awesome RLHF
1.0.0
Esta es una colección de trabajos de investigación para el aprendizaje de refuerzo con comentarios humanos (RLHF). Y el repositorio se actualizará continuamente para rastrear la frontera de RLHF.
¡Bienvenido a seguir y estrella!
Awesome RLHF (RL con comentarios humanos)
2024
2023
2022
2021
2020 y antes
Explicación detallada
Tabla de contenido
Descripción general de RLHF
Papeles
Bases de código
Conjunto de datos
Blogs
Otro soporte del idioma
Que contribuye
Licencia
La idea de RLHF es utilizar métodos desde el aprendizaje de refuerzo para optimizar directamente un modelo lingüístico con retroalimentación humana. RLHF ha permitido que los modelos de idiomas comiencen a alinear un modelo capacitado en un corpus general de datos de texto a los de valores humanos complejos.
RLHF para un modelo de lenguaje grande (LLM)
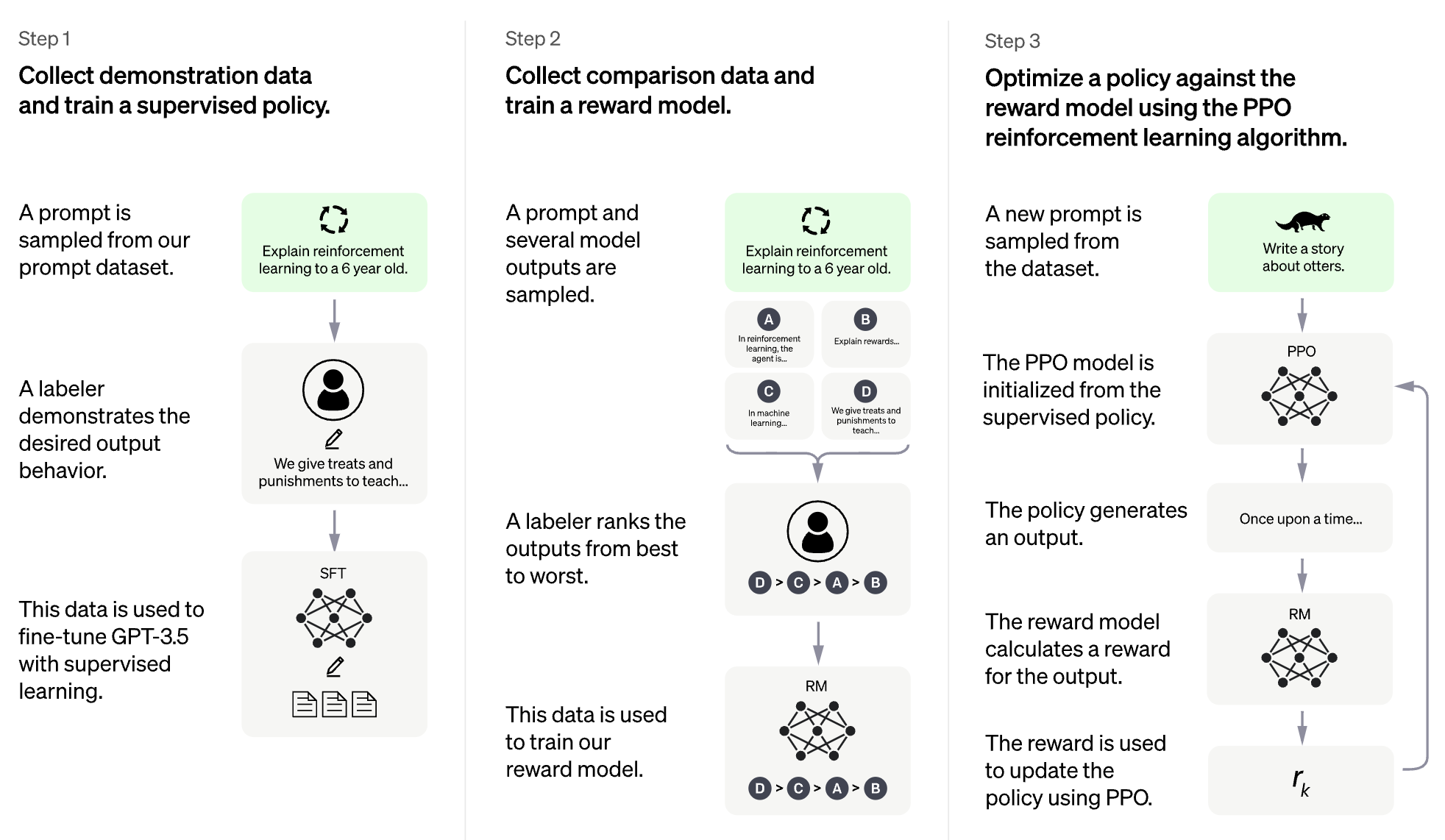
RLHF para videojuegos (por ejemplo, Atari)
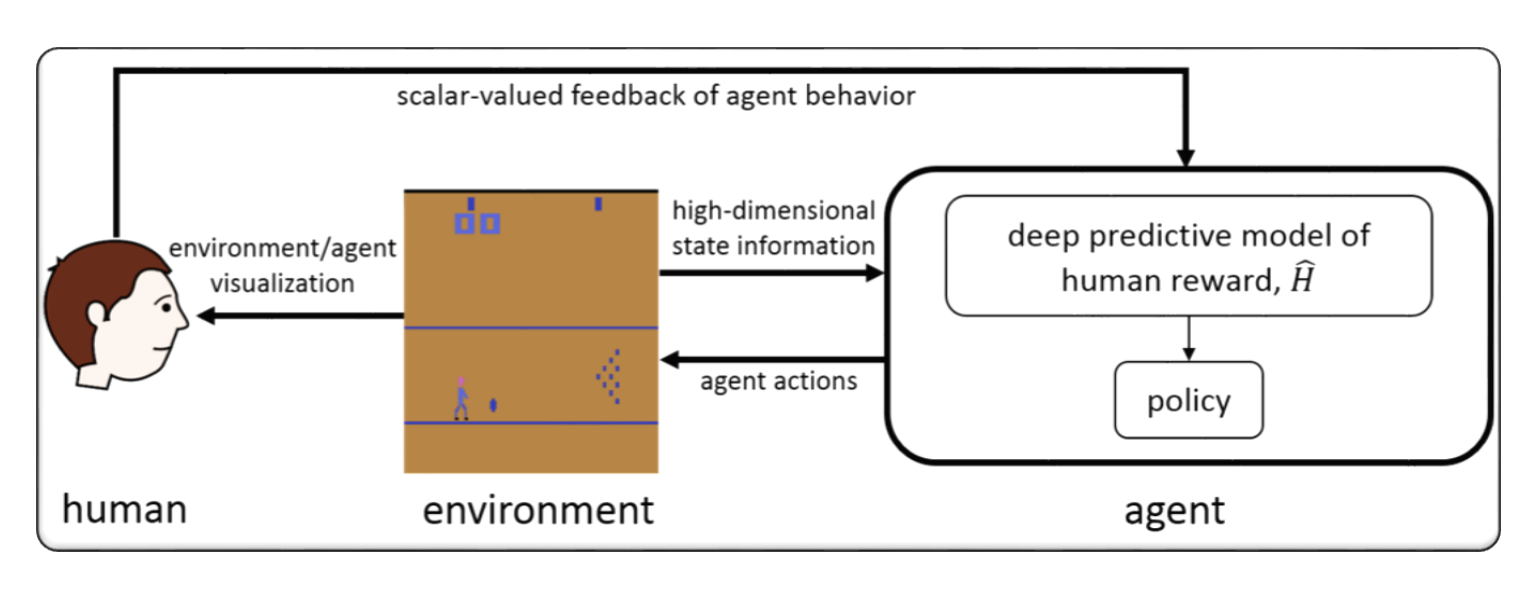
(ChatGPT generó automáticamente la siguiente sección)
RLHF generalmente se refiere al "aprendizaje de refuerzo con retroalimentación humana". El aprendizaje de refuerzo (RL) es un tipo de aprendizaje automático que implica capacitar a un agente para tomar decisiones basadas en la retroalimentación de su entorno. En RLHF, el agente también recibe comentarios de los humanos en forma de calificaciones o evaluaciones de sus acciones, lo que puede ayudarlo a aprender de manera más rápida y precisa.
RLHF es un área de investigación activa en inteligencia artificial, con aplicaciones en campos como robótica, juegos y sistemas de recomendaciones personalizadas. Busca abordar los desafíos de RL en escenarios en los que el agente tiene acceso limitado a la retroalimentación del medio ambiente y requiere información humana para mejorar su rendimiento.
El aprendizaje de refuerzo con la retroalimentación humana (RLHF) es un área de investigación en rápido desarrollo en inteligencia artificial, y hay varias técnicas avanzadas que se han desarrollado para mejorar el rendimiento de los sistemas RLHF. Aquí hay algunos ejemplos:
Inverse Reinforcement Learning (IRL) : IRL es una técnica que permite al agente aprender una función de recompensa de la retroalimentación humana, en lugar de depender de las funciones de recompensa predefinidas. Esto hace posible que el agente aprenda de señales de retroalimentación más complejas, como demostraciones de comportamiento deseado.
Apprenticeship Learning : el aprendizaje de aprendizaje es una técnica que combina a IRL con el aprendizaje supervisado para permitir que el agente aprenda de la retroalimentación humana y las demostraciones de expertos. Esto puede ayudar al agente a aprender de manera más rápida y efectiva, ya que puede aprender de la retroalimentación positiva y negativa.
Interactive Machine Learning (IML) : IML es una técnica que implica una interacción activa entre el agente y el experto humano, lo que permite al experto proporcionar comentarios sobre las acciones del agente en tiempo real. Esto puede ayudar al agente a aprender de manera más rápida y eficiente, ya que puede recibir comentarios sobre sus acciones en cada paso del proceso de aprendizaje.
Human-in-the-Loop Reinforcement Learning (HITLRL) : HITLRL es una técnica que implica integrar la retroalimentación humana en el proceso RL en múltiples niveles, como la configuración de la recompensa, la selección de acción y la optimización de políticas. Esto puede ayudar a mejorar la eficiencia y la efectividad del sistema RLHF aprovechando las fortalezas de los humanos y las máquinas.
Aquí hay algunos ejemplos de aprendizaje de refuerzo con comentarios humanos (RLHF):
Game Playing : en el juego, la retroalimentación humana puede ayudar al agente a aprender estrategias y tácticas que son efectivas en diferentes escenarios de juegos. Por ejemplo, en el popular juego de GO, los expertos humanos pueden proporcionar comentarios al agente sobre sus movimientos, ayudándolo a mejorar su juego y toma de decisiones.
Personalized Recommendation Systems : en los sistemas de recomendación, los comentarios humanos pueden ayudar al agente a aprender las preferencias de los usuarios individuales, lo que permite proporcionar recomendaciones personalizadas. Por ejemplo, el agente podría usar los comentarios de los usuarios sobre los productos recomendados para saber qué características son más importantes para ellas.
Robotics : en robótica, la retroalimentación humana puede ayudar al agente a aprender a interactuar con el entorno físico de manera segura y eficiente. Por ejemplo, un robot podría aprender a navegar un nuevo entorno más rápidamente con los comentarios de un operador humano en el mejor camino a tomar o qué objetos para evitar.
Education : en educación, la retroalimentación humana puede ayudar al agente a aprender a enseñar a los estudiantes de manera más efectiva. Por ejemplo, un tutor basado en IA podría usar comentarios de los maestros sobre los que las estrategias de enseñanza funcionan mejor con diferentes estudiantes, ayudando a personalizar la experiencia de aprendizaje.
format: - [title](paper link) [links] - author1, author2, and author3... - publisher - keyword - code - experiment environments and datasets
Hybridflow: un marco RLHF flexible y eficiente
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, Chuan Wu
Palabra clave: marco flexible, eficiente, RLHF
Código: Oficial
Alarma: alinear modelos de idiomas a través del modelado de recompensas jerárquicas
Yuhang Lai, Siyuan Wang, Shujun Liu, Xuanjing Huang, Zhongyu Wei
Palabra clave: recompensa jerárquica, abrir tareas de generación de texto
Código: Oficial
TLCR: Recompensa continua a nivel de token por el aprendizaje de refuerzo de grano fino de la retroalimentación humana
Eunseop Yoon, Hee Suk Yoon, Soohwan Eom, Gunsoo Han, Daniel Wontae Nam, Daejin Jo, Kyoung-Woon On, Mark A. Hasegawa-Johnson, Sungwoong Kim, Chang D. Yoo
Palabra clave: Recompensa continua a nivel de token, RLHF
Código: Oficial
Alinear grandes modelos multimodales con RLHF de objetos fácticamente aumentados
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Exiong Wang, Yiming Yang, Kurt Keutzer, Trevor Darrell
Palabra clave: RLHF, visión e lenguaje de fáctica, conjunto de datos de preferencias humanas
Código: Oficial
Alineación directa del modelo de lenguaje grande a través de la destilación rápida contrastante de contrato autosuficiente
Aiwei Liu, Haoping Bai, Zhiyun Lu, Xiang Kong, Simon Wang, Jiulong Shan, Meng Cao, Lijie Wen
Palabra clave: sin datos de preferencias humanas, autoreward, DPO
Código: Oficial
Control aritmético de LLM para diversas preferencias de usuario: alineación de preferencias direccionales con recompensas de objetivos múltiples
Haoxiang Wang, Yong Lin, Wei Xiong, Rui Yang, Shizhe Diao, Shuang Qiu, Han Zhao, Tong Zhang
Palabra clave: preferencia del usuario, modelo de recompensa de objetivos múltiples, muestreo de muestreo de rechazo
Código: Oficial
Volver a lo básico: revisando la optimización de estilo de refuerzo para aprender de la retroalimentación humana en LLMS
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet üstün, Sara Hooker
Palabra clave: optimización de RL en línea, bajo costo computacional
Código: Oficial
Mejora de modelos de idiomas grandes a través del aprendizaje de refuerzo de grano fino con una restricción de edición mínima
Zhipeng Chen, Kun Zhou, Wayne Xin Zhao, Junchen Wan, Fuzheng Zhang, Di Zhang, Ji-Rong Wen
Palabra clave: Recompensa a nivel de token, LLM
Código: Oficial
RLAIF vs. RLHF: Escala de refuerzo de refuerzo de la retroalimentación humana con comentarios de IA
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Ren Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, Sushant Prakash
Palabra clave: RL de AI Comentarios
Código: Oficial
Métodos basados en penalización de principios para el aprendizaje de refuerzo bilevel y RLHF
Han Shen, Zhuoran Yang, Tianyi Chen
Palabra clave: optimización bilevel
Código: Oficial
Recompensa densa gratis en el aprendizaje de refuerzo de la retroalimentación humana
Alex James Chan, Hao Sun, Samuel Holt, Mihaela van der Schaar
Palabra clave: conformación de recompensa, RLHF
Código: Oficial
Un enfoque minimaximalista para el aprendizaje de refuerzo de la retroalimentación humana
Gokul Swamy, Christoph Dann, Rahul Kidambi, Steven Wu, Alekh Agarwal
Palabra clave: ganador de Minax, optimización de preferencias de autocomplacencia
Código: Oficial
RLHF-V: Hacia MLLMS confiables a través de la alineación de comportamiento de la retroalimentación humana correccional de grano fino
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, Tat-Seng Chua
Palabra clave: modelos de idiomas grandes multimodales, problema de alucinación, aprendizaje de refuerzo de la retroalimentación humana
Código: Oficial
RLHF Flujo de trabajo: desde el modelado de recompensas hasta RLHF en línea
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, Tong Zhang
Palabra clave: RLHF iterativo en línea, modelado de preferencias, modelos de idiomas grandes
Código: Oficial
Maxmin-RLHF: Hacia la alineación equitativa de modelos de idiomas grandes con diversas preferencias humanas
Souradip Chakraborty, Jiahao Qiu, Hui Yuan, Alec Koppel, Furong Huang, Dinesh Manocha, Amrit Singh Bedi, Mengdi Wang
Palabra clave: mezcla de distribuciones de preferencias, objetivo de alineación máxima
Código: Oficial
Optimización de políticas de reinicio del conjunto de datos para RLHF
Jonathan D. Chang, Wenhao Zhan, Owen Oertell, Kianté Brantley, Dipendra Misra, Jason D. Lee, Wen Sun
Palabra clave: la optimización de la política de reinicio del conjunto de datos
Código: Oficial
Una densa vista de recompensa sobre la alineación de la difusión de texto a imagen con preferencia
Shentao Yang, Tianqi Chen, Mingyuan Zhou
Palabra clave: RLHF para la generación de texto a imagen, mejora densa de recompensas de DPO, alineación eficiente
Código: Oficial
La autocontrol ajusta convierte modelos de lenguaje débiles a modelos de lenguaje fuertes
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, Quanquan GU
Palabra clave: autocontrol ajustado
Código: Oficial
RLHF descifró: Un análisis crítico del aprendizaje de refuerzo de la retroalimentación humana para LLMS
Shreyas Chaudhari, Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande, Bruno Castro da Silva
Palabra clave: RLHF, recompensa oracular, análisis del modelo de recompensa, encuesta
Enfrentando la recompensa excesiva para los modelos de difusión: una perspectiva de los sesgos inductivos y primacios
Ziyi Zhang, Sen Zhang, Yibing Zhan, Yong Luo, Yonggang Wen, Dacheng Tao
Palabra clave: modelos de difusión, alineación, aprendizaje de refuerzo, RLHF, recompensa excesiva, sesgo de primacía
Código: Oficial
Sobre las preferencias diversificadas de la alineación del modelo de idioma grande
Dun Zeng, Yong Dai, Pengyu Cheng, Tianhao Hu, Wanshun Chen, Nan Du, Zenglin Xu
Palabra clave: Alinear la preferencia compartida, las métricas de modelado de recompensas, LLM
Código: Oficial
Alinear la retroalimentación de la multitud a través del modelado de recompensas de preferencia de distribución
Dexun Li, Cong Zhang, Kuicai Dong, Derrick Goh Xin Deik, Ruiming Tang, Yong Liu
Palabra clave: RLHF, distribución de preferencias, alineación, LLM
Más allá de la alineación de una preferencia para todos: optimización de preferencias directas de objetivos múltiples
Zhanhui Zhou, Jie Liu, Chao Yang, Jing Shao, Yu Liu, Xiangyu Yue, Wanli Ouyang, Yu Qiao
Palabra clave: RLHF multi-objetivo sin modelado de recompensas, DPO
Código: Oficial
Desalignación emulada: ¡La alineación de seguridad para modelos de idiomas grandes puede ser contraproducente!
Zhanhui Zhou, Jie Liu, Zhichen Dong, Jiaheng Liu, Chao Yang, Wanli Ouyang, Yu Qiao
Palabra clave: LLM Inference-Time Attack, DPO, produciendo LLM dañinos sin entrenamiento
Código: Oficial
Un análisis teórico del aprendizaje de NASH de la retroalimentación humana bajo la preferencia regularizada del general KL
Chenlu Ye, Wei Xiong, Yuheng Zhang, Nan Jiang, Tong Zhang
Palabra clave: RLHF basado en juegos, Aprendizaje Nash, alineación bajo Oracle sin modelo de recompensa
Mitigar el impuesto de alineación de RLHF
Yong Lin, Hangyu Lin, Wei Xiong, Shizhe Dioo, Jianmeng Liu, Jipeng Zhang, Rui Pan, Haoxiang Wang, Wenbin Hu, Hanning Zhang, Hanze Dong, Renjie PI, Han Zhao, Nan Jiang, Heng Ji, Yuan Ya
Palabra clave: RLHF, impuesto de alineación, olvido catastrófico
Modelos de difusión de entrenamiento con aprendizaje de refuerzo
Kevin Black, Michael Janner, Yilun du, Ilya Kostrikov, Sergey Levine
Palabra clave: aprendizaje de refuerzo, RLHF, modelos de difusión
Código: Oficial
Aligndiff: Alineando diversas preferencias humanas a través del modelo de difusión de comportamiento-personalizable
Zibin Dong, Yifu Yuan, Jianye Hao, Fei Ni, Yao Mu, Yan Zheng, Yujing Hu, Tangjie LV, Changjie Fan, Zhipeng Hu
Palabra clave: aprendizaje de refuerzo; Modelos de difusión; Rlhf; Alineación de preferencias
Código: Oficial
Recompensa densa gratis en el aprendizaje de refuerzo de la retroalimentación humana
Alex J. Chan, Hao Sun, Samuel Holt, Mihaela van der Schaar
Palabra clave: RLHF
Código: Oficial
Transformar y combinar recompensas para alinear modelos de idiomas grandes
Zihao Wang, Chirag Nagpal, Jonathan Berant, Jacob Eisenstein, Alex d'Amour, Sanmi Koyejo, Victor Veitch
Palabra clave: RLHF, Alineing, LLM
Parámetros de refuerzo eficiente Aprendizaje de la retroalimentación humana
Hakim Sidahmed, Samrat Phatale, Alex Hutcheson, Zhuonan Lin, Zhang Chen, Zac Yu, Jarvis Jin, Simral Chaudhary, Roman Komarytsia, Christiane Ahlheim, Yonghao Zhu, Bowen Li, Saravanan Ganesh, Bill Byrne, Jessica Hoffmann, Hassan Mansoor, Wei Li , Abhinav Rastogi, Lucas Dixon
Palabras clave: RLHF, Método eficiente de parámetros, bajo costo computacional, LLM, VLM
Mejorar el aprendizaje de refuerzo de la retroalimentación humana con un conjunto de modelos de recompensa eficiente
Shun Zhang, Zhenfang Chen, Sunli Chen, Yikang Shen, Zhiqing Sun, Chuang Gan
Palabras clave: RLHF, conjunto de recompensas, método de conjunto eficiente
Un paradigma teórico general para comprender el aprendizaje de las preferencias humanas
Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Daniel Guo, Daniele Calandriello, Michal Valko, Rémi Munos
Palabras clave: RLHF, preferencia por pares
La retroalimentación humana de grano fino ofrece mejores recompensas para la capacitación del modelo de idioma
Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A. Smith, Mari Ostendorf, Hannaneh Hajishirzi
Palabra clave: RLHF, Recompensa a nivel de oración, LLM
Código: Oficial
Guía de nivel de token de preferencia para el modelo de idioma ajustado
Shentao Yang, Shujian Zhang, Congying Xia, Yihao Feng, Caiming Xiong, Mingyuan Zhou
Palabra clave: RLHF, orientación de capacitación a nivel de token, marco de capacitación alternativo/en línea, objetivos de capacitación minimalista
Código: Oficial
Recompensas fantásticas y cómo domarlas: un estudio de caso sobre el aprendizaje de recompensas para los sistemas de diálogo orientados a las tareas
Yihao Feng*, Shentao Yang*, Shujian Zhang, Jianguo Zhang, Caiming Xiong, Mingyuan Zhou, Huan Wang
Palabra clave: RLHF, Learning de función de recompensa genralizada, utilización de la función de recompensa, sistema de diálogo orientado a las tareas, aprendizaje de clasificar
Código: Oficial
Aprendizaje de preferencias inversas: RL basada en preferencias sin una función de recompensa
Joey Hejna, Dorsa Sadigh
Palabra clave: aprendizaje de preferencias inversas, sin modelo de recompensa
Código: Oficial
Alpacafarm: un marco de simulación para métodos que aprenden de la retroalimentación humana
Yann Dubois, Chen Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy BA, Carlos Guestrin, Percy S. Liang, Tatsunori B. Hashimoto
Palabra clave: RLHF, marco de simulación
Código: Oficial
Optimización de clasificación de preferencias para la alineación humana
Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, Houfeng Wang
Palabra clave: optimización de clasificación de preferencias
Código: Oficial
Optimización de preferencias adversas
Pengyu Cheng, Yifan Yang, Jian Li, Yong Dai, Nan du
Palabra clave: rlhf, gan, juegos adversos
Código: Oficial
Preferencia iterativa Aprendizaje de la retroalimentación humana: teoría y práctica de puente para RLHF bajo la restricción de KL
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
Palabra clave: RLHF, DPO iterativo, Mathematical Foundation
Ejemplo de refuerzo eficiente aprendizaje de la retroalimentación humana a través de la exploración activa
Viraj Mehta, Vikramjeet Das, Ojash Neopane, Yijia Dai, Ilija Boguunovic, Jeff Schneider, Willie Neiswanger
Palabra clave: RLHF, eficiencia de muestra, exploración
Aprendizaje de refuerzo de la retroalimentación estadística: el viaje de las pruebas AB a las pruebas de hormigas
Feiyang Han, Yimin Wei, Zhaofeng Liu, Yanxing Qi
Palabra clave: RLHF, AB Pruebas, RLSF
Un análisis de referencia de la capacidad de los modelos de recompensa para analizar con precisión los modelos de base en el cambio de distribución
Ben Pikus, Will Levine, Tony Chen, Sean Hendryx
Palabra clave: rlhf, ood, cambio de distribución
Alineación eficiente de datos de modelos de lenguaje grande con retroalimentación humana a través del lenguaje natural
Di Jin, Shikib Mehri, Devamanyu Hazarika, Aishwarya Padmakumar, Sungjin Lee, Yang Liu, Mahdi Namazifar
Palabra clave: RLHF, eficiente de datos, alineación
Reforzemos paso a paso
Sarah Pan, Vladislav Lialin, Sherin Muckatira, Anna Rumshisky
Palabra clave: RLHF, razonamiento
Optimización de políticas basada en preferencias directas sin modelado de recompensas
Gaon An, Junhyeok Lee, Xingdong Zuo, Norio Kosaka, Kyung-Min Kim, Hyun Oh Song
Palabra clave: RLHF sin modelado de recompensas, aprendizaje contrastante, aprendizaje de refinamiento fuera de línea
Aligndiff: Alineando diversas preferencias humanas a través del modelo de difusión de comportamiento-personalizable
Zibin Dong, Yifu Yuan, Jianye Hao, Fei Ni, Yao Mu, Yan Zheng, Yujing Hu, Tangjie LV, Changjie Fan, Zhipeng Hu
Palabra clave: RLHF, Modelo de alineación, difusión
Eureka: diseño de recompensas a nivel humano a través de modelos de lenguaje grande
Yecheng Jason MA, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, Anima Anandkumar
Palabra clave: Basado en LLM, diseño de funciones de recompensa
RLHF seguro: refuerzo seguro aprendiendo de comentarios humanos
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, Yaodong Yang
Palabra clave: Sale RL, LLM Fine-Ture
Diversidad de calidad a través de la retroalimentación humana
Li Ding, Jenny Zhang, Jeff Clune, Lee Spector, Joel Lehman
Palabra clave: diversidad de calidad, modelo de difusión
Remax: un método de aprendizaje de refuerzo simple, efectivo y eficiente para alinear modelos de idiomas grandes
Ziniu Li, Tian Xu, Yushun Zhang, Yang Yu, Ruoyu Sun, Zhi-Quan Luo
Palabra clave: eficiencia computacional, técnica de reducción de varianza
Ajustar modelos de visión por computadora con recompensas de tareas
André Susano Pinto, Alexander Kolesnikov, Yuge Shi, Lucas Beyer, Xiaohua Zhai
Palabra clave: ajuste de recompensa en la visión por computadora
La sabiduría de la retrospectiva hace que los modelos de idioma sean mejores seguidores de instrucciones
Tianjun Zhang, Fangchen Liu, Justin Wong, Pieter Abbeel, Joseph E. González
Palabra clave: Relabelación de instrucciones retrospectivas, sistema RLHF, no se requiere red de valor
Código: Oficial
Lenguaje instruyó el aprendizaje de refuerzo para la coordinación humana-AI
Hengyuan Hu, Dorsa Sadigh
Palabra clave: Coordinación Human-AI, alineación de preferencias humanas, instrucción condicionada RL
Alinear modelos lingüísticos con el aprendizaje de refuerzo fuera de línea de la retroalimentación humana
Jian Hu, Li Tao, June Yang, Chandler Zhou
Palabra clave: alineación basada en el transformador de decisión, aprendizaje de refuerzo fuera de línea, sistema RLHF
Optimización de clasificación de preferencias para la alineación humana
Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li y Houfeng Wang
Palabra clave: alineación de preferencias humanas supervisadas, extensión de clasificación de preferencias
Código: Oficial
Bridging the Gap: una encuesta sobre retroalimentación de integración (humana) para la generación del lenguaje natural
Patrick Fernandes, Aman Madaan, Emmy Liu, António Farinhas, Pedro Henrique Martins, Amanda Bertsch, José GC de Souza, Shuyan Zhou, Tongshuang Wu, Graham Neubig, André Ft Martins
Palabra clave: Generación del lenguaje natural, integración de retroalimentación humana, formalización de comentarios y taxonomía, comentarios de IA y juicios basados en principios
Informe técnico GPT-4
Opadai
Palabra clave: un modelo multimodal a gran escala, modelo basado en transformador, ajustado RLHF usado
Código: Oficial
DataSet: Drop, Winogrande, HellaSwag, Arco, Humaneval, GSM8K, MMLU, Verdad para
Raft: recompensa clasificada Finetuning para la alineación del modelo de base generativa
Hanze Dong, Wei Xiong, Deepanshu Goyal, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, Tong Zhang
Palabra clave: muestreo de rechazo Fineting, alternativa a PPO, modelo de difusión
Código: Oficial
RRHF: respuestas de rango para alinear los modelos de lenguaje con la retroalimentación humana sin lágrimas
Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, Fei Huang
Palabra clave: Nuevo paradigma para RLHF
Código: Oficial
Aprendizaje de preferencia de pocos disparos para el humano en el bucle RL
Joey Hejna, Dorsa Sadigh
Palabra clave: aprendizaje de preferencias, aprendizaje interactivo, aprendizaje de tareas múltiples, ampliando el grupo de datos disponibles al ver RL humano en el bucle
Código: Oficial
Mejor alinear modelos de texto a imagen con preferencia humana
Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, Hongsheng Li
Palabra clave: modelo de difusión, texto a imagen, estética
Código: Oficial
Imagereward: aprender y evaluar las preferencias humanas para la generación de texto a imagen
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, Yuxiao Dong
Palabra clave: RM de preferencia humana de texto a imagen de uso general, evaluando modelos generativos de texto a imagen
Código: Oficial
Conjunto de datos: Coco, DiffusionDB
Alinear modelos de texto a imagen utilizando retroalimentación humana
Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing du, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Shixiang Shane Gu
Palabra clave: texto a imagen, modelo de difusión estable, función de recompensa que predice la retroalimentación humana
Chatgpt visual: hablar, dibujar y editar con modelos de Foundation Visual
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan
Palabra clave: Modelos Visual Foundation, chatgpt visual
Código: Oficial
Modelos lingüísticos previos a la altura con preferencias humanas (PHF)
Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Bhalerao, Christopher L. Buckley, Jason Phang, Samuel R. Bowman, Ethan Perez
Palabra clave: preventiva, fuera de línea RL, Transformador de decisión
Código: Oficial
Alinear modelos de lenguaje con preferencias a través de la minimización de divergencia F (F-DPG)
Dongyoung Go, Tomasz Korbak, Germán Kruszewski, Jos Rozen, Nahyeon Ryu, Marc Dymetman
Palabra clave: f-divergencia, RL con penalizaciones de KL
Aprendizaje de refuerzo de principios con comentarios humanos de comparaciones por pares o K-sabios
Banghua Zhu, Jiantao Jiao, Michael I. Jordan
Palabra clave: pesimista MLE, max-entropy IRL
La capacidad de la autocorrección moral en modelos de idiomas grandes
Antrópico
Palabra clave: mejorar la capacidad de autocorrección moral al aumentar el entrenamiento RLHF
Conjunto de datos; Barbacoa
¿Es el aprendizaje de refuerzo (no) para el procesamiento del lenguaje natural?: Puntos de referencia, líneas de base y bloques de construcción para la optimización de políticas de lenguaje natural (NLPO)
Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté, Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, Yejin Choi
Palabra clave: Optimización de generadores de idiomas con RL, algoritmo RL de Benchmark, Performant RL
Código: Oficial
Conjunto de datos: IMDB, Commongen, CNN Daily Mail, Totto, WMT-16 (en-de), Narrativeqa, DailyDialog
Leyes de escala para el modelo de recompensa en exceso de optimización
Leo Gao, John Schulman, Jacob Hilton
Palabra clave: modelo de recompensa de oro Modelo de recompensa de proxy, tamaño del conjunto de datos, tamaño de parámetro de política, BON, PPO
Mejora de la alineación de los agentes del diálogo a través de juicios humanos dirigidos (gorrión)
Amelia Glaese, Nat McAleese, Maja Trębacz, et al.
Palabra clave: Agente de diálogo que busca información, desglose el buen diálogo en las reglas del lenguaje natural, DPC, interactúe con el modelo para provocar la violación de una regla específica (sondeo adversario)
Conjunto de datos: preguntas naturales, ELI5, Calidad, Triviaqa, Winobias, BBQ
Modelos de lenguaje de equipo rojo para reducir los daños: métodos, comportamientos de escala y lecciones aprendidas
Ganguli profundo, Liane Lovitt, Jackson Kernion, et al.
Palabra clave: modelo de lenguaje de equipo rojo, investigar comportamientos de escala, leer el conjunto de datos de equipo
Código: Oficial
Planificación dinámica en diálogo abierto utilizando el aprendizaje de refuerzo
Deborah Cohen, Moonkyung Ryu, Yinlam Chow, Orgad Keller, Ido Greenberg, Avinatan Hassidim, Michael Fink, Yossi Matias, Idan Szpektor, Craig Boutilier, Gal Elidan
Palabra clave: sistema de diálogo en tiempo real, abierto, combina la incrustación de la incrustación del estado de conversación por modelos de idiomas, CAQL, CQL, Bert
Quark: generación de texto controlable con desaprendizaje reforzado
Ximing Lu, Sean Welleck, Jack Hessel, Liwei Jiang, Lianhui Qin, Peter West, Prithviraj Ammanabrolu, Yejin Choi
Palabra clave: ajustar el modelo de idioma en las señales de qué no hacer, Decision Transformer, LLM Tuning con PPO
Código: Oficial
Conjunto de datos: WritingPrompts, SST-2, Wikitext-103
Capacitar a un asistente útil e inofensivo con refuerzo aprendiendo de comentarios humanos
Yuntao Bai, Andy Jones, Kamal Ndousse, et al.
Palabra clave: Asistentes inofensivos, modo en línea, robustez de la capacitación RLHF, detección de OOD.
Código: Oficial
Conjunto de datos: Triviaqa, HellaSwag, ARC, OpenBookqa, Lambada, Humaneval, MMlu, Lucinffulqa
Enseñanza de modelos de idiomas para apoyar las respuestas con citas verificadas (Gophercite)
Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, Nat McAleesee
Palabra clave: genere respuestas que citen evidencia específica, se abstengan de responder cuando no están seguros
Conjunto de datos: preguntas naturales, ELI5, calidad, verdaderaqa
Modelos de lenguaje de capacitación para seguir las instrucciones con comentarios humanos (instructSppt)
Long Oyang, Jeff Wu, Xu Jiang, et al.
Palabra clave: modelo de lenguaje grande, alinear el modelo de lenguaje con intención humana
Código: Oficial
Conjunto de datos: verdaderos, REOTOXICITIONPROMPTS
AI constitucional: inofensiva de la retroalimentación de la IA
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, et al.
Palabra clave: RL de AI Comentarios (RLAIF), capacitar a un asistente de IA inofensivo a través de la superposición, el estilo de la cadena de pensamiento, el comportamiento de AI con mayor precisión
Código: Oficial
Descubrir comportamientos del modelo de idioma con evaluaciones escritas por modelos
Ethan Pérez, Sam Ringer, Kamilė Lukošiūtė, Karina Nguyen, Edwin Chen, et al.
Palabra clave: generar automáticamente evaluaciones con LMS, más RLHF empeora LMS, las evaluaciones escritas por LM son de alta calidad
Código: Oficial
Conjunto de datos: BBQ, esquemas de Winogender
Modelado de recompensas no markovianas a partir de etiquetas de trayectoria a través de aprendizaje interpretable de múltiples instancias múltiples
Joseph Early, Tom Bewley, Christine Evers, Sarvapali Ramchurn
Palabra clave: modelado de recompensas (RLHF), no Markovian, aprendizaje de instancias múltiples, interpretabilidad
Código: Oficial
WebGPT: cuestionamiento asistido por el navegador-respuesta con comentarios humanos (WebGPT)
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, et al.
Palabra clave: Modelo Busque en la web y proporcione referencia, aprendizaje de imitación, BC, pregunta de forma larga
DataSet: Eli5, Triviaqa, Verdadqa
Resumiendo libros recursivamente con comentarios humanos
Jeff Wu, Long Oyang, Daniel M. Ziegler, Nisan Stiennon, Ryan Lowe, Jan Leike, Paul Christiano
Palabra clave: modelo capacitado en una pequeña tarea para ayudar a la evaluación humana a evaluar tareas más amplias, BC
Conjunto de datos: booksum, narrativeqa
Revisando las debilidades del aprendizaje de refuerzo para la traducción del automóvil neuronal
Samuel Kiegeland, Julia Kreutzer
Palabra clave: el éxito del gradiente de política se debe a la recompensa en lugar de a la forma de la distribución de salida, la traducción automática, NMT, adaptación de dominio
Código: Oficial
Conjunto de datos: WMT15, IWSLT14
Aprender a resumir de la retroalimentación humana
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, Paul Christiano
Palabra clave: cuidado por la calidad de resumen, la pérdida de capacitación afecta el comportamiento del modelo, el modelo de recompensa se generaliza a nuevos conjuntos de datos
Código: Oficial
Conjunto de datos: TL; DR, CNN/DM
Modelos lingüísticos de ajuste de las preferencias humanas
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving
Palabra clave: recompensa el aprendizaje por el lenguaje, el texto continuo con sentimiento positivo, tarea resumida, descriptivo físico
Código: Oficial
Conjunto de datos: TL; DR, CNN/DM
Alineación de agentes escalables a través del modelado de recompensas: una dirección de investigación
Jan Leike, David Krueger, Tom Everitt, Miljan Martic, Vishal Maini, Shane Legg
Palabra clave: Problema de alineación del agente, aprender recompensa de la interacción, optimizar la recompensa con RL, modelado recursivo de recompensa
Código: Oficial
Env: Atari
Recompensa el aprendizaje de las preferencias y manifestaciones humanas en Atari
Borja Ibarz, Jan Leike, Tobias Pohlen, Geoffrey Irving, Shane Legg, Dario Amodei
Palabra clave: Preferencias de trayectoria de demostración de expertos Problema de piratería de recompensas, ruido en la etiqueta humana
Código: Oficial
Env: Atari
Deep Tamer: agente interactivo que forma en espacios de estado de alta dimensión
Garrett Warnell, Nicholas Waytowich, Vernon Lawhern, Peter Stone
Palabra clave: estado de alta dimensión, aproveche la entrada del entrenador humano
Código: tercero
Env: Atari
Refuerzo profundo aprendiendo de las preferencias humanas
Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, Dario Amodei
Palabra clave: Explore el objetivo definido en las preferencias humanas entre pares de trayectorias segmentación, aprenda algo más complejo que la retroalimentación humana
Código: Oficial
Env: Atari, Mujoco
El aprendizaje interactivo de la retroalimentación humana dependiente de la política
James MacGlashan, Mark K HO, Robert Loftin, Bei Peng, Guan Wang, David Roberts, Matthew E. Taylor, Michael L. Littman
Palabra clave: la decisión está influenciada por la política actual en lugar de la retroalimentación humana, aprenda de la retroalimentación dependiente de las políticas que converge a un local óptimo
format: - [title](codebase link) [links] - author1, author2, and author3... - keyword - experiment environments, datasets or tasks
Verl: aprendizaje de refuerzo del motor del volcán para LLM
Bytedance Seed Mlsys Team & Hku: Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, Chuan Wu
Palabra clave: marco flexible, eficiente, RLHF
Tareas: RLHF, tareas de razonamiento que incluyen matemáticas y código.
OpenRLHF
OpenRLHF
Palabra clave: 70B, RLHF, Deepspeed, Ray, VLLM
Tarea: un marco RLHF de alto rendimiento fácil de usar, escalable y de alto rendimiento (soporte 70B+ Tuning completo y Lora y Mixtral & KTO).
Palm + Rlhf - Pytorch
Phil Wang, Yachine Zahidi, Ikko Eltociear Ashimine, Eric Alcaide
Palabra clave: transformadores, arquitectura de palma
Conjunto de datos: enwik8
preferencias de LM-Human
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving
Palabra clave: recompensa el aprendizaje por el lenguaje, el texto continuo con sentimiento positivo, tarea resumida, descriptivo físico
Conjunto de datos: TL; DR, CNN/DM
siguientes instrucciones-retroalimentación
Long Oyang, Jeff Wu, Xu Jiang, et al.
Palabra clave: modelo de lenguaje grande, alinear el modelo de lenguaje con intención humana
Conjunto de datos: verdadero reeoxicidadpromts
Aprendizaje de refuerzo de transformadores (TRL)
Leandro von Werra, Younes Belkada, Lewis Tunstall, et al.
Palabra clave: Train LLM con RL, PPO, Transformer
Tarea: sentimiento IMDB
Transformer Reflor Learning x (TRLX)
Jonathan Tow, Leandro von Werra, et al.
Palabra clave: Marco de capacitación distribuido, modelos de idiomas basados en T5, Train LLM con RL, PPO, ILQL
Tarea: Fait Tuning LLM con RL utilizando la función de recompensa proporcionada o el conjunto de datos marcado con recompensas
RL4LMS (una biblioteca RL modular para ajustar los modelos de lenguaje a las preferencias humanas)
Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté, Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, Yejin Choi
Palabra clave: Optimización de generadores de idiomas con RL, algoritmo RL de Benchmark, Performant RL
Conjunto de datos: IMDB, Commongen, CNN Daily Mail, Totto, WMT-16 (en-de), Narrativeqa, DailyDialog
Lamda-rlhf-pytorch
Phil Wang
Palabra clave: Lamda, mecanismo de atención
Tarea: Implementación previa a la capacitación de código abierto del documento de investigación LAMDA de Google en Pytorch
Textrl
Eric Lam
Palabra clave: Transformador de Huggingface
Tarea: Generación de texto
Env: PFRL, gimnasio
minrlhf
Thomfoster
Palabra clave: PPO, biblioteca mínima
Tarea: fines educativos
Chat de tierra profunda
Microsoft
Palabra clave: capacitación RLHF asequible
Dromedario
IBM
Palabra clave: supervisión humana mínima, autoalineada
Tarea: modelo de lenguaje autoalineado entrenado con una supervisión humana mínima
FG-RLHF
Zeqiu Wu, Yushi Hu, Weijia Shi, et al.
Palabra clave: RLHF de grano fino, proporcionando una recompensa después de cada segmento, incorporando múltiples RMS asociados con diferentes tipos de retroalimentación
Tarea: un marco que permite la capacitación y el aprendizaje de las funciones de recompensa que son de grano fino en densidad y múltiples rms -safe-rlhf
Xuehai Pan, Ruiyang Sun, Jiaming Ji, et al.
Palabra clave: admite modelos populares previamente capacitados, un gran conjunto de datos marcados con humanos, métricas de múltiples escala para verificación de restricciones de seguridad, parámetros personalizados
Tarea: LLM de valor alineado restringido a través de SAFE RLHF
format: - [title](dataset link) [links] - author1, author2, and author3... - keyword - experiment environments or tasks
HH-RLHF
Ben Mann, Ganguli profundo
Palabra clave: conjunto de datos de preferencias humanas, datos de equipo rojo, escrito por máquina
Tarea: conjunto de datos de código abierto para datos de preferencias humanas sobre ayuda e inocuencia
Estanford Human Preferences DataSet (SHP)
Ethayarajh, Kawin y Zhang, Heidi y Wang, Yizhong y Jurafsky, Dan
Palabra clave: conjunto de datos naturales y escritos por humanos, 18 áreas temáticas diferentes
Tarea: destinado a ser utilizado para capacitar modelos de recompensa RLHF
Avance
Stephen H. Bach, Victor Sanh, Zheng-Xin Yong et al.
Palabra clave: conjuntos de datos en inglés, asignando un ejemplo de datos en lenguaje natural
Tarea: Kit de herramientas para crear, compartir y usar indicaciones de lenguaje natural
Colecciones de recursos de conexión a tierra de conocimiento estructurado (SKG)
Tianbao Xie, Chen Henry Wu, Peng Shi et al.
Palabra clave: base de conocimiento estructurado
Tarea: la recopilación de conjuntos de datos está relacionada con la base de conocimiento estructurado
La colección flan
Longpre Shayne, Hou Le, Vu Tu et al.
Tarea: la colección compila conjuntos de datos de FLAN 2021, P3, instrucciones súper naturales
rlhf-reward-datasets
Yiting xie
Palabra clave: conjunto de datos escrito por máquina
webgpt_comparisons
Opadai
Palabra clave: conjunto de datos escrito por humanos, respuesta de la pregunta de formulario largo
Tarea: capacite a un modelo de respuesta de preguntas de forma larga para alinearse con las preferencias humanas
resumen_from_feedback
Opadai
Palabra clave: conjunto de datos escrito por humanos, resumen
Tarea: capacite a un modelo de resumen para alinearse con las preferencias humanas
Dahoas/sintética-insuclute-gptj-Pairwise
Dahoas
Palabra clave: conjunto de datos escrito por humanos, conjunto de datos sintético
Alineación estable: aprendizaje de alineación en juegos sociales
Ruibo Liu, Ruixin (Ray) Yang, Qiang Peng
Palabra clave: datos de interacción utilizados para el entrenamiento de alineación, ejecutado en Sandbox
Tarea: Entrena en los datos de interacción grabados en juegos sociales simulados
Lima
Meta ai
Palabra clave: sin ningún RLHF, pocas indicaciones y respuestas cuidadosamente seleccionadas
Tarea: conjunto de datos utilizado para capacitar al modelo Lima
[OpenAI] Chatgpt: Optimización de modelos de idiomas para el diálogo
[Cara abrazada] Ilustrando el aprendizaje de refuerzo de la retroalimentación humana (RLHF)
[Zhihu] 通向 agi 之路 : 大型语言模型 (llm) 技术精要
[Zhihu] 大语言模型的涌现能力 : 现象与解释
[Zhihu] 中文 hh-rlhf 数据集上的 ppo 实践
[W&B totalmente conectado] Comprensión del aprendizaje de refuerzo de la retroalimentación humana (RLHF)
[DeepMind] aprendiendo a través de la retroalimentación humana
[Noción] 深入理解语言模型的突现能力
[Noción] 拆解追溯 GPT-3.5 各项能力的起源
[GIST] Aprendizaje de refuerzo para modelos de idiomas
[YouTube] John Schulman - Aprendizaje de refuerzo de los comentarios humanos: progreso y desafíos
[OpenAi / Arize] OpenAi sobre el aprendizaje de refuerzo con comentarios humanos
[Encord] Guía para el aprendizaje de refuerzo de la retroalimentación humana (RLHF) para la visión por computadora
[Weixun Wang] Descripción general de RL (HF)+LLM
turco
Nuestro propósito es hacer que este repositorio sea aún mejor. Si está interesado en contribuir, consulte aquí para obtener instrucciones en contribución.
Awesome RLHF se lanza bajo la licencia Apache 2.0.


