Controlador con la mano de la sombra
Construimos un controlador para el modelo de mano de la sombra en el entorno de Mujoco utilizando el aprendizaje profundo y el aprendizaje de refuerzo profundo. El controlador permite que la mano realice gestos en el idioma de signos. Los gestos compatibles de esta mano son:
- Descansar
- Gota
- Dedo medio
- Sí
- No
- Roca
- Círculo
Demo de shadow-hand: https://youtu.be/vt_booel3fu
Descripción de la mano en la sombra

Shadow-Hand es una mano robótica 3D proporcionada por el repositorio de Mujoco_Menagerie , con fines académicos y de investigación. Se puede encontrar aquí: https://github.com/deepmind/mujoco_menagerie/tree/main/shadow_hand
Cómo funciona
Shadow-Hand utiliza 20 motores posicionales como actuadores para permitir el movimiento en sus dedos y su muñeca. Su actuador tiene un rango de control limitado definido por el fabricante. Las posiciones de cada actuador se pueden encontrar descargando el simulador de Mujoco e importando el archivo XML-Hand-Hand (ubicado en objecs/shadow_hand/escena_left.xml ) en el simulador a través de Drag & Drop . Para ver la posición y la orientación de cada actuador, la opción de juntas debe habilitarse dentro de la ventana de simulación, que se puede encontrar en el panel de representación/elemento modelo. En todo momento, se describen analíticamente dentro del archivo XML.
La posición, así como el rango de control de cada actuador de la mano, se proporcionan a continuación:
| identificación | ctrl_limit_left | ctrl_limit_right |
|---|
| 0 | -0.523599 | 0.174533 |
| 1 | -0.698132 | 0.488692 |
| 2 | -1.0472 | 1.0472 |
| 3 | 0 | 1.22173 |
| 4 | -0.20944 | 0.20944 |
| 5 | -0.698132 | 0.698132 |
| 6 | -0.261799 | 1.5708 |
| 7 | -0.349066 | 0.349066 |
| 8 | -0.261799 | 1.5708 |
| 9 | 0 | 3.1415 |
| 10 | -0.349066 | 0.349066 |
| 11 | -0.261799 | 1.5708 |
| 12 | 0 | 3.1415 |
| 13 | -0.349066 | 0.349066 |
| 14 | -0.261799 | 1.5708 |
| 15 | 0 | 3.1415 |
| 16 | 0 | 0.785398 |
| 17 | -0.349066 | 0.349066 |
| 18 | -0.261799 | 1.5708 |
| 19 | 0 | 3.1415 |

Clonación del comportamiento
La clonación de comportamiento (BC) es un método de enseñar a los controladores para realizar tareas observando e imitando a expertos humanos. Es una técnica particularmente común en robótica, donde un modelo aprende a realizar tareas imitando a los humanos. Este método implica:
- Recopilación de datos : un experto humano debe construir un conjunto de datos, que consiste en pares: (observaciones, acciones) .
- Algoritmo de aprendizaje : se diseña un algoritmo de aprendizaje (por ejemplo, una red neuronal) para mapear las observaciones (entradas) a las acciones esperadas (salidas).
- Implementación : el controlador se evalúa y se implementa en el modelo físico.
Aprendizaje de refuerzo profundo
El aprendizaje de refuerzo profundo (DRL) es otra técnica popular para que las máquinas de enseñanza realicen tareas de una manera óptima, pero difiere de la clonación conductual. Mientras que la clonación de comportamiento aprende directamente de los ejemplos (demostraciones) del comportamiento deseado, DRL aprende a través de la interacción con un entorno y recibe comentarios en forma de recompensas o sanciones. En entornos DRL, un agente recibe su estado $ s_ {t} $ del medio ambiente, elige una acción $ a_ {t} $ Usando su política $ pi _ { theta} $ , luego transiten al siguiente estado $ S_ {t+1} $ y finalmente recibe una recompensa $ r_ {t+1} $ Basado en lo buena que fue la acción. El objetivo del agente es maximizar las devoluciones acumulativas $ r = r_ {t + 1} + r_ {t + 2} + r_ {t + 3} + ... $.
Hay dos familiares populares de algoritmos que se utilizan en problemas de DRL:
- Métodos basados en el valor : estos métodos tienen como objetivo encontrar una función de valor, que es una medida de la recompensa acumulada esperada que un agente puede obtener de cualquier estado dado (o par de acción estatal). La función de valor más común es la función Q, Q (s, a), que mide el rendimiento esperado de tomar medidas $ a_ {t} $ agitado $ s_ {t} $ . Otra forma de medir el rendimiento esperado es mediante el uso de $ V (s) $ , que mide lo bueno que es un estado $ s_ {t} $ . A veces, estas dos funciones se combinan para acelerar el proceso de entrenamiento y el rendimiento de aprendizaje del agente. Al estimar la función de valor correctamente, el agente puede hacer una transición óptima entre los estados consecutivos y, por lo tanto, aprender un comportamiento óptimo. Tanto las funciones de la función Q como las de valor se pueden estimar utilizando una red neuronal, como se muestra a continuación.
- Métodos de gradiente de políticas : en lugar de calcular los rendimientos estimados, los métodos de gradiente de política optimizan directamente la función de la política sin la necesidad de una función de valor como intermediario. La política típicamente es parametrizada por un conjunto de pesos (por ejemplo, una red neuronal), y el aprendizaje implica ajustar estos pesos para maximizar la recompensa esperada. La idea es que al cambiar los pesos de una red neuronal y, por lo tanto, al cambiar las acciones seleccionadas, también cambia las recompensas que el agente recibe por el entorno. El objetivo del agente es cambiar su política (sus pesos) en el directino que maximiza sus recompensas, como se muestra a continuación. Una ventaja importante de los métodos de gradiente de políticas sobre los métodos basados en el valor es que permiten el uso de acciones continuas (por ejemplo, valores de flotación), en lugar de acciones discretas (por ejemplo, 1,2,3). Esto es específicamente útil en entornos de Mujoco, como el nuestro, donde el objetivo es predecir el control (valores de flotación) de cada actuador.
Observaciones (entradas)
Tanto la clonación de comportamiento como la técnica DRL requieren un conjunto de datos o un entorno de simulación para recuperar los datos. Para entrenar a ambos agentes, construimos un conjunto de datos que consiste en pares $ (Signo, pedido) -& gt; (Control) $ .
- Signo: Signo es un conjunto de controles secuenciales, que el controlador de mano tiene que ejecutar, para realizar un gesto de signo. Por ejemplo, para realizar un gesto "sí", la mano primero debe hacer un puño (1), luego mover su mano hacia abajo (2) y luego hacia arriba (3).
- Orden: el orden es el índice del control deseado dentro de la secuencia. Esto es necesario, porque el agente debe ejecutar todos los controles secuencialmente, en un orden especificado. Por ejemplo, en el ejemplo "Sí", los controles (1), (2), (3) deben ejecutarse como consecutivamente.
- Control: el control es un vector (matriz) de 20 valores, uno para cada actuador. Cada valor es un número flotante que controla la posición del actuador y no excede sus límites de control descritos en la tabla anterior.
Representación de signo/orden
La red neuronal recibe un vector de entrada y genera el vector de control. Si bien se espera que el vector de entrada sea un vector de valores flotantes, nuestro conjunto de datos contiene signos, que son cadenas (palabras) y órdenes, que son números enteros. Debido a que el conjunto de datos es muy pequeño, convertimos cada palabra y ordenamos a un vector único como se muestra a continuación:
| firmar | vector |
|---|
| descansar | [0,0,0,0,0,0,1] |
| gota | [0,0,0,0,0,1,0] |
| dedo medio | [0,0,0,0,1,0,0] |
| Sí | [0,0,0,1,0,0,0] |
| No | [0,0,1,0,0,0,0] |
| roca | [0,1,0,0,0,0,0] |
| círculo | [1,0,0,0,0,0,0] |
| orden | vector |
|---|
| 1 | [0,0,1] |
| 2 | [0,1,0] |
| 3 | [1,0,0] |
Ahora, estas características se pueden concatenar e insertar en el controlador de red neuronal/agente DRL.
Red neural (BC)
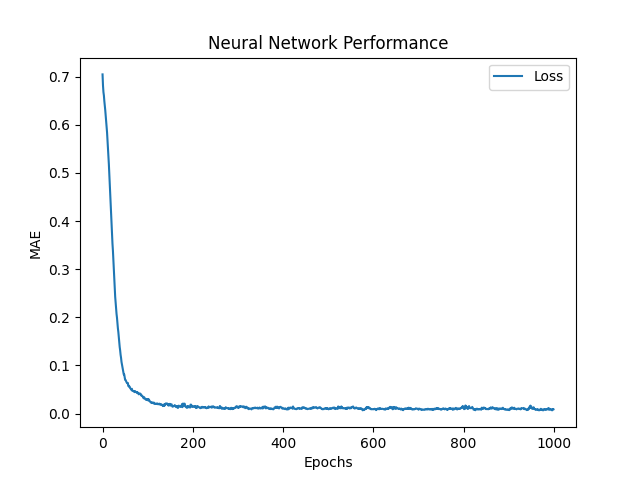
El objetivo de la red neuronal es predecir los valores de control de los 20 actuadores: $ hat {y_ {0}}, hat {y_ {1}}, hat {y_ {2}}, hat {y_ {3}}, ..., hat {y_ {19}} $ , al usar el signo, ordenar el par como entradas. Para hacer eso, la red genera una predicción de control y utiliza la función media de error absoluto (MAE) para evaluar su error de predicción. Luego, la red utiliza Adam Optimizer, que es una mejora del algoritmo de descenso de gradiente , para actualizar sus pesos y reducir el MAE. Si $ y $ y $ hat {y} $ son el objetivo (real) y el control predicho respectivamente, entonces MAE se define como:
$ frac {1} {n} * sum_ {i = 1}^{n} | y_i - hat {y_i} | $
Peformance de optimización de política proximal (DRL)
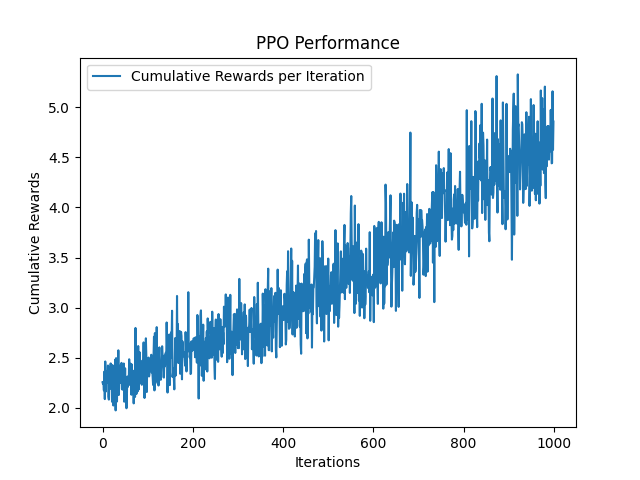
La optimización de políticas proximales (PPO) es un algoitmo de gradiente de política popular que aborda algunos desafíos en la estabilidad y la eficiencia de la capacitación que enfrentan la optimización de políticas de la región fiduciaria (TRPO). PPO presenta un mecanismo de recorte para evitar que la política se actualice demasiado drásticamente en un solo paso (evita que los pesos reciban grandes actualizaciones y cambien drásticamente), asegurando que la nueva política no se desvíe demasiado de la anterior. Al ubicar la política, en lugar de maximizar directamente la recompensa esperada, PPO tiene como objetivo maximizar una versión recortada de la función objetivo. Este objetivo recortado limita la relación de las probabilidades de las políticas nuevas y antiguas. Específicamente, si la nueva política aumentara la probabilidad de la acción significativamente en comparación con la antigua política, este cambio se recorta para estar dentro de un rango especificado (por ejemplo, entre 0.8 y 1.2). Esto evita actualizaciones demasiado agresivas que podrían converger rápidamente en políticas subóptimas. Este rango se define por un parámetro de recorte $ E $ , que generalmente se establece entre $ [0.1, 0.3] $ .
Al igual que BC Neural Network, PPO recibe pares de (signo, orden) como entradas y salidas el control objetivo de la mano. Luego, en lugar de usar una función de pérdida (error) para evaluar su error, utiliza una función de recompensa para recibir recompensas, que intenta maximizar en cada iteración. La función de recompensa $ R $ se define como $ R_ {t} = frac {1} {euclidean (y_ {t} - hat {y_ {t}})} $ , donde el euclidiano es la distancia euclidiana entre el control predicho y el objetivo.
Versión y bibliotecas de Python
- python == 3.9 https://www.python.org/downloads/release/python-390/
- Mujoco = 2.3.7 https://github.com/deepmind/mujoco
- tensorflow == 2.9.1 https://www.tensorflow.org/install
- Ray [rllib] == 2.3.1 https://docs.ray.io/en/latest/rllib/index.html
- gimnasio == 0.26.1 https://gymnasium.farama.org/
- matplotlib == 3.7.2 https://matplotlib.org/
Cómo correr
- Python Generate_Expert_dataset.py para construir un conjunto de datos. La mano puede cambiar de gestos con botones de tecla (1-7). El mouse se puede usar para navegar por el mundo de la simulación
- Python Train_nn.py para entrenar y evaluar la red neuronal
- Python Train_po.py para entrenar y evaluar el agente PPO
- Python Simulate_NEural_network_controller.py para implementar y evaluar el controlador basado en la red neuronal
- Python simulate_neural_network_controller.py para implementar y evaluar el controlador basado en PPO
Explicación de parámetros
- Trajectory_steps : el número de controles intermidantes para ejecutar entre dos controles consecutivos (por ejemplo, si
start_ctrl = [1,1,1], end_ctrl = [2,2,2] and trajectory_steps=5 , entonces la mano ejecuta los controles 2 + 3 entre [ 1,1,1] y [2,2,2]. - Cam_verbose : imprime la posición de la cámara en el terminal (esto ayuda inicialmente a ajustar la posición y la orientación de la cámara).
- SIM_VERBOSE : imprime los controles de cada actuador en cada paso de tiempo.
- One_hot_signs : si a los signos y órdenes de un solo estado. Si es falso, entonces los signos y órdenes se devolverán como cadenas e enteros respectivamente. Sin embargo, tanto la red neuronal como el agente DRL deberán modificarse para permitir el uso de cadenas como entrada. Una forma de hacerlo es agregar una capa de incrustación (https://www.tensorflow.org/text/guide/word_embeddings). Esto podría ser útil en los casos en que el número de gestos, así como los tamaños de secuencia de los signos son extremadamente grandes, por lo que no se puede utilizar un método de codificación único.
- Learning_Rate : la tasa de Learning de la red neuronal. Esto reduce las actualizaciones de la red, asegurando que la red converja lentamente al mínimo local. 0.001 es un buen valor típico
- épocas : el número de épocas para entrenar la red (número de veces el conjunto de datos se alimentará a la red). El valor predeterminado a 1000.
- Loss_fn : la función de pérdida de la red neuronal. El valor predeterminado es "MAE".
- Train_iterations : el número de iteraraciones que el agente estará capacitado. El valor predeterminado a 1000.
- Semilla : la semilla aleatoria, que se usa para generar números aleatorios. Esto permite que los experimentos se reproduzcan. El valor predeterminado es 0.
Controlador personalizado
Se puede proporcionar un controlador de modelo personalizado en la clase GLFWSimulator en orden o Control de los actuadores de Hand (verifique simulate_neural_network_controller.py y simulate_neural_network_controller.py ejemplos). La siguiente línea se puede modificar
hand_controller = Controller(
model=agent,
ctrl_limits=ctrl_limits
)
para que el agente sea reemplazado por un agente personalizado. El agente (o modelo) debe heredar la Controller class , encontrarse en el archivo controladores/controlador.py y definir los siguientes métodos:
-
def _set_sign(self, sign: str) : establece el comportamiento del controlador en signo especificado -
def _get_next_control(self, sign: str, order: int) : obtiene el siguiente control del signo especificado (por ejemplo, si un signo se define como 10 controles secuenciales, entonces get_next_control debería devolver el siguiente control predicho de esa secuencia (verifique model.py.py archivo).
Entorno de simulación
El entorno de simulación se escribe utilizando la biblioteca GLFW, que proporciona Mujoco. Se puede modificar fácilmente modificando el bucle while del archivo simulaton/pyopengl.py .
Red neuronal personalizada
La red neuronal está integrada en modelos/tf/nn.py utilizando la biblioteca TensorFlow. Se puede construir una red neuronal personalizada extendiendo el método de construcción de NeuralNetwork class . Las arquitecturas actuales usan 2 capas de 128 unidades para cada vector de entrada (128 para el vector de signo y 128 para el vector de pedido) y la función de activación de Relu en cada capa. Luego, las 2 capas se concatenan en un vector de 256 unidades, que luego es seguido por otra capa de 128 neuronas y finalmente 20 unidades de salida. Las 20 unidades finales se utilizan para establecer los controles del actuador.
Agente personalizado
Este repositorio utiliza el agente PPO de RLLIB. Sin embargo, se pueden agregar varias cosas:
- Tune fino (busque mejores parámetros para PPO). Actualmente, el algorito utiliza los parámetros predeterminados de PPO, según lo descrito por John Schulman et. Al en el artículo original https://arxiv.org/abs/1707.06347
- Agregue un algoritmo de aprendizaje más fuerte: por ejemplo, se sabe que SAC-Critic, también conocido como SAC tiene un rendimiento muy fuerte en los entornos de Mujoco: https://arxiv.org/pdf/1801.01290.pdf
- Aumente las iteraciones de capacitación: en los modelos previamente capacitados proporcionados en esta biblioteca, tanto la red neuronal como el agente PPO fueron capacitados para 1000 iteraciones. Aunque la red neuronal convergió a un pequeño error, PPO requiere más iteraciones de entrenamiento para converger. Esa es la razón por la que el controlador de PPO parece tener un comportamiento extraño.
- Agregue una red neuronal personalizada como modelo de actor-crítico. Esta es una tarea muy difícil de lograr, sin embargo, también hemos creado un repositorio para ese propósito: https://github.com/kochlisgit/deep-rl-frameworks


