guidewire
1.0.0
Interpretación Guidewire CDA Como Table Delta: como empresa de tecnología, GuideWire ofrece una plataforma de la industria para compañías de seguros de propiedades y víctimas en todo el mundo. A través de diferentes productos y servicios bajo su suite de seguros, proporcionan a los usuarios las capacidades de operación requeridas para adquirir, procesar y resolver reclamos, mantener políticas, apoyar los procesos de suscripción y ajuste. Databricks, por otro lado, proporciona a los usuarios capacidades analíticas (desde informes básicos hasta soluciones ML complejas) a través de su Lakehouse para el seguro. Al combinar ambas plataformas juntas, las compañías de seguros de P&C ahora tienen la capacidad de comenzar a integrar las capacidades de análisis avanzados (AI/ML) en sus procesos comerciales centrales, enriqueciendo la información del cliente con datos alternativos (por ejemplo, datos meteorológicos) pero conciliando e informando la información crítica en la empresa en la empresa escala.
GuideWire admite el acceso a los datos al entorno analítico a través de su oferta de acceso a datos en la nube (CDA). El almacenamiento de archivos como archivos de parquet individuales bajo diferentes marcas de tiempo y evolución del esquema desafortunadamente está dificultando el procesamiento de los usuarios finales. En lugar de procesar archivos individualmente, ¿por qué no generaríamos los archivos manifiestos delta log para leer solo la información que necesitamos, cuando la necesitamos, sin tener que descargar, procesar y reconciliar información compleja? Este es el principio detrás de esta iniciativa. La tabla delta generada no se materializará (los datos no se moverán físicamente) sino que actúen como un clon superficial para guiar los datos.
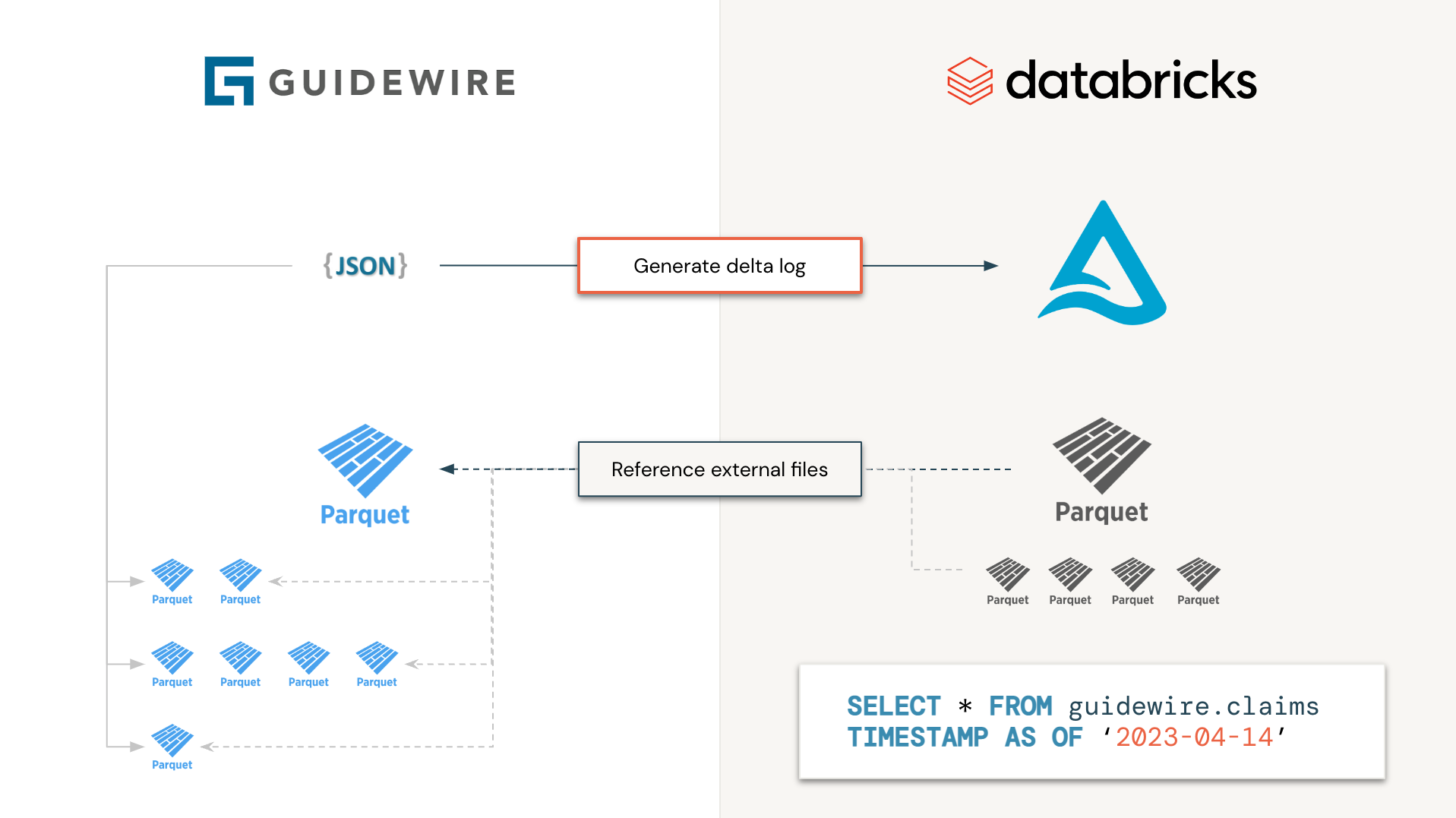
Más específicamente, procesaremos todas las tablas Guidewire de forma independiente, en paralelo (es decir, como un trabajo de chispa), donde cada tarea consistirá solo en enumerar archivos y carpetas de parquet y generar el registro delta en consecuencia. Desde el punto de vista del usuario final, Guidewire se verá como una tabla delta y se procesará como tal, reduciendo el tiempo de procesamiento de días a segundos (ya que no tenemos que descargar y procesar cada archivo a través de muchos trabajos de Spark).

Como los datos ahora están en Delta Lake (se materializan físicamente o no), uno puede beneficiarse de todas las capacidades aguas abajo del lago Delta, "suscribiéndose" a cambios a través de capacidades de cargador automático, Tabla Delta Live (DLT) o incluso Delta Compartir, acelerar Hora de ideas de días a minutos.
Como este modelo sigue un enfoque de clonos poco profundos, se recomienda solo otorgar permiso de lectura al usuario final, ya que una operación VACCUM en el delta generado posiblemente daría lugar a una pérdida de datos en el cubo Guidewire S3. Recomendamos encarecidamente que la organización no exponga este conjunto de datos sin procesar a los usuarios finales, sino que cree una versión plateada con datos materializados para el consumo. Tenga en cuenta que un comando OPTIMIZE dará como resultado la materialización de la última instantánea delta con archivos de parquet optimizados. Solo los archivos relevantes se descargarán físicamente de S3 original a la tabla de destino.
import com . databricks . labs . guidewire . Guidewire
val manifestUri = " s3://bucket/key/manifest.json "
val databasePath = " /path/to/delta/database "
Guidewire .index(manifestUri, databasePath) Este comando se ejecutará en un incremento de datos de forma predeterminada, cargando nuestros puntos de control anteriores almacenados como una tabla Delta en ${databasePath}/_checkpoints . Si necesita reindexar todos los datos de guía de guía, proporcione el parámetro savemode opcional de la siguiente manera
import org . apache . spark . sql . SaveMode
Guidewire .index(manifestUri, databasePath, saveMode = SaveMode . Overwrite )Siguiendo un patrón de 'clonos poco profundos', los archivos de guía no se almacenarán sino que se hace referencia desde una ubicación delta que puede definirse como una tabla externa.
CREATE DATABASE IF NOT EXISTS guidewire;
CREATE EXTERNAL TABLE IF NOT EXISTS guidewire . policy_holders LOCATION ' /path/to/delta/database/policy_holders ' ;Finalmente, podemos consultar Guidewire Data y acceder a todas sus diferentes versiones en diferentes marcas de tiempo.
SELECT * FROM guidewire . policy_holders
VERSION AS OF 2 mvn clean package -Pshaded Siguiendo el estándar Maven, agregue perfil shaded para generar un archivo jar independiente con todas las dependencias incluidas. Este frasco se puede instalar en un entorno de Databricks en consecuencia.


