Marketing Attribution Models
1.0.10
Clase de Python creada para abordar problemas con respecto a la atribución de marketing digital.
Mientras navega en línea, un usuario tiene múltiples puntos de contacto antes de convertirse, lo que podría conducir a viajes cada vez más largos y complejos.
¿Cómo acreditar debidamente las conversiones y optar la inversión en los medios?
Para admitir esto, aplicamos modelos de atribución .
Modelos heurísticos :
Última interacción :
Atribución predeterminada en Gogle Analytics y otras plataformas de medios, como Google Ads y Facebook Business Manager;
Solo se acredita el último punto de contacto para la conversión.
Último clic no directo :
Se ignora todo el tráfico directo y, por lo tanto, el 100% del resultado va al último canal a través del cual el cliente llegó al sitio web antes de convertirse.
Primera interacción :
El resultado se atribuye por completo al primer punto de contacto.
Lineal :
Cada punto de contacto es igualmente acreditado.
Decadencia de tiempo :
Cuanto más reciente es un punto de contacto, más crédito se obtiene.
Posición basada :
En este modelo, el 40% del resultado se atribuye al último punto de contacto, otro 40% al primero y el 20% restante se distribuye igualmente entre los canales a mitad de camino.
Modelos algotítmicos
Valor de Shapley
Utilizado en la teoría del juego, este valor es una estimación de la contribución de cada jugador individual en un juego cooperativo.
Las conversiones se acreditan a los canales mediante un proceso de permutación de los viajes. En cada permutación se entrega un canal para estimar cómo es la esencia que es en general.
Como ejemplo , echemos un vistazo al siguiente viaje hipoternario:
Búsqueda orgánica> Facebook> Direct> $ 19 (como ingresos)
Para obtener el valor de Shapley de cada canal, primero debemos considerar todos los valores de conversión para las permutaciones de componentes de este viaje dado.
Búsqueda orgánica> $ 7
Facebook> $ 6
Directo> $ 4
Búsqueda orgánica> Facebook> $ 15
Búsqueda orgánica> Direct> $ 7
Facebook> Directo> $ 9
Búsqueda orgánica> Facebook> Direct> $ 19
El número de componentes Joneys aumenta exponencialmente los canales más distintos que tiene: la velocidad es 2^N (2 a la potencia de N) para los canales N.
En otras palabras, con 3 puntos de contacto distintos hay 8 permutaciones. Con más de 15, por ejemplo, este proceso es inviable .
Por defecto, el orden de los puntos de contacto no se tiene en cuenta al calcular el valor de Shapley, solo su presencia o falta de allí. Para hacerlo, aumenta el número de permutaciones.
Con eso en mente, tenga en cuenta que es bastante difícil usar este modelo al considerar el orden de las interacciones. Para los canales n, no solo hay 2^n permutaciones de un canal I dado, sino también cada permutación que contiene i en una posición diferente .
Algunos problemas y limitaciones del valor de Shapley
Las cadenas de Markov, una cadena de Markov, es un proceso estocástico particular en el que la distribución de probabilidad de cualquier estado siguiente depende solo de lo que sea el estado actual, sin tener en cuenta los estados precedentes y su secuencia.
En la atenución multicanal, podemos usar las cadenas de Markov para calcular la probabilidad de interacción entre pares de canales de medios con la matriz de transición .
Con respecto a la contribución de cada canal en las conversiones, el efecto de eliminación entra: para cada jorney se elimina un canal dado y se calcula una probabilidad de conversión.
El valor atribuido a un canal, entonces, se obtiene por la relación de la diferencia entre la probabilidad de conversión en general y la probabilidad una vez que dicho canal se elimine nuevamente sobre la probabilidad general.
En otras palabras, cuanto más grande es el efecto de eliminación de un canal, mayor será su contribución.
** Al trabajar con los procesos de Markovian, no hay restricciones debido a la cantidad u orden de los canales. Su secuencia, en sí misma, es una parte fundamental del algoritmo.
>> pip install marketing_attribution_models from marketing_attribution_models import MAM Al crear un objeto MAM, se pueden usar dos plantillas de cuadro de datos como entrada dependiendo de cuál sea el valor de los parámetros group_channels .
Para esta demostración, utilizaremos un marco de datos en el que los viajes aún no se agrupen , con cada fila como una sesión diferente y sin una identificación de viaje única.
Note: The MAM Class has a built in parameter for journey id creation, create_journey_id_based_on_conversion , that if True , an id is created based on the user id, input in the group_channels_id_list parameter, and the column indicating wether there is a conversion or not, whose El nombre se define por el parámetro Journey_With_Conv_ColName .
En este escenario, se ordenarán todas las sesiones de cada usuario distinto y para cada conversión se crea una nueva ID de viaje. Sin embargo, alentamos mucho que esta creación de ID de viaje se personalice en función del conocimiento específico del negocio en cuestión y las conclusiones exploratorias. Por ejemplo, si en un negocio determinado se observa que la duración promedio del viaje es de aproximadamente una semana, se puede definir un nuevo crítico para que una vez que cualquier usuario no tenga ninguna interacción durante siete días, el viaje se rompe bajo el supuesto de que hubo una pérdida de interés.
En cuanto a los parámetros ahora, así es como están configurados para nuestro escenario Group_ Channels = True:
attributions = MAM ( df ,
group_channels = True ,
channels_colname = 'channels' ,
journey_with_conv_colname = 'has_transaction' ,
group_channels_by_id_list = [ 'user_id' ],
group_timestamp_colname = 'visitStartTime' ,
create_journey_id_based_on_conversion = True )Para explorar y comprender las capacidades de MAM, se implementó un "generador de marco de datos aleatorio" mediante el uso del parámetro Random_DF cuando se establece en True .
attributions = MAM ( random_df = True )Después de que se crea el objeto MAM, podemos consultar nuestra base de datos ahora con la adición de nuestro Journey_ID y con sesiones agrupadas en viajes utilizando el Attriute ".DataFrame" .
attributions . DataFrame| Journey_id | Channels_agg | Time_till_conv_agg | convertido_agg | conversion_value | |
|---|---|---|---|---|---|
| 0 | ID: 0_J: 0 | 0.0 | Verdadero | 1 | |
| 1 | ID: 0_J: 1 | Búsqueda de Google | 0.0 | Verdadero | 1 |
| 2 | ID: 0_J: 10 | Búsqueda de Google> Orgánica> Marketing por correo electrónico | 72.0> 24.0> 0.0 | Verdadero | 1 |
| 3 | ID: 0_J: 11 | Orgánico | 0.0 | Verdadero | 1 |
| 4 | ID: 0_J: 12 | Marketing por correo electrónico> Facebook | 432.0> 0.0 | Verdadero | 1 |
| ... | ... | ... | ... | ... | ... |
| 20341 | ID: 9_J: 5 | Directo> Facebook | 120.0> 0.0 | Verdadero | 1 |
| 20342 | ID: 9_J: 6 | Búsqueda de Google> Búsqueda de Google> Búsqueda de Google | 48.0> 24.0> 0.0 | Verdadero | 1 |
| 20343 | ID: 9_J: 7 | Orgánico> orgánico> búsqueda de google> búsqueda de google | 480.0> 480.0> 288.0> 0.0 | Verdadero | 1 |
| 20344 | ID: 9_J: 8 | Directo> orgánico | 168.0> 0.0 | Verdadero | 1 |
| 20345 | ID: 9_J: 9 | Búsqueda de Google> Orgánica> Búsqueda de Google> Emai ... | 528.0> 528.0> 408.0> 240.0> 0.0 | Verdadero | 1 |
Este atributo se actualiza para cada modelo de atribución generado. Solo en el caso de los modelos heurísticos, se agrega una nueva columna que contiene el valor de atribución dado por dicho modelo.
Nota: El atributo .Dataframe no interfiere con ningún cálculo del modelo. Si se altera mediante el uso, los siguientes resultados no se ven afectados.
attributions . attribution_last_click ()
attributions . DataFrame| Journey_id | Channels_agg | Time_till_conv_agg | convertido_agg | conversion_value | |
|---|---|---|---|---|---|
| 0 | ID: 0_J: 0 | 0.0 | Verdadero | 1 | |
| 1 | ID: 0_J: 1 | Búsqueda de Google | 0.0 | Verdadero | 1 |
| 2 | ID: 0_J: 10 | Búsqueda de Google> Orgánica> Marketing por correo electrónico | 72.0> 24.0> 0.0 | Verdadero | 1 |
| 3 | ID: 0_J: 11 | Orgánico | 0.0 | Verdadero | 1 |
| 4 | ID: 0_J: 12 | Marketing por correo electrónico> Facebook | 432.0> 0.0 | Verdadero | 1 |
| ... | ... | ... | ... | ... | ... |
| 20341 | ID: 9_J: 5 | Directo> Facebook | 120.0> 0.0 | Verdadero | 1 |
| 20342 | ID: 9_J: 6 | Búsqueda de Google> Búsqueda de Google> Búsqueda de Google | 48.0> 24.0> 0.0 | Verdadero | 1 |
| 20343 | ID: 9_J: 7 | Orgánico> orgánico> búsqueda de google> búsqueda de google | 480.0> 480.0> 288.0> 0.0 | Verdadero | 1 |
| 20344 | ID: 9_J: 8 | Directo> orgánico | 168.0> 0.0 | Verdadero | 1 |
| 20345 | ID: 9_J: 9 | Búsqueda de Google> Orgánica> Búsqueda de Google> Emai ... | 528.0> 528.0> 408.0> 240.0> 0.0 | Verdadero | 1 |
Por lo general, el volumen de datos trabajados es extenso, por lo que no es práctico o incluso imposible analizar los resultados atribuidos a cada viaje con transacción. Sin embargo, con el Attribute Group_By_channels_Models , todos los resultados se pueden ver agrupados por canal.
Nota : Los resultados agrupados no se sobrescriben en caso de que el mismo modelo se use en dos casos distintos. Ambos (o incluso más) de ellos se muestran en " group_by_channels_models ".
attributions . group_by_channels_models| canales | attribution_last_click_heuristic |
|---|---|
| Directo | 2133 |
| Marketing por correo electrónico | 1033 |
| 3168 | |
| Visualización de Google | 1073 |
| Búsqueda de Google | 4255 |
| 1028 | |
| Orgánico | 6322 |
| YouTube | 1093 |
Al igual que con el atributo .dataframe , Group_By_channels_Models también se actualiza para cada modelo utilizado sin la limitación de no mostrar resultados algorítmicos.
attributions . attribution_shapley ()
attributions . group_by_channels_models| canales | attribution_last_click_heuristic | atribution_shapley_size4_conv_rate_algorithmic | |
|---|---|---|---|
| 0 | Directo | 109 | 74.926849 |
| 1 | Marketing por correo electrónico | 54 | 70.558428 |
| 2 | 160 | 160.628945 | |
| 3 | Visualización de Google | 65 | 110.649352 |
| 4 | Búsqueda de Google | 193 | 202.179519 |
| 5 | 64 | 72.982433 | |
| 6 | Orgánico | 315 | 265.768549 |
| 7 | YouTube | 58 | 60.305925 |
Todos los modelos heurísticos se comportan de la misma manera cuando se usan los atributos .Dataframe y .group_by_channels_models , como se explicó anteriormente, y la salida de todos los métodos del modelo heurístico devuelve una tupla que contiene dos series Pandas .
attribution_first_click = attributions . attribution_first_click ()La primera serie de la tupla son los resultados en una granularidad de viaje , similar a la observada en el atributo .dataframe
attribution_first_click [ 0 ] 0 [1, 0, 0, 0, 0]
1 [1]
2 [1, 0, 0, 0, 0, 0, 0, 0, 0]
3 [1, 0]
4 [1]
...
20512 [1, 0]
20513 [1, 0, 0]
20514 [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
20515 [1, 0, 0]
20516 [1, 0, 0, 0]
Length: 20517, dtype: object
El segundo contiene los resultados con una granularidad del canal , como se ve en el atributo .group_by_channels_models .
attribution_first_click [ 1 ]| canales | atribution_first_click_heuristic | |
|---|---|---|
| 0 | Directo | 2078 |
| 1 | Marketing por correo electrónico | 1095 |
| 2 | 3177 | |
| 3 | Visualización de Google | 1066 |
| 4 | Búsqueda de Google | 4259 |
| 5 | 1007 | |
| 6 | Orgánico | 6361 |
| 7 | YouTube | 1062 |
De todos los modelos presentes en el objeto MAM, solo el último clic, el primer clic y el lineal no tienen parámetros personalizables , sino group_by_channels_models , que tiene un valor booleano que cuando se establece en falso el modelo no devuelve la atribución grorupada por los canales.
Creado para replicar la attriución predeterminada de Google Analytics ( último clic no directo ) en el que el tráfico directo se sobrescribe en caso de que las interacciones anteriores tengan una fuente de tráfico específica que no sea directa en un tiempo de tiempo determinado (6 meses por defecto).
Si no se especifica, el parámetro but_not_this_channel se establece en 'directo' , pero se puede establecer en cualquier otro canal de interés para el negocio.
attributions . attribution_last_click_non ( but_not_this_channel = 'Direct' )[ 1 ]| canales | atribution_last_click_non_direct_heuristic | |
|---|---|---|
| 0 | Directo | 11 |
| 1 | Marketing por correo electrónico | 60 |
| 2 | 172 | |
| 3 | Visualización de Google | 69 |
| 4 | Búsqueda de Google | 224 |
| 5 | 67 | |
| 6 | Orgánico | 350 |
| 7 | YouTube | 65 |
Este modelo tiene una lista de parámetros_positions_first_middle_last en la que los pesos respectivos a las posiciones de los canales en cada viaje me pueden especificar de acuerdo con las decisiones relacionadas con el negocio . La distribución predeterminada del parámetro es del 40% para el canal de introducción , 40% para el canal de conversión / último y 20% para los intermidiados .
attributions . attribution_position_based ( list_positions_first_middle_last = [ 0.3 , 0.3 , 0.4 ])[ 1 ]| canales | attribution_position_based_0.3_0.3_0.4_heuristic | |
|---|---|---|
| 0 | Directo | 95.685085 |
| 1 | Marketing por correo electrónico | 57.617191 |
| 2 | 145.817501 | |
| 3 | Visualización de Google | 56.340693 |
| 4 | Búsqueda de Google | 193.282305 |
| 5 | 54.678557 | |
| 6 | Orgánico | 288.148896 |
| 7 | YouTube | 55.629772 |
Hay dos configuraciones personalizables: la tasa de descomposición , el parámetro Decay_over_Time * y el tiempo (en horas) entre cada decaimente a través del parámetro de frecuencia .
Sin embargo, vale la pena señalar que en caso de que haya más de un punto de contacto entre los intervalos de frecuencia, el valor de conversión se distribuirá por igual entre estos canales.
Como ejemplo:
attributions . attribution_time_decay (
decay_over_time = 0.6 ,
frequency = 7 )[ 1 ]| canales | atribution_time_decay0.6_freq7_heuristic | |
|---|---|---|
| 0 | Directo | 108.679538 |
| 1 | Marketing por correo electrónico | 54.425914 |
| 2 | 159.592216 | |
| 3 | Visualización de Google | 64.350107 |
| 4 | Búsqueda de Google | 192.838884 |
| 5 | 64.611414 | |
| 6 | Orgánico | 314.920082 |
| 7 | YouTube | 58.581845 |
Al llamar a Uppon, este modelo devuelve una tupla con cuatro componentes. Los dos primeros (indexados 0 y 1) son como con los modelos heurísticos, con la representación del .dataframe y .group_by_channels_models respectivamente. En cuanto al tercer y cuarto componentes (indexados 2 y 3), los resultados son la matriz de transición y la tabla de efectos de eliminación .
Para comenzar, es posible indicar si las mismas transiciones de estado se consideran o no ( por ejemplo, directamente a Direct).
attribution_markov = attributions . attribution_markov ( transition_to_same_state = False )| canales | attribution_markov_algorithmic | |
|---|---|---|
| 0 | Directo | 2305.324362 |
| 1 | Marketing por correo electrónico | 1237.400774 |
| 2 | 3273.918832 | |
| 3 | YouTube | 1231.183938 |
| 4 | Búsqueda de Google | 4035.260685 |
| 5 | 1205.949095 | |
| 6 | Orgánico | 5358.270644 |
| 7 | Visualización de Google | 1213.691671 |
Esta configuración no afecta los resultados atribuidos generales para cada canal, sino los valores observados en la matriz de transición . Debido a que establecemos Transition_To_Same_State en False , la diagonal, que indica que los estados se transmiten a sí mismos, se anulan.
ax , fig = plt . subplots ( figsize = ( 15 , 10 ))
sns . heatmap ( attribution_markov [ 2 ]. round ( 3 ), cmap = "YlGnBu" , annot = True , linewidths = .5 )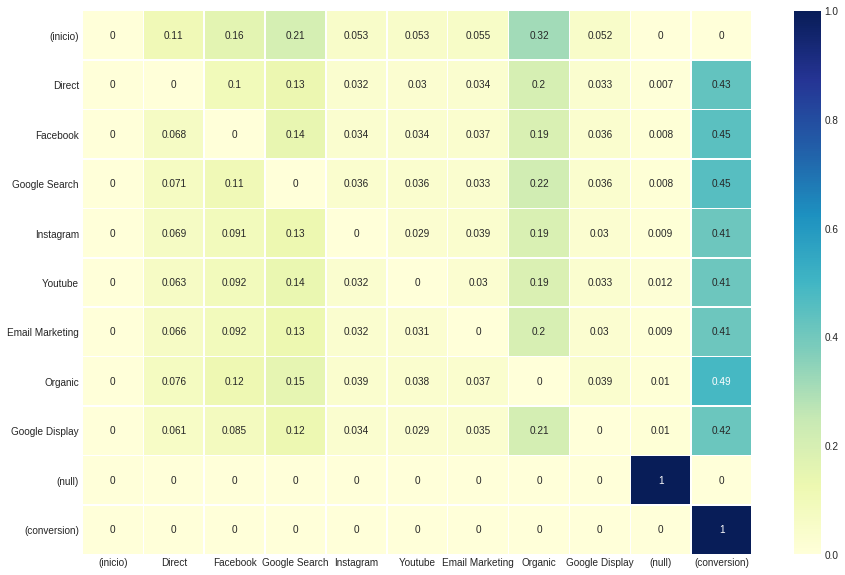
El efecto de eliminación , la cuarta salida de atribución_markov , se obtiene mediante la relación de la diferencia entre la probabilidad de conversión en general y la probabilidad una vez dicho canal se elimina nuevamente sobre la probabilidad general nuevamente.
ax , fig = plt . subplots ( figsize = ( 2 , 5 ))
sns . heatmap ( attribution_markov [ 3 ]. round ( 3 ), cmap = "YlGnBu" , annot = True , linewidths = .5 )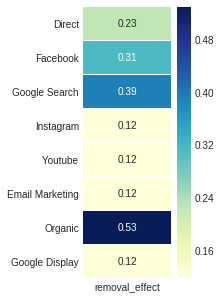
Finalmente, el segundo modelo de algorito de MAM cuyo concepto proviene de la teoría del juego . El objetivo aquí es distribuir la contribución de cada jugador (en nuestro caso, canal) en un juego de cooperación calculado utilizando combinaciones de viajes con y sin un canal dado.
El tamaño del parámetro define un límite de cuánto tiempo es una cadena de canales en cada viaje. Por defecto, su valor se establece en 4 , lo que significa que solo se consideran los cuatro últimos canales anteriores a una conversión .
El método de cálculo de las contribuciones marginales de cada canal puede variar con el parámetro de orden . Por defecto, se establece en falso , lo que significa que la contribución se calcula que no tiene en cuenta el orden de cada canal en los viajes.
attributions . attribution_shapley ( size = 4 , order = True , values_col = 'conv_rate' )[ 0 ]| combinaciones | conversiones | Total_sequencias | conversion_value | convencer | atribution_shapley_size4_conv_rate_order_algorithmic | |
|---|---|---|---|---|---|---|
| 0 | Directo | 909 | 926 | 909 | 0.981641 | [909.0] |
| 1 | Directo> Marketing por correo electrónico | 27 | 28 | 27 | 0.964286 | [13.948270234099155, 13.051729765900845] |
| 2 | Directo> Marketing por correo electrónico> Facebook | 5 | 5 | 5 | 1.000000 | [1.6636366232390172, 1.5835883671498818, 1.752 ... |
| 3 | Directo> Marketing por correo electrónico> Facebook> Google D ... | 1 | 1 | 1 | 1.000000 | [0.2563402919193473, 0.2345560799963515, 0.259 ... |
| 4 | Direct> Marketing por correo electrónico> Facebook> Google S ... | 1 | 1 | 1 | 1.000000 | [0.2522517802130265, 0.2401286956930936, 0.255 ... |
| ... | ... | ... | ... | ... | ... | ... |
| 1278 | YouTube> orgánico> Búsqueda de Google> Google Dis ... | 1 | 2 | 1 | 0.500000 | [0.2514214624662836, 0.24872101523605275, 0.24 ... |
| 1279 | YouTube> Orgánico> Search de Google> Instagram | 1 | 1 | 1 | 1.000000 | [0.2544401477637237, 0.2541071889956603, 0.253 ... |
| 1280 | YouTube> orgánico> Instagram | 4 | 4 | 4 | 1.000000 | [1.2757196742326997, 1.4712839059493295, 1.252 ... |
| 1281 | YouTube> Orgánico> Instagram> Facebook | 1 | 1 | 1 | 1.000000 | [0.2357631944623868, 0.2610913781266248, 0.247 ... |
| 1282 | YouTube> Orgánico> Instagram> Búsqueda de Google | 3 | 3 | 3 | 1.000000 | [0.7223482210689489, 0.7769049003203142, 0.726 ... |
Finalmente, el parámetro que indica qué métrica se usa para calcular el valor de Shapley es valores_col , que por defecto se establece en la tasa de conversión . Al hacerlo, los viajes sin conversiones se toman en cuenta.
Sin embargo, es posible considerar solo conversiones literal cuando se usa el modelo como se ve a continuación.
attributions . attribution_shapley ( size = 3 , order = False , values_col = 'conversions' )[ 0 ]| combinaciones | conversiones | Total_sequencias | conversion_value | convencer | atribution_shapley_size3_conversions_algorithmic | |
|---|---|---|---|---|---|---|
| 0 | Directo | 11 | 18 | 18 | 0.611111 | [11.0] |
| 1 | Directo> Marketing por correo electrónico | 4 | 5 | 5 | 0.800000 | [2.0, 2.0] |
| 2 | Directo> Marketing por correo electrónico> Búsqueda de Google | 1 | 2 | 2 | 0.500000 | [-3.16666666666666665, -7.666666666666666, 11.8 ... |
| 3 | Directo> Marketing por correo electrónico> orgánico | 4 | 6 | 6 | 0.6666667 | [-7.83333333333333333, -10.8333333333333332, 22.6 ... |
| 4 | Directo> Facebook | 3 | 4 | 4 | 0.750000 | [-8.5, 11.5] |
| ... | ... | ... | ... | ... | ... | ... |
| 75 | Instagram> Orgánico> YouTube | 46 | 123 | 123 | 0.373984 | [5.83333333333333332, 34.33333333333333, 5.83333 ... |
| 76 | Instagram> YouTube | 2 | 4 | 4 | 0.500000 | [2.0, 0.0] |
| 77 | Orgánico | 64 | 92 | 92 | 0.695652 | [64.0] |
| 78 | Orgánico> youtube | 8 | 11 | 11 | 0.727273 | [30.5, -22.5] |
| 79 | YouTube | 11 | 15 | 15 | 0.733333 | [11.0] |
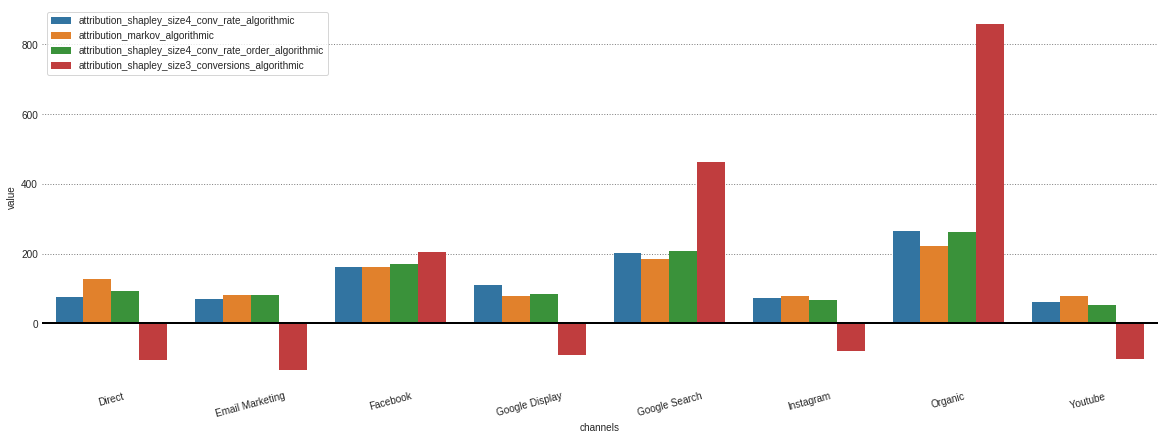
Después de obtener cada atribución de diferentes modelos almacenados en nuestro objeto .group_by_channels_models , es posible trazar y comparar los resultados para obtener información
attributions . plot ()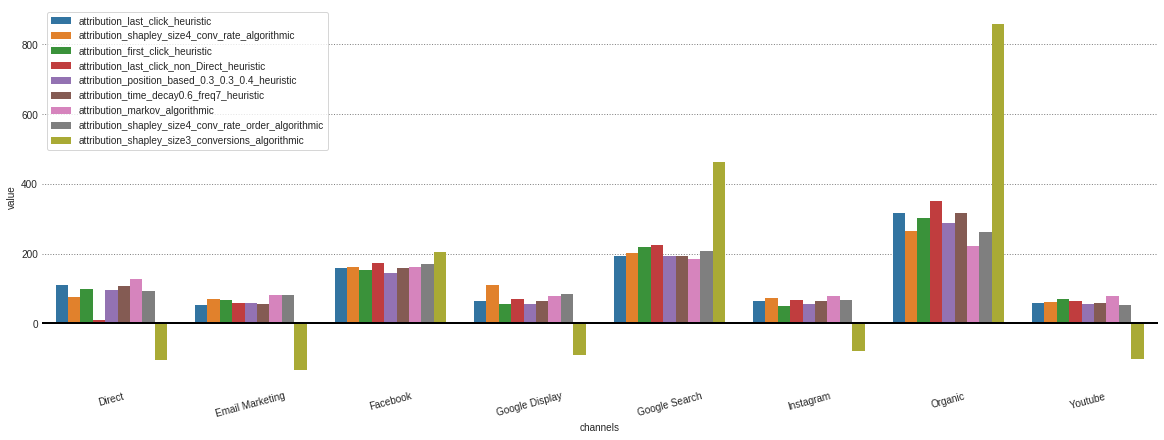
En caso de que solo esté interesado en los modelos algorítmicos, esto me puede especificar en el parámetro Model_Type .
attributions . plot ( model_type = 'algorithmic' )