágenes de entrenamiento_set que se reflejan en los valores de pérdida (verifique la Training track for VQ-VAE.txt ).
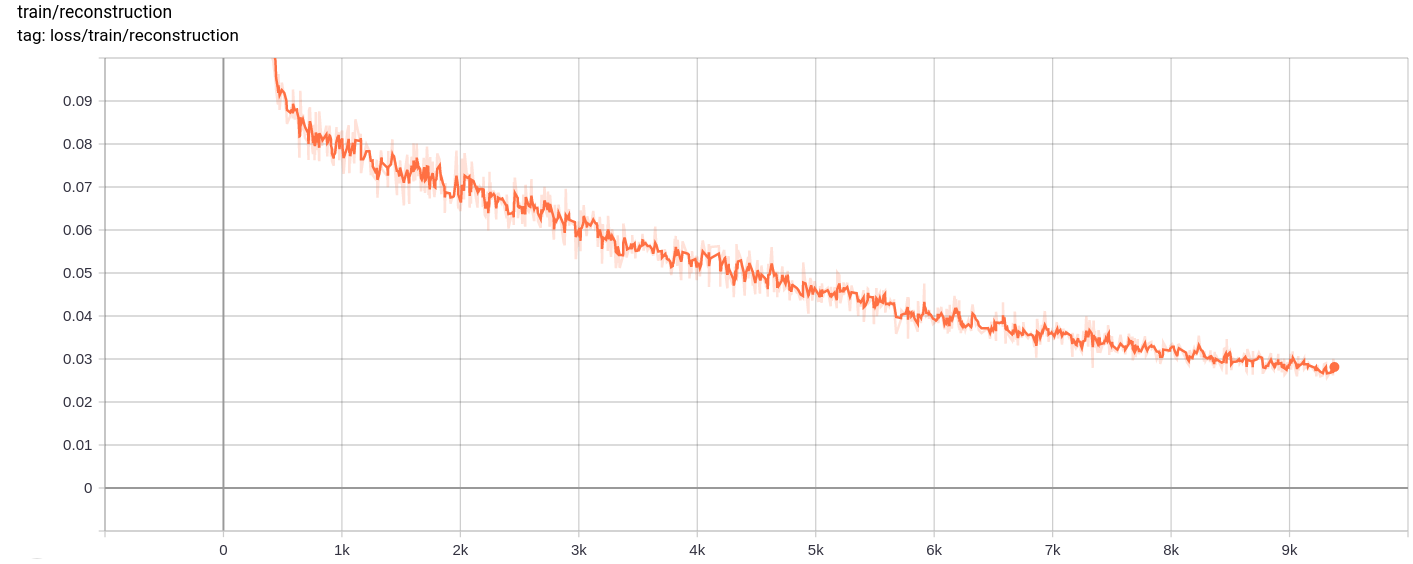
Pérdida de reconstrucción
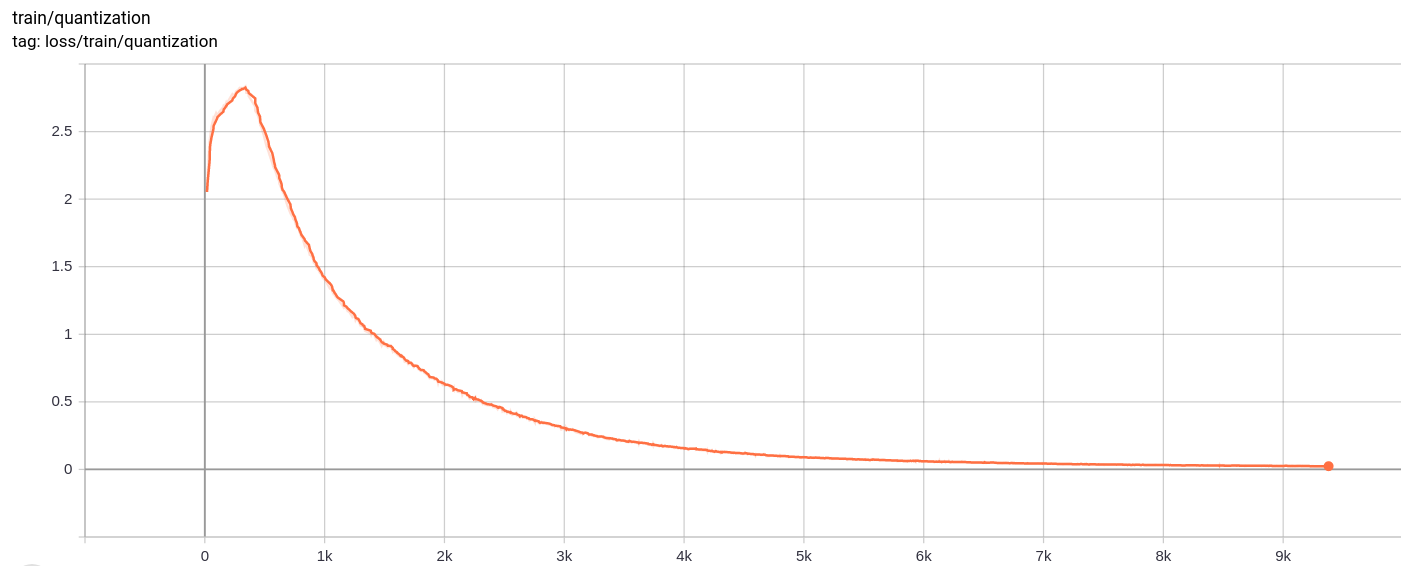
Pérdida de cuantificación
Total_loss
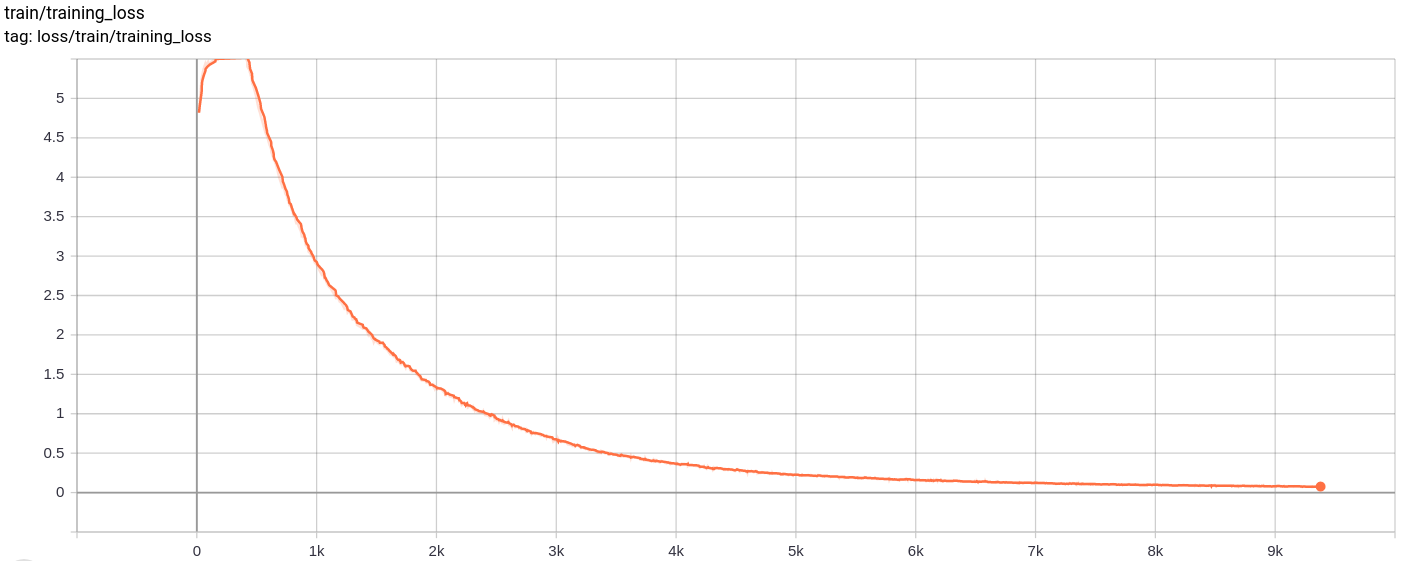
La pérdida total, la pérdida de reconstrucción y la pérdida de cuantización disminuyen de manera uniforme como se esperaba.
Testing_loss
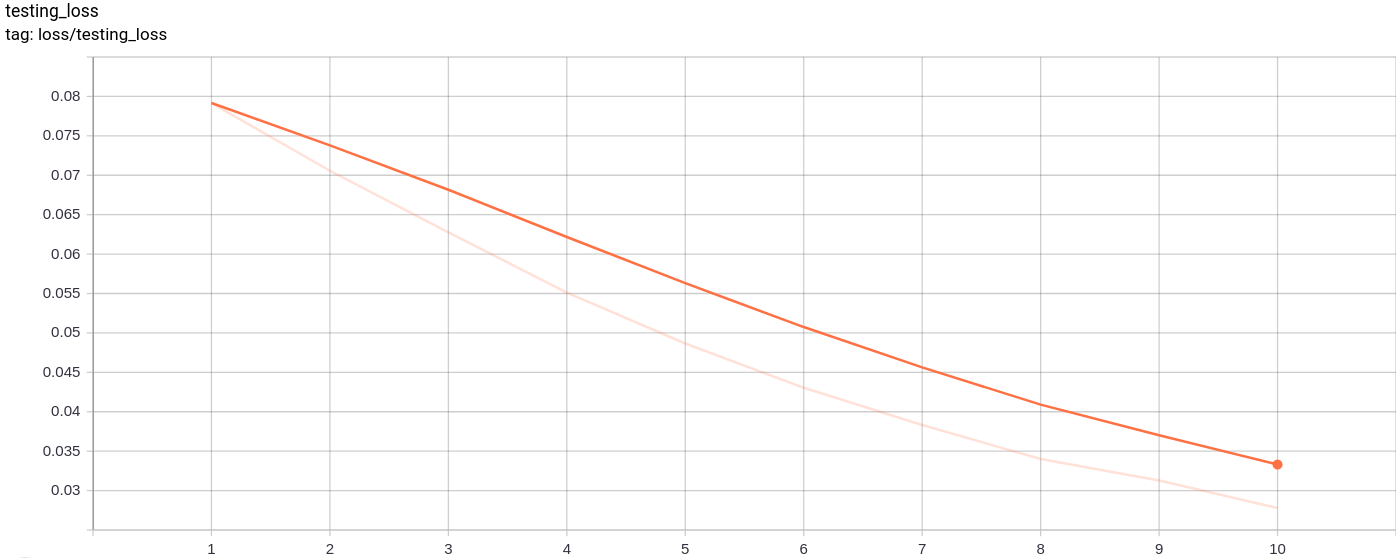
La pérdida de prueba disminuye de manera uniforme como se esperaba.
La siguiente cuadrícula de imagen se generó después de pasar imágenes MNIST como entradas:

La generación es bastante buena.
Las siguientes cuadrículas de imagen se generaron después de pasar AZ muestreadas al azar de una unidad gaussiana como entrada al modelo y luego pasó por el decodificador


Las imágenes no se ven perfectas. Sintonizar las dimensiones del espacio latente, el número de vectores de incrustación, etc., puede ayudar a generar mejores imágenes aleatorias.
El modelo fue entrenado en Google Colab para 10 épocas, con el tamaño del lote 128.
Después de entrenar, el modelo pudo reconstruir las imágenes de entrada bastante bien, y también pudo generar nuevas imágenes, aunque las imágenes generadas no son tan buenas.
La capacitación y la pérdida de pruebas también siguieron disminuyendo casi monotónicamente.
Observé que el entrenamiento del modelo para más de 10-20 épocas produjo resultados que sugirieron un signo probable de sobreajuste en el modelo. Además, experimenté con diferentes dimensiones del espacio Latednt y en la dimension = 40 produje los mejores resultados. El mejor rango para la dimensión salió a ser entre 16 y 42.
Las siguientes fuentes ayudaron mucho a hacer este repositorio.


