Face Shape Classification using CNN
1.0.0

Este es un proyecto de clasificación de imágenes para identificar 5 formas faciales femeninas utilizando redes neuronales convolucionales (CNN) . Completé esto como mi Capstone Project for Data Science Inmersive Course con Asamblea General (octubre de 2020).
Este proyecto también se implementa como una aplicación web que usa Stremlit en Heroku. Si está interesado, revise la forma de su cara en myfaceShape.eokuapp.com
Según la revisión del consumidor de Deloitte, los consumidores exigen una experiencia más personalizada, sin embargo, la prueba sigue siendo baja. En la industria de la belleza y la moda, más del 40%de los adultos de 16 a 39 años están interesados en una oferta personalizada, mientras que el juicio es solo del 10%-14%. Entre los interesados, ~ 80% están dispuestos a pagar al menos un precio de 10% más alto.
Al poder clasificar las formas faciales permitirá a las marcas ofrecer soluciones más personalizadas para aumentar la satisfacción del cliente, al tiempo que aumenta el margen del posicionamiento premium. Ejemplo de casos de uso son:
Para este proyecto, utilizaré un enfoque de aprendizaje profundo con redes neuronales convolucionales (CNN) para clasificar 5 formas de cara femenina diferentes (corazón, oblongo, ovalado, redondo, cuadrado). Se eligirá el modelo que fue la puntuación de mayor precisión.
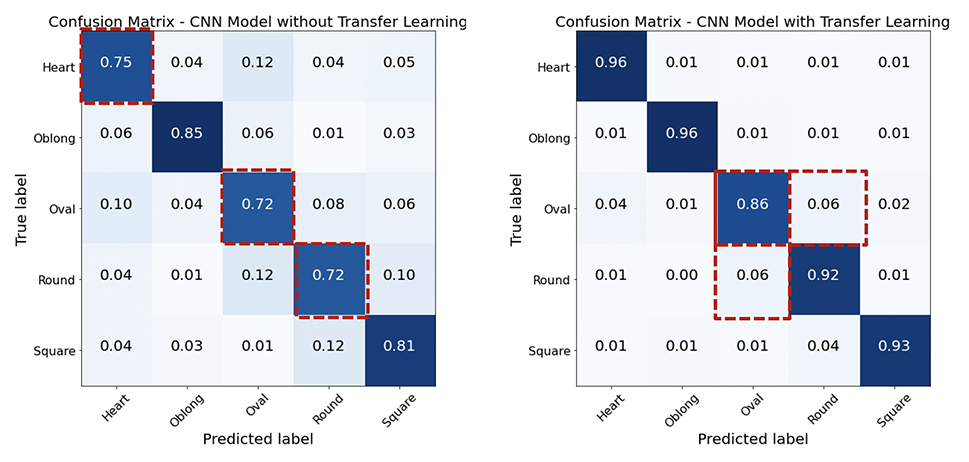
He explorado 2 enfoques de CNN construyendo desde cero frente al aprendizaje de Trasfer con arquitectura VGG-16 y pesos previamente capacitados de VGGFace. El enfoque de aprendizaje de transferencia ayudó a aumentar la precisión, mientras que la forma de la cara más mal clasificada es 'ovalada'.
El preprocesamiento de la imagen también jugó un papel importante en la reducción de la sobreajuste y el aumento de la precisión de validación. Los controladores clave son:
El conjunto de datos de la forma de la cara es un conjunto de datos de Kaggle de Niten Lama.
Este conjunto de datos comprende un total de 5000 imágenes de las celebridades femeninas de todo el mundo que se clasifican de acuerdo con su forma de cara, a saber:
Cada categoría consta de 1000 imágenes (800 para capacitación: 200 para pruebas)
El preprocesamiento de las imágenes es un factor crítico para reducir el sobreajuste del modelo al conjunto de datos de entrenamiento y aumentar la precisión de validación. Se han explorado los siguientes pasos:
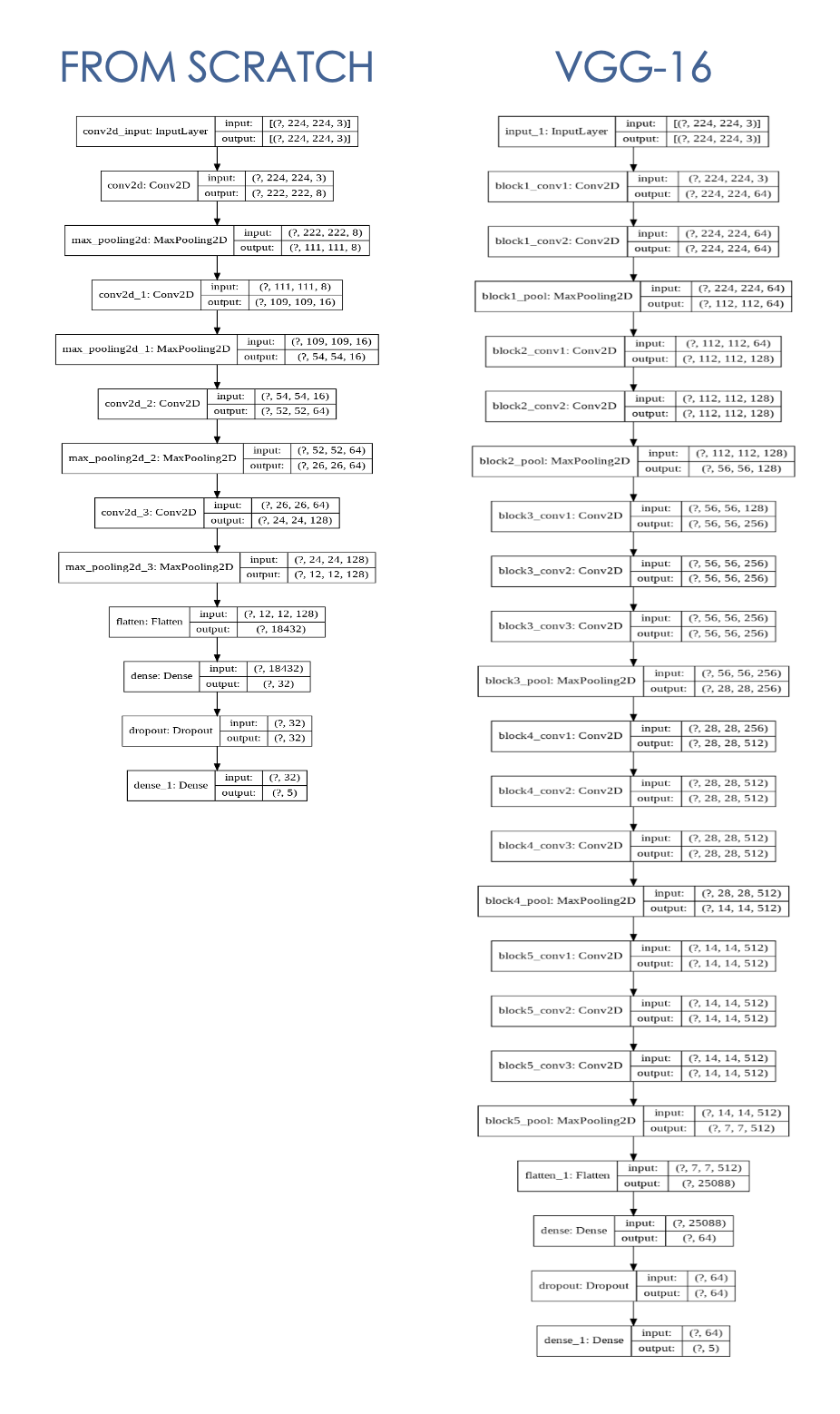
Modelo CNN construido desde cero con datos de entrenamiento limitados de 4000 imágenes (800 imágenes x 5 clases), construyo el modelo con 4 capas convolucionales de + poleación máxima y 2 capas densas (detalles a continuación).
El modelo CNN con el aprendizaje de transferencia me permite usar una arquitectura VGG-16 más compleja, mediante el uso de pesos previamente capacitados de VGGFace que ha sido entrenado en más de 2.6 millones de imágenes.
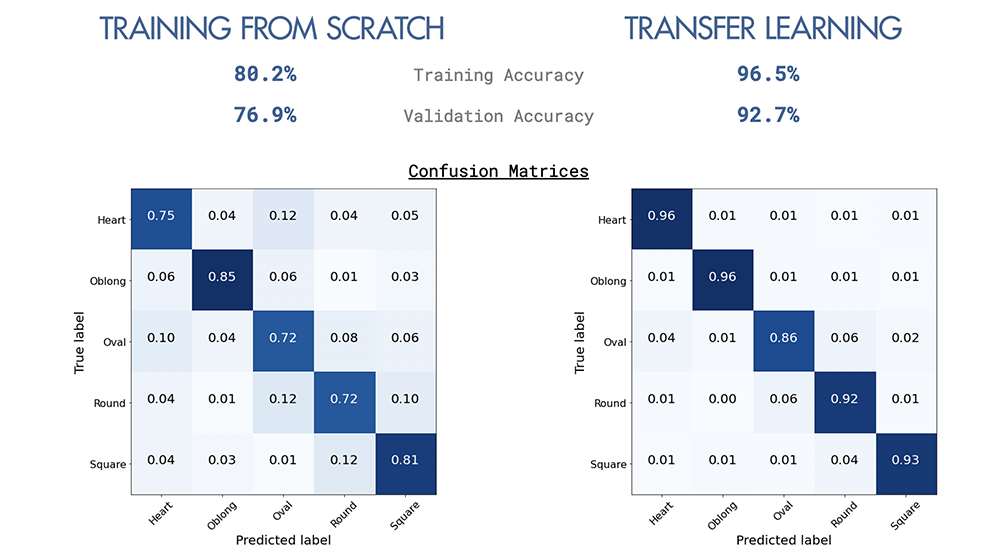
El aprendizaje de la transferencia ayudó a mejorar la precisión significativamente, de 76.9% a 92.7%, con la ayuda de pesos previamente capacitados en un conjunto de datos más grande.
A partir de los modelos construidos desde cero, todos los modelos funcionaban mejor que la línea de base del 20% (5 clases están equilibradas con 20% cada uno).
Resumen de todos los modelos a continuación.

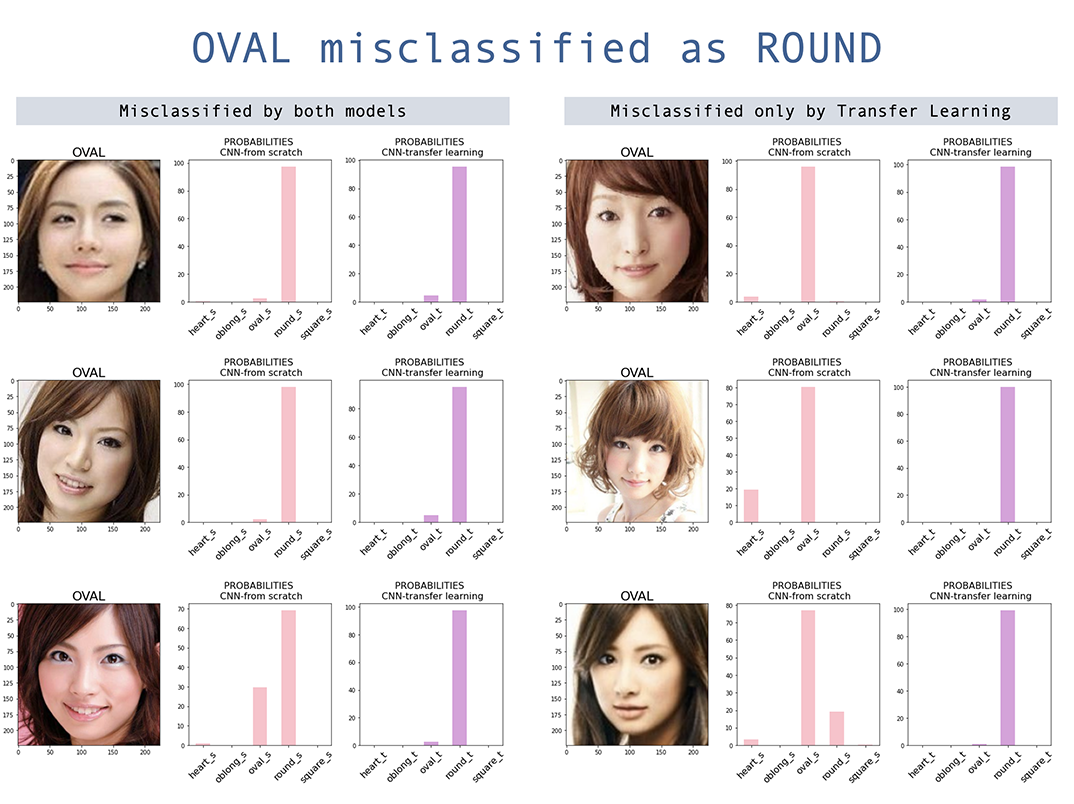
Ambos modelos tienen una clasificación errónea más alta en forma de cara ovalada . Aunque el modelo de aprendizaje de transferencia mejoró la precisión del modelo construido desde cero, pero Oval sigue siendo el más concretado, y la mayoría se clasifica erróneamente como redonda. Curiosamente, la cara redonda también se clasifica erróneamente como ovalada, aunque la clasificación errónea general de la cara redonda es baja. La confusión entre oval y redondo son en su mayoría caras asiáticas, y más aún con el aprendizaje de transferencia. Esto es probable porque los pesos previos a la aparición tienen menos imágenes asiáticas.